[인공지능사관학교: 자연어분석A반] 기업연계 프로젝트 20일차
프로젝트 관련 공부
자바스크립트
https://ssocoit.tistory.com/190
리액트
https://www.youtube.com/watch?v=dvQMbg7n6mY&list=PLZKTXPmaJk8J_fHAzPLH8CJ_HO_M33e7-&index=2
타입스크립트
https://react.vlpt.us/using-typescript/
- 리액트 + 타입스크립트 공부 자료 정리
- 컴파일 단계에서 에러를 알려주는 타입스크립트를 사용해 형변환 관련 버그를 미리 방지
- 자바스크립트는 선언할 때 타입을 지정하지 않기 때문에, 동작하면서 내가 모르는 사이에 형변환이 되어 있는 부분이 예상치 못한 오류를 발생시킬 수 있음
- 자바스크립트의 버그 중 15%는 타입스크립트의 사용으로 미리 예방할 수 있다는 연구 결과
- "To Type or Not to Type: Quantifying Detectable Bugs in JavaScript" (Gao et al., 2017)
- GitHub 공개 프로젝트 400건의 버그를 분석한 연구에서 타입스크립트가 15% 정도의 버그를 예방하는 데 도움이 된다는 결과
- 타입스크립트와 Flow를 이용한 정적 타입 검사로 감지 가능한 버그 비율이 평균 15%임
- "To Type or Not to Type: Quantifying Detectable Bugs in JavaScript" (Gao et al., 2017)
- tsc라는 컴파일러를 통해 자바스크립트로 변환
- 자바스크립트는 별도의 컴파일 단계없이 프로그램이 바로 실행되는데, 엄밀히 말하자면 JS를 해석하고 실행하는 V8엔진에서 JS코드를 최적화하는 컴파일 단계를 거친다고 함
- 자바스크립트의 상위 집합인 타입스크립트는 명시적 혹은 추론된 타입을 기반으로 코드를 검사
- 컴파일러는 각 변수, 함수, 객체의 타입을 검사하고 타입이 일치하지 않거나 오류가 있으면 이 단계에서 에러가 발생
- 타입 검사가 끝나면 타입스크립트는 코드를 자바스크립트로 변환
- 이때 타입스크립트의 고유 문법(interface, type, enum, 제네릭 등)은 모두 제거되거나 대응되는 자바스크립트의 코드로 변환됨
// TypeScript 코드
interface Person {
name: string;
age: number;
}
const person: Person = { name: "Alice", age: 30 };
// 컴파일 후의 JavaScript 코드
const person = { name: "Alice", age: 30 };FAQ 관련 폴더
- src/app/api/faq/route.ts
네이버 클라우드 특강
https://brunch.co.kr/@topasvga/5245
네이버 클라우드 CLOVA Studio 이론
이전 강의까지는 GPU 사용법
오늘부터는 생성형 AI 활용
네이버 클라우드: 사용 서비스 4가지
- 개인용
- GPU 서버 제공
- Server 서비스
- 네이버 클라우드 사용
- Server 서비스
- 생성형 AI
- 네이버 클라우드 사용
- 기타 AI 서비스들
- 네이버 클라우드 사용
- Chatbot
- OCR 등
- 네이버 클라우드 사용
생성형 AI 도구 'CLOVA Studio' 알아보기
- 목차
- AI / 머신러닝 / 딥러닝 / 자연어 처리
- 생성형 AI
- 네이버 클라우드 AI 서비스
- 네이버 생성형 AI 개발 플랫폼 CLOVA Studio
- 프롬프트 엔지니어링
- 파인 튜닝
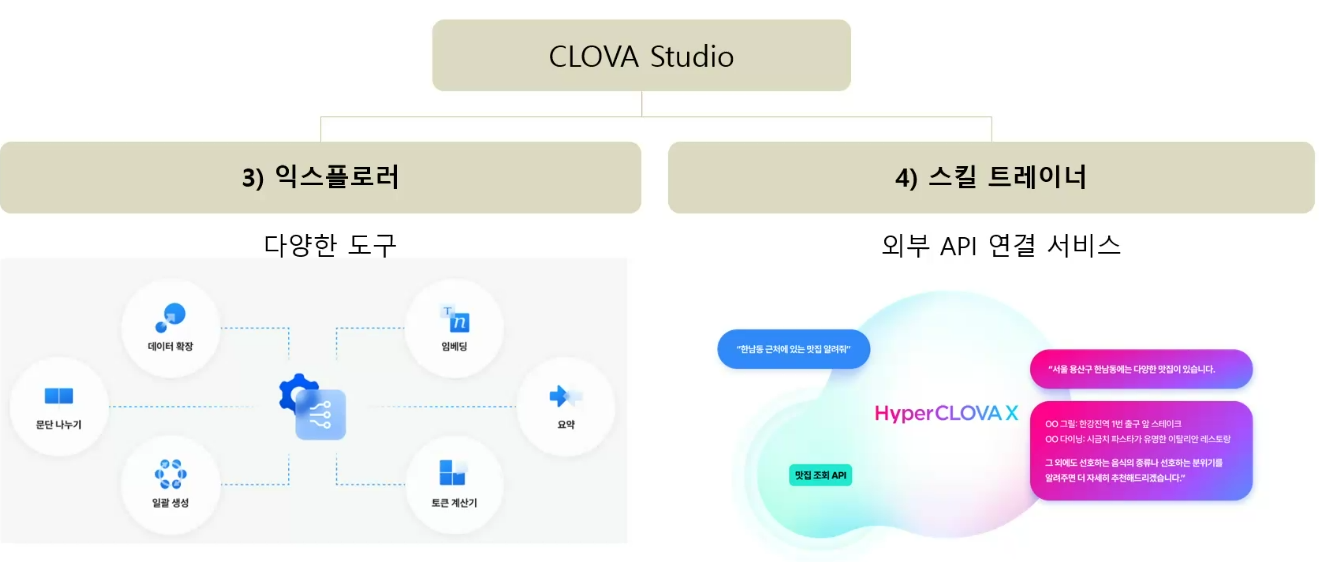
- 네이버 익스플로러
- 검색증강생성(RAG)
- 랭체인
- 네이버 스킬 트레이너
1. AI / 머신러닝 / 딥러닝 / 자연어 처리
- AI, 머신러닝, 딥러닝
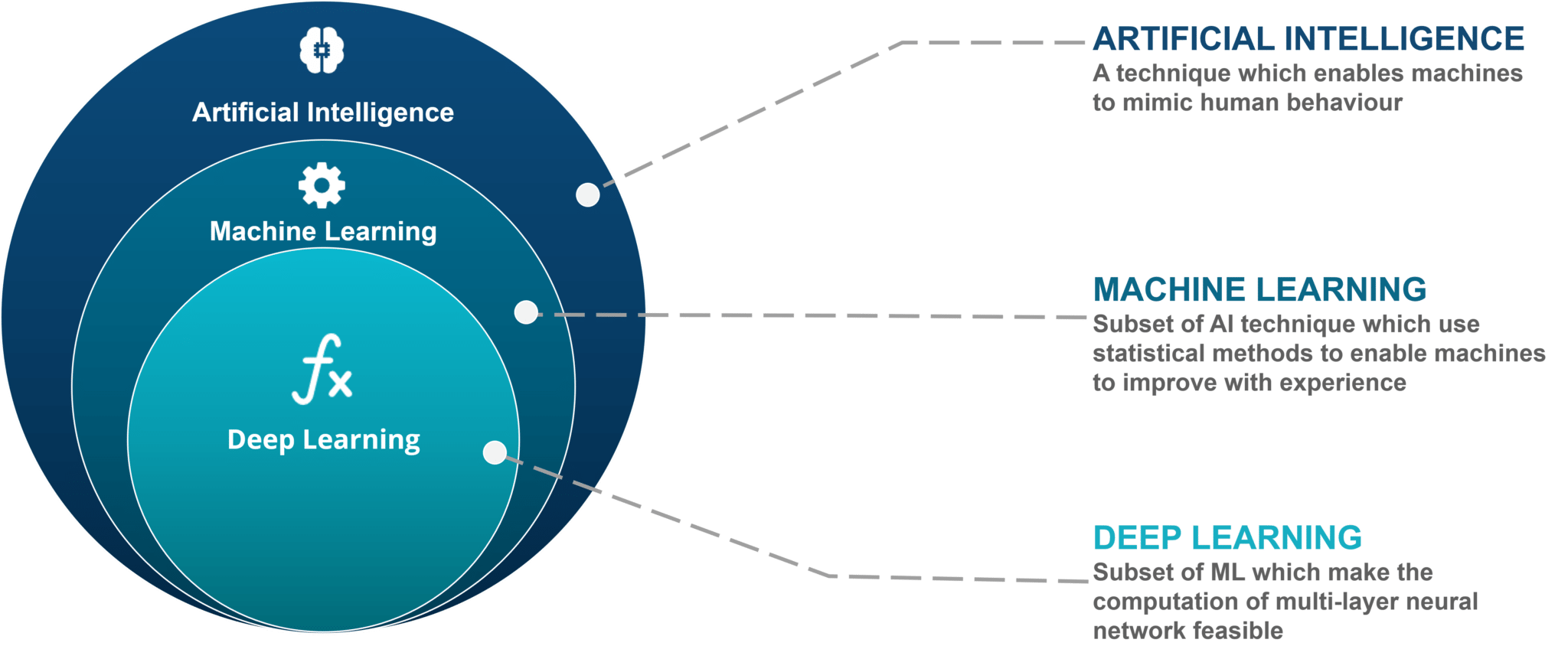
- 자연어 처리(NLP, Natural Language Process)
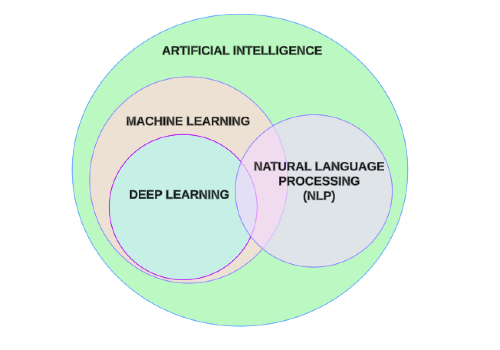
- 언어 모델(Language Model)
LLM vs. LMM(Large Multimodal Model)
2. 생성형 AI
- 생성형 AI
- 데이터 학습과 질문 의도 분석을 바탕으로 가장 정학환 답변을 내놓도록 설계
- LLM(대규모 언어 모델)
- Foundation Model(FM)이라고도 함
- 생성형 AI 사용
| no | 작업 | 난이도 | 비용 | 정확성 |
|---|---|---|---|---|
| 1 | 프롬프트 엔지니어링 | 쉬움 | 저비용 | 정확도 낮음 |
| 2 | 검색 증강 생성(RAG) | 보통 | 중비용 | 정확도+1 |
| 3 | 파인 튜닝 | - | - | 정확도+2 |
| 4 | 지속적 학습(LLM 기업) | 어려움 | 고비용 | 정확도+3 |
- 프롬프트 엔지니어링만으로도 80%의 정확도를 얻을 수 있다고 함
- FM이 구축된 상태에서 프롬프트 엔지니어링으로 대응하는 건 비용이 낮음
- 지속적 학습의 경우 학습한 데이터의 '날짜'도 중요함
프롬프트 엔지니어링
- 대형 언어 모델(LLM)과 상호 작용하는 방법과 사용자의 목적에 맞게 모델의 반응을 최적화하는 기술
검색 증강 생성(RAG)
- 정보 검색과 생성을 결합
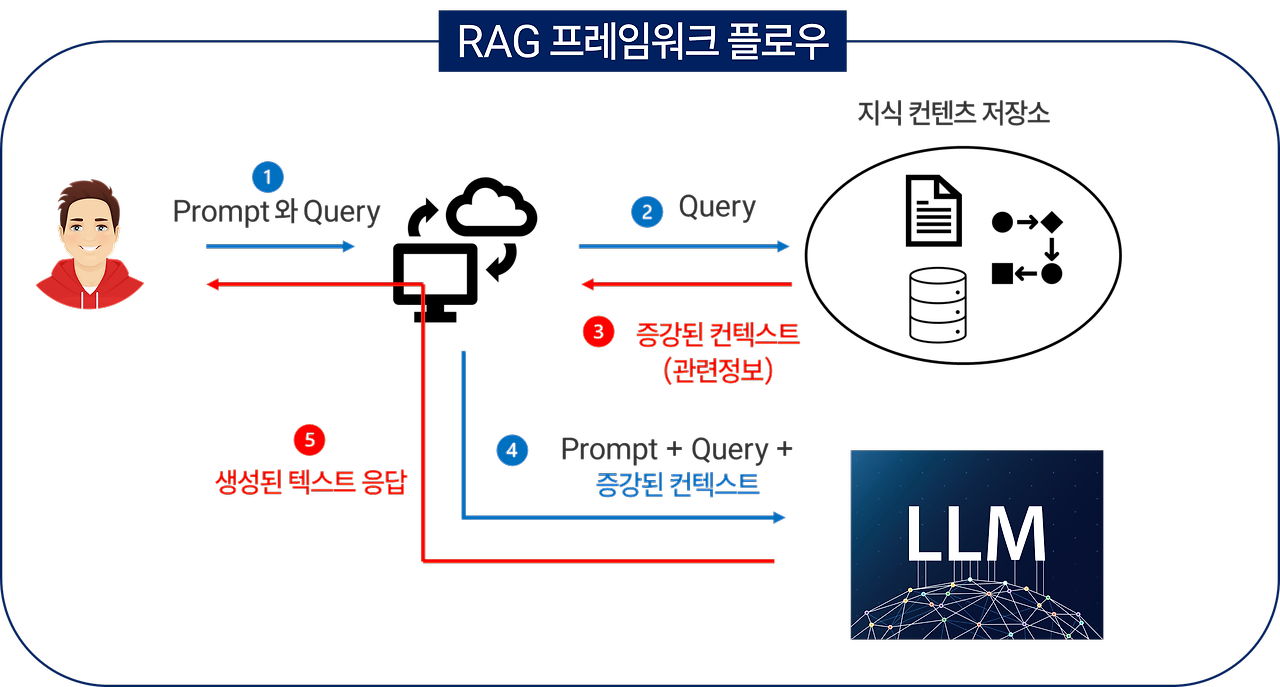
- 정보 검색
- 관련 문서 반환
- 문장 생성
- 정보 저장과 질문 동작
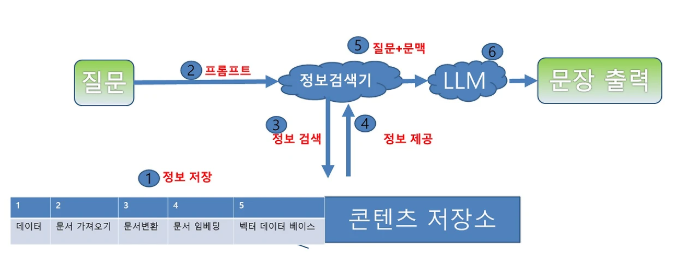
- 정보 저장
- 프롬프트
- 정보 검색
- 정보 제공
- 질문+문맥
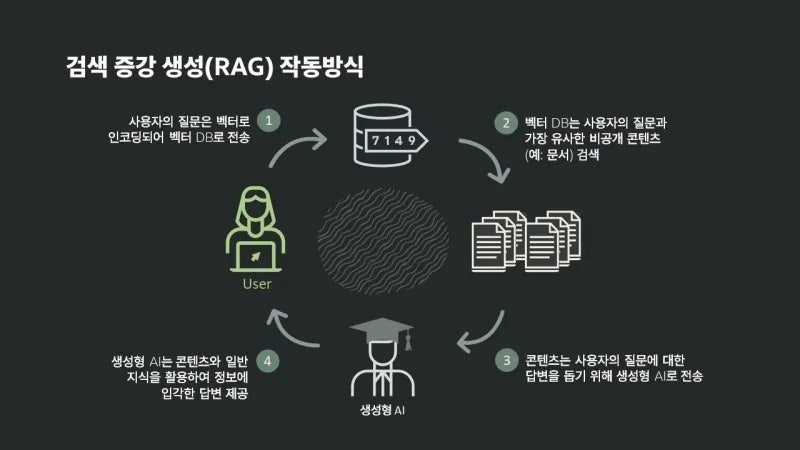
- 동작 순서
- 데이터, 매뉴얼 텍스트를 벡터화한다.
- 사용자가 질문한다.
- 벡터화된 매뉴얼과 질문을 비교하여 매뉴얼 중 질문한다.
- 예: 인사정보 → n년 차에 휴가는 몇 개인가요?
- 연관성 있는 정보를 획득한다.
- 획득한 매뉴얼의 정보를 프롬프트에 삽입해 LLM에 질문한다.
- LLM이 답변한다.
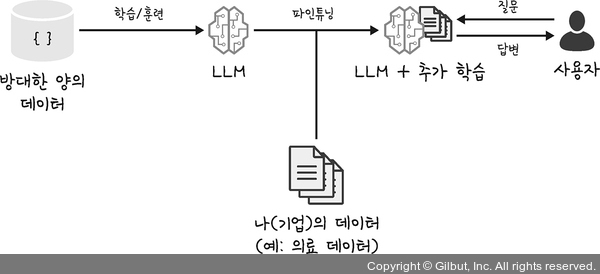
파인튜닝
- 기존의 LLM을 조금 더 훈련시키는 과정
- LLM을 특별한 상황에 맞게 가르치는 것
- 예: 법률 데이터, 의료 데이터
- 추가 학습된 새로운 LLM이 생김
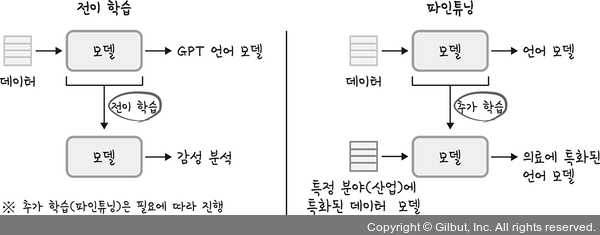
전이 학습 vs. 파인튜닝
랭체인
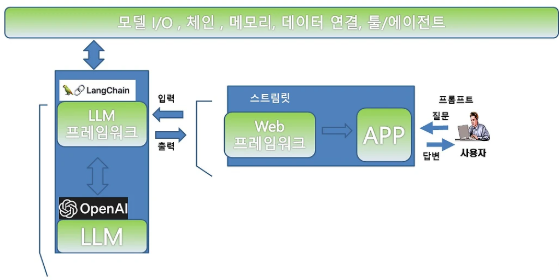
- LLM과 외부 도구를 사슬처럼 결합시켜주는 것
3. 네이버 클라우드 AI 서비스
- 2025-11 기준 네이버 클라우드 AI 상품
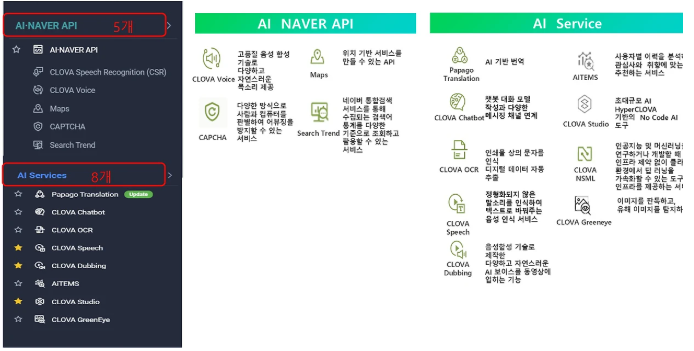
- AI NAVER API
- CLOVA Voice
- CAPCHA
- Maps
- Search Trend
- AI Service
- Papago Translation
- CLOVA Chatbot
- CLOVA OCR → 지로용지, 영수증 이벤트 영수증 읽기 등
- CLOVA Speech
- CLOVA Dubbing
- AITEMS → "추천" 서비스: 사용자별 이력을 분석해 관심사와 취향에 맞는 상품을 추천하는 서비스
커머스, 리테일 산업에서 많이 사용 - CLOVA Studio
- CLOVA NSML → AI, ML 연구/개발할 때
- CLOVA Greeneye
- AI NAVER API
문제 자주 나옴: 다음 중 네이버 클라우드 AI 서비스가 아닌 것은?
- HyperCLOVA X(HCX) 특장점
- 한국어 문장의 맥락을 잘 구별
- 한국 고유 지식에 상당한 이해력을 보여주는 데 탁월
- 한국어 문장 구조를 가장 잘 이해하는 모델
- 조사 + 명사/구
- 어미 + 어간 = 다양한 의미 파생
- 라인업

- cue:
- 네이버 생성형 AI 검색
- 네이버 클로바 앱
- 네이버 대화형 AI 서비스
- cue:
- HyperCLOVA X 모델의 기능 발전
| 구분 | 2024 | 2025 | |
|---|---|---|---|
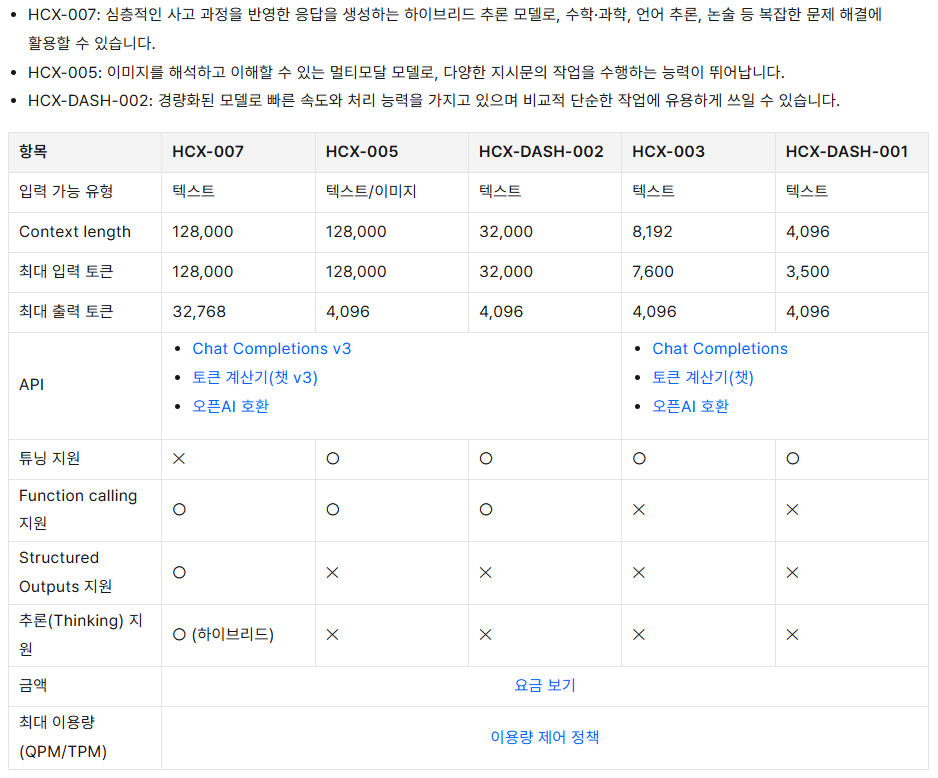
| 플래그십 모델 | HCX-003 | HCX-005 | HCX-007 |
| 경량모델 | HCX-DASH-001 | HCX-DASH-002 | |
| 오픈소스 | HCX-SEED HCX-THINK | ||
| CLOVA Studio | LangChain Compatibility Embedding V2 | Router Function Call | Structured Output RAG Reasioning API Re-ranker API |
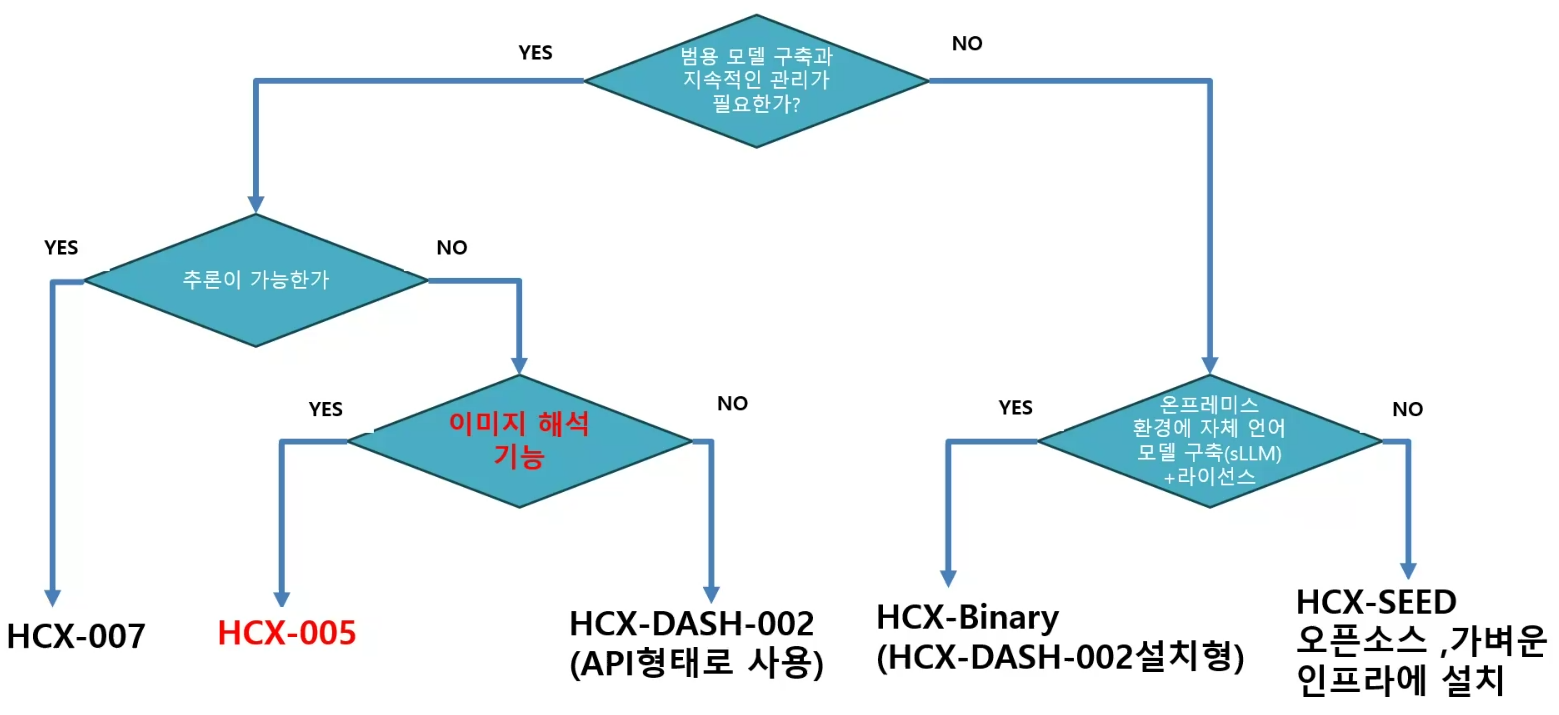
- HCX-005
- 국내 최초 Vision Model
- 이미지 내용을 분석(이미지 분석)
- 국내 최대 Context Size(128K)
- 국내 최초 Vision Model
- HCX-007
- 추론(Reasioning) 모델(128K)
- HCX-DASH-002
- 32K Context
- 경량모델은 1/4~1/5 가격이라고 함
- HCX-SEED
- 초경량 모델 3종
- HCX-SEED-3B(vision)
- HCX-SEED-1.5B
- HCX-SEED-0.5B
- 초경량 모델 3종
- HCX-THINK
- 경량 추론 모델 1종
- HCX-SEED-Think
- 경량 추론 모델 1종
- 플레이그라운드 > Model
- 모델 선택
| THINK 모델 | SEED 모델 | DASH 모델 |
|---|---|---|
| 추론 능력을 강화한 생성형 AI 모델 | 상업용 무료 오픈소스 AI 모델 | 높은 속도의 경량화 AI 모델 |
| 복잡한 질의를 단계적으로 분석 텍스트와 이미지를 함께 이해해 정확한 추론 결과를 생성하는 모델 | 세 가지 모델 추론 능력을 갖춘 SEED Think 모델 오픈 소스로 제공 | 속도와 비용 면에서 탁월한 활용성 제공 |
- 주요 고객 사례
- 플래그십 모델 사례: HCX-005 채용 AI
- LLM이 인재 추천, 추천 사유 생성
- 플래그십 모델 사례: HCX-007 생성형 AI 기반 그룹사 검색 서비스 구축
- LLM + RAG + Orchestrator
- 사용자는 챗봇형태로 질의/답변
- 경량 모델 사례: HCX-DASH-002 (32K Context) 금융 특화 sLLM 구축
- 금융 규제로 인해 사내에 설치할 수 있는 모델
- 플래그십 모델 사례: HCX-005 채용 AI
- 네이버 클라우드: 생성형 AI 도구(기능)
| 구분 | 네이버 클라우드 생성형 AI 도구 |
|---|---|
| 문장 생성 및 이미지 이해 | Chat Completion |
| 튜닝 | 튜닝 |
| 분류 | 라우터 |
| 외부 데이터 연동 | Function call |
| 외부 API 연동 | Skill Trainer |
| 문단 나누기 | Segmentation |
| 요약 | Summarize |
| 토큰 계산기 | Tokenize |
| 임베딩 | Embedding |
| 리랭커 | Reranker |
| RAG추론 | RAG Reasoning |
- 외부 데이터 연동 예시
- 실시간 항공권 조회 → Foundation 모델만 쓰면 안 됨(해당 모델은 몇 년 전 데이터만 학습한 거니까)
4. 네이버 생성형 AI 개발 플랫폼 CLOVA Studio
- 서비스 모델

Basic
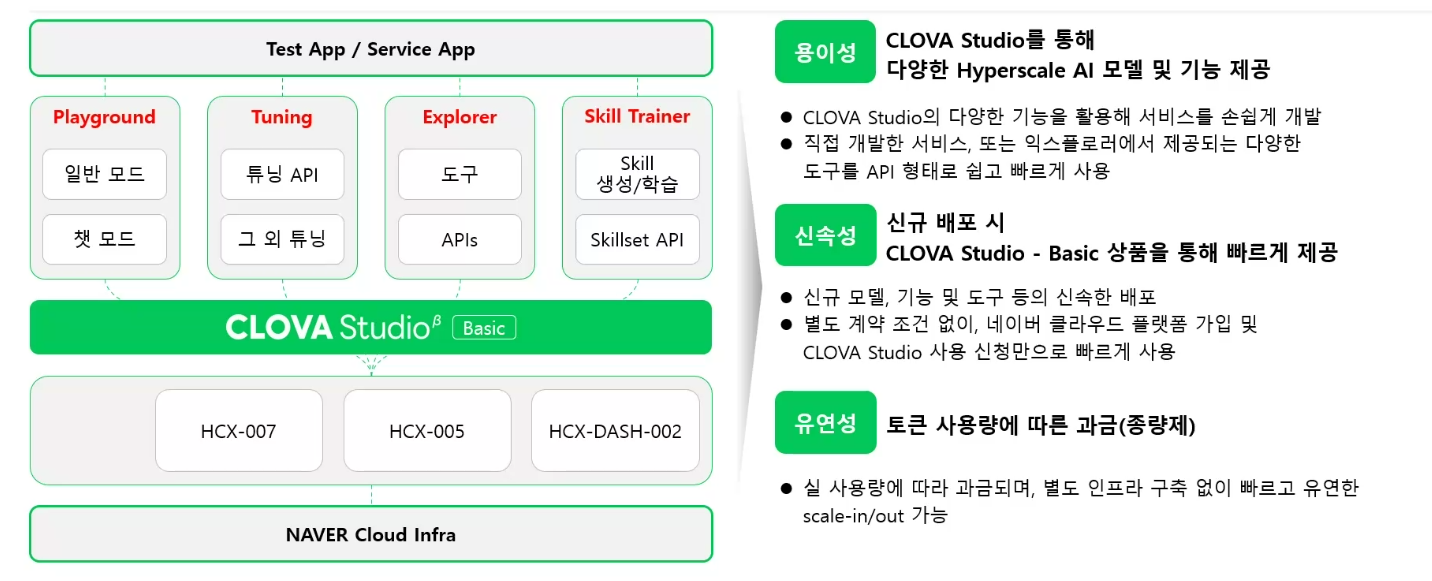
- Foundation 모델만 보내면 최근 정보에 대응할 수 없기 때문에 외부 연동을 통해 최근 정보를 가져와서 단점 보완
Exclusive

주요 기능

플레이그라운드 파라미터
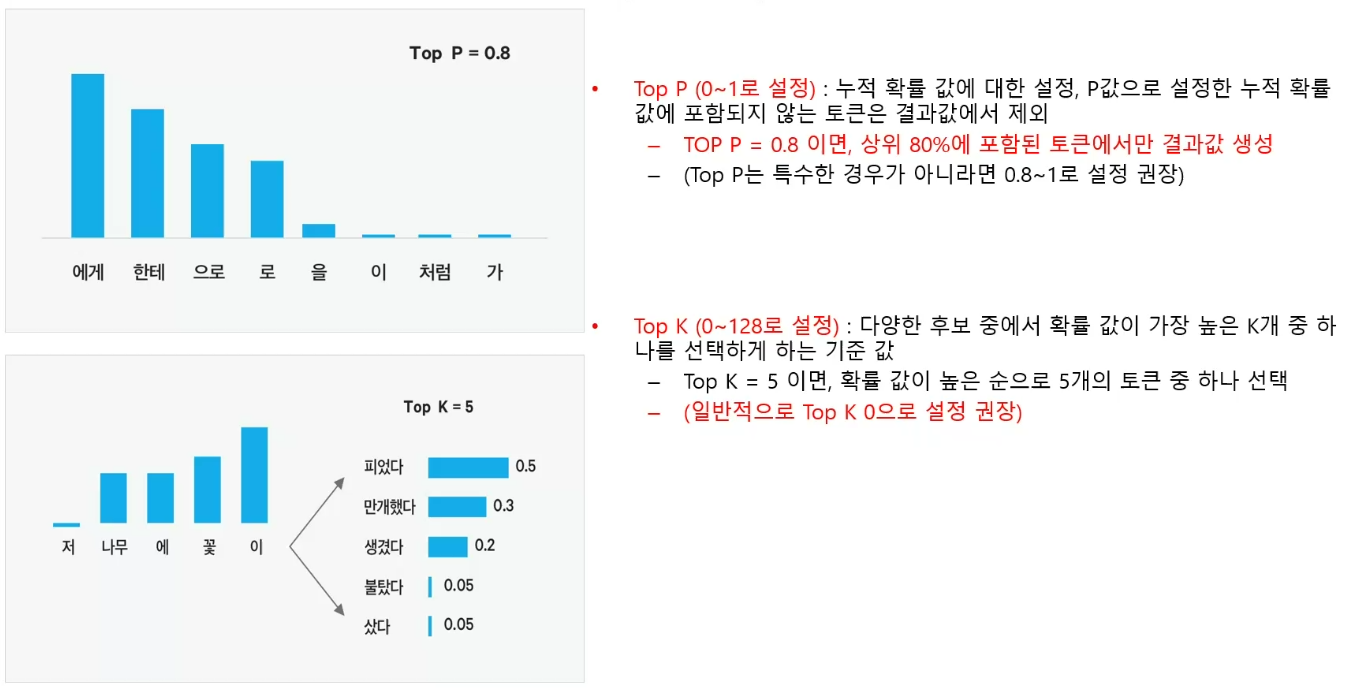
- Model
- Top P, Top K
- Maximum Token
- 0~4096으로 설정
- AI가 생성하는 결과값의 최대 길이
- 작업의 목적과 형태에 따라 값 조정
- 카피라이터, 자소서, 소설 창작 등
- HCX-005 모델은 최대 40
- Token
- 토큰화

- 토큰을 만드는 작업
- 언어 모델이 자연어를 처리하기 위한 필수 과정
토큰은 돈이다~
영어 토큰보다 한글 토큰이 조금 더 비쌈
- Temperature
- 0~1로 설정
- 확률 분포에 가중치 변화를 주어 문장의 다양성을 조절하는 값
- 값을 낮게 설정하면 정형적인 결과값 생성, 후보 토큰 간 확률 값 차이 큼
- 예측 가능한 결과물이 필요하면 값을 낮게 설정
- default는 0.5
- 값을 높게 설정하면 다양한 문장 생성 가능
- 문장 품질 편차 발생, 토큰 간 확률 값 차이 적음
- 소설 창작, 마케팅 문구 작성 등 창의적인 결과물이 필요하면 값을 높게 설정
- Pepetition penalty
- 0~10으로 설정
- 결과 문구 생성 시 동일 토큰에 감점 요소를 부여하는 값
- 값이 낮으면 같은 결과를 반복 생성할 확률 높아짐
- 값이 높으면 같은 결과를 반복 생성할 확률 낮아짐
- Input값이 같아도 새로운 output 값을 생성함
- 활용 예시
- 목록화
- 키워드 추출
- 어휘 치환
5. 프롬프트 엔지니어링

2 B R 0 2 B