📅 TIL - 2026-01-02 ~ 08
Kafka
Kafka란?
Kafka는 분산 이벤트 스트리밍 플랫폼이다.
- 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 등의 용도로 활용되며, 대용량 메시지 실시간 처리 및 저장, 분산 환경에서 높은 처리량과 확장성(scalability), 영속성(durability)을 제공한다.
- 발행-구독(Publish-Subscribe) 모델 기반으로 동작한다.
구성 요소
Producer
- 역할: Kafka 토픽으로 메시지를 생산하여 전송하는 클라이언트 애플리케이션
- 특징
- 데이터를 보낼 토픽과 파티션 지정 가능
- 토픽의 파티션에 레코드(메시지) append(추가)하는 방식으로 동작
Topic
- 역할: Kafka에 저장되는 메시지들을 분류하는 논리적 개념의 카테고리(폴더)
(같은 종류의 메시지를 모아둔다.) - 특징: 하나의 토픽이 여러 개의 파티션으로 구성됨
Partition
- 역할: Topic을 여러 칸으로 나눈 것
- 특징
- 같은 파티션 내 메시지 순서를 보장해줌
- 각 파티션 Broker에 분산 저장 → Kafka의 병렬 처리 핵심
- 파티션마다 offset이라는 고유한 순번을 부여하고 읽은 메시지 위치를 표시
Broker
- 역할
- Kafka Cluster 구성 핵심 서버 단위
- Producer로부터 메시지 받아 디스크 저장 → Consumer에게 메시지를 전달하는 역할
- 특징
- 하나 이상의 Broker가 모여 Kafka Cluster 형성
- 각 Broker마다 특정 파티션의 리더(Leader) 또는 복제본(Replica) 역할을 수행함
- KRaft 모드에서는 Broker가 메타데이터 관리 역할(Controller)도 겸할 수 있음
Consumer
- 역할: Kafka 토픽으로부터 메시지를 소비하는 클라이언트 애플리케이션
- 특징:
- 하나 이상의 Consumer가 모여 Consumer Group을 형성
- 동일한 Consumer Group 내 Consumer들은 Topic의 파티션들을 나누어 병렬 처리함
- 각 Consumer 자신이 마지막으로 읽은 메시지의 offset을 커밋하여 관리
Flow
-
Producer 메시지 생성: 애플리케이션에서 Producer가 전달할 메시지(이벤트) 생성
-
Producer → Topic (Broker): Producer의 메시지를 특정 Topic으로 전송
Kafka Client 라이브러리 메시지를 해당 토픽의 Partition 중 하나로 라우팅 (Key 기준으로 해싱, 또는 라운드 로빈 방식)
이 Partition은 Broker에 저장된다.
- 메시지는 해당 Partition의 끝(append)에 순서대로 추가하고, 고유한 offset을 부여받음
- Topic이 Partition으로 나뉘어 Broker에 분산되어 저장 → Kafka 대용량 메시지 안정적 처리 및 저장이 가능함
-
Consumer Group에서 메시지 소비 준비: 여러 Consumer가 동일한 Consumer Group에 속해 특정 Topic 구독
-
Consumer → Topic (Broker): Consumer들 자신이 속한 Consumer Group에서 할당받은 Partition으로부터 메시지 순서대로 가져와 소비함(= Consumer도 Application 소속)
- Consumer Group 내 Consumer들이 서로 다른 Partition을 할당받아 동시에 메시지를 소비해 병렬 처리 구현
- Consumer 수가 Partition 수보다 많으면 일부 Consumer 유휴 상태(= 놀고있다)
- Consumer 수가 Partition 수보다 적으면 일부 Consumer 여러 Partition 소비(= 왔다갔다 출장? 잡스러운 동작)
- Offset 관리: 각 Consumer 자신이 어디까지 메시지를 읽었는지(offset) Kafka에 커밋(commit)해서 관리
장애 발생 시 → Consumer가 이전에 처리했던 메시지를 다시 처리하지 않고 마지막으로 커밋된 offset부터 메시지 다시 읽어옴
📓 프로젝트 구조 개선하기
🔹 결제 및 배송 시스템 구조도
현재 구조도
Kafka 메시지 처리 구조도
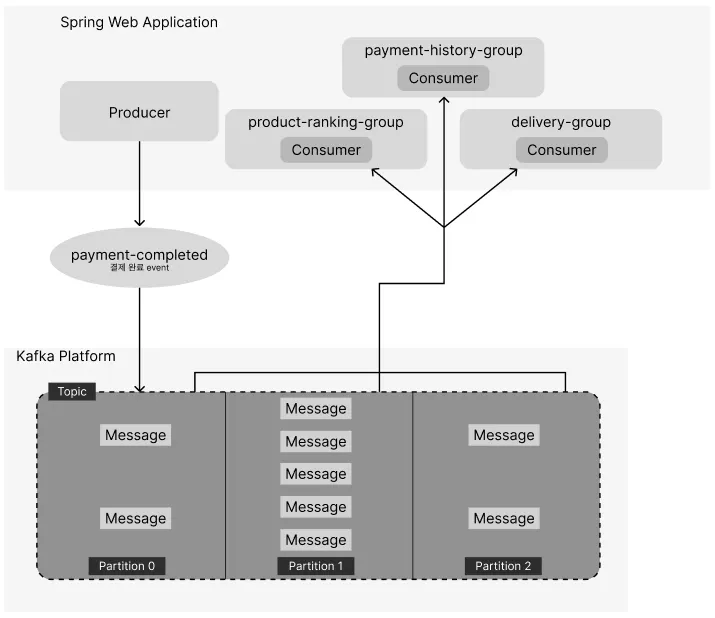
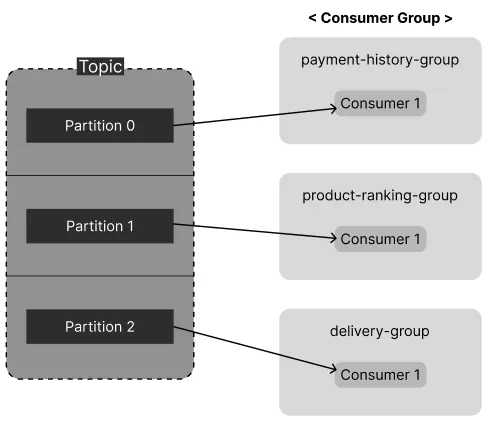
🔹 Focus(개선할 점 및 기대 효과)
1. Partition key rule 지정하기
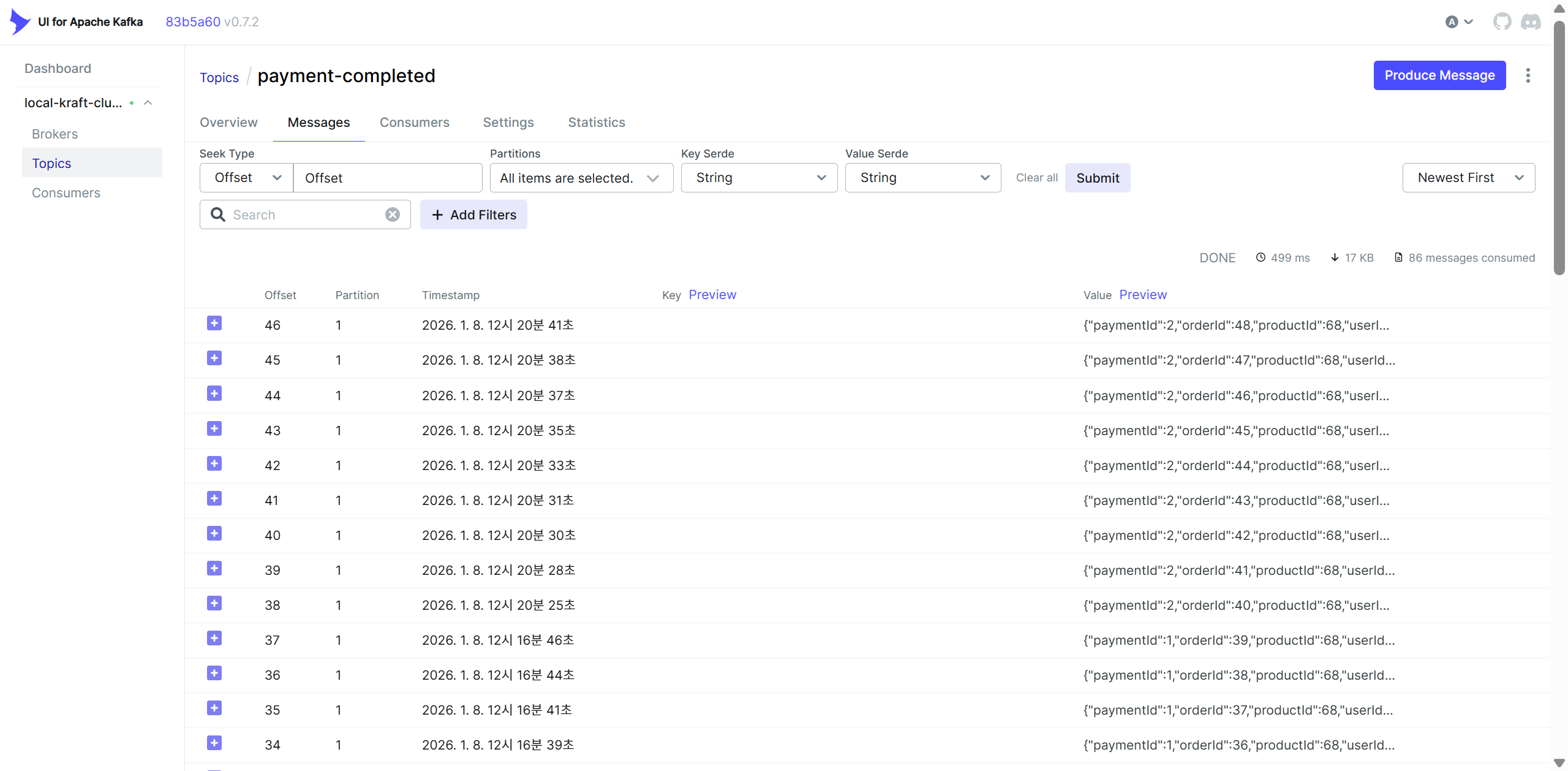
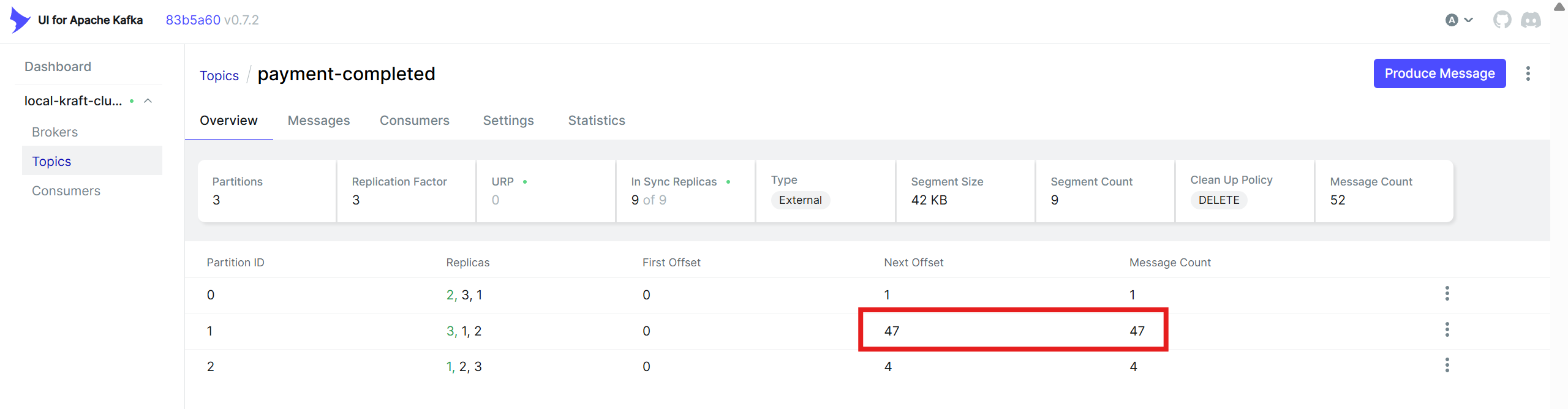
현재 보내고 있는 모든 이벤트 메시지가 Partition 1에서 처리되고 있다. Producer가 event를 전달해줄 때 따로 key를 지정해두지 않은 게 원인이니 Partition 1이 과로하지 않도록 분산시켜주면 성능이 좋아지지 않을까?
분산 처리 시 고려해야 할 점
-
같은 파티션 안에서만 순서를 보장할 수 있다.
지금 프로젝트에 설정해 둔 결제 기록(payment-history-group), 상품 랭킹(product-ranking-group), 배송(delivery-group) 모두 처리 순서보단 정보의 유무가 우선되니 충분히 분산 처리해도 된다고 생각한다. -
key 전략 정하기
기준으로 할 수 있는 Key는 어떤 게 있을까?
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class PaymentCompletedEvent {
private Long paymentId; // 결제 ID (PG사나 내부 결제 번호)
private Long orderId; // 주문 번호
private Long productId; // 상품 ID
private Long userId; // 사용자 ID
private Category category; // 카테고리 ID
private int quantity; // 결제된 상품 수량
private String paidAt; // 결제 완료 시각 (예: "2025-11-28T10:15:30")
}paymentId는 결제 아이디로 PG사와 연관성이 많기 때문에 다루기엔 영향이 커보인다.
orderId는 결제 1건과 보통 1건씩 연계되므로 적당해보인다.
productId는 여러 상품 정보를 포함할 수 있으므로 탈락.
userId도 사용자 기준으로 처리할 수 있으니 괜찮아보인다.
이 event의 경우 결제 완료를 의미하므로, 사용자보단 주문 중심으로 처리되도록 설정하는 게 좋겠다고 판단했다. 사용자가 주문을 취소할 경우 같은 주문 ID가 같은 파티션 내에서 처리되도록 설정하는 게 정보를 편하게 찾아낼 수 있을 것이다.
(이 경우, 사용자 ID도 똑같지 않나?라는 의문이 생기긴 하지만 커머스 플랫폼의 경우 구매자만 사용자인 게 아니기 때문에 주문 중심으로 가야 된다고 생각했다.)
결론: orderId를 key로 지정하기!
2. Consumer Group 당 Consumer 수 늘리기
현재 프로젝트 구조에선 Consumer Group마다 하나의 Consumer만 메세지를 처리하고 있어 처리 중인 Partition 외 나머지 두 Partition이 놀고있다. 이 두 놈들도 일을 시키기 위해 그룹마다 Partition 수와 같거나 작은 수로 Consumer를 늘려주면 처리 속도가 늘어날 것이다.
그래서 Consumer 수를 늘리는 방법을 검색해봤다.
내가 처음에 생각한 방식은 Consumer 1, 2, 3...이런 식으로 늘리기였다. 근데 Spring Kafka는 concurrency라는 걸 사용해서 Consumer Thread를 늘리는 방식으로 병렬 처리되도록 만들 수 있다고 한다.
- Consumer 개수 늘리기(물리적)
단순히 Spring Application을 여러 개(물론 파티션 수보다는 같거나 적게) 띄워 Consumer 개수를 늘리는 방식이다. 이 경우 Docker나 인스턴스 개수를 늘려야하기 때문에 단일 서버로 돌리고 싶은 내 입장에선 비용적으로 부담이라고 생각했다. - Parallel Consumer로 Consumer Thread 수를 늘리기(논리적)
하나의 애플리케이션 내에서@KafkaListener가 지정된concurrency숫자만큼의 스레드를 생성해내서 개별 Consumer처럼 사용할 수 있다.
여기서 내가 선택한 방식은 Consumer 자체가 아닌 Consumer Thread를 늘리는 방식이다. 인스턴스 수를 늘리는 것은 인프라와 관계가 있고 이 프로젝트의 목적은 Kafka의 메시지 처리 구조를 이해하는 게 주요 목적이니 굳이 비용을 많이 쏟을 필요가 없다. (아직 DLT를 도입하지 않았기 때문에)장애 처리의 위험성이 있지만 이 단점은 염두에 두고 하나의 애플리케이션에서 실행되도록 구조를 결정했다.
개선된 구조도
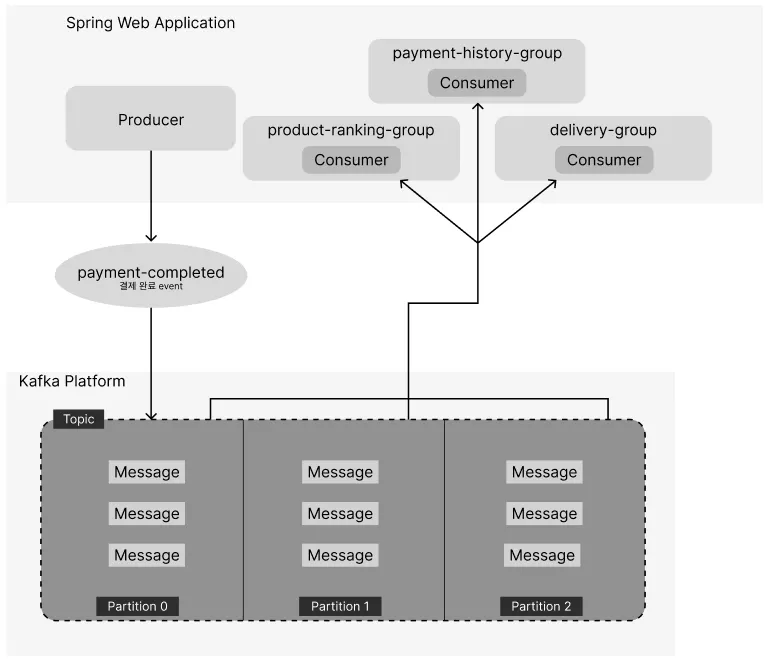
기존 구조에서 메시지가 각 파티션에 고루 전달되는 형태로 수정했다.
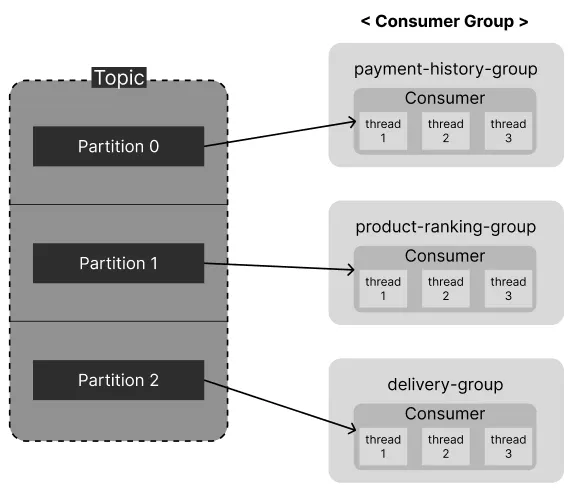
Consumer 안에서 각각 3개의 Thread가 생성되어 메시지를 Kafka에서 읽어와 설정해 둔 기능을 수행하는 구조를 표현하고 싶었다.
잘 전달되는지는 모르겠다...^^
구현 코드
이번에는 실습과 같이 진행하느라 커밋을 똑바로 못했기 때문에 수정된 코드를 아래에 붙이도록 하겠다.
@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public ConsumerFactory<String, PaymentCompletedEvent> productRankingConsumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "product-ranking-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
JsonDeserializer<PaymentCompletedEvent> deserializer = new JsonDeserializer<>(PaymentCompletedEvent.class);
return new DefaultKafkaConsumerFactory<>(
props,
new StringDeserializer(),
deserializer
);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, PaymentCompletedEvent> paymentKafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, PaymentCompletedEvent> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(productRankingConsumerFactory());
factory.setConcurrency(3);
return factory;
}
@Bean
public ConsumerFactory<String, PaymentCompletedEvent> paymentHistoryConsumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "payment-history-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
JsonDeserializer<PaymentCompletedEvent> deserializer = new JsonDeserializer<>(PaymentCompletedEvent.class);
return new DefaultKafkaConsumerFactory<>(
props,
new StringDeserializer(),
deserializer
);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, PaymentCompletedEvent> paymentHistoryKafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, PaymentCompletedEvent> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(paymentHistoryConsumerFactory());
factory.setConcurrency(3);
return factory;
}
@Bean
public ConsumerFactory<String, PaymentCompletedEvent> deliveryConsumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "delivery-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
JsonDeserializer<PaymentCompletedEvent> deserializer = new JsonDeserializer<>(PaymentCompletedEvent.class);
return new DefaultKafkaConsumerFactory<>(
props,
new StringDeserializer(),
deserializer
);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, PaymentCompletedEvent> deliveryKafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, PaymentCompletedEvent> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(deliveryConsumerFactory());
factory.setConcurrency(3);
return factory;
}
}@EnableKafka
@Configuration
public class KafkaProduceConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public ProducerFactory<String, PaymentCompletedEvent> eventProducerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(props);
}
@Bean
public KafkaTemplate<String, PaymentCompletedEvent> paymentCompletedEventKafkaTemplate() {
return new KafkaTemplate<>(eventProducerFactory());
}
}어디를 어떻게 변경했는지는 Github의 Javadoc으로 작성했으니 참고해주시면 감사합니다.

🔹 결과 및 회고
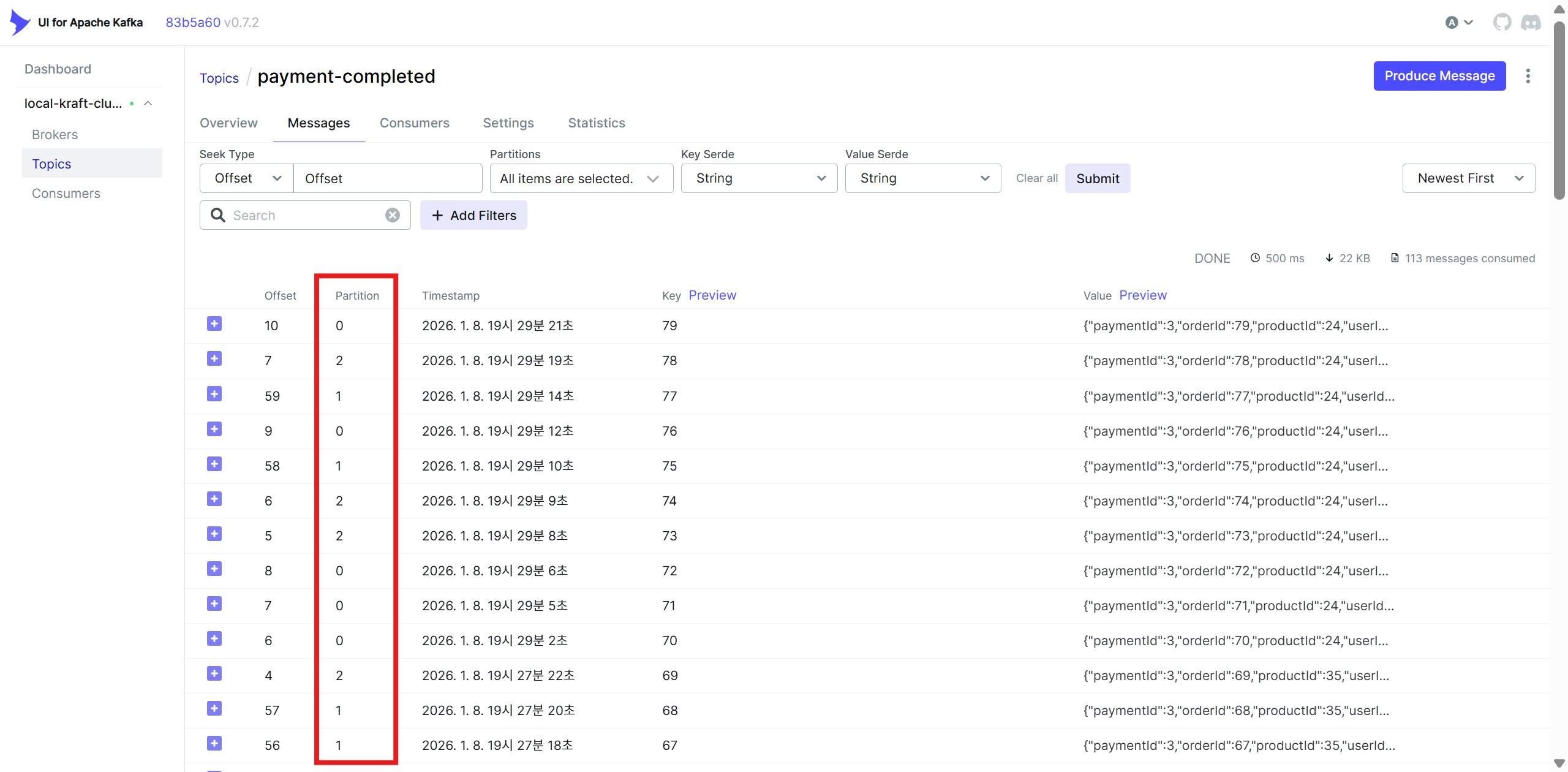
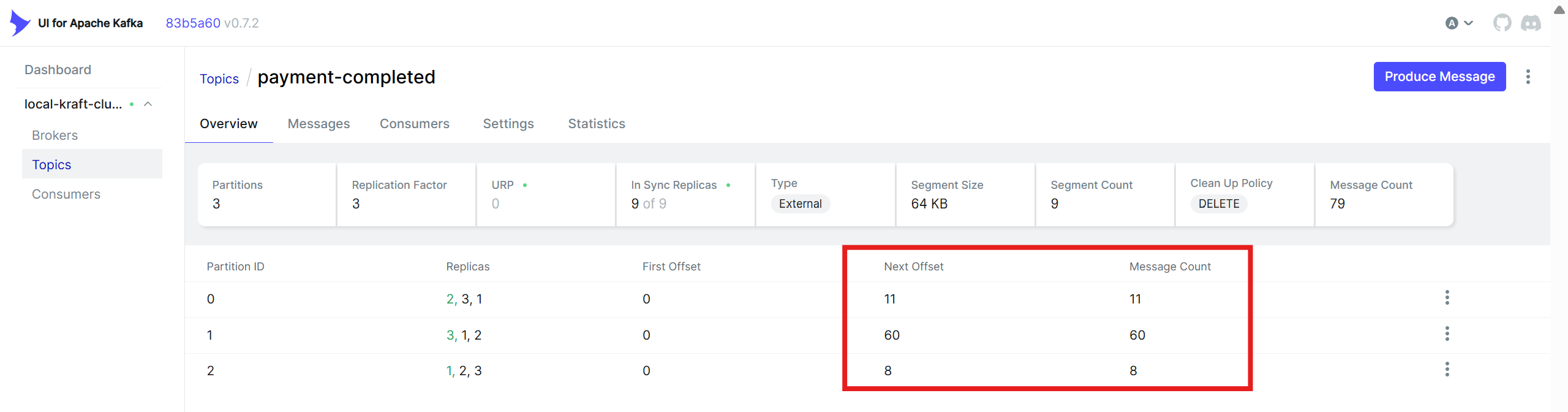
비교적 고르게 메시지가 분산되어 보내지는 것을 확인했다.
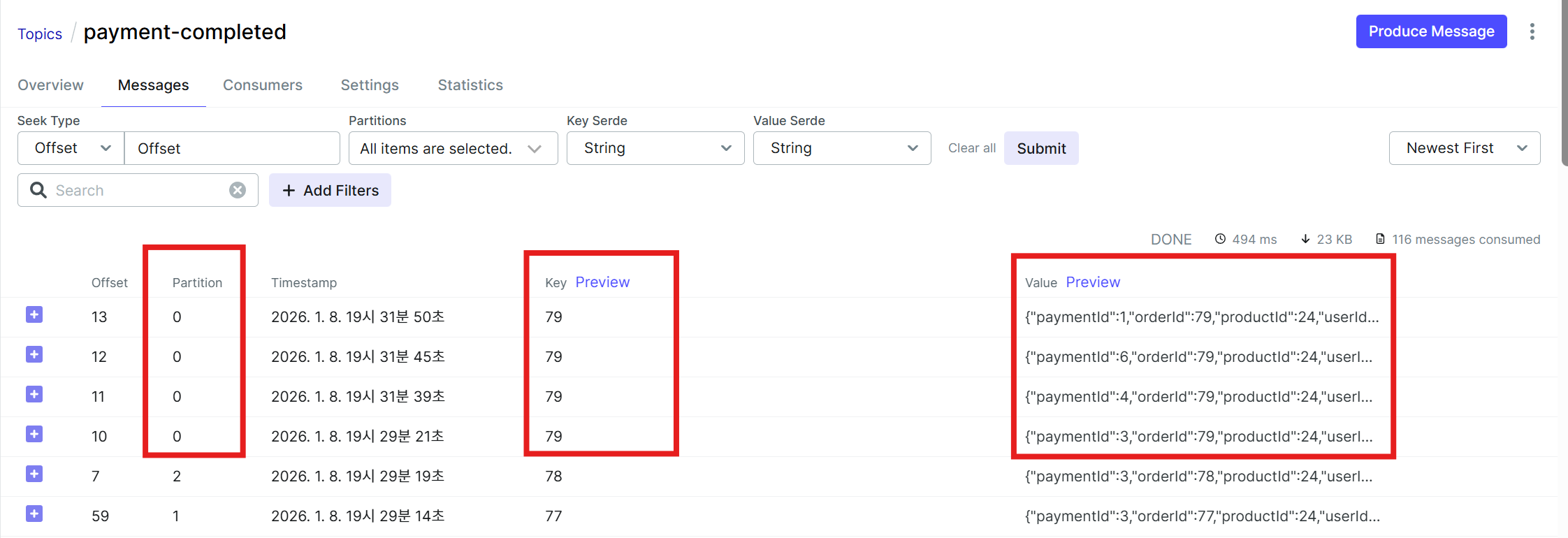
같은 orderId로 전달된 event는 같은 파티션으로 보내지고 있다.
concurrency 적용 방식은 수정하기 전에 로그로 성능 측정을 해두는 걸 잊어서 다른 테스트 방법을 찾아봐야 성능비교를 할 수 있겠다...
Kafka 내용이 단순한듯 보이면서 실제 사용해보기 어려운 분야라 익히는데 오래 걸렸다. 실제로 이 TIL도 Today가 아니라 Week 수준으로 이번 주 내내 임시글로 계속 조려진 상태다...보이지 않는 곳에서 열심히 쓰고 있었다고! 그만큼 머리에 새기려고 노력했으니 나중에 실무에서 사용하게 된다면 빛을 발하길 바랄 뿐이다✨
📚 참고 자료
