정렬(Sorting)
정렬 알고리즘
- 섞여 있는 데이터를 특정한 기준에 따라 순서대로 나열하는 것
- 시간 복잡도에 따라 성능이 좌우됨
- 성능이 좋을수록 구현 방법이 어려움
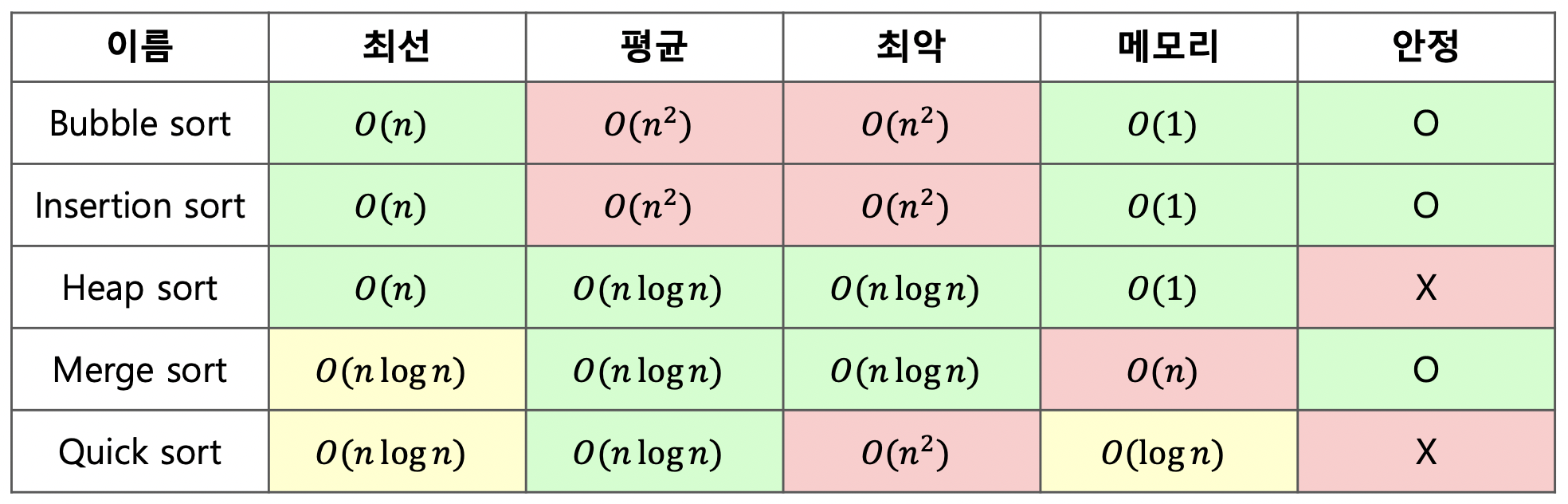
시간 복잡도 O()
: 정렬할 자료의 수가 늘어나면 제곱에 비례해서 증가
- 버블 정렬(Bubble Sort)
- 선택 정렬(Selection Sort)
- 삽입 정렬(Insertion Sort)
버블 정렬(Bubble Sort)
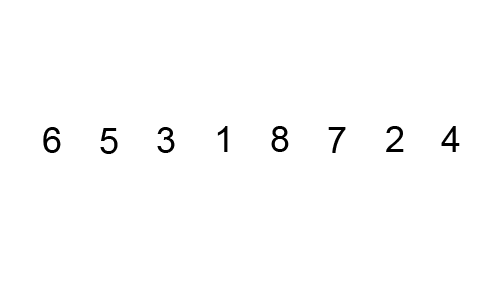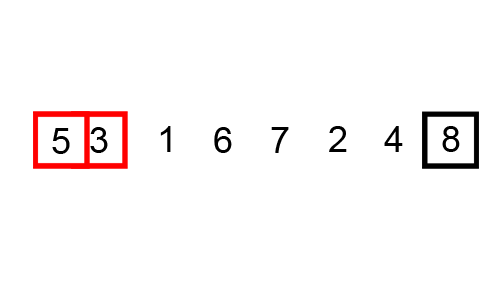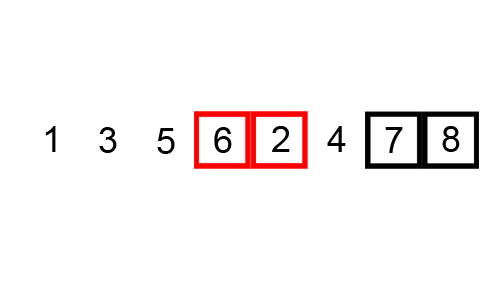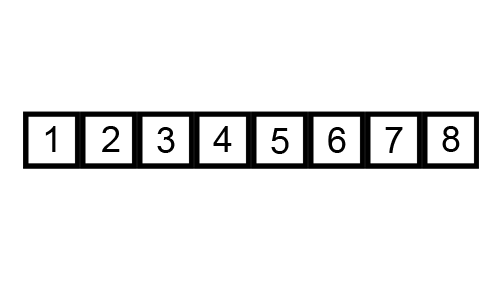
- 인접한 두 수를 비교하며 정렬(바로 옆에 있는 것과 비교)
- 앞에서부터 시작해 큰 수를 뒤로 보내 뒤가 가장 큰 값을 가지도록 완성
- 뒤에서부터 반복해 앞의 작은 값부터 정렬을 완성
- 구현은 쉽지만 O()의 느린 성능이라 효율성이 매우 낮음
예시
l = [
[1, 10, 'leehojun']
, [20, 30, 'hojun']
, [10, 20, 'weniv!']
, [1, 2, 'hello world']
, [55, 11, 'sun']
,
]
# 글자 수가 작은 리스트부터 큰 리스트 순으로 정렬
for i in range(len(l)):
for j in range(len(l)-1):
if len(l[j][2]) > len(l[j+1][2]):
l[j], l[j+1] = l[j+1], l[j]
print(l)선택 정렬(Selection Sort)

- 한 바퀴 돌 때 가장 작은 값을 찾아 맨 앞과 교환하는 방식
- 앞에서부터 정렬해 나가는 특성
- 버블 정렬과 마찬가지로 성능은 최악
삽입 정렬(Insertion Sort)
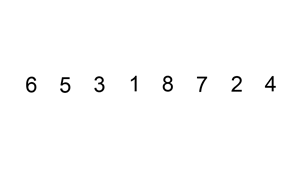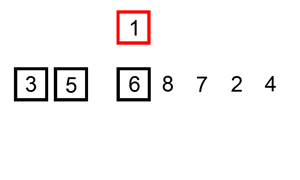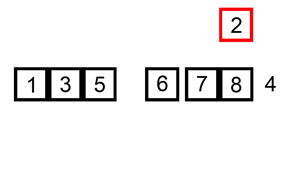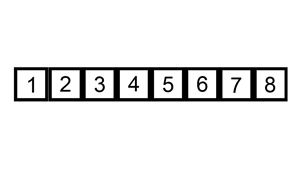
- 정렬된 데이터 그룹을 늘려가며 추가되는 데이터를 알맞은 자리에 삽입하는 방식
- 자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 삽입함으로써 정렬을 완성
- 성능은 버블 정렬, 선택 정렬과 마찬가지(최악의 성능)
예시
l = [[1, 10, 'leehojun'],
[20, 30, 'hojun'],
[10, 20, 'weniv!'],
[1, 2, 'hello world'],
[55, 11, 'sun']]
for i in range(1, len(l)):
key = l[i]
j = i - 1
# key의 문자열 길이가 더 짧을 때 앞으로 이동
while j >= 0 and len(l[j][2]) > len(key[2]):
l[j + 1] = l[j]
j -= 1
l[j + 1] = key
print(l)시간 복잡도 O()
- 병합 정렬(Merge Sort)
- 퀵 정렬(Quick Sort)
병합 정렬(Merge Sort)
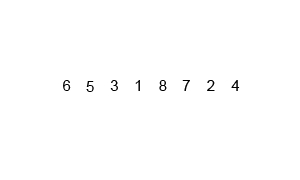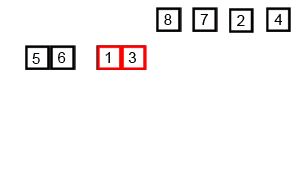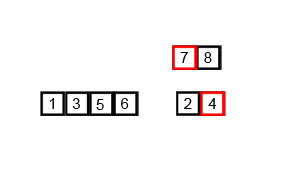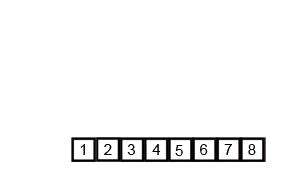
- 분할 정복과 재귀를 이용한 비교 기반 정렬 알고리즘
- O()의 시간 복잡도
- 반으로 쪼개고 다시 합치는 과정에서 그룹을 만들어 정렬
- 이 과정에서 개의 공간이 필요함
- 일반적인 방법으로 구현했을 때 이 정렬은 안정 정렬에 속하며, 분할 정복 알고리즘의 하나임
예시
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if len(left[i][2]) <= len(right[j][2]):
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
l = [
[1, 10, 'leehojun'],
[20, 30, 'hojun'],
[10, 20, 'weniv!'],
[1, 2, 'hello world'],
[55, 11, 'sun']
]
sorted_l = merge_sort(l)
print(sorted_l)퀵 정렬(Quick Sort)
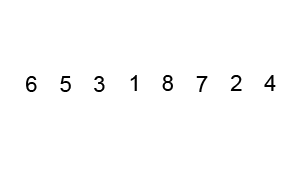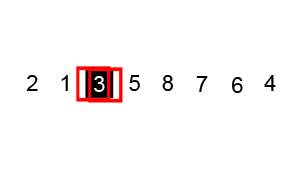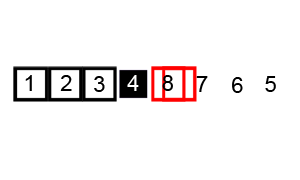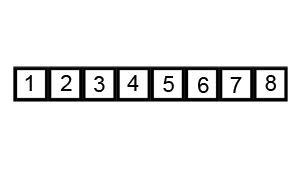
- 분할 정복 알고리즘
- 추가적인 메모리나 공간이 필요 없다는 장점
- 최악의 경우에는 O(n²)번의 비교를 수행하고, 평균적으로 O(n log n)번의 비교를 수행
- Pivot을 설정하고 그 기준으로 정렬(cf. 병합 정렬: 균등 분할)
그 외
- 힙 정렬(Heap Sort)
- 최대 힙 트리나 최소 힙 트리를 구성해 정렬을 하는 방법
- 내림차순 정렬을 위해서는 최소 힙을 구성하고 오름차순 정렬을 위해서는 최대 힙을 구성하면 됨
- 기수 정렬(Radix Sort)
- 기수별로 비교 없이 수행하는 정렬 알고리즘
- 기수로는 정수, 낱말, 천공카드 등 다양한 자료를 사용할 수 있으나 크기가 유한하고 사전순으로 정렬할 수 있어야 함
- 버킷 정렬의 일종으로 취급되기도 함
- 계수 정렬(Count Sort)
- 작은 양의 정수들인 키에 따라 객체를 수집하는 것(즉, 정수 정렬 알고리즘의 하나)
파이썬 코드
import random
class Sort :
def bubble_sort(arr):
for i in range(len(arr)):
for j in range(len(arr) - i - 1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
def selection_sort(arr):
for i in range(len(arr)):
min_index = i
for j in range(i+1, len(arr)):
if arr[min_index] > arr[j]:
min_index = j
arr[i], arr[min_index] = arr[min_index], arr[i]
return arr
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left, right, equal = [], [], []
for i in arr:
if i < pivot:
left.append(i)
elif i > pivot:
right.append(i)
else:
equal.append(i)
return quick_sort(left) + equal + quick_sort(right)
def merge_sort(arr):
if len(arr) < 2:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
merged_arr = []
l = r = 0
while l < len(left) and r < len(right):
if left[l] < right[r]:
merged_arr.append(left[l])
l += 1
else:
merged_arr.append(right[r])
r += 1
merged_arr += left[l:]
merged_arr += right[r:]
return merged_arr
def heap_sort(arr):
def heapify(arr, n, i):
largest = i
l = 2 * i + 1
r = 2 * i + 2
if l < n and arr[i] < arr[l]:
largest = l
if r < n and arr[largest] < arr[r]:
largest = r
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
n = len(arr)
for i in range(n, -1, -1):
heapify(arr, n, i)
for i in range(n-1, 0, -1):
arr[i], arr[0] = arr[0], arr[i]
heapify(arr, i, 0)
return arr
def radix_sort(arr):
RADIX = 10
placement = 1
max_digit = max(arr)
while placement < max_digit:
buckets = [list() for _ in range(RADIX)]
for i in arr:
tmp = int((i / placement) % RADIX)
buckets[tmp].append(i)
a = 0
for b in range(RADIX):
buck = buckets[b]
for i in buck:
arr[a] = i
a += 1
placement *= RADIX
return arr
def counting_sort(arr):
max_value = max(arr)
m = max_value + 1
count = [0] * m
for a in arr:
count[a] += 1
i = 0
for a in range(m):
for c in range(count[a]):
arr[i] = a
i += 1
return arr
arr = [i for i in random.sample(range(10), 10)]
print("Original array: ", arr)
print("Bubble sort: ", Sort.bubble_sort(arr))
print("Selection sort: ", Sort.selection_sort(arr))
print("Quick sort: ", Sort.quick_sort(arr))
print("Merge sort: ", Sort.merge_sort(arr))
print("Heap sort: ", Sort.heap_sort(arr))
print("Radix sort: ", Sort.radix_sort(arr))
print("Counting sort: ", Sort.counting_sort(arr))파이썬의 정렬
sort() 메서드와 sorted() 내장 함수
- sort() 메서드
- 리스트명.sort() 형식으로 사용하는 리스트형의 메서드
- 즉, 입력값으로 리스트만 받음
- 리스트 원본값을 직접 수정
- 정렬을 수행한 리스트를 따로 반환하지 않음
- 리스트명.sort() 형식으로 사용하는 리스트형의 메서드
- sorted() 내장 함수
- sorted(리스트명) 형식으로 이용
- 리스트 원본값 유지
- sort()와는 달리 어떤 입력값이든 받을 수 있음
- 정렬 작업을 수행한 후의 값을 반환
- 상황에 따라 적절히 골라 사용
- 원본을 유지해야 할 때: sorted() 함수
- 리스트 말고 다른 자료형을 정렬할 때: sorted() 함수
- 원본이 필요 없을 때: 시간, 공간 절약을 위해 sort() 함수
- list를 이용할 때: 시간, 공간 절약을 위해 sort() 함수
Tim sort 알고리즘
- sorted() 함수의 내부 알고리즘
- 미리 어느 정도 정렬된 부분이 존재하는 실생활 데이터의 특성을 고려하여 더 빠르게 작동하도록 고안됨
- 최선의 시간복잡도는 O(n), 평균은 O(nlogn), 최악은 O(nlogn)의 시간복잡도
- 안정적인 두 정렬 방법을 결합(Insert sort와 Merge sort)했기에 안정적
- 추가메모리를 사용하긴 하지만 Mergesort에 비해 적은 추가 매모리를 사용하여 다른 O(nlogn) 정렬 알고리즘의 단점을 최대한 극복함
- python을 제외하고도, java, android, google chrome, 그리고 swift까지 많은 프로그래밍 언어에서 표준 정렬 알고리즘으로 채택되어 사용되고 있음

2 B R 0 2 B