[인공지능사관학교] Python
Python
특징
- 쉽고 간단한 문법: 읽기 쉽고 배우기 쉬움
- 다양한 활용 가능: 웹 개발, 데이터 분석, 인공지능, 게임 개발 등
- 현재 데이터 분석, 인공지능 분야에서 가장 많이 사용
- 우리나라 웹 개발은 JAVA
- 오픈 소스: 무료로 누구나 사용 가능
- 객체 지향 프로그래밍(OOP) 지원: 코드 재사용 용이
- 학술적으로 객체 지향 프로그래밍의 개념을 익히고 싶다면 JAVA, C++까지 하는 게 좋다고 함
- 코드를 재사용한다 == 남이 만들어 놓은 메서드나 함수를 가져다 쓴다는 개념(메서드, 함수를 만들어 놓고 이를 여러 번 재사용)
- 강력한 커뮤니티와 라이브러리 지원: 많은 개발자가 사용
Q.
객체 지향이라는 말이 하나의 큰 덩어리가 하나의 결과를 완성하는게 아니라 여러 작은 덩어리로 하나의 결과를 완성하는걸로 이해하면 쉬울까요?
그렇기 때문에 여러 작은 덩어리들을 뜯어서 또다시 재사용 하기 용이하다 이해하면 되구요?!
A.
아닙니다. 단순히 '덩어리에 뭉친다', '덩어리가 여러 개 뭉친 것'이라고 보면 안 되고 "여러 가지 성질을 가진 조각들"이 한 덩어리 안에 뭉쳐져 있는 것이라 생각하는 쪽이 더 좋을 것 같습니다.
큰 문제를 작게 쪼개는 것이 아니라, 먼저 작은 문제들을 해결할 수 있는 객체들을 만든 뒤, 이 객체들을 조합해서 큰 문제를 해결하는 상향식(Bottom-up) 해결법
객체란 것을 일단 한번 독립성/신뢰성이 높게 만들어 놓기만 하면 그 이후엔 그 객체를 수정 없이 재사용할 수 있으므로 개발 기간과 비용이 대폭 줄어들게 됨
클래스를 프로그래밍 언어에서 만들 수도 있고 가져다 쓸 수도 있고 제어할 수도 있는 기술을 '객체 지향 프로그래밍'이라 함

- 라이브러리
- 재사용 가능한 코드 모음집을 가리키는 포괄적인 용어
- 패키지와 모듈의 집합체
- 패키지: 모듈의 집합(여러 개의 .py 파일을 모아놓은 폴더 개념으로 볼 수 있음)
- 모듈(module): 여러 클래스, 함수, 변수를 가지고 있는 하나의 파이썬 파일(.py)
실제 사용 예시
- 웹사이트 제작: 구글, 인스타그램, 넷플릭스 등
- AI&머신러닝: chatGPT
- 업무 자동화: 엑셀 자동화, 웹 크롤링 등 다양한 자동화 작업 가능
파이썬 실행 방법
인터렉티브 모드(Python Shell)
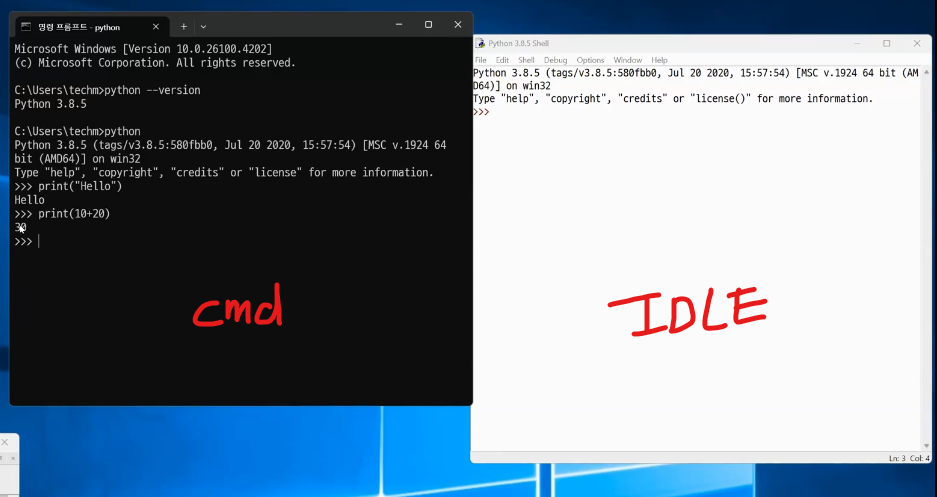
- 빠르게 테스트할 때 유용하지만 코드 저장이 안 됨
- 터미널이나 명령 프롬프트에서 python 또는 python3 입력해 바로 실행
- python IDLE 실행
- IDLE shell은 단방향으로 밖에 안되니 주의
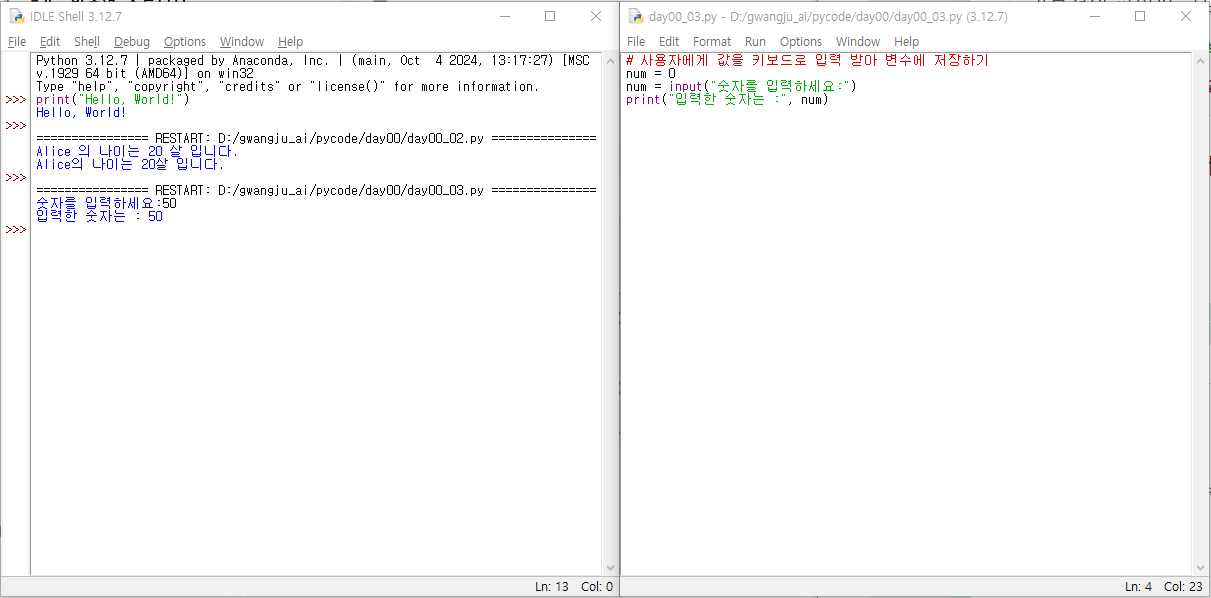
Hello, World! 출력하기
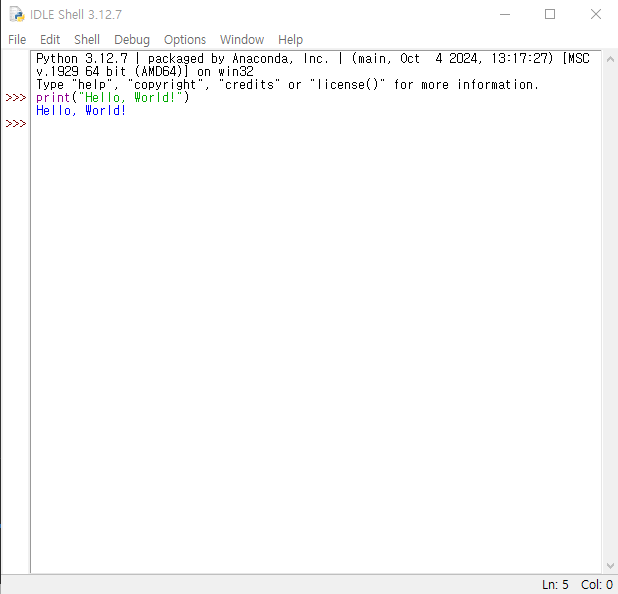
스크립트 파일 실행(.py 파일 생성)
- 실제 개발할 때 주로 사용
hello.py파일 생성 후 코드 작성
- IDLE에서 File>New File
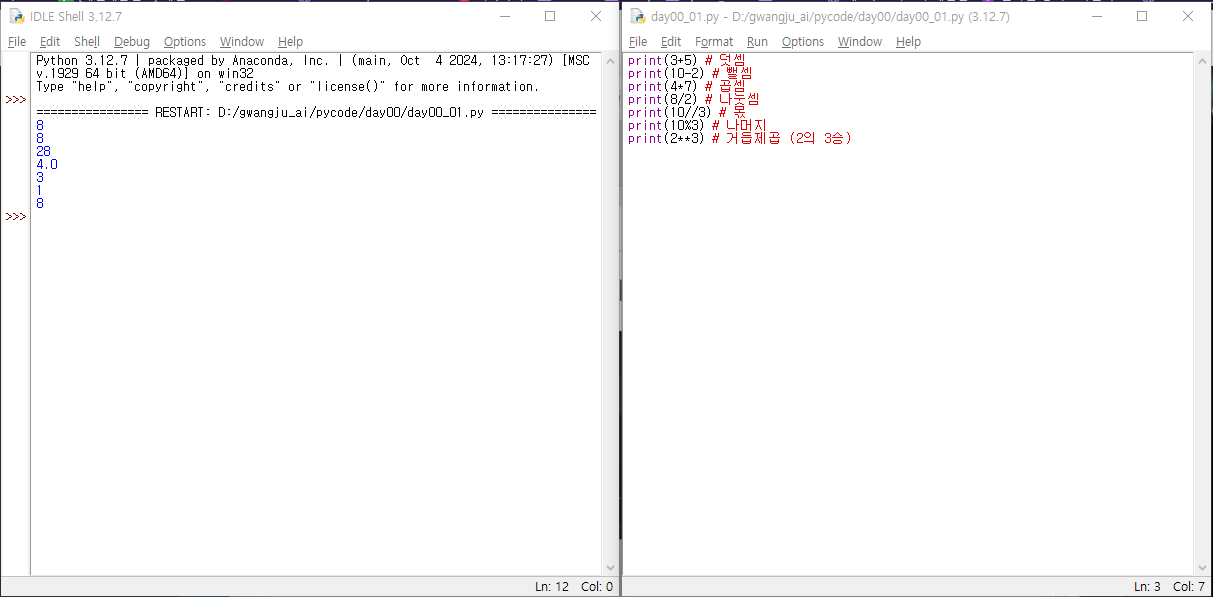
간단한 계산하기
변수 사용해보기
입력받은 내용 출력
Jupyter Notebook(데이터 분석용)
- 코드와 설명을 함께 작성할 수 있는 강력한 도구
pip install jupyter로 설치 → jupyter notebook 명령어로 실행.ipynb파일
vsCode
- 파이썬 프로그램을 코딩(입력하는 작업)하기 위한 에디터, 인터프리터, 실행을 수행하는 통합 관리 툴
Extensions
- Python
- Python Extended
- Code Runner
Setting
- File>Preferences>Settings: Open Settings(JSON)
setting.json
{
"editor.fontSize": 30,
"code-runner.saveFileBeforeRun": true,
"code-runner.runInTerminal": true,
"python.linting.enabled": false,
"python.pythonPath": "C:\\Program Files\\python\\Python39",
"window.zoomLevel": 0,
"terminal.integrated.fontSize": 30,
"terminal.integrated.shell.windows": "C:\\Windows\\system32\\cmd.exe",
"editor.fontFamily": "D2Coding ligature, Consolas, ‘Courier new’, monospace",
"editor.fontLigatures": true,
"code-runner.clearPreviousOutput": true
}-
python.pythonPath": "C:\\Program Files\\python\\Python39설정에 대한 추가설명 -
위의 경로는 ‘파이썬 설치’ 시 지정하였던 경로를 똑같이 지정하여야 함
- ‘파이썬 설치’ 과정에서 ‘C:\Program Files\python\Python39’ 과 같이 입력하였다면 이곳의 설정파일에서는 "python.pythonPath": "C:\Program Files\python\Python39"와 같이 입력
- 다른 점: 폴더와 폴더 사이의 구분자인 \ 을 두 개씩 → 이것은 vsCode에서 가지는 기술 방법의 특징임
-
설정 예시
{
"editor.fontSize": 19,
"editor.fontWeight": 1000,
"code-runner.saveFileBeforeRun": true,
"code-runner.runInTerminal": true,
"python.linting.enabled": false,
"python.pythonPath": "C:\\Program Files\\python\\Python311",
"window.zoomLevel": 0,
"terminal.integrated.fontSize": 19,
"code-runner.clearPreviousOutput": true,
"explorer.confirmDelete": false,
"explorer.incrementalNaming": "smart",
"files.autoSave": "afterDelay",
"command": "workbench.action.terminal.clear",
"workbench.startupEditor": "newUntitledFile",
"workbench.colorTheme": "Visual Studio Light",
"jupyter.alwaysTrustNotebooks": true,
"jupyter.askForKernelRestart": false,
"liveServer.settings.donotShowInfoMsg": true,
"workbench.editorAssociations": {
"*.ipynb": "jupyter-notebook"
},
"python.showStartPage": false,
"python.languageServer": "Pylance",
"notebook.cellToolbarLocation": {
"default": "right",
"jupyter-notebook": "left"
},
"python.defaultInterpreterPath": "C:\\Program Files\\python\\Python311",
"editor.minimap.enabled": false,
"terminal.integrated.scrollback": 1000,
"editor.fontFamily": "D2 Coding ligature, D2Coding, Consolas, 'Courier New', monospace",
"editor.fontLigatures": true,
"editor.mouseWheelZoom": true,
"notebook.lineNumbers": "on",
"explorer.confirmDelete": false,
"explorer.confirmDelete": false,
"security.workspace.trust.untrustedFiles": "open",
"editor.unicodeHighlight.nonBasicASCII": false,
"workbench.editor.empty.hint": "hidden",
"files.associations": {
"*.py": "python"
},
}파일/폴더 관련
- 리눅스, 유닉스 서버에 올릴 때 한글 들어가 있으면 오류 발생하니까(다 깨짐) 절대 한글 쓰지 말 것!
실습
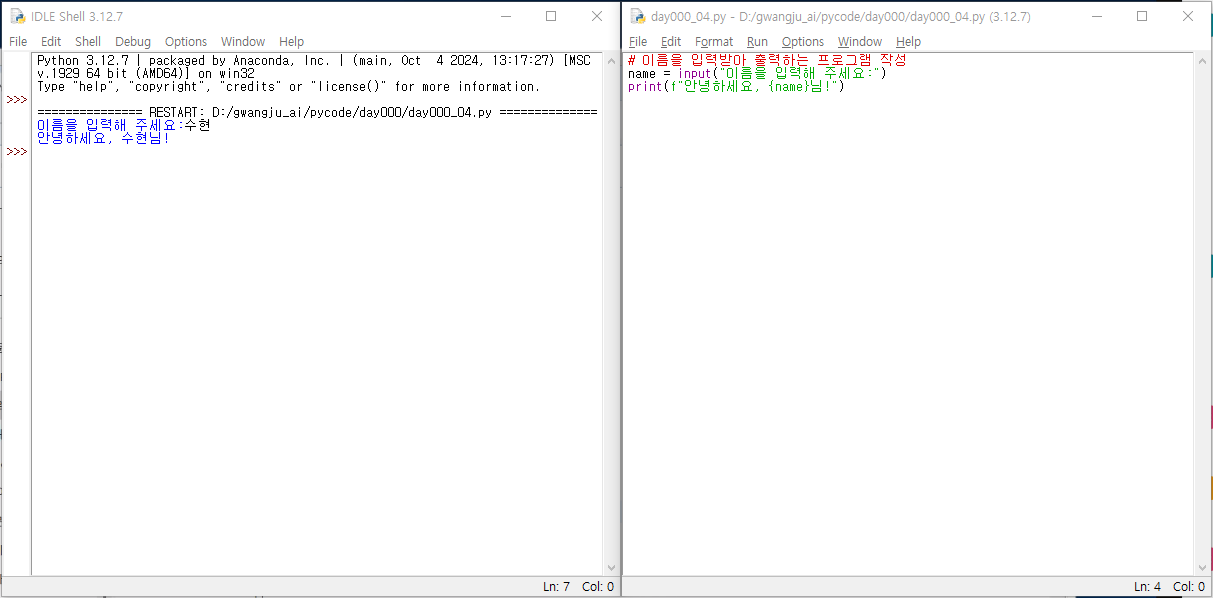
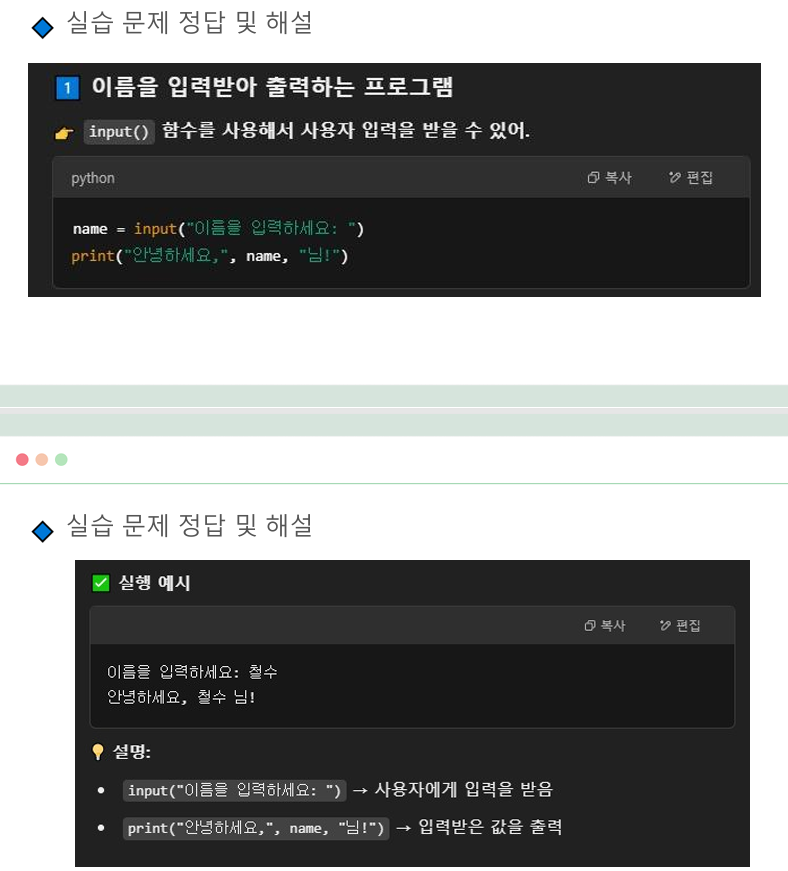
이름을 입력받아 출력
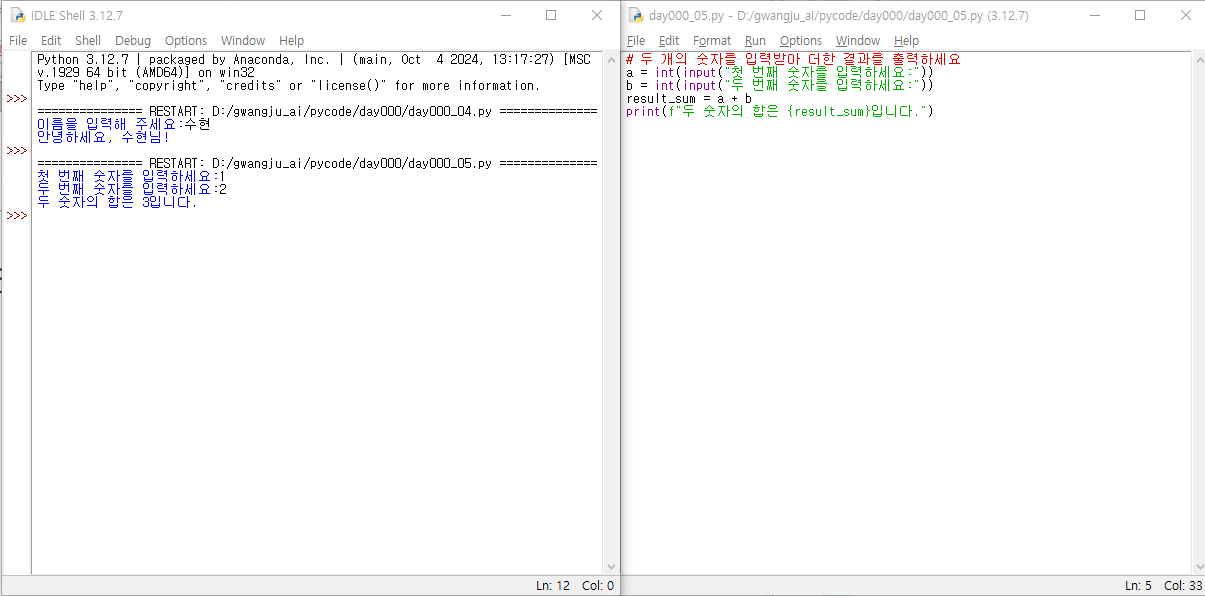
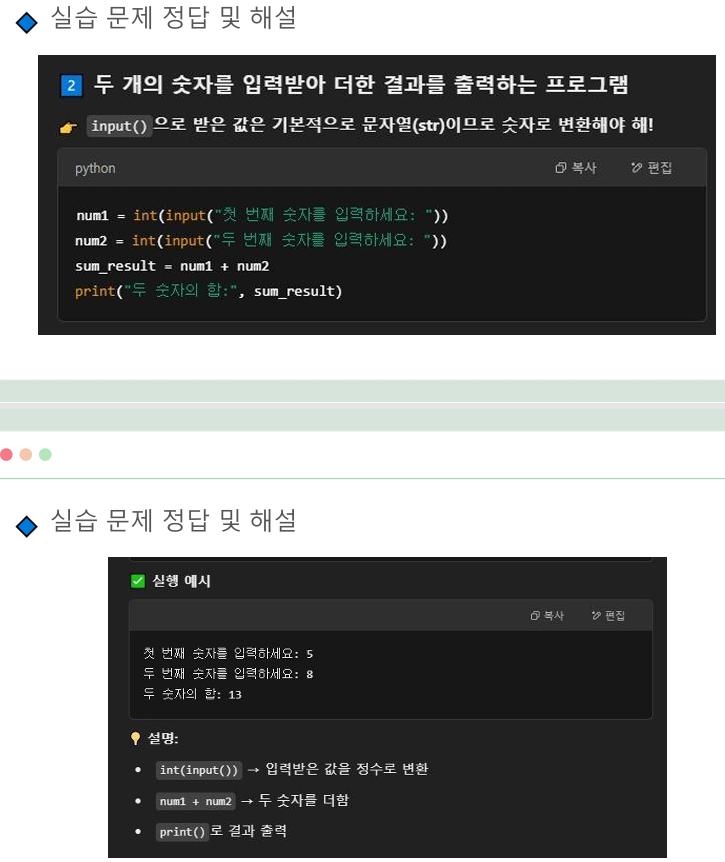
두 개의 숫자를 입력받아 더한 결과를 출력
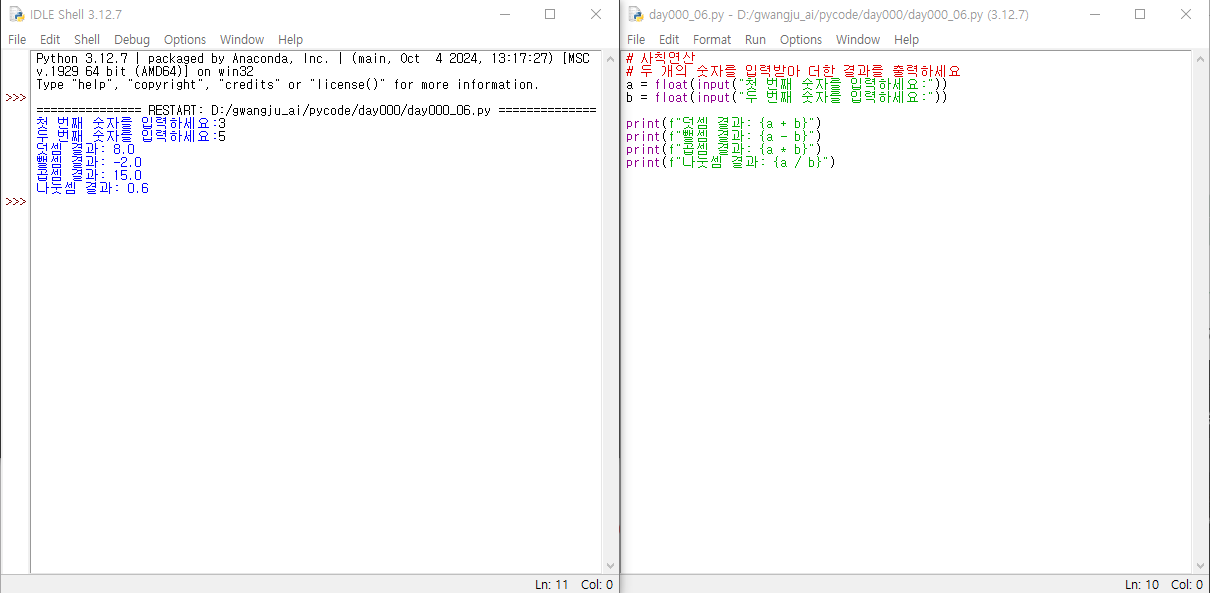
사칙연산(+, -, *, \/)을 수행하는 프로그램 작성
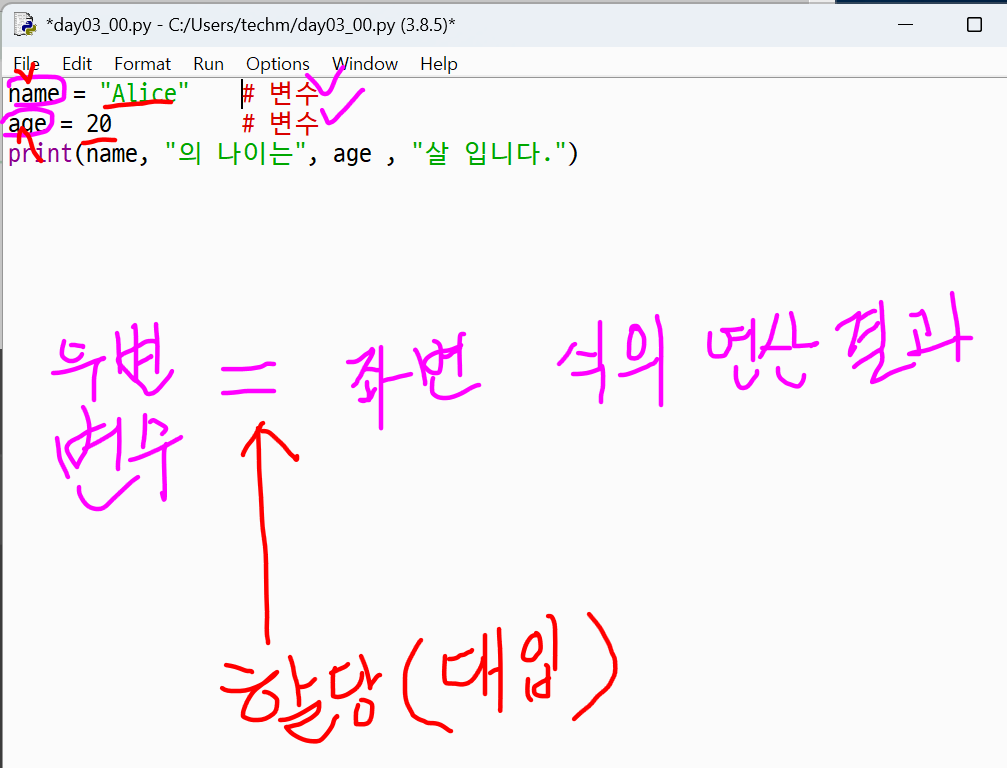
변수
- 데이터(값) 저장 공간
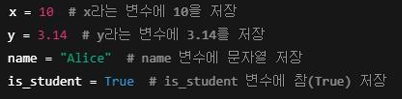
변수 선언과 값 저장
-
변수 선언 및 할당
- 변수를 만들과 값을 저장하는 것
- 변수를 만들과 값을 저장하는 것
-
=연산자- 할당, 대입의 개념
- '같다'가 아니라 값을 저장하는 역할
- 수학 equal에 해당하는 연산자는
==
- 할당, 대입의 개념
-
상수의 특성이 달라서 색이 다름
-
변수명은 규칙을 지켜야 함: 변수 명명 규칙
-
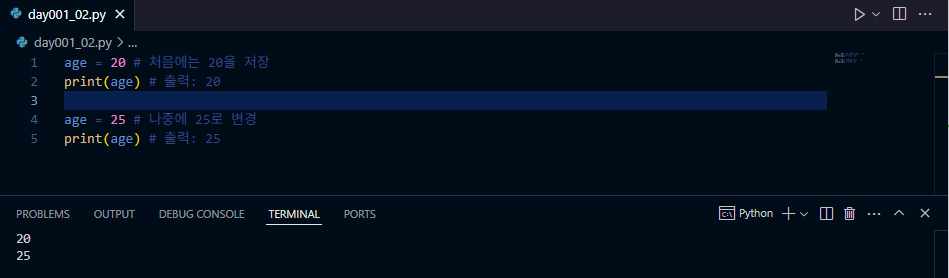
변수에 저장된 값은 언제든 변경 가능
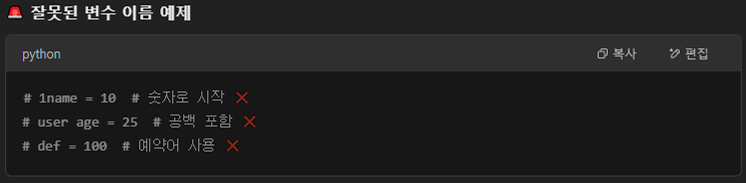
변수 명명 규칙 ★★★★★
- 영서, 숫자, 밑줄(_)만 사용 가능
- 숫자로 시작할 수 없음
- 대소문자를 구별함 → Name과 name은 다름
- 공백 사용 불가능
- 파이썬 예약어(if, while 등) 사용 불가
여러 개의 변수 한 번에 할당
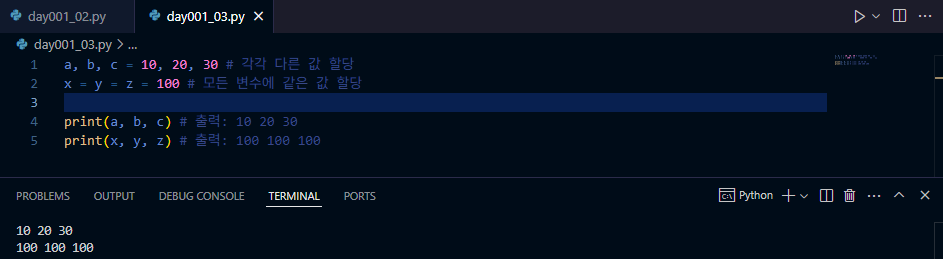
a, b, c = 10, 20, 30와 같은 방식으로 변수들을 동시에 선언하고 값을 할당하는 문법은 파이썬- C, Java, JavaScript 등의 언어에서는 각 변수를 개별적으로 선언하고 값을 할당하는 것이 일반적
int num1 = 10, num2 = 20, num3 = 30;
- C, Java, JavaScript 등의 언어에서는 각 변수를 개별적으로 선언하고 값을 할당하는 것이 일반적
데이터 타입
기본 데이터 타입(자료형)

- 변수에는 여러 종류의 데이터(값) 저장 가능 → 이 값을 구분하는 것을 "데이터 타입" 이라고 함
- 숫자
- 글자
- 참/거짓

- 예약어
int- 정수(Integer)형 변수를 선언할 때 사용
- int 키워드를 사용하여 변수를 선언하면, 해당 변수는 정수 값을 저장하도록 지정됨
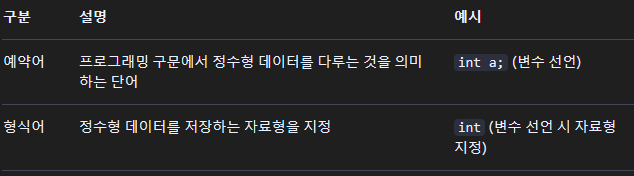
예약어 int와 형식어 int는 모두 프로그래밍 언어에서 정수형 값을 다루기 위해 사용되는 단어이지만, 의미와 역할이 다릅니다.
예약어 int는 특정 언어에서 미리 정의된 단어(keyword)로, 변수 선언이나 함수 반환값 지정 등 프로그래밍 구문을 구성하는 데 사용됩니다. 예를 들어 C, Java, Python 등에서 int는 정수형 변수를 선언할 때 사용하며, 이 예약어는 프로그래머가 임의로 사용할 수 없습니다.
형식어 int는 언어에서 데이터의 종류를 지정하는 데 사용되는 선언어입니다. int는 정수형 데이터, 즉 음수, 0, 양수와 같은 정수 값을 저장하는 자료형을 의미합니다. 예를 들어, 변수 선언 시int a;처럼 사용하며, 이 형식어를 통해 변수가 정수형 데이터를 저장할 수 있도록 정의됩니다.
요약하면, 예약어 int는 특정 프로그래밍 구문에서 정수형 데이터를 다루는 것을 의미하는 단어이며, 형식어 int는 정수형 데이터 자체를 지정하는 자료형을 의미합니다.
C언어
# 여러 변수 동시 선언 int age, height, weight;→ 동일한 데이터 형식을 가지는 변수의 그룹화: 동일한 데이터 형식을 가지는 변수를 그룹화하여 선언(변수의 이름을 쉼표로 구분하여 나열하고 마지막에 세미콜론을 사용하여 선언을 마무리)
# 여러 변수 선언 및 초기값 지정 int num1 = 10, num2 = 20, result;# 변수 선언과 동시에 값 변경 int num = 10; num = 20;
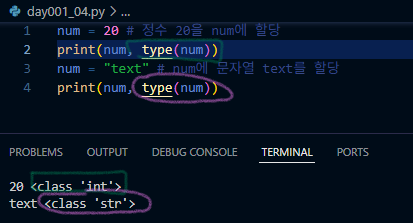
형변환
TIP: 터미널에
cls입력하면 실행 결과 지워짐(clear screen)
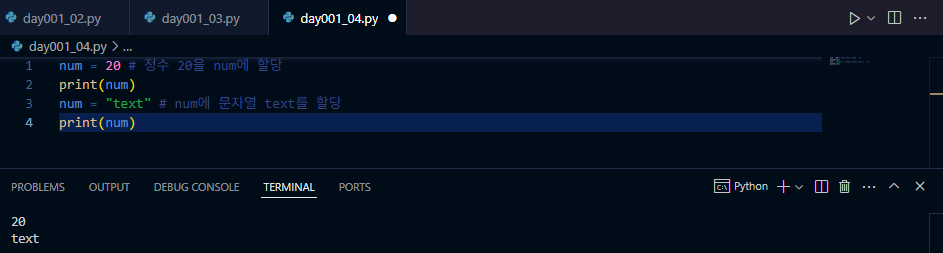
a = 10 # 정수(int)
b = float(a) # float()는 형변환 함수임 → 실수(float)로 변환
print(a, type(a))
print(b, type(b))
num = 100
text = str(num) # 문자열 형변환 함수를 사용함 → 숫자를 문자열로 변환
print(text, type(text)) # 출력: '100'
s = "3.14" # 문자열 '3.14' // 실수 3.14가 아님!
print(s, type(s))
f = float(s) # 실수형 형변환함수 사용 → 문자열을 실수로 변환
print(f, type(f))연습문제
1. 변수 선언과 출력
요구사항
다음 조건을 만족하는 변수를 만들고 출력하세요.
name변수에"김철수"저장- 저장 → '할당'이라는 개념과 유사
=: 할당 연산자, 대입 연산자
age변수에25저장height변수에180.5저장is_student변수에False저장
2. 변수 값 변경
요구사항
x = 10을 선언하고 출력- 출력 → print()
x의 값을20으로 변경하고 다시 출력
3. 데이터 타입 확인
요구사항
아래 변수들의 데이터 타입을 확인하는 코드를 작성하세요.
a = 50
b = 5.5
c = "Hello"
d = True→ type() 함수 사용
4. 형 변환
요구사항
다음 코드를 실행하고 결과를 예상해보세요.
x = "123"
y = int(x)
z = float(y)
print(y, z)# 1번 name = "김철수" age = 25 height = 180.5 is_student = False print(f"name: {name}, Age: {age}, height: {height}, is_student: {is_student}")
답
#연습문제-1
print("\n연습문제-1")
name = '김철수'
age =15
height = 180.5
is_student = False
print('이름 :', name)
print('나이 :', age)
print('키 :', height)
print('학생여부 :', is_student)
#
#연습문제-2
print("\n연습문제-2")
x = 10
print(x)
x = 20
print(x)
#
#연습문제-3
print("\n연습문제-3")
a = 50
b = 5.5
c = 'Hello'
d = True
print(a, type(a))
print(b, type(b))
print(c, type(c))
print(d, type(d))
#
#연습문제-4
print("\n연습문제-4")
x= "123"
y= int(x)
z = float(y)
print(y,z)추가: 입출력과 이스케이프 문자
\n- 출력되지는 않지만 줄바꿈 기능을 하는 특수 문자
- 상수와 문자열과 리터럴(literal)
- 상수와 리터럴 둘 다 변하지 않는 값(데이터)
- 상수는 변하지 않는 '변수'를 의미하며(메모리 위치) 메모리 값을 변경할 수 없음, 리터럴은 변수의 값이 변하지 않는 '데이터'(메모리 위치 안의 값)
final int a = 1→ a: 상수, 1: 리터럴- 인스턴스는 동적으로 사용되기 위해 작성되므로 리터럴이 될 수 없지만 특정 객체(Immutable class, VO class)에 한해서는 리터럴이 될 수 있음
- 리터럴(literal)은 프로그래밍 언어에서 소스 코드 내에서 특정한 값을 직접 나타내는 표기법
- 즉, 변수나 상수 등에 직접 할당되는 고정된 값을 의미하며, 정수, 실수, 문자, 문자열, 불리언 등 다양한 자료형에 대해 사용
- "abc"와 같은 문자열을 '객체 리터럴/리터럴'이라 표현
- 상수와 리터럴 둘 다 변하지 않는 값(데이터)
- 출력 형식 다양화
응용 데이터 타입
- 컬렉션(Collection) 자료형
- 응용 자료형이라고도 함
- 여러 개의 데이터를 한 번에 저장하는 자료형
- 기본 데이터 타입(int, float, str, bool) → 하나만 저장
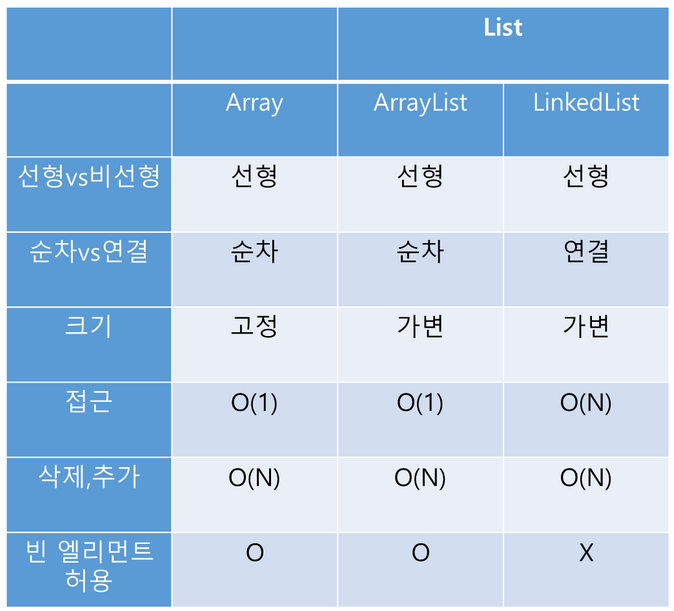
리스트(List)
- 여러 개의 데이터를 저장할 수 있는 자료형
- 여러 개의 데이터를 저장하는 배열과 비슷
- 리스트 안에는 정수, 실수, 문자열, 다른 리스트까지도 저장 가능
생성과 사용법
# 리스트 만들기
numbers = [1, 2, 3, 4, 5]
fruits = ["apple", "banana", "cherry"]
mixed = [10, "hello", 3.14, True]
print(numbers) # 출력: [1, 2, 3, 4, 5]
print(fruits[1]) # 출력: banana
print(mixed[-1]) # 출력: True조작 (추가, 삭제, 정렬)
numbers.append(6) # 리스트 끝에 추가
print(numbers) # 출력: [1, 2, 3, 4, 5, 6]
numbers.remove(3) # 값 3 삭제
print(numbers) # 출력: [1, 2, 4, 5, 6]
numbers.append(3) # 리스트 끝에 추가
print(numbers) # 출력: [1, 2, 4, 5, 6, 3]
numbers.sort() # 오름차순 정렬
print(numbers) # 출력: [1, 2, 3, 4, 5, 6]강사님 코드
numbers = [1,2,3,4,5]
fruits=["apple", 'banana', 'cherry']
mixed = [10, 'hello', 3.14, True]
numbers.append(6)
print(numbers)
numbers.remove(3)
print(numbers)
numbers.sort()
print(numbers)
numbers.reverse()
print(numbers).reverse(): 역순 정렬(내림차순 정렬)
참고할 만한 코드: 다른 학우분이 정리해주신 내용
numbers = [1,2,3,4,5]
fruits = ['apple', 'banana', 'cherry']
mixed = [10, 'hello', 3.14, True]
numbers.append(6)
numbers.remove(3)
numbers.sort()
numbers.reverse() # 뒤집기 함수
fruits.append('orange')
fruits.append('퐈인애뽀')
fruits.remove(1) # 1이라는 값이 없어서 에러
fruits.remove("orange")
fruits.reverse() # 뒤집기 함수
def add(numbers):
return numbers
class Person:
def __init__(name):
self.name = name
"""
# link: # https://docs.python.org/3/tutorial/datastructures.html
# 만약 해당 값이 리스트에 없을 경우 ValueError 가 발생함.
# > 만약 인덱스로 값을 제거하고 싶으면 pop() 이나 del 을 사용하면 됌.
# mixed 의 경우 타입 자체가 섞여서 에러가 발생함.
# > 정렬은 순위를 메길수 있는 타입끼리만 정렬이 가능하다는걸 확인함.
# 람다 사용: 값을 개별적으로 접근하면서 Sorting, 이때 기준은 '타입'의 알파벳 순서임.
# > 예: bool > float > function > int -> str
# > 이 경우는 리스트의 내부를 전부 str 로 cast 한다음 알파벳 순서라는 기준하에 정렬하도록 구현
"""
mixed.append(add(numbers))
mixed.append(Person("윤정기"))
mixed.remove(1) # ValueError, 1 이라는 값이 없어서 에러
mixed.sort()
result = sorted(mixed, key=lambda x: (type(x).__name__, str(x)))
print(numbers)
print(fruits)
print(mixed)튜플(Tuple)
- 변경 불가능한 리스트
- 리스트와 거의 비슷하지만 한 번 생성하면 값을 변경할 수 없음
특징
- 읽기 전용
- 변경 불가능
- 리스트보다 속도가 빠름
- 리스트보다 메모리 사용이 적음
생성과 사용법
coordinates = (10, 20) # (x, y) 좌표
colors = ("red", "green", "blue")
print(coordinates[0]) # 출력: 10
print(colors[-1]) # 출력: blueQ: 그럼 튜플은 어느 때에 사용하는 건가요? 값을 변경할 수 없으면 리스트와 비교했을 때 특정한 쓰임새가 있는 건가요
A: 튜플이 연산이 더 빨라서 내용의 변경이 없을 때에는 튜플을 쓰는게 더 좋습니다
참고로 요소의 숫자가 10,000개 이상이 되는 연속형 자료인 경우에는 리스트 보다 튜플인 경우가 훨씬 처리속도가 빠르고 저장장소의 용량도 적습니다.
그래서 요소 각각의 내용에 대한 변동성이 적은 경우에는 튜플이 유리합니다.
튜플로 사용하는 예시는 위도, 경도, 만세력, 등의 변동성이 없으면 이웃하는 요소의 갯수가 많은 정보입니다.
강사님 코드 및 기타 추가 내용
coordinates = (10,20)
colors = 'red', 'green', 'blue'
print(coordinates[0])
print(colors[-1])
print(type(coordinates))
print(type(colors))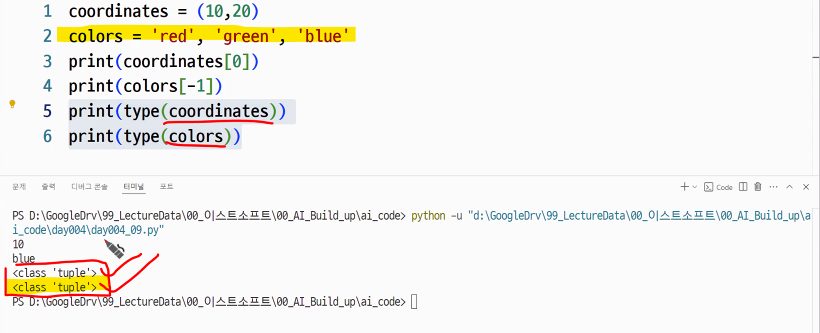
- 괄호 생략하고 써도 "튜플"임
- 튜플과 리스트 속도 차이
- List와 Tuple: 배열(array)이라는 자료구조 특성을 가짐
- 배열(array)
- 정해진 고유의 순서에 따라 데이터를 나열한 것
- 배열 메모리 할당 방식 → 연속적인 메모리에 정렬되어 있음
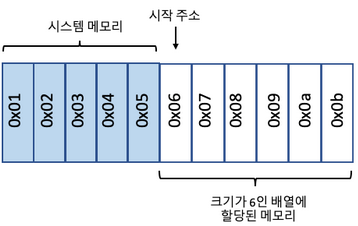
→ 순서가 있기 때문에 특정 위치의 데이터에 바로 접근 가능(O(1) 시간 복잡도)
- List와 Tuple의 차이
- List: 저장하는 데이터나 배열 크기를 변경할 수 있는 동적 배열 → 동적 배열이 배열의 크기를 변경하는 resize 연산을 지원하기 때문에
append함수로 데이터 추가 가능 - Tuple: 내용이 고정된 변경 불가능한 정적 배열 → 정적이기 때문에 파이썬이 내부적으로 수행하는 '리소스 캐싱'이 가능
- List: 저장하는 데이터나 배열 크기를 변경할 수 있는 동적 배열 → 동적 배열이 배열의 크기를 변경하는 resize 연산을 지원하기 때문에
- 리스트 크기 할당 방정식
M = (N>>3) + (3 if N < 9 else 6)
# N | 0 | 1-4 | 5-8 | … | 991-1120 |
# M | 0 | 4 | 8 | … | 1120 |→ 배열의 크기가 N일 때 1개의 요소가 더 추가되면 배열의 크기가 N+1이 되는 것이 아니라 나중을 위한 여유분으로 N보다 큰 M만큼의 메모리를 할당(데이터가 추가될 때마다 메모리 할당 및 복사 요청이 오는 걸 줄이기 위함 ▶ 복사 비용이 크기 때문)
→ 만약 우리가 데이터를 991개만 사용하는 리스트를 반복적으로 새로운 변수에 할당하는 프로그램이 있다면 사실상 각 변수는 메모리를 1120개 데이터를 사용하는 것과 같아 조심해야 함!
- Tuple은 크기를 변경할 순 없어도 두 개의 튜플을 새로운 튜플로 합칠 수 있음 → 정확히 합친 만큼의 메모리를 할당: List와 달리 여유공간 메모리를 주지 않음 → 따라서 정적인 데이터(e.g. 주민등록번호, 여권번호 등)를 쓸 때 더 가볍고 효과적
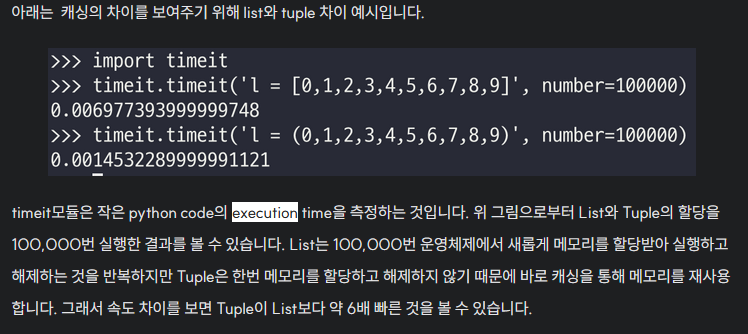
import time
l = list(range(1000000))
t = tuple(range(1000000))
start = time.time_ns()
for i in l:
_ = i
end = time.time_ns()
print(f"List iteration: {end - start}")
start = time.time_ns()
for i in t:
_ = i
end = time.time_ns()
print(f"Tuple iteration: {end - start}")집합(Set)
- 중복 없는 데이터 저장
- 중복을 허용하지 않는 자료형
- 순서가 없음 → 인덱스 접근 불가
- 같은 값이 여러 번 저장되지 않음
특징
- 중복 제거 기능이 있음
- 순서가 없음
- 인덱스로 접근 불가
- 빠른 검색 기능 제공
생성과 사용법
unique_numbers = {1, 2, 3, 3, 4, 5, 5}
print(unique_numbers) # 출력: {1, 2, 3, 4, 5}
# 집합 연산
A = {1, 2, 3}
B = {3, 4, 5}
print(A | B) # 합집합: {1, 2, 3, 4, 5}
print(A & B) # 교집합: {3}
print(A - B) # 차집합: {1, 2}딕셔너리(Dictionary)
- 키(key)와 값(value) 저장
- 이름표와 데이터를 함께 저장하는 자료형
- "이름": "홍길동", "나이": 25처럼 키-값 쌍을 저장
- 인덱스의 시작을 프로그래머가 정할 수 있는 자료형
- 여기서 인덱스는 '키'를 의미
- 키는 리스트, 튜플에서 인덱스가 하는 기능을 수행
- 키는 프로그래머가 부여 OK
- 여기서 인덱스는 '키'를 의미
사용 빈도가 많은 연속형 자료형 1,2순위를 다툼
리스트/딕셔너리>>튜플>셋
Q. 딕셔너리 기능은 관리자 페이지 같은곳에서
특정 정보로 조회 하는것에 응용 되는건가요?
예를 들면 회원 검색 할때 생년월일이나 핸드폰 뒷번호 4자리만 검색해도 해당 회원이 검색되는 기능이 딕셔너리의 기능이라고 생각 하면 되는건가요?
A.
관리자 페이지에서 회원 검색 예제를 생각해보면, 회원 데이터가 엑셀에 들어가 있는 구조로 전제를 잡아놓고 시작하면 될 것 같아요.
엑셀에서 A~Z 까지 회원 데이터(이름, 나이,,) 등이 있다고 했을 때 딕셔너리의 키와 같은 맥락은 엑셀 Row(행)에 명시된 행 번호와 같은 맥락이라고 생각하시면 될 것 같습니다.
회원 검색을 하고자한다면:
서버 -> 엑셀 조회 -> { 회원 목록 } -> 보여주기(web) 이런식으로 진행할텐데, 엑셀에서 회원을 가져올때 데이터 포맷이 필요해요. Xml 로도 가져올수있고, json 형태로 가져올수도 있습니다. 이때 json 과 딕셔너리의 포맷 구조가 같아서 보통 json(딕셔너리)로 가져옵니다. 이때 각 회원의 식별 가능한 식별키로 유저를 분류합니다.Users: [ {id: 1, name: “박찬주”}, {Id: 2, name: “윤정기”} ]이때 식별 가능한 키는 id 입니다. 이름은 중복이 가능하니까요. 그래서 보통 데이터베이스 다룰 때 이 식별키를 구분할 수 있도록 사전에 처리해줘요
핸드폰 뒷번호 4자리만으로 Unique 값을 검출하기엔 무리가 있어서 핸드폰 번호 자체(010-Xxxx-xxxx) 자체를 유니크키로 쓰기도 합니다. 이건 구현하기 나름이라서요. 가능하다면 식별 가능하고 중복이 없는 상태의 식별자를 딕셔너리의 키값으로 두고 사용한다고 생각하시면 될 것 같아요!
인증과 권한을 구현할때도 식별 가능한 키 값 여러개를 두고 전략을 구성하기도 하는데, 저는 보통 사용자의 이메일은 식별가능한 식별키라고 생각해서 데이터베이스에 유니크값 설정하고 인증권한 설정시 Email 자체를 식별키로 두기도 합니다.
딕셔너리를 사용할 때(보통 문제는 없지만) 내부적으로 해쉬테이블 자료구조를 사용하기 떄문에 해쉬 충돌에 대한 개념은 알고 있어야 한다고 생각합니다. 링크
특징
- 키는 중복 불가능, 값은 중복 가능
- 데이터를 빠르게 찾을 수 있음
생성과 사용법
student = {"name":"Alice", "age":25, "grade":"A"}
print(student["name"]) # 출력: Alice
print(student.get("age")) # 출력: 25조작 (추가, 수정, 삭제)
student["major"] = "Computer Science" # 새 키-값 추가
student["age"] = 26 # 값 변경
del student["grade"] # 삭제
print(student) # 출력: {"name":"Alice", "age":26, "major": "Computer Science"}연습문제
1. 리스트 활용
아래 조건을 만족하는 리스트를 만들고 조작하세요.
fruits리스트에"apple", "banana", "cherry"저장"banana"를"grape"로 변경"cherry"삭제"orange"추가- 리스트 출력
2. 튜플 활용
다음
colors튜플에서"blue"를 출력하는 코드를 작성하세요.
colors = ("red", "green", "blue", "yellow")3. 집합 활용
두 개의 집합이 있을 때 합집합, 교집합, 차집합을 구하세요.
A = {1, 2, 3, 4}
B = {3, 4, 5, 6}4. 딕셔너리 활용
아래 조건을 만족하는
student딕셔너리를 만들고 수정하세요.
- "이름"을 "김철수"로 저장
- "나이"를 20으로 저장
- "학교"를 "서울대학교"로 저장
- "학과"를 추가하고 "컴퓨터공학과"로 설정
- "나이"를 21로 변경
- "학교" 정보 삭제
작성한 코드
print("\n연습 문제 1")
fruits = ["apple", "banana", "cherry"]
fruits[1] = "grape"
fruits.remove("cherry")
fruits.append("orange")
print(fruits)
print("\n연습 문제 2")
colors = ("red", "green", "blue", "yellow")
print(colors[2])
print(colors[-2])
print("\n연습 문제 3")
A = {1, 2, 3, 4}
B = {3, 4, 5, 6}
print(f"합집합: {A|B}")
print(f"교집합: {A&B}")
print(f"차집합: {A-B}")
print("\n연습 문제 4")
student = {"이름": "김철수", "나이": 20, "학교": "서울대학교"}
student["학과"] = "컴퓨터공학과"
student["나이"] = 21
del student["학교"]
print(student)보충
depth 계산 등에서, 특정 요소가 어떤 목록 안에 있는지 여부를 확인할 때 사용할 수 있는 방법은 여러가지가 있습니다.
이 방법에 대한 간단한 속도 테스트!
>>> t1 = 0
>>> t2 = 0
>>> t3 = 0
>>> t4 = 0
>>> a = []
>>> for n in range(1, 7000000) :
a.append(n)
>>> b = tuple(a)
>>>
>>> for n in range(7000000-100, 7000000 + 50) :
t = time.time()
try :
x = a.index(n)
except ValueError :
continue
t1 += time.time()-t
>>> for n in range(7000000-100, 7000000 + 50) :
t = time.time()
x = n in a
t2 += time.time()-t
>>> for n in range(7000000-100, 7000000 + 50) :
t = time.time()
x = b.count(n)
t3 += time.time()-t
>>> for n in range(7000000-100, 7000000 + 50) :
t = time.time()
try :
x = b.index(n)
except ValueError :
continue
t4 += time.time()-t
>>> print t1, t2, t3, t4
11.1800000668 17.0140001774 16.9639995098 10.7339997292
6999999 개의 항목을 갖는 리스트 안에서 특정 값을 찾는 테스트를 위한 코드입니다.
t1 : list에서 index, try / except 구문 이용하는 방법
t2 : list에서 in 연산자 사용하는 방법 (사용하기 제일 간편하죠!ㅋ)
t3 : tuple에서 count를 이용하는 방법
t4 : tuple에서 index, try / except 구문 이용하는 방법
뭐.. 비교를 위해서 조금 비효율적인 방법을 포함하긴 했는데. 속도 차이는 위와 같습니다!
tuple이 생각보다 빨라요ㅇㅇ
(count같은 비효율적인 방법을 사용해도 in 보다는 빠릅니다!)