예시 데이터
- student.txt
- 데이터 간 구분자: 공백이라고 가정
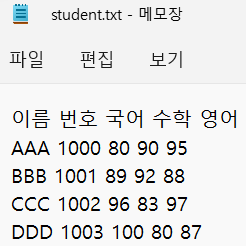
- 데이터 간 구분자: 공백이라고 가정
1. text 파싱 후 변환
- txt 파일을 연 뒤, 데이터 파싱 과정을 거쳐 데이터프레임으로 변환하는 방법
- 구분자가 불규칙한 상황 등에서 유용
- 구분자가 규칙적이라면 방법 2의 read_csv 함수를 이용한 방법 사용을 권장
Step 1: 파일 열기
- txt 파일의 정보를 readlines 함수를 통해서 리스트 형태로 받아오기
with open('student.txt', 'r') as f:
data = f.readlines()
print(data)
# 저장된 값
['이름 번호 국어 수학 영어\n',
'AAA 1000 80 90 95\n',
'BBB 1001 89 92 88\n',
'CCC 1002 96 83 97\n',
'DDD 1003 100 80 87']Step 2: 열 이름 목록 가져오기
- column의 이름으로 진행될 첫 줄의 데이터를 split 함수를 통하여 분리
- 구분자가 공백이 아니라면 split 내에 해당 구분자를 input으로 적기
- 마지막 부분의 줄 바꿈 기호는 strip 함수를 이용하여 제거
column_name = data[0].strip().split()
print(column_name)
# ['이름', '번호', '국어', '수학', '영어']Step 3: 각 행의 데이터 가져오기
- 두 번째 행부터 각 행마다 저장된 데이터를 불러와서 열 strip, split의 전처리를 진행
data_split = [x.strip().split() for x in data[1:]]
print(data_split)
# [['AAA', '1000', '80', '90', '95'], ['BBB', '1001', '89', '92', '88'], ['CCC', '1002', '96', '83', '97'], ['DDD', '1003', '100', '80', '87']]Step 4: 데이터프레임 변환
- Step 3에서 생성한 각 행 단위로 분할된 데이터가 저장된 리스트와 Step 2에서 생성한 열 이름이 저장된 리스트를 pd.DataFrame 함수에 input으로 넣어 최종 데이터프레임을 생성
import pandas as pd
df = pd.DataFrame(data_split, columns = column_name)
df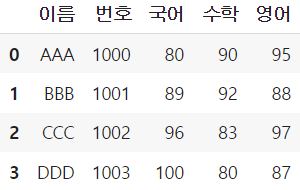
2. to_csv 함수 이용
- 각 데이터가 구분되어 있는 구분자가 파일 전체에서 동일한 상황이라면, read_csv 함수를 이용하며 txt 파일의 데이터프레임 변환이 아주 쉽게 가능
- read_csv 파일 내에 해당 txt 파일을 input으로 넣고, sep 인자를 구분자로 맞추어 함수를 실행시키면 데이터프레임 변환 완료
df = pd.read_csv('student.txt', sep = ' ')
df추가: read_csv, to_csv 함수
- 다음과 같은 간단한 내용이 student.csv 파일로 저장되어 있다고 가정
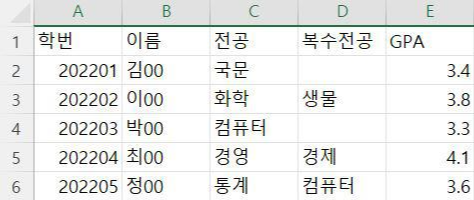
- 메모장으로 열게 되면 다음과 같이 콤마(,)로 각 내용이 구분되어 있음 → 이름의 유래가 여기서 왔어요!
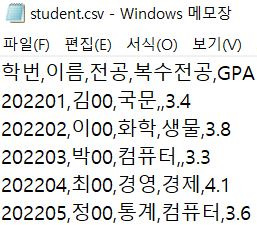
- 메모장으로 열게 되면 다음과 같이 콤마(,)로 각 내용이 구분되어 있음 → 이름의 유래가 여기서 왔어요!
csv 파일 읽어오기 함수 : pd.read_csv
- pd.read_csv 함수의 가장 기본적인 사용법
- csv 파일의 디렉토리를 input으로 지정 → 기본 옵션으로 파일을 읽어와 데이터프레임을 만듦
- 디렉토리는 작업중인 파이썬 파일을 기준으로 작성
- csv 파일과 파이썬 파일이 같은 폴더에 있다면 csv 파일 이름만 적어주어도 됨
import pandas as pd
df = pd.read_csv('student.csv')
df파라미터 뜯어보기
- 파라미터
※ read_csv 함수에서 제공하는 인자의 개수는 수십 가지로 매우 다양하므로 공식 문서를 읽는 편이 좋음
import pandas as pd
import inspect
print(inspect.getfullargspec(read_csv))
-
filepath_or_buffer
- 데이터가 들어 있는 파일 경로를 입력하는 파라미터
- read_csv를 사용할 때 가장 먼저 입력하는 파라미터
-
sep, delimeter
- sep 인자의 값을 기준으로 value를 구분
- 상황에 따라 " " 스페이스바가 두 칸일수도 있고 "\t" tab일수도 있으니 데이터 파일을 열어보고 거기에 맞게 sep 파라미터를 설정하면 됨

import pandas as pd
pd.read_csv('test.txt',sep='a,',header=None, engine='python')
#header None은 첫 행의 원소들을 열이름으로 받아들이지 않기 위해 설정
#engine python은 c기반 언어인 python이 정규표현식을 구분자로 받아들이지 못하는 오류를 해결하기 위해 사용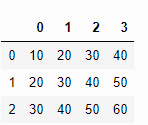
delimiter : str, default None
Alias for sep.
what is the difference between sep and delimiter
결론적으로, 용도는 거의 비슷하고 다른 메서드들에서도 범용적으로 사용되는 sep파라미터가 보통 사용된다고 한다.
- names, header
- 열 이름과 관련된 파라미터

pd.read_csv('test.txt')
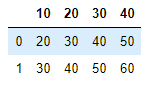
pd.read_csv('test.txt', header=None)
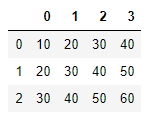
pd.read_csv('test.txt', header=1)
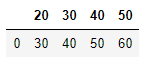
pd.read_csv('test.txt', names=['c1','c2','c3','c4'], header=None)
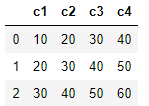
names 파라미터를 사용하는 경우
(1) 데이터 파일에 열 이름이 없는 경우 → header를 none으로 지정
(2) 데이터 파일에 열 이름이 있지만 바꾸고 싶은 경우 → header를 0으로 지정
- index_col, usecols
- index_col은 특정 열을 index 정보로 활용할 수 있게 해주는 파라미터
- usecols는 사용할 열을 선택할 수 있게 해주는 파라미터
- index_col과 usecols 모두 인덱스 번호 뿐만 아니라, 문자열 열 이름을 값으로 받을 수 있음
- index_col과 usecols 모두 list로 여러가지 값을 받을 수 있음 → 응용: multiple indexing

pd.read_csv('test.txt', index_col=1,header=None)

pd.read_csv('test.txt', usecols=[0, 1,2],header=None)
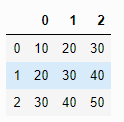
※ index_col과 같이 사용하는 경우 usecols에 index_col의 컬럼이 포함되어야 함
pd.read_csv('test.txt', index_col=1 ,usecols=[0, 2, 3],header=None)
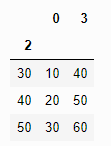
위와 같이 index_col을 첫 번째 열로 하고싶었지만 사용하는 열에서는 첫 번째 열을 제외한 경우 usecols에서 첫 번째 열인 두 번째 열이 index_col이 됨
- squeeze
- 컬럼의 수가 하나밖에 없을 때 데이터를 series 형태로 출력

pd.read_csv('test.txt',header=None)

pd.read_csv('test.txt',header=None, squeeze=True)
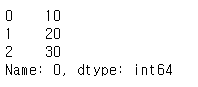
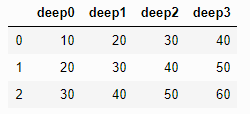
- prefix
- 열 이름에 특정 이름을 추가

pd.read_csv('test.txt',header=None, prefix='deep')
- mangle_dupe_cols

- 위와 같이 열 이름이 같은 파일을 불러오는 경우 컴퓨터의 입장에서는 어느 열이름으로 접속해야지?라는 혼란이 생김
- mangle_dupe_cols라는 파라미터의 default가 true인 이유임!
→ 열 이름 옆에 .number를 붙여 열 이름을 다르게 표기
- mangle_dupe_cols라는 파라미터의 default가 true인 이유임!
- 위와 같이 열 이름이 같은 파일을 불러오는 경우 컴퓨터의 입장에서는 어느 열이름으로 접속해야지?라는 혼란이 생김
pd.read_csv('test.txt')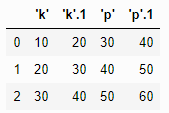
※ 공식 문서에 따르면 mangle_dupe_cols를 false로 설정하면 중복되는 열들을 제거한다고 하는데 아직 지원하지 않을 수도 있다고 함
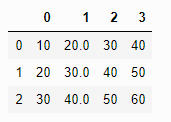
- dtype
- dict 형태로 열의 데이터 타입을 지정

pd.read_csv('test.txt', dtype={1:np.float32}, header=None)
- engine
- 사용할 engine을 설정
- 'C'와 'Python' 둘 중 하나 쓰면 됨
- read_csv 단계에서 일어나는 오류중 꽤 많은 오류들이 engine='python'만 명시해줘도 해결되는 경우가 많음
- 사용할 engine을 설정
- converters
- dtype과 같이 특정 열의 데이터 타입을 변경해주는 역할
- converters는 단순한 타입을 넘어서 좀 더 구체적인 명시가 가능하다고 함
whats the difference between dtype and converters
import io
t="""int,float,date,str
001,3.31,2015/01/01,005"""
df = pd.read_csv(io.StringIO(t))위와 같이 데이터를 불러올 때, date를 datetime64[ns] 형태로 불러올 때 dtype에서는 오류가 발생해 parse_dates라는 파라미터를 추가적으로 사용해야 하지만 converters에서는 오류 없이 date열을 datetime형으로 변환시킬 수 있음
pd.read_csv(io.StringIO(t), dtype={'date':pd.to_datetime})

pd.read_csv(io.StringIO(t), parse_dates=['date'])
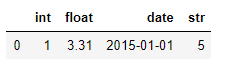
pd.read_csv(io.StringIO(t), converters={'date':pd.to_datetime})
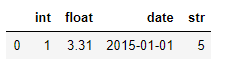
- true_vlaues, false_values
- 특정 열의 값들을 모두 true 혹은 false로 변환시킬 때 사용

pd.read_csv('test.txt', header=None)

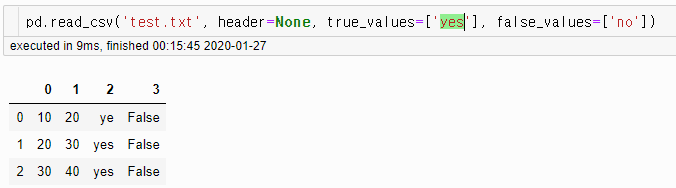
pd.read_csv('test.txt', header=None, true_values=['yes'], false_values=['no'])

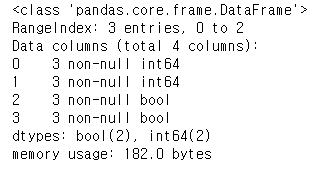
→ 값이 True, False로 바뀌었을 뿐만 아니라 자료 형태가 bool 타입으로 바뀜
※ 단 하나의 value라도 해당 값이 아니면 변환이 되지 않음
인덱스 column 지정: index_col 인자
기본적으로 모든 열들을 값으로 취급하고, 인덱스는 0, 1, 2, ...의 값으로 지정해주게 되는데, 만일 특정 열 자체를 인덱스로 취급하고 싶다면 index_col 인자에 해당 열의 위치 번호를 지정해주시면 됩니다.(가장 첫 열은 0번 기준)
df = pd.read_csv('student.csv', index_col = 0)
df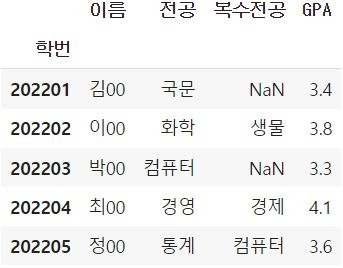
tsv 등 다른 형식 파일 열기 옵션: sep 인자
- 파일이 콤마로 구분된 csv 파일이 아니라 탭(\t)으로 구분된 tsv 파일 등 다른 형식의 파일이더라도 read_csv 함수를 이용하여 파일을 열 수 있음!
- 내용을 구분하고 있는 문자를 sep 인자에 지정하면 됨
- sep 인자의 기본 값은 콤마(,)로 csv 파일에서는 지정할 필요가 없음
- tsv 파일인 경우에는 \t로 지정
- 텍스트 파일(txt)에서도 마찬가지 원리로 read_csv 함수 사용이 가능
- 내용을 구분하고 있는 문자를 sep 인자에 지정하면 됨
# 열려는 파일이 tsv 파일인 경우
df = pd.read_csv('student.tsv', sep = '\t')
# 열려는 파일이 공백을 기준으로 내용이 구분된 txt 파일인 경우
df = pd.read_csv('student.txt', sep = ' ')파일 인코딩 형식 지정: encoding 인자
- 파일을 여는 과정에서 UnicodeDecodeError가 발생할 때가 있음
- 인코딩 형식이 일치하지 않아 파일 내 값들을 읽어올 수 없는 상황이라는 뜻
- encoding 인자를 통하여 인코딩 방식을 지정해주어야 함!
df = pd.read_csv('student.csv', encoding = 'utf-8')
df기타 유용한 인자
engine : 'c', 'python' 처럼 지정, 'c'가 속도는 빠르나, feature-complete하지 않을 수 있음
skiprows : 특정 행 위치부터 읽어오고 싶을 때 사용, engine = 'c'에서는 미지원
na_values : 특정 데이터 값들을 결측값으로 취급하고 싶은 경우 목록 지정
keep_default_na : 결측치에 NaN 대신 빈 칸으로 남기고 싶다면 False로 지정
dtype : 특정 column의 데이터 타입을 지정해주고 싶다면 열 이름 : 타입의 딕셔너리로 지정
csv 파일 내보내기 함수 : to_csv
- 작업이 완료된 데이터프레임을 csv 파일로 저장하고 싶은 경우
데이터프레임.to_csv(디렉토리)형태로 간단하게 지정하면 저장 완료
# 데이터프레임 변수.to_csv(저장할 디렉토리)
df.to_csv('student_2.csv')