반복문으로 DataFrame 합치기
개요
- 같은 구조의 DataFrame을 반복적으로 만든 뒤, 하나의 DataFrame으로 합치는 방법 정리
- DataFrame을 합치는 방법으로는 concat, merge, append, join 등의 함수가 존재하나 기준 열을 이용해 합치는 것이 아니라 단순히 세로로 데이터 연결을 하고자 하므로 "concat"을 중점적으로 살펴볼 것
- append 함수는 Pandas 1.4.0부터 concat으로 대체되어 앞으로 나올 버전에서는 dataframe에 적용되지 않을 수 있음
- DataFrame을 합치는 방법으로는 concat, merge, append, join 등의 함수가 존재하나 기준 열을 이용해 합치는 것이 아니라 단순히 세로로 데이터 연결을 하고자 하므로 "concat"을 중점적으로 살펴볼 것
- titanic 데이터를 예시로 설명 진행
import numpy as np
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset("titanic")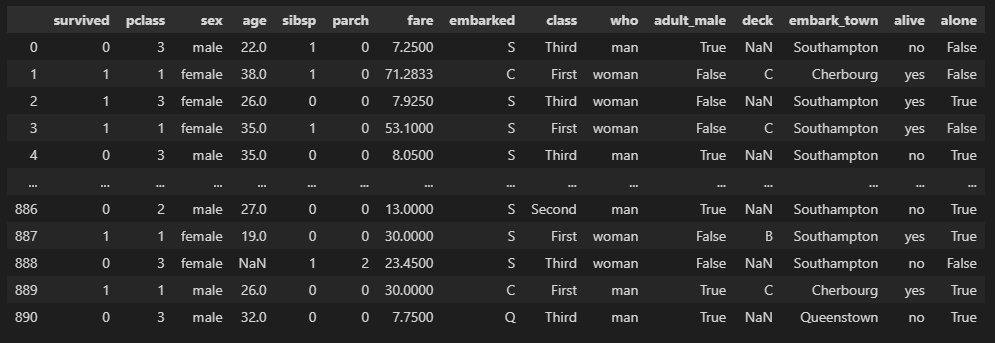
append
- 행 끝에 다른 행을 추가한 새 DataFrame을 반환
- 추가할 DataFrame의 인덱스를 무시할 때는 ignore_index 매개변수를 True로 지정
💡 append 함수는 Pandas 1.4.0부터 concat으로 대체되어 앞으로 나올 버전에서는 삭제될 수 있으므로 append 대신 concat을 사용하는 것을 권장한다.
df = pd.DataFrame()
for idx in range(10):
tmp = titanic.iloc[idx]
df = df.append(tmp, ignore_index=True)
df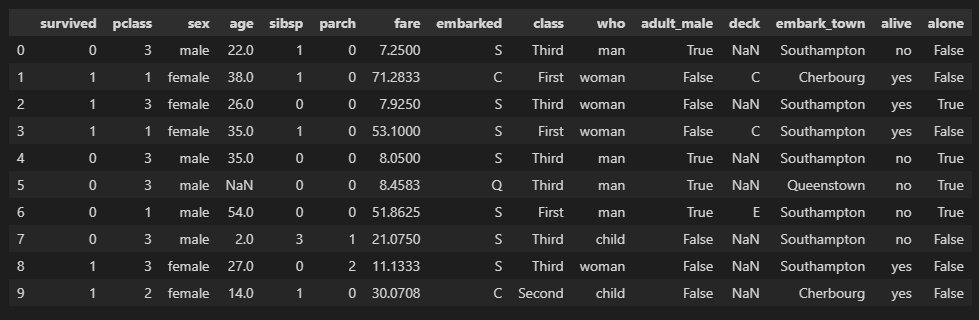
concat ★★★★★
- concatenation의 줄임말
- iterable 한 개체를 행 또는 열을 기준으로 합친 객체를 반환
- 결합할 데이터를 iterable한 개체로 전달해야 하기 때문에 리스트 등에 결합할 데이터를 모은 뒤 한 번에 결합하는 것이 좋음
list_tmp_df = []
for idx in range(10):
tmp = titanic.iloc[[idx], :]
list_tmp_df.append(tmp)
df = pd.concat(list_tmp_df, ignore_index=True)
df성능 비교
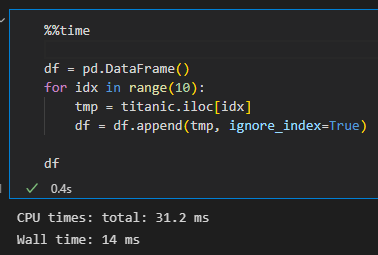
- append는 deprecated되었다는 것도 있지만 성능에 있어서도 concat을 사용하는 것이 좀 더 좋음
- %%time 명령어로 이용해 위에서 실행한 코드의 소요시간을 확인해보기
- append
- concat
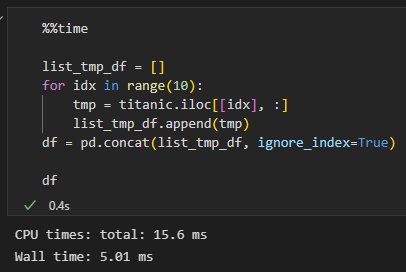
→ concat을 사용했을 때보다 append를 사용했을 때의 소요시간이 훨씬 길다
- append
- %%time 명령어로 이용해 위에서 실행한 코드의 소요시간을 확인해보기
return NONE
함수는 항상 return 값을 반환해줍니다. 그 반환해준 값은 함수를 대체하게 됩니다.
하지만 함수에 return 값이 지정되어 있지 않은 경우(리턴값이 선언되지 않았을 경우) python은 내부적으로 함수 가장 마지막 라인에 return None이 있다고 간주합니다.
def print_value(a):
print(a * a)
print(print_value(3))→ 괄호 안을 계산한 결과인 9와 None이 print 함수와 만나기 때문에 9와 None이 출력됨
파이썬은 return 안해도 돼?
- return문이 없으면 자동으로 return None을 하는 것
- 함수가 return문이 없어도 되고, 없으면 리턴 없이 끝나는 게 아님
재귀함수에서 재귀가 종료되는 경우
def dfs():
if 재귀 종료 조건:
return cnt
dfs()- 위와 같은 함수가 있다고 가정할 때 동작 방식:
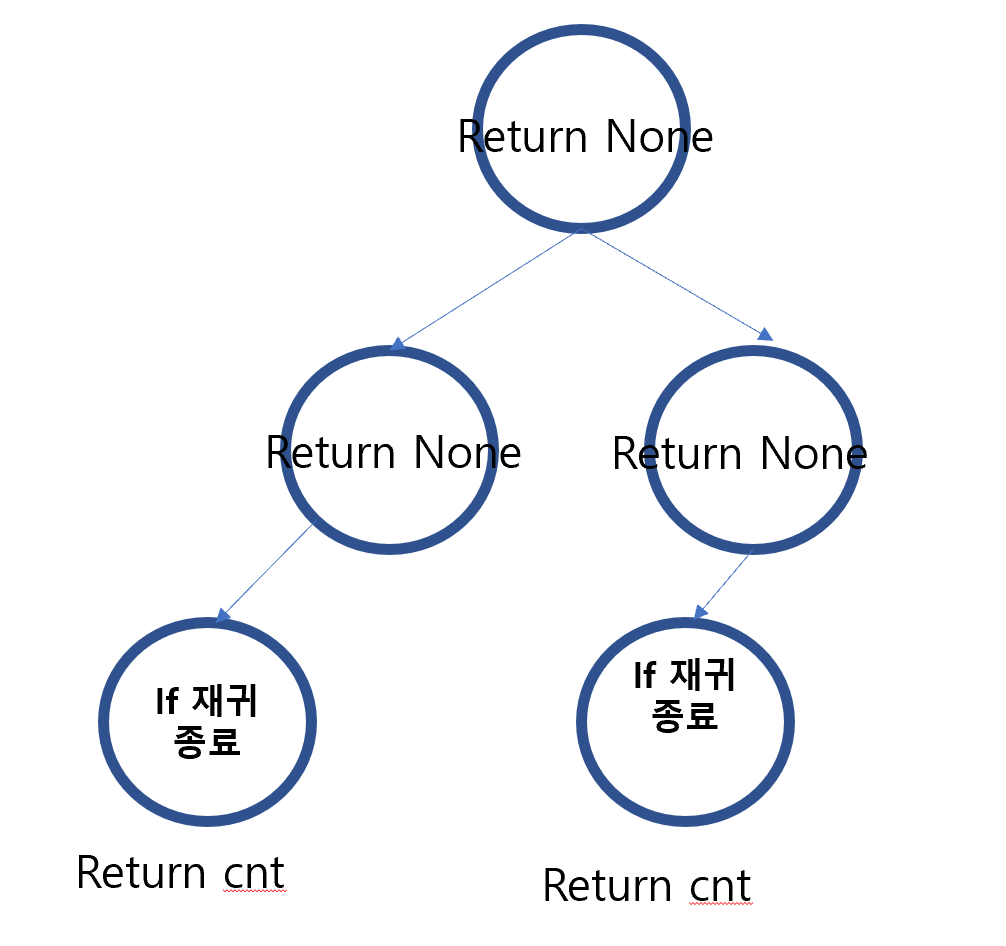
- 재귀가 종료되면, 해당 재귀에서 cnt를 리턴하고 해당 함수는 종료
- 그리고, 해결되지 않은 나머지 함수에서는 자동으로 None을 리턴
- 사실 함수에 global변수를 사용하는 것은 좋지 않으나 코딩테스트에서는 사용해도 무관하니 global 변수로 cnt를 선언하고, 함수에서는 해당 변수를 재할당 한 뒤, return None인 방식으로 동작하도록 작성해도 됨
return None, return, return을 사용하지 않을 때 비교
python 함수에서 None을 리턴하는 방법 3가지
def return_case_1():
return
def return_case_2():
return None
def return_case_3():
test_a = 11) return을 사용해야 할 때
def find_prisoner_with_knife(prisoners):
for prisoner in prisoners:
if "knife" in prisoner.items:
prisoner.move_to_inquisition()
return # no need to check rest of the prisoners nor raise an alert
raise_alert()- 칼을 가진 감옥수를 찾는 함수
- for loop를 돌면서 탐색에 성공하면 for문을 다 돌지 않고 return을 통해서 break
- 리턴되는 None을 따로 사용하는 것이 아닌, 단순히 early return 목적이라면 굳이 return None을 사용할 필요는 없음
- 맥락상 break와 유사한 효과를 내기 때문에 자주 사용
- 무언가를 리턴한다는 의미보다는 실행 중단의 의미가 더 큼
2) return None을 사용해야 할 때
- 목적으로 하는 대상이 아닌 경우에는 명시적으로 None값을 리턴해줘야 함
FRUITS = {"banana", "apple"}
def get_some_fruit(fruit):
if fruit in FRUITS:
return fruit
return None
if __name__ == "__main__":
if get_some_fruit("banana") is not None:
print("이것은 과일 입니다")
else:
print("이것은 과일이 아닙니다")- 위 함수의 의도는 None 이 아닐 때 과일임을 나타내는 프린트 문을 출력하고, None 일 때는 과일이 아님을 나타내는 프린트 문을 출력하고자 하는 것
→ 이럴 때는 그냥 return보다는 return None을 써줘서 명시적으로 None을 리턴함을 알려주는 것이 좋다.
3) return을 사용하지 않을 때 → 자동으로 Return None
def set_some_fruit(fruit):
fruits = []
if is_fruit(fruit):
fruits.append(fruit)- 함수가 무언가를 반환하는게 목적이 아닌, 단순 연산의 목적일 경우
- 위 예시에서는 과일인지를 판별한 후, 과일이면 fruits 리스트를 넣으면 return을 따로 적지 않아도 위 함수가 의도한 동작을 정상적으로 마쳤지 때문에 return을 사용하지 않음
- void 타입의 함수가 동작하는 것과 같다
- 연산이 끝난 후 연산 성공이나 실패를 반환해야 한다면 달라지겠지만, 그게 아니라 단순히 글로벌 변수 연산이 목적이라면 사용하지 않는 경우가 있음
- 추가: 함수 이름의 측면에서 봤을 때 set을 하였는데 return을 하는 것은 좀 어색한 느낌
- 위 예시에서는 과일인지를 판별한 후, 과일이면 fruits 리스트를 넣으면 return을 따로 적지 않아도 위 함수가 의도한 동작을 정상적으로 마쳤지 때문에 return을 사용하지 않음
예시
from collections import deque
def find_loction(location, i):
if location == i:
return True
else:
return False
def is_printe(q, count):
print("start~!")
print(q)
if len(q) == 0:
return count
if q[0][0] >= max(q)[0]:
print(max(q))
count += 1
if q[0][1]:
print(q[0][1])
print(count)
return count
q.popleft()
is_printe(q, count)
else:
check = q.popleft()
q.append(check)
is_printe(q, count)
def solution(priorities, location):
pri = [[prio, find_loction(location, idx)] for idx, prio in enumerate(priorities) ]
que = deque(pri)
answer = 0
answer = is_printe(que, 0)
return answer
print(solution([2, 1, 3, 2],1))- 여기서 결과적으로 return 값이 none → 이유를 알아보고 수정해보자
- 함수 안에서 다시 함수를 호출할 때 return 이란 키워드를 붙이지 않으면 none이라는 걸 암시함
is_printe(q, count)앞에 return이 없어서is_printe(q, count)다음 줄에return None이 있다고 간주함 → 결과값이 None으로 나오는 이유
- is_printe(q, count) 앞에 return을 붙여주면 잘 됨
from collections import deque
def find_loction(location, i):
if location == i:
return True
else:
return False
def is_printe(q, count):
print("start~!")
print(q)
if len(q) == 0:
return count
if q[0][0] >= max(q)[0]:
print(max(q))
count += 1
if q[0][1]:
print(q[0][1])
print(count)
return count
q.popleft()
return is_printe(q, count)
else:
check = q.popleft()
q.append(check)
return is_printe(q, count)
def solution(priorities, location):
pri = [[prio, find_loction(location, idx)] for idx, prio in enumerate(priorities) ]
que = deque(pri)
answer = 0
answer = is_printe(que, 0)
return answer
print(solution([2, 1, 3, 2],1))결론
- 위에서 살펴본 함수는 아래처럼 작성하는 게 올바름
def dfs():
if 재귀 종료 조건:
return cnt
return dfs()
2 B R 0 2 B