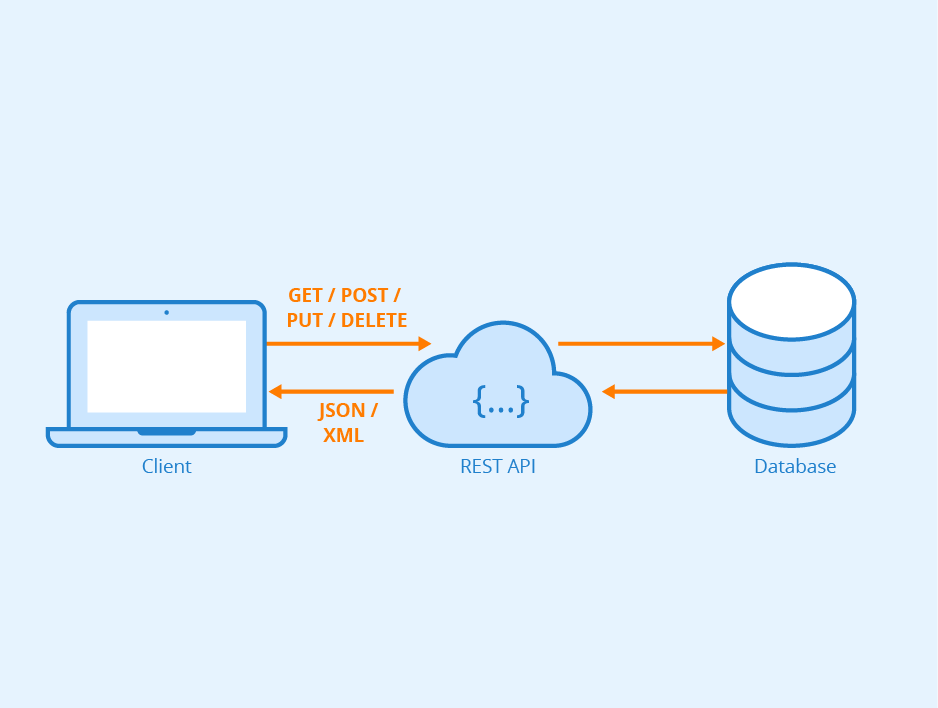
Param vs Query
HTTP 메시지 구조
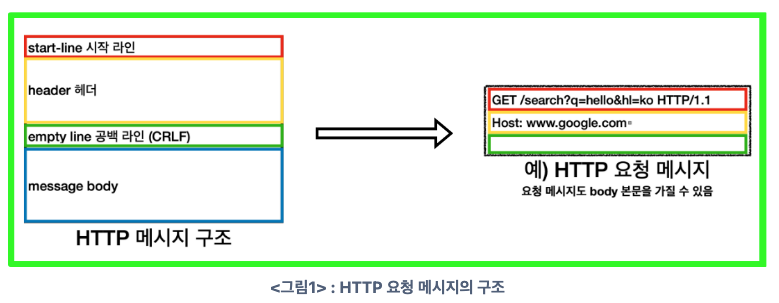
- HTTP 메시지는 ‘시작라인(Strat-Line)’, ‘헤더(Header)’, ‘공백라인(Empty-Line == CRLF)’, ‘메시지 바디(Message Body)’로 구성
- HTTP 요청 메시지의 시작라인(Start-Line)은 Request-Line으로 부를 수 있음
- Request-Line은 'Method, Request-Target, HTTP-Version의 구조를 가짐
- GET(Method : 서버가 수행해야할 동작을 지정)에 해당
- /search?q=hello&hl=ko(Request-Target)가 됨
- HTTP/1.1(HTTP-Version)
- Header에 Header-Filed의 구성
- filed-name”:” 띄워쓰기허용(OWS) filed-value OWS
- Host: www.google.com(도메인)을 가짐
- CRLF(공백 라인)
- HTTP Body는 실제 전송할 데이터. HTML 문서, 이미지, 영상, JSON, 등 Byte로 표현할 수 있는 모든 데이터 전송이 가능
- HTTP 요청 메시지의 시작라인(Start-Line)은 Request-Line으로 부를 수 있음
- HTTP API를 설계할 때 가장 중요한 건 리소스(Resource)
- 리소스란 무엇일까?
- 회원을 등록하고 수정하고 조회하는 게 리소스가 아니라 ‘회원’이라는 개념 자체가 바로 리소스
- 미네랄을 캐라라고 하면 ‘미네랄’이 리소스
- 어떻게 리소스를 식별하는 게 좋을까?
- 회원을 등록하고 수정하고 조회하는 것을 모두 배제 먼저
- 회원이라는 리소스만 식별 하돼 회원 리소스를 URI에 매핑 → URI는 계층구조를 가짐
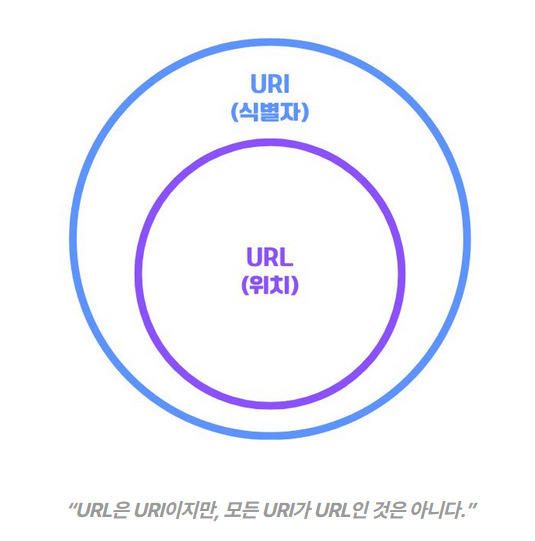
※ URI= 식별자, URL=식별자+위치
elancer.co.kr은 URI입니다. 리소스의 이름만 나타내기 때문입니다.
반면, https://elancer.co.kr은 URL입니다. 이름과 더불어, 어떻게 도달할 수 있는지 위치까지 함께 나타내기 때문이죠. (프로토콜 ‘https’ 포함)
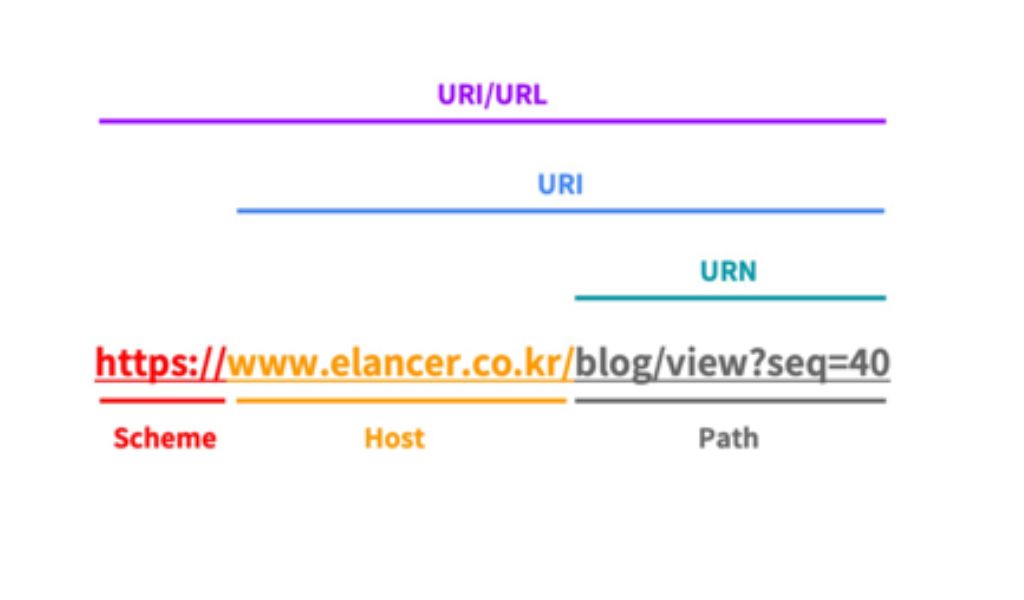
- 리소스란 무엇일까?
| 리소스 | URI | Question |
|---|---|---|
| 회원 목록 조회 | /members | |
| 회원 조회 | /members/{id} | 어떻게 구분할까? |
| 회원 등록 | /members/{id} | 어떻게 구분할까? |
| 회원 수정 | /members/{id} | 어떻게 구분할까? |
| 회원 삭제 | /members/{id} | 어떻게 구분할까? |
→ 여기서 핵심은 리소스와 행위(메서드)를 분리하는 것
리소스는 '회원'
행위는 '조회', '등록', '수정', '삭제'
→ 행위(메서드)를 구분: GET, POST, PUT, DELETE
(PUT,DELETE도 post방식으로 가능해 대부분 GET,POST방식만 사용함)
API GET 메서드
- GET의 역할은 리소스 조회
- 클라이언트가 서버에 전달하고 싶은 데이터를 Query(쿼리 파라미터 or 쿼리 스트링)을 통해 전달
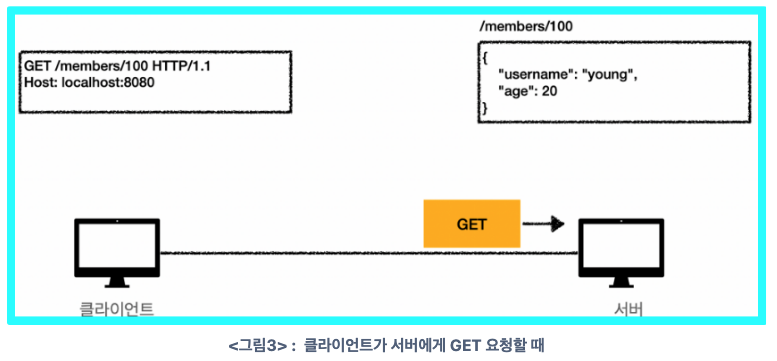
- 서버의 응답 메시지를 받은 클라이언트는 100번째 회원의 정보를 얻게 됨
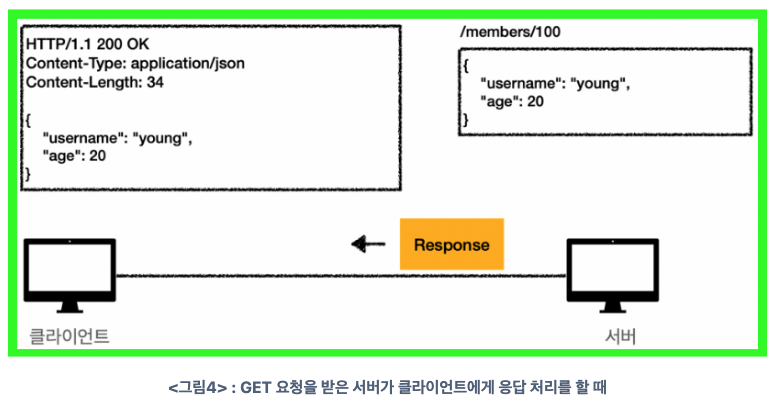
- HTTP Header의 정보는 HTTP-Version(HTTP/1.1)에 Status-Code(200) O
- Type은 애플리케이션/JSON
- 문자 길이는 34
- HTTP Body의 정보는 이름은 young이고 나이는 20살
- 클라이언트가 서버에 전달하고 싶은 데이터를 Query(쿼리 파라미터 or 쿼리 스트링)을 통해 전달
- GET 메서드를 컨트롤하는 두 가지 형태
- Param
- Query
Param
- 주소에 포함된 변수의 값을 처리
http://localhost:3000/blog/8763주소에서 8763 값을 Path Parameter라 함- 서버에서는
/:blogId같은 형태로 라우터 값을 받아와서 처리할 수 있음 - 필터링 or 정렬처럼 옵셔널한 값이 아닌 유일한 값을 식별할 때 사용
Query
- URL 끝에 ? 물음표 뒤에 나타나는 값
http://localhost:3000/blog?type=all&lang=kr- ? 뒤에 key와 value 형태로 &(and) 기호로 key=value 형태로 구분
- 아래와 같은 상황에서 많이 사용:
- 데이터 필터링
- 데이터 정렬
- 검색
- 데이터 페이지네이션
- 필요한 조건을 요청에 처리해야 되는 상황에서 필수값이 아닌 옵셔널한 값일 때 사용
Query
- POINT
- GET 요청은 캐시가 가능
- GET을 통해 서버에 리소스를 요청할 때 웹 캐시가 요청을 가로채 서버로부터 리소스를 다시 다운로드하는 대신 리소스의 복사본을 반환
- HTTP 헤더에서 cache-control 헤더를 통해 캐시 옵션을 지정할 수 있음
- GET 요청은 브라우저 히스토리에 남음
- GET 요청은 길이 제한이 있음
- GET 요청은 멱동(idempotent)
- GET 요청은 중요한 정보를 다루면 안된다. (보안)
- GET 요청은 캐시가 가능
GET은 불필요한 요청을 제한하기 위해 요청이 캐시될 수 있습니다. js, css, 이미지 같은 정적 컨텐츠는 데이터 양이 크고, 변경될 일이 적어서 반복해서 동일한 요청을 보낼 필요가 없습니다. 정적 컨텐츠를 요청하고 나면 브라우저에서는 요청을 캐시해두고, 동일한 요청이 발생할 때 서버로 요청을 보내지 않고 캐시된 데이터를 사용합니다. 그래서 프론트엔드 개발을 하다보면 정적 컨텐츠가 캐시돼 컨텐츠를 변경해도 내용이 바뀌지 않는 경우가 종종 발생합니다. 이 때는 브라우저의 캐시를 지워주면 다시 컨텐츠를 조회하기 위해 서버로 요청을 보내게 됩니다.(이게 바로 f12누르고 새로고침 오른쪽 누르는 거)
멱등이란?
멱등의 사전적 정의는 연산을 여러 번 적용하더라도 결과가 달라지지 않는 성질을 의미한다.
GET은 리소스를 조회한다는 점에서 여러 번 요청하더라도 응답이 똑같을 것 이다. 반대로 POST는 리소스를 새로 생성하거나 업데이트할 때 사용되기 때문에 멱등이 아니라고 볼 수 있다. (POST 요청이 발생하면 서버가 변경될 수 있다.)
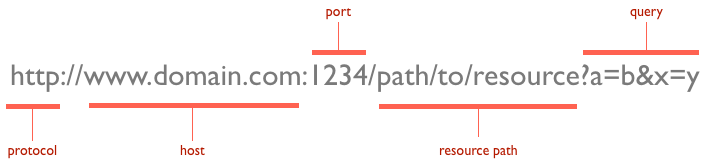
Path parameter VS Query Parameter
Path Parameter
URL로는 고유한 자원(resource, data)을 지칭할 수 있습니다. 그러나 특정 자원을 가리키는 url 경로에 가변적인 부분이 있다면 어떻게 될까요?
-
http://naver.com/stocks/kakao라는 주소는 직관적으로 kakao의 주식 정보를 나타냄을 알 수 있음- 이 상황에서 회사의 이름 부분은 다른 회사에 대한 정보를 요청할 때는 언제든지 바뀔 수 있는 가변적인 자리
-
즉, 가리키는 특정 리소스가 변경될 수 있다 == 변수로 지정해줄 수 있다는 의미
🡆 이 변수의 이름을 Path Parameter라고 함 -
백엔드 서버에서는
http://naver.com/stocks/:companyName같은 형태로 라우팅 할 수 있음 -
변수로 지정하더라도 ‘특정 리소스를 가리키는' URI로서의 역할은 변하지 않음
- 백엔드 서버 입장에서는 매개변수이지만, 클라이언트가 API를 호출할 때에는 해당 매개변수를 실제 값으로 대체하여 호출하기 때문
- 해당 변수는 유일한 값을 식별하는 역할을 함
-
서로 다른 데이터지만 resource(자원)의 종류는 동일할 때, path parameter를 이용하여 RESTful한 API를 구성할 수 있음
-
예시

- 제품 데이터를 목록으로 호출했을 때와, Path parameter를 이용해 한가지의 제품에 대한 데이터만을 호출했을 때의 차이점
- 두 url은 제품 정보를 나타낸다는 점에서 비슷해보일 수 있지만, 엄연히 서로 다른 정보를 요청하는 서로 다른 API임
- 제품의 목록 데이터 : products 라는 리소스에 접근. 제품의 전체 목록을 나타냄.
- 제품의 상세 데이터 : procuts/1 라는 1번 리소스에 접근. 1번 제품에 대한 정보만을 나타냄.
- 두 url은 제품 정보를 나타낸다는 점에서 비슷해보일 수 있지만, 엄연히 서로 다른 정보를 요청하는 서로 다른 API임
- 제품 데이터를 목록으로 호출했을 때와, Path parameter를 이용해 한가지의 제품에 대한 데이터만을 호출했을 때의 차이점
-
[GET] 메서드에서 뿐만 아니라 path parameter는 모든 메서드에서 사용할 수 있음
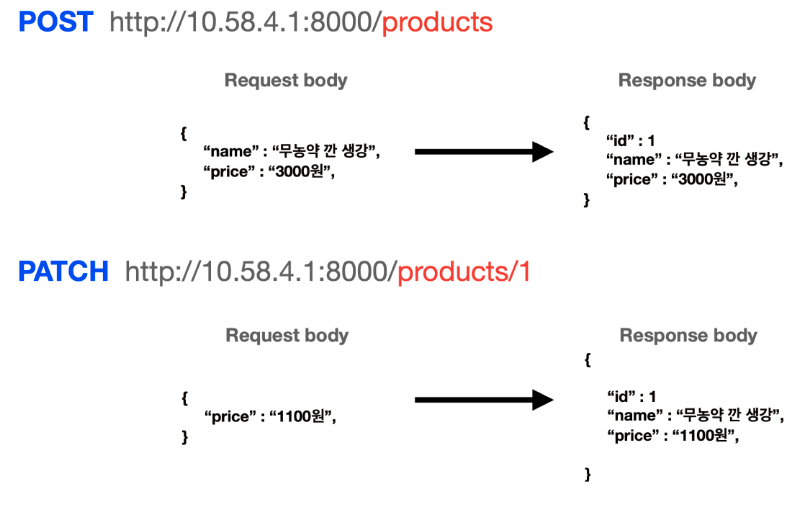
- [POST] 메서드는 데이터를 저장할 때 사용되므로, 특정한 변수가 없어도 됨
- 즉 path parameter가 사용되지 않을 수도 있음
- [PATCH] 메서드는 특정 리소스를 지칭하여 ‘수정할 것'을 표현하므로 path parameter로 어떤 데이터를 수정할 지 알려줄 수 있음
- [DELETE] 메서드 또한 마찬가지로 특정한 리소스를 지칭하여 ‘어떤 제품을 삭제할 지’ 를 명확히 가리킬 수 있음

- [POST] 메서드는 데이터를 저장할 때 사용되므로, 특정한 변수가 없어도 됨
Query Parameter
- url에서 특정한 조건을 주고싶을 때 사용하는 매개변수 유형
- 같은 API를 호출한다고 해도, 서로 다른 조건으로 나열하는 것이 필요한 상황에 사용
- URL 끝에 물음표(?) 뒤에 나타나며, and 기호(&)로 구분된 이름=값 쌍으로 구성되어 있음
- 같은 신발 목록 데이터를 호출 하는데, 신상품 순, 사이즈가 230인 데이터만 따로, 사이즈가 250인 제품 따로, 낮은 가격순으로 데이터를 호출하는 API를 매번 새로 생성하는 것은 비효율적임
- 따라서 필요한 조건을 요청에 따라 선택적으로 처리할 수 있는 통일된 API를 구성할 때 사용
- 쿼리 파라미터는 HTTP의 [GET], [DELETE] 요청에서만 사용
- 유일 값을 식별하기 위한 용도가 아닌 옵션을 줄 때 사용
- 데이터 필터링
- 데이터 정렬
- 데이터 수 조절 (페이지네이션)
- 검색 등
필터링

- url에서 쿼리 파라미터를 이어서 나열할 때, & 연산자를 사용
- 이는 파라미터를 나열하기 위해 사용되는 연산자로, 필터링 조건이 늘 and 조건이라는 뜻은 아님
- API를 어떻게 작성하느냐에 따라 or 조건으로 이용될 수 있음
- url의 & 연산자 와 API의 동작 방식은 독립적
- 이는 파라미터를 나열하기 위해 사용되는 연산자로, 필터링 조건이 늘 and 조건이라는 뜻은 아님
정렬
url에서 쿼리 파라미터를 이어서 나열할 때, & 연산자를 사용합니다. 이는 파라미터를 나열하기 위해 사용되는 연산자로, 필터링 조건이 늘 and 조건이라는 뜻은 아닙니다. API를 어떻게 작성하느냐에 따라 or 조건으로 이용될 수 있습니다. url의 & 연산자 와 API의 동작 방식은 독립적입니다.
Pagination
- 데이터베이스에 저장된 데이터의 수가 엄청나게 많다면, 클라이언트가 한 번에 모든 데이터를 호출하여 사용하면 통신 속도가 매우 저하될 수 있어 비효율적
- 따라서 한 번 클릭에 정해진 수 만큼의 데이터만 호출하는 것이 보다 효율적
- 이러한 상황에서 필요한 데이터의 시작점와 마지막 끝나는 점을 쿼리 스트링을 통해 전달할 수 있음
- 관습적으로 데이터의 시작점을 offset , 주고 받고자 하는 데이터의 갯수를 limit 으로 칭함

- 위와 같은 요청을 보내면, 전체 데이터 가운데 0번부터 100번까지만 호출함
검색
- 마치 독립적인 새로운 기능처럼 보이지만, 사실은 필터링과 동일한 기능
- 특정한 키워드를 기준으로 필터링을 하는 것
- 통상적으로 search 라는 단어를 주로 사용하지만, 검색어를 이용하는 기준이 늘 동일해야하는 것은 아님

- Query parameter을 이용해 생성된 위 4가지 API는 기본적으로 [GET] /products 와 동일한 API를 호출하는 것
- 따라서 API는 한 가지이고, query string을 변수로 받아서 각각의 조건마다 필요한 데이터를 전송해야 함
위 변수들을 request body 에 넣고 요청할 수 있지 않을까? 라고 생각할 수 있습니다.
데이터를 표현하는 HTTP method는 [GET]이고, GET method에서는 request body를 사용하지 않는 것이 권장됩니다.
따라서 GET method를 호출하면서 동시에 정보를 전달할 때에는 query parameter를 이용해야 합니다.
-
쿼리 매개변수라고도 불리는 query parameter를 서버 코드에서 다룰 때에는, 클라이언트에서 값을 주지 않을 때를 대비해 기본값을 설정할 수 있음
-
또한, 동일한 키 값으로 여러 값을 전달할 경우, 서버에서는 배열로 값을 받을 수 있음
- [GET] /products?size=230&size=240&size=280 → { size : [230, 240, 280] }
