
오늘은 지금 진행 하고있는 프로젝트에 OCR기능을 추가하고 싶어서 찾아보았던 OCR인 Tesseract OCR 을 직접 코랩에서 실습해보며 간단한 사용법을 알아보려 한다!
Tesseract OCR?
테서랙트는 Apache2.0 라이선스에 사용할 수 있는 오픈 소스 텍스트 인식 엔진이다. UTF-8를 지원하며 100개 이상의 언어를 지원한다. 사용시 단점으로는 GPU:-1 즉 GPU를 사용하지 않아 속도가 느리다.
Python Tesseract?
Python Tesseract는 Google의 Tesseract-OCR Engine을 래핑한 라이브러리이다!
필수 프로그램 다운로드
Tesseract 다운로드
!sudo apt install tesseract-ocr
pytesseract 다운로드
!pip install pytesseract

import
import pytesseract
import cv2
import os
from PIL import Image
from google.colab.patches import cv2_imshow

code 실행부
#이미지를 불러와 gray 스케일로 변환해 준다.
image = cv2.imread('numbers.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#pytesseract에서는 numpy array를 읽지 못하고 file을 읽기 때문에 os로 파일을 불러들여야 한다.
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
#pytesseract의 image to string을 써준다.
#숫자니까 lang = 'None'으로
text = pytesseract.image_to_string(Image.open(filename), lang = None)
os.remove(filename)
#결과를 보자.
print(text)
cv2_imshow(image)결과
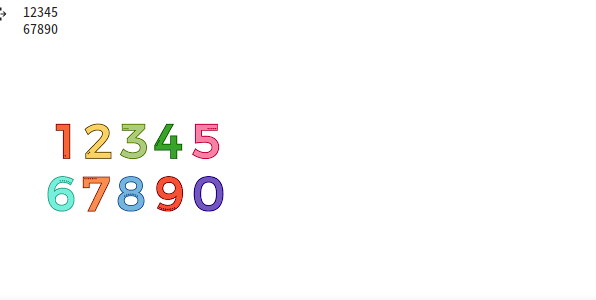
상당히 만족스러운 결과가 출력 되었음을 알 수 있다! :)

그저 그런 개발자가 되지 않겠습니다.
코드하고 설명 잘 읽어보았습니다!
혹시 OCR로 한글이나 알파벳도 인식이 가능할까요???