다중 컬럼 인덱스(Multiple-Column indexes)
문법
CREATE INDEX [index name]
ON [Table name]([column1, column2, column3, ..])
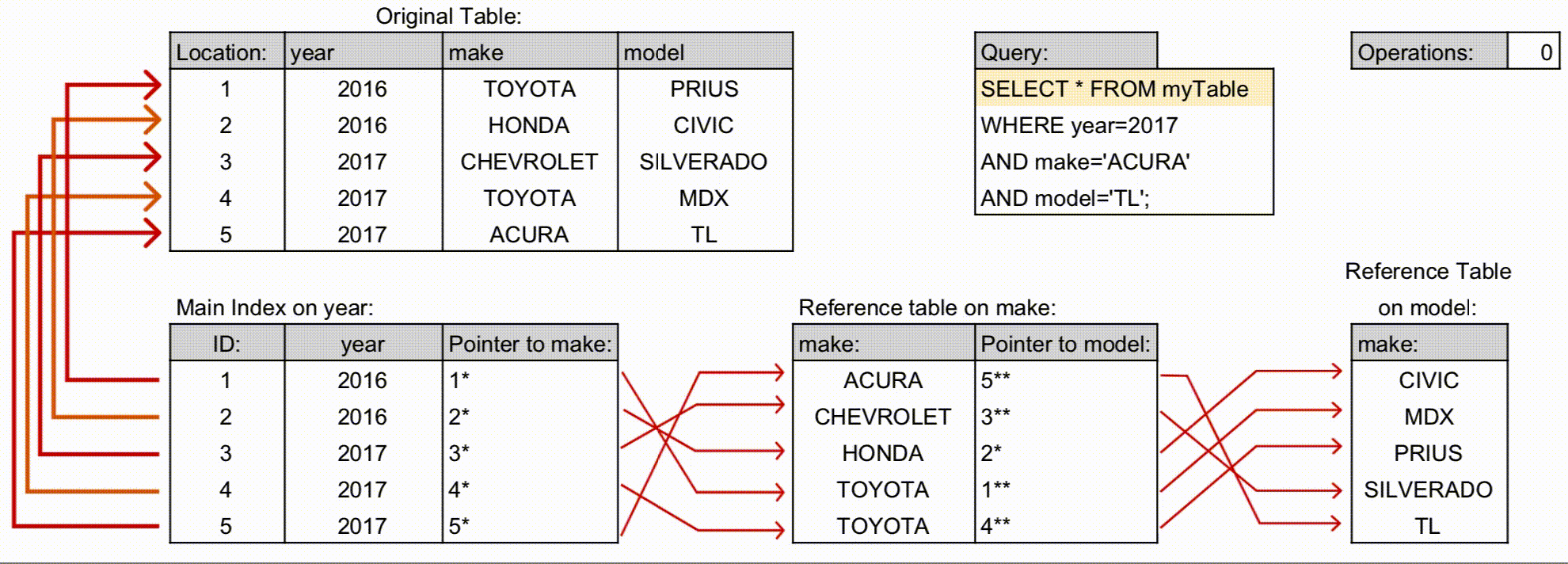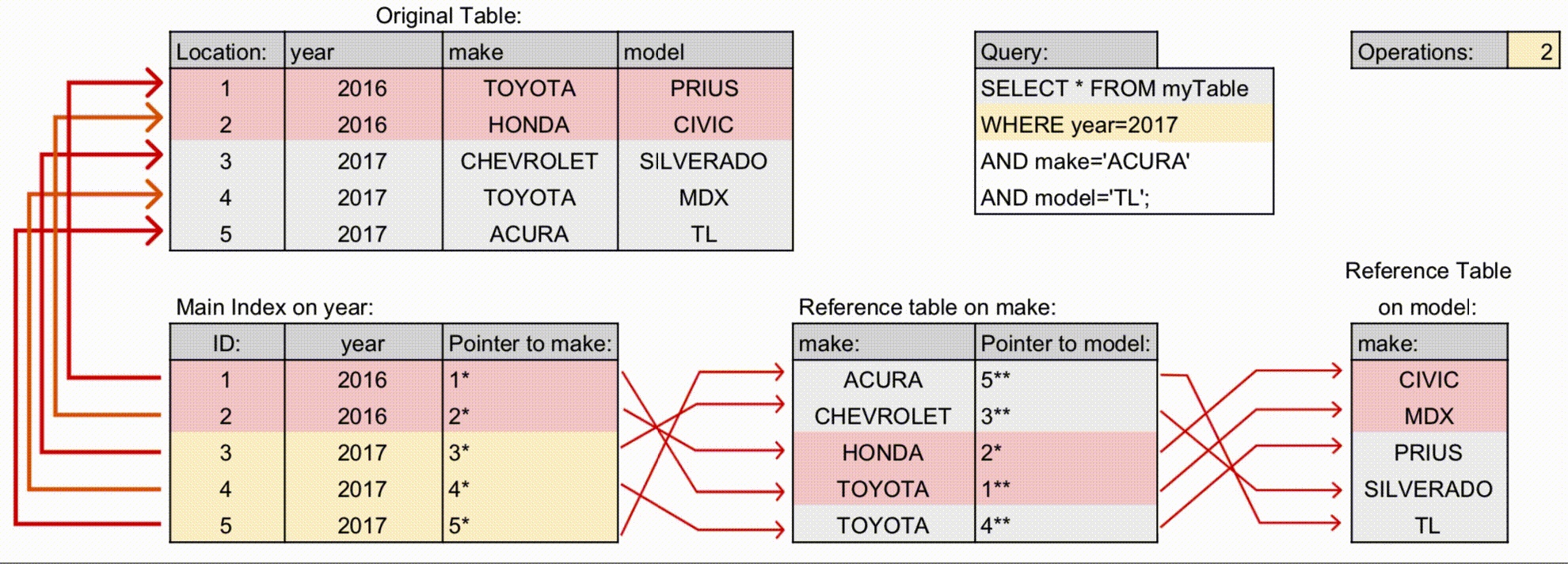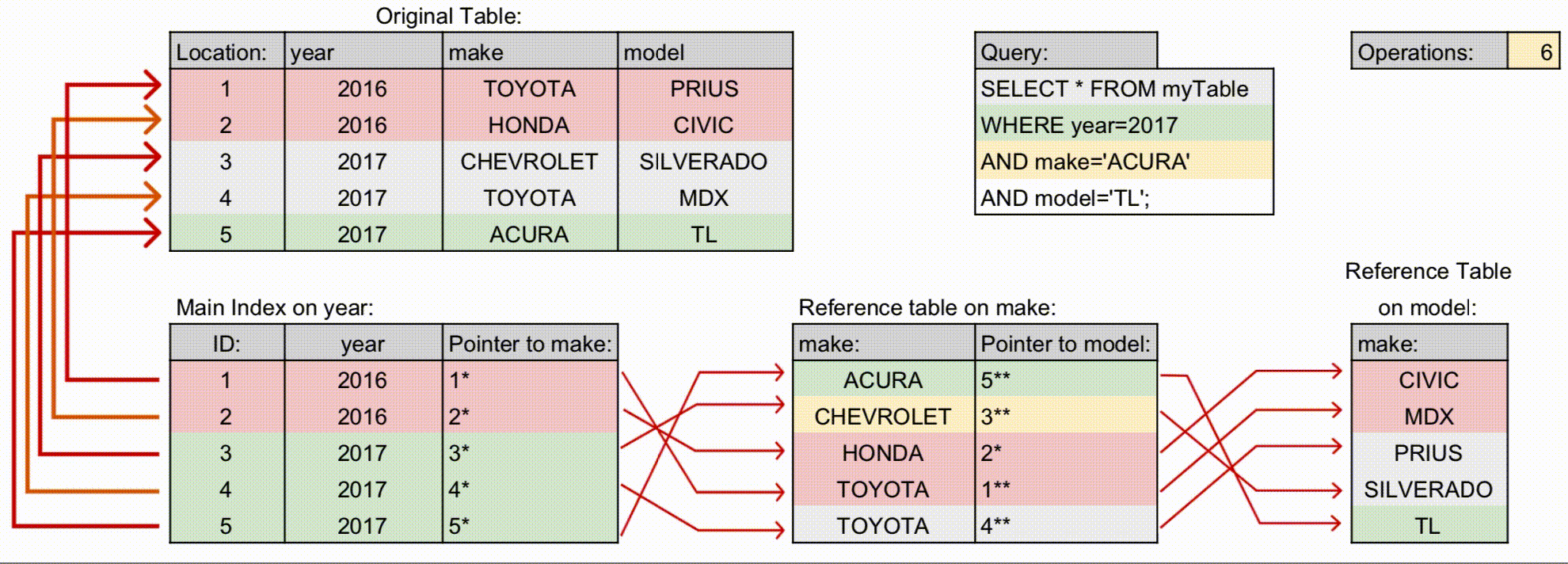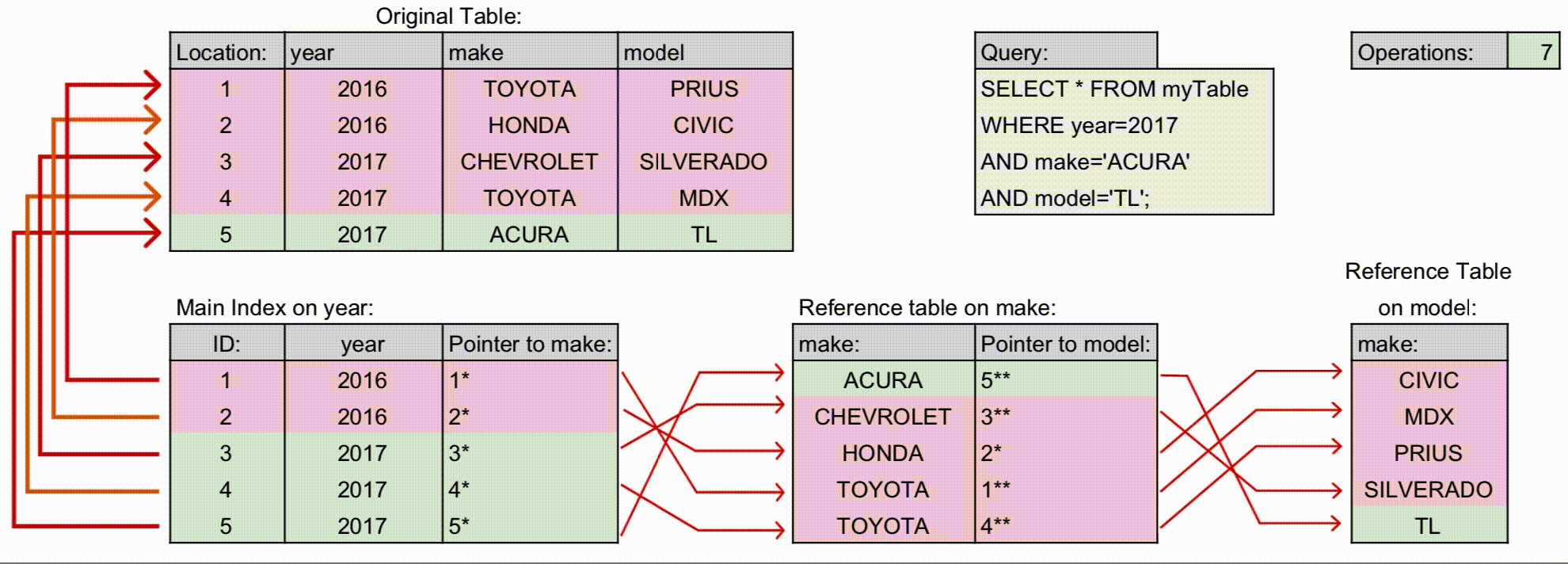
구조
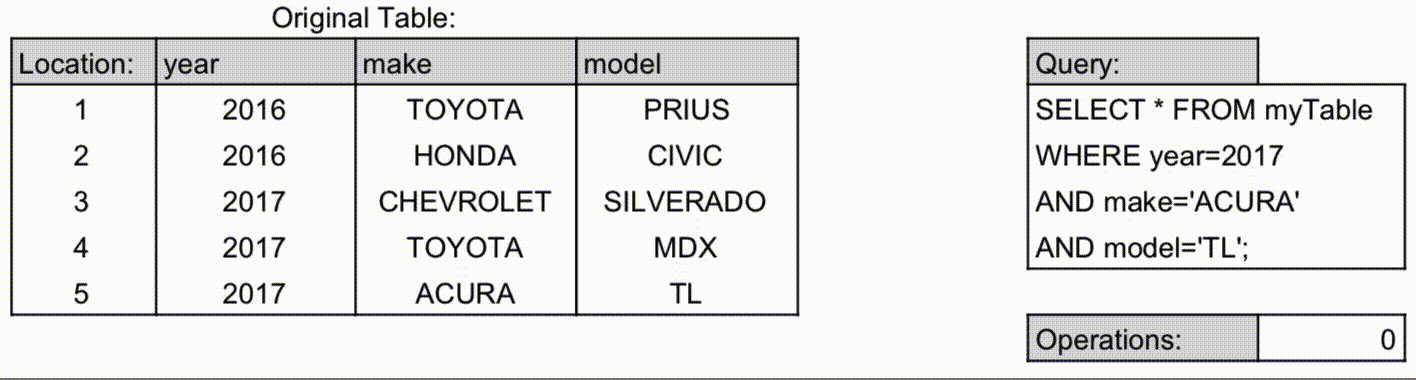
- 인덱스가 계층 구조로 정렬되어 있으며, 순서쌍에서 왼쪽에 위치할수록 상위계층입니다.
- 위 그림을 보시면, 각 컬럼별로 정렬되어 있으며, 인덱스 생성 선언문 왼쪽에 있는 컬럼의 인덱스가 그 오른쪽에 위치한 컬럼을 포인터로 연결하며, 이것이 연쇄적으로 이루어져서 하나의 인덱스를 생성하는 것을 볼 수 있습니다.
- 계층 구조에 따라 선언된 컬럼의 순서대로만 포인터에 엑세스 할 수 있습니다.
- 위 예시에서 인덱스를 사용가능한 조회 쿼리는 다음과 같습니다. 컬럼의 순서는 쓰여진 순서와 반드시 일치해야 합니다.
- year
- year, make
- year, make, model
주의 사항
- 컬럼의 순서를 신중히 결정해야 합니다.
- 구체적으로, equal(=) 조건 처럼 적은 데이터를 조회하는 컬럼을 인덱스 앞 쪽에 설정하고, 범위 검색과 같이 개수가 많은 데이터를 조회하는 컬럼을 뒤쪽에 설정하는 것이 좋습니다.
- 단일 컬럼 인덱스보다 더 비효율적으로 INSERT/UPDATE/DELETE 작업을 수행하니, 되도록 수정되지 않는 컬럼을 선택해야 합니다.
언제 사용하면 좋을까?
- 데이터를 조회할 때 여러개의 컬럼을 사용해야 하는 경우
- A, B 컬럼을 바탕으로 데이터 조회를 자주 하는 경우를 생각해보면...
- A, B 컬럼을 각각 단일 인덱스로 만드는 경우, A 컬럼과 B 컬럼을 보고 둘 중에 어떤 컬럼이 빠르게 검색되는지 판단하고 더 빠른 쪽을 먼저 검색하고 그 다음 컬럼을 검색합니다.
- (A, B)를 다중 컬럼 인덱스로 설정하는 경우, 인덱스 안에 A, B 정보가 있으므로 바로 검색이 가능하여 위의 경우보다 빠릅니다.
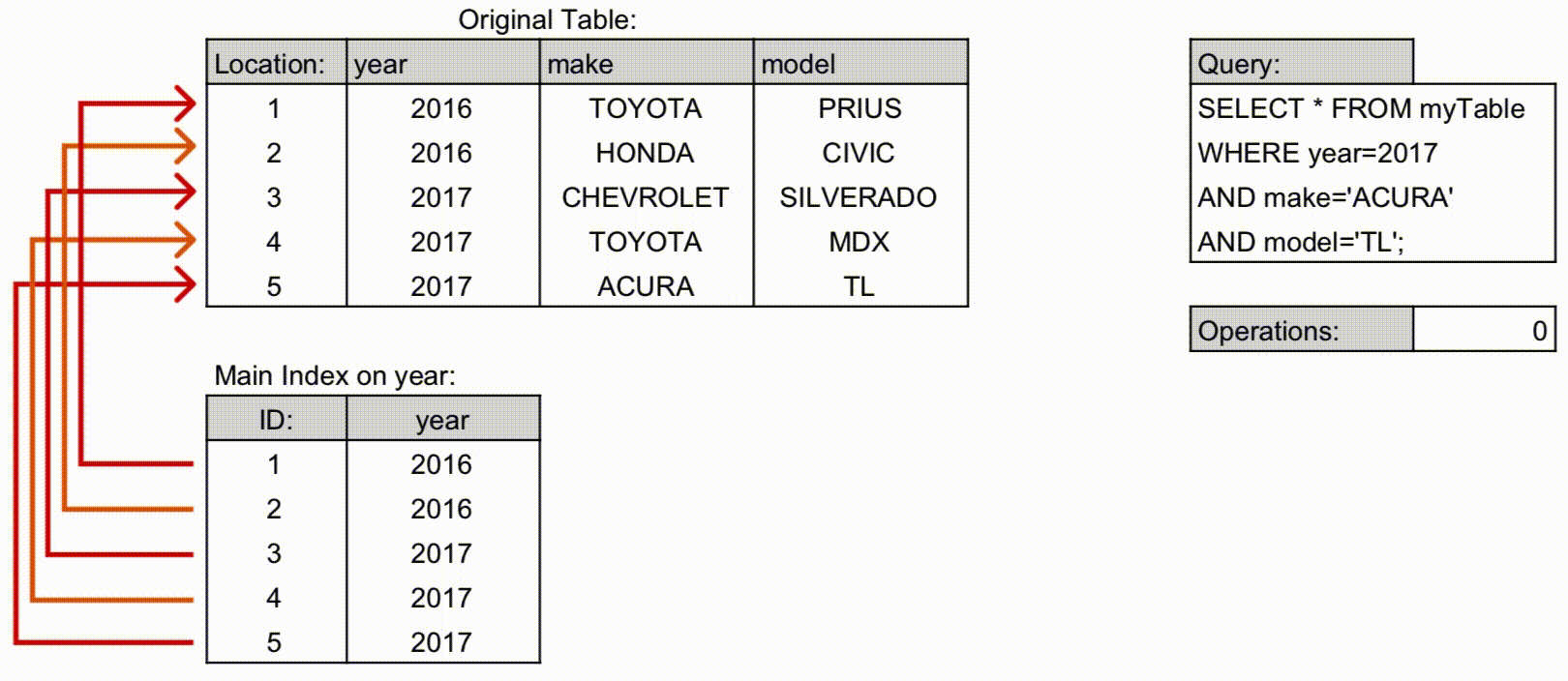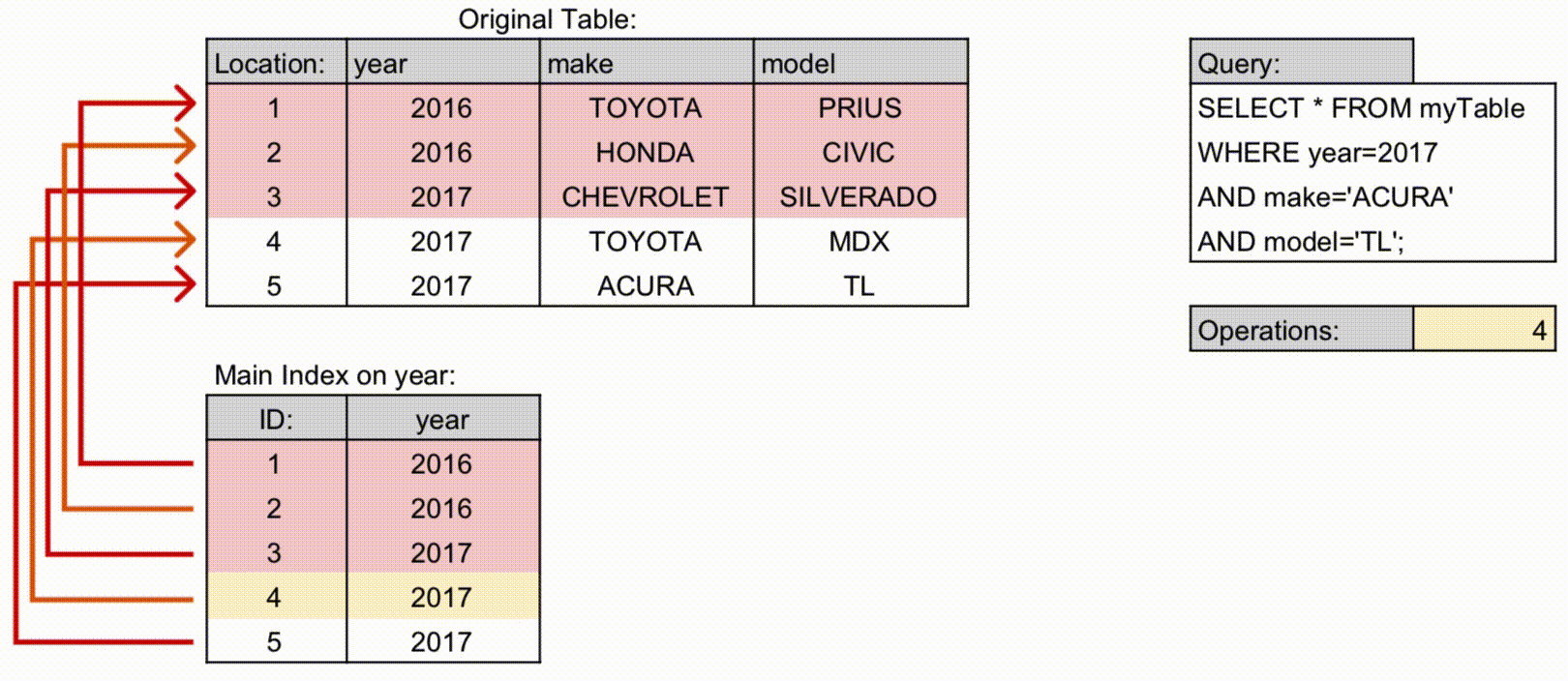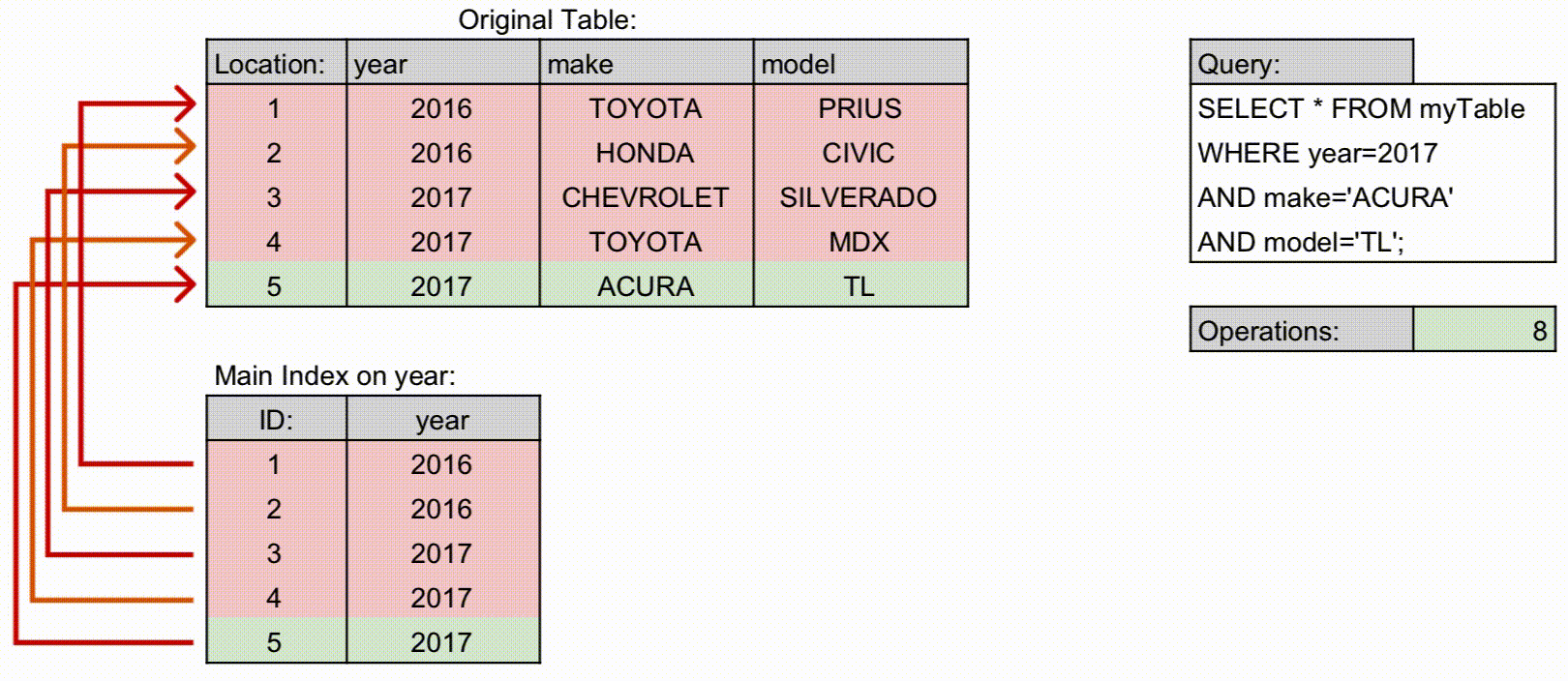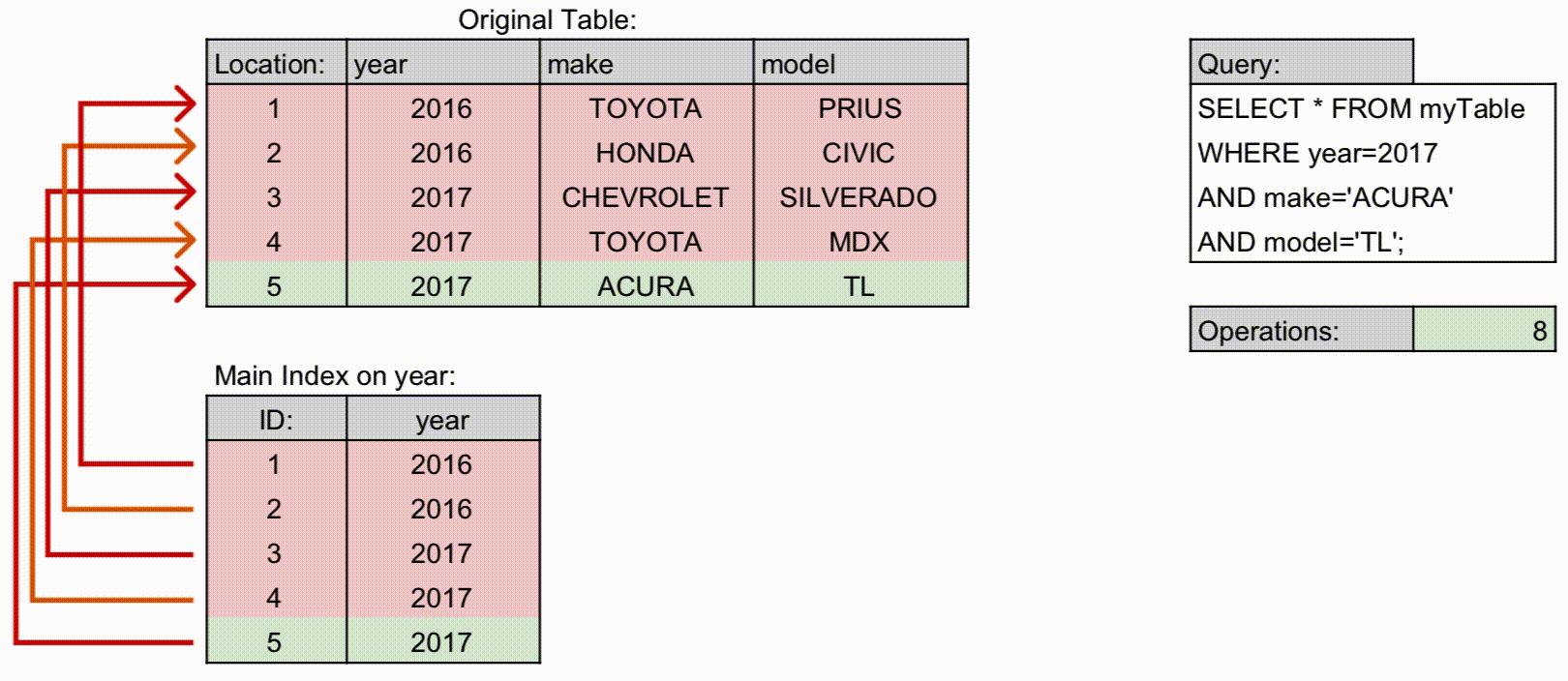
- 예시: Operations가 다중 컬럼 인덱스에서 더 적게 사용합니다.
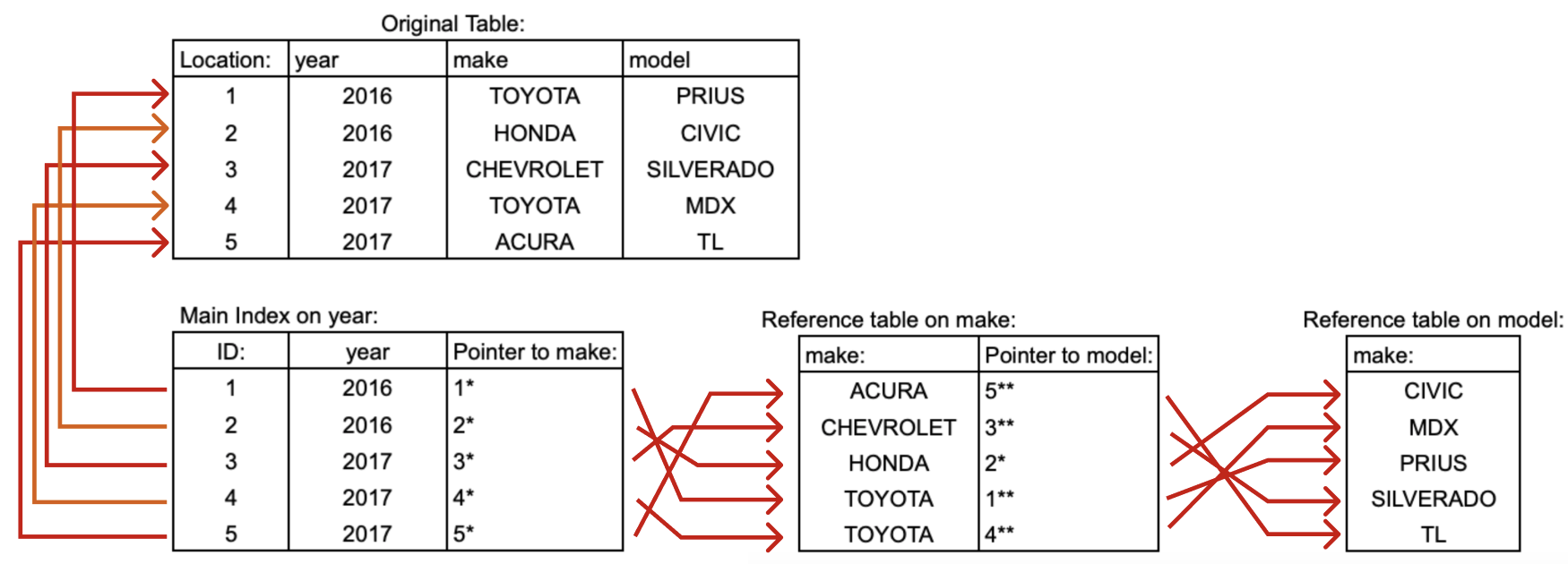
- 기존 인덱스를 사용하는 경우
- 다중 컬럼 인덱스를 사용하는 경우
참고 문헌