
이번 시간에는 정규 표현식 모듈 함수 예제를 실습해볼 예정이다!
Regular Expression moduel 함수
re.match() 와 re.search()의 차이
search()가 정규 표현식 전체에 대해서 문자열이 매치하는지를 본다면, match()는 문자열의 첫 부분부터 정규 표현식과 매치하는지를 확인합니다. 문자열 중간에 찾을 패턴이 있더라도 match 함수는 문자열의 시작에서 패턴이 일치하지 않으면 찾지 않습니다.

위 경우 정규 표현식이 ab. 이기때문에, ab 다음에는 어떤 한 글자가 존재할 수 있다는 패턴을 의미합니다. search 모듈 함수에 kkkabc라는 문자열을 넣어 매치되는지 확인한다면 abc라는 문자열에서 매치되어 Match object를 리턴합니다.match 모듈 함수의 경우 앞 부분이 ab.와 매치되지 않기때문에, 아무런 결과도 출력되지 않습니다. 하지만 반대로 abckkk로 매치를 시도해보면, 시작 부분에서 패턴과 매치되었기 때문에 정상적으로 Match object를 리턴합니다.
re.split()
split() 함수는 입력된 정규 표현식을 기준으로 문자열들을 분리하여 리스트로 리턴합니다. 토큰화에 유용하게 쓰일 수 있습니다. 공백을 기준으로 문자열 분리를 수행하고 결과로서 리스트를 리턴해봅시다.

이와 유사하게 줄바꿈이나 다른 정규 표현식을 기준으로 텍스트를 분리할 수도 있습니다.


re.findall()
findall() 함수는 정규 표현식과 매치되는 모든 문자열들을 리스트로 리턴합니다. 단, 매치되는 문자열이 없다면 빈 리스트를 리턴합니다. 임의의 텍스트에 정규 표현식으로 숫자를 의미하는 규칙으로 findall()을 수행하면 전체 텍스트로부터 숫자만 찾아내서 리스트로 리턴합니다.

입력 텍스트에 숫자가 없다면 빈 리스트를 리턴하게 됩니다.

re.sub()
sub() 함수는 정규 표현식 패턴과 일치하는 문자열을 찾아 다른 문자열로 대체할 수 있습니다. 아래와 같은 정제 작업에 많이 사용되는데, 영어 문장에 각주 등과 같은 이유로 특수 문자가 섞여있는 경우에 특수 문자를 제거하고 싶다면 알파벳 외의 문자는 공백으로 처리하는 등의 용도로 쓸 수 있습니다.
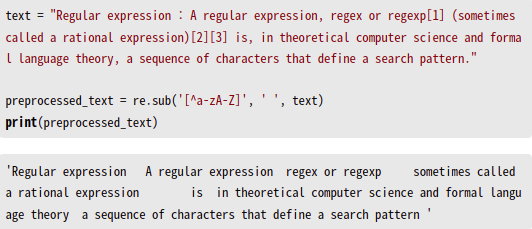
정규 표현식 텍스트 전처리 예제

'\s+'는 공백을 찾아내는 정규표현식입니다. 뒤에 붙는 +는 최소 1개 이상의 패턴을 찾아낸다는 의미입니다. s는 공백을 의미하기 때문에 최소 1개 이상의 공백인 패턴을 찾아냅니다. split은 주어진 정규표현식을 기준으로 분리하므로 결과는 아래와 같습니다.

공백을 기준으로 값이 구분되었습니다. 해당 입력으로부터 숫자만을 뽑아온다고 해봅시다. 여기서 \d는 숫자에 해당되는 정규표현식입니다. +를 붙이면 최소 1개 이상의 숫자에 해당하는 값을 의미합니다. findall()은 해당 표현식에 일치하는 값을 찾아냅니다.

정규 표현식을 이용한 토큰화
NLTK에서는 정규 표현식을 사용해서 단어 토큰화를 수행하는 RegexpTokenizer를 지원합니다. RegexpTokenizer()에서 괄호 안에 하나의 토큰으로 규정하기를 원하는 정규 표현식을 넣어서 토큰화를 수행합니다. tokenizer1에 사용한 \w+는 문자 또는 숫자가 1개 이상인 경우를 의미합니다.
tokenizer2에서는 공백을 기준으로 토큰화하도록 했습니다. gaps=true는 해당 정규 표현식을 토큰으로 나누기 위한 기준으로 사용한다는 의미입니다. 만약 gaps=True라는 부분을 기재하지 않는다면, 토큰화의 결과는 공백들만 나오게 됩니다. tokenizer2의 결과는 위의 tokenizer1의 결과와는 달리 아포스트로피나 온점을 제외하지 않고 토큰화가 수행된 것을 확인할 수 있습니다.

