java 에서 사용되는 AtomicReference 에 대해 알아본다.
CPU Cache
CPU 성능이 발달하면서, CPU 코어와 메인 메모리 간 속도 차이가 현저히 증가하게 되었다.
CPU 코어와 메인메모리 간 데이터 접근 시간을 줄이기 위해, CPU 칩 내부나 바로 옆에 존재하는 작은 메모리 칩을 두어 cache 로 사용하게 되었는데, 이를 CPU cache 라고 한다.
자세한 설명은 아래 글 참고.
CPU Cache 란 무엇인가
Volatile
사진 출처: https://nesoy.github.io/articles/2018-06/Java-volatile
각 스레드가 다른 CPU 에 위치하고 다른 CPU cache 에서 쓰기와 읽기를 하는 경우, CPU cache 간 데이터 일관성이 깨지게 된다.
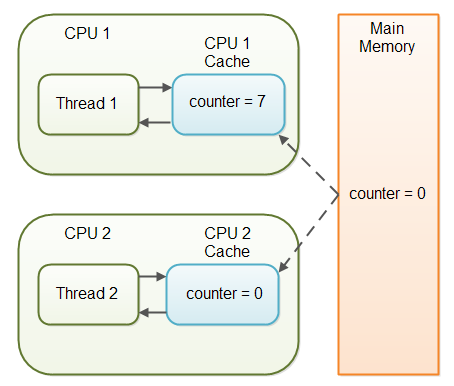
CPU cache 에서 값을 읽지 않고, 메인 메모리에 직접 접근하게 읽어 오는 것이 volatile 키워드.
즉, 메모리 가시성(visibility)은 보장한다.
하지만 여러 스레드에서 쓰기 연산을 한다면 여전히 동시성 문제는 존재.
아래 그림에서 두 스레드의 +1 쓰기가 동시성 문제 없이 모두 성공했다면, 최종값은 2가 되어야 한다.
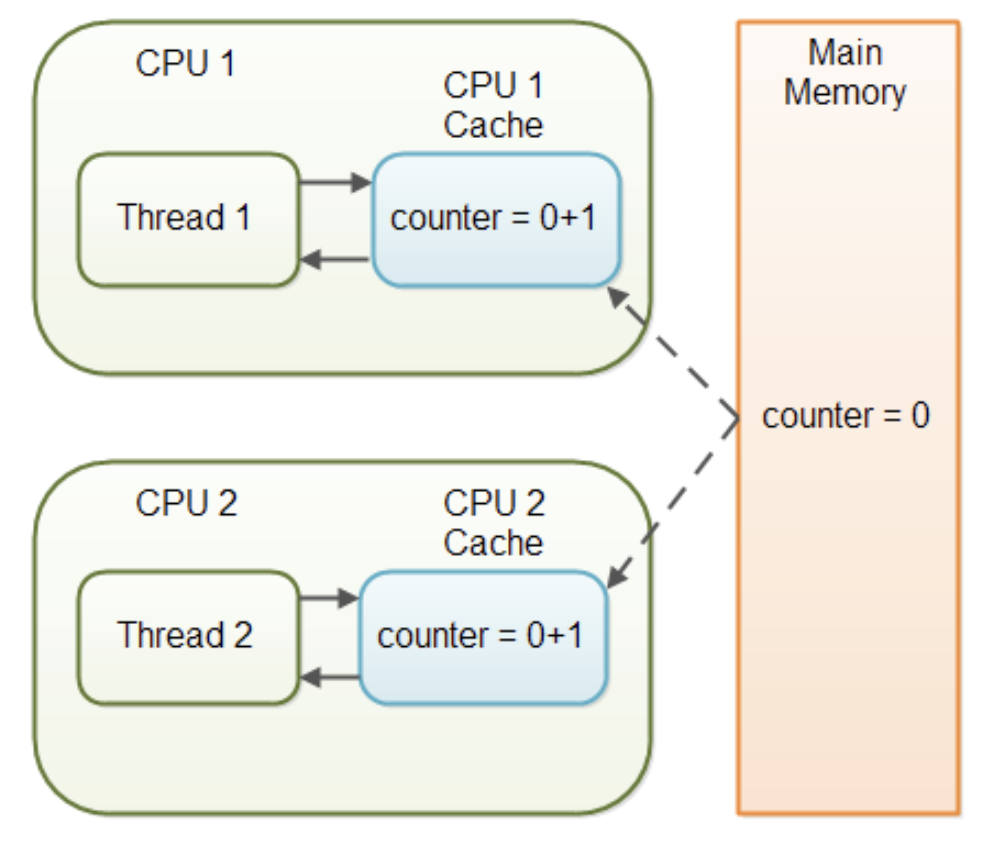
따라서 volatile 을 사용할 때, 하나의 쓰레드에서만 쓰기를 하는 경우에만 동시성 문제가 발생하지 않음.
자세한 설명은 아래 글 참고.
Java volatile이란?
Syncronized
synchronized (lockObj) {
// 여기는 동시에 한 쓰레드만 실행 가능
doSomething();
}Syncronized의 기능
1) 상호 배제(mutual exclusion)
syncronized키워드는 락(lock) 을 사용하여 한 번에 하나의 스레드만 메소드에 진입하도록 보장한다.- 다른 스레드는 락이 풀릴 때까지 block되거나 spin로 있다가 깨워짐
- 🧱 Block (블록 / 수면 대기)
- 현재 쓰레드를 잠재운다 (sleep / park)
- OS 스케줄러 입장에서 “이 쓰레드는 당분간 쓸 일 없음” 상태로 바뀜
- CPU를 다른 쓰레드에게 양보하고,
- 나중에 누가 깨워줄 때까지 기다리는 방식
- 🌀 Spin (스핀 / 바쁜 대기, busy-wait)
- 쓰레드를 안 재우고, 계속 돌면서 체크
- “락 풀렸나? 풀렸나?” 를 루프 돌며 계속 확인
- CPU를 계속 소비하지만, 락이 곧 풀릴 경우 매우 빠르게 이어서 실행 가능
- 🧱 Block (블록 / 수면 대기)
2) happens-before
java에서 말하는 happens-before는 다음을 의미한다.
작업 A에서 한 메모리 변경이, 작업 B가 실행될 때까지 반드시 보일 때, A happens-before B라고 한다.
happens-before가 없으면, A에서 값을 바꿔도, B에서 옛 값이 보이거나, 아예 안보일 수도 있음
메모리 가시성을 보장하면서, 쓰기 연산의 동시성 문제도 해결한다.
Syncronized의 락 획득 과정
java의 lock은 객체 헤더 기반으로 제공 됨.
synchronized(lockObj)는 바이트코드로 들어가면 아래와 같이 lockObj의 락을 획득/해제 함.
monitorenter // lockObj의 락 모니터 획득
...
monitorexit // lockObj의 락 모니터 해제이 동작이 헤더에서 어떻게 이루어지는지 조금 더 깊게 들어가보자.
각 객체마다 자기 전용 락 모니터가 헤더의 mark word부분에 존재하고, synchronized 코드가 이 모니터를 획득하여 동작하는 형태.
Mark Word (normal):
64 39 8 3 0
[.......................HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH.AAAA.TT]
(Unused) (Hash Code) (GC Age)(Tag)mark word는 위와 같이 생겼고, 마지막 Tag 2비트로 락 모니터 상태를 나타냄
| lock 비트(하위 2비트) | 상수 이름 | 의미 |
|---|---|---|
00 (0) | locked_value | thin lock(경량 락) 상태. ptr가 스택의 BasicLock를 가리킴 (stack-locked) |
01 (1) | unlocked_value | 일반 객체 헤더 (unlocked). hash/age 등이 그대로 들어있는 상태 |
10 (2) | monitor_value | inflated monitor 상태. ptr가 ObjectMonitor를 가리킴 (무거운 모니터 락) |
11 (3) | marked_value | GC markSweep에서만 사용하는 마킹 상태 (정상 실행 시에는 안 나와야 함) |
락이 잡히면 mark word에 있던 hash, gc age 비트를 어딘가에 백업해두고, mark word에는 ptr로 lock객체를 가리키도록 바뀜. lock이 풀리면 백업에서 mark word를 원복
Mark Word (locked):
64 0
[ 포인터 상위 비트 .................. ][ TT ]- 어딘가
- thin -> 스레드 스택 위의 BasicLock.displaced_header
- inflated -> 힙 위의 ObjectMonitor._header
jdk21에선 다음 단계로 락을 획득
1. 경량 락(thin lock) 경로로 시도
2. 경합 심하면 **무거운 락(infalted lock)로 승격
thin lock: 락을 잡을 때, 경합이 심하지 않다면 CAS 방식으로 OS 커널 호출 없이 유저 모드에서 끝내어 매우 빠른 방식
1. 객체의 mark word를 읽어본다.
2. 아무도 안잡고 있는 상태(unlocked)면 CAS로 lock 소유자를 현재 스레드로 바꾸려고 시도
3. CAS 성공하면 현재 스레드가 락 소유자가 되고, 스택 위에 BasicLock에 원래 mark word를 백업하고 ptr를 이 BasicLock으로 설정. 재진입(reentrant)시에는 카운트만 증가(스택에 새로운 BasicLock를 만들고 해당 객체의 displaced_header 0로)
4. CAS 실패하면 재시도하다가, inflate lock 으로 승격
CAS 재시도로 낙관적 락이라고 헷갈릴 수 있겠지만, lock을 잡는 것에 대해 CAS를 사용한 것이기에 여전히 비관적 락이다.
inflated lock
1. JVM이 힙에 ObjectMonitor 구조체를 생성
- ObjectMonitor에서 관리되는 정보
- owner (현재 락 소유자),
- EntryList (락을 얻으려고 대기 중인 쓰레드 목록),
- WaitSet (wait() 호출한 쓰레드 목록),
- 재진입 카운트 등…
- lock을 얻으면 mark word를 ObjectMonitor에 백업하고 이 구조체를 가르키는 ptr로 변경.
- 락을 못 얻은 스레드는, spin으로 후에도 안되면 park()같은 OS수준 블로킹을 통해 block.
- 락이 풀릴 때, 재진입 카운트가 0이 되면,EntryList에서 하나를 골라 깨우고(unpark) 락을 넘김
단점
하지만 하나의 스레드가 락을 획득하면, 해당 메서드에 접근한 다른 메서드들은 일시 중단되고 성능의 타격을 입는다.
락의 비용은 생각보다 꽤나 비싸다.
1. 락을 획득하지 못하면 유휴상태가 된다.
2. 스레드 스케줄링 비용이 발생한다.
- 스레드가 락을 획득하지 못하면 스레드의 상태 변경이 일어난다.(일시정지, 재개).
- 스레드의 상태 변경을 위해, 컨텍스트 스위칭이 유발되고 이를 위한 스레드 스케줄링 비용이 발생한다.
Kotlin에서
kotlin 에서 syncronized 를 사용하는 것보다, @Volatile, Mutex 컴비네이션으로 사용하는 것이 좀더 coroutine 친화적이라고 한다.
| 구분 | synchronized (JVM Monitor) | Mutex (kotlinx.coroutines) |
|---|---|---|
| 락 획득 방식 | 스레드를 블로킹 하며 모니터를 점유 | 코루틴을 중단(suspend) 하며 협력적 락 |
| suspend 호출 | 금지 — 모니터 안에서 withContext, delay 등은 호출할 수 없음 → 컴파일 에러 | withLock { … } 블록 안에서 자유롭게 suspend 호출 가능 |
| 스레드 수 | 락을 잡은 동안 실제 스레드가 놀고 있음 → 스레드 소비 증가 | 스레드 반환 → 다른 코루틴이 재사용 |
| 컨텐션 시 영향 | JVM 레벨 경쟁, OS 스케줄러로 넘어가므로 지연 커질 수 있음 | 동일 디스패처의 코루틴끼리는 협력적으로 스케줄링 |
자세한 설명은 아래 글 참고
AtomicReference 에 대하여
AtomicReference
하나의 값(single value)에 대해 lock-free thread-safe promgramming 을 제공한다.
기본적으로 값은 volatile 로 선언된다.(메모리 가시성이 보장된다.)
AtomicReference.compareAndSet() 은 이 값에 대해 CPU-level 에서 제공하는 atomic 한 연산 CAS(CompareAndSet) 를 호출한다. CAS 는 atomic 하여서, 읽고 쓰는 것이 쪼갤 수 없는 연산으로 이루어져있다. CAS 중에 다른 CAS가 요청되면 실패한다. 고로, CAS의 동시 호출 중에 어떤 호출에서 stale 한 값을 읽을 가능성은 없고 thread-safe 하다.
낙관적 락을 무한루프와 compareAndSet() 을 함께 구현해 compareAndSet 이 성공할 때까지 시도하도록 구현할 수도 있다.
대략 코드상으로 다음과 같다.
fun countExample() {
val value = AtomicReference<Int>(0)
do {
val cur = value.get()
val result = value.compareAndSet(cur, cur+1)
} while(result == false) // compareAndSet 에 실패했다면 반복한다.
}락을 획득하는 과정에서 발생하는 비용이 더 비싼 연산이기 때문에, 락을 사용하는 것보다 실패하고 몇 번 재시도 하는 게 훨씬 성능이 나을 수 있다. 다만, CAS로 재시도하는 연산의 비용이 크다면, 몇 번의 재시도가 오히려 락을 획득하는 것보다 더 큰 비용을 치룰 수 있다. 때에 따라 다를 수 있으므로, 언제나 낙관적 락이 비관적 락보다 성능이 좋다곤 할 수 없다고 한다.
이 글에선 다음과 같은 기준을 제시한다.
- critical section <
100ns+ 낮은 경쟁(2~4 threads) → 스핀락이 유리할 수 있음 (컨텍스트 스위치보다 스핀이 싸다). 100ns ~ 10µs+ 중간 경쟁 → 짧게 스핀 후 잠드는 하이브리드/어댑티브 뮤텍스(예: glibc adaptive, PostgreSQL LWLock)- critical section >
10µs또는 높은 경쟁 → 일반 뮤텍스 권장(스핀은 CPU 낭비).
HowTech - 실시간/지연 상한이 중요한 경우 → PREEMPT_RT + PI 뮤텍스 쪽을 권장
