[인공지능사관학교: 자연어분석A반] 학습 내용 보충 - 파라미터, 인자, 매개변수
함수
- 프로그램을 만들며 특정한 작업을 수행하는 코드들을 모아놓은 코드들의 집합
- 명령 작업들이 모여 작업을 구성하는 것
매개변수와 파라미터
- 함수의 구성을 먼저 알아야 함
- 어떤 언어에서든 함수는 크게 4가지로 구성됨:
- 함수 이름
- 매개 변수
- 반환값
- 함수 본문
- 어떤 언어에서든 함수는 크게 4가지로 구성됨:
- 함수 이름과 함수 본문은 말 그대로 함수를 호출해야 할 때 부를 이름과 실행될 내용임
- 모든 함수는 본문의 내용을 실행하고 난 뒤 값을 반환: 반환값
- 어떠한 값을 입력받아 3을 더한 뒤 해당 값을 반환하는 함수 plusThree에 4가 입력되었다면 7이 해당 함수의 반환값이 됨
- 간혹 void나 Unit 타입처럼 반환값이 없는 함수도 있긴 함
- 매개변수(parameter)에 대해 이햐하기 위해서는 먼저 인자(argument)에 대해 알아야 함
- 인자: 함수를 호출할 때 전달되어야 하는 값이 있을 경우 해당 함수에 전달되는 값
- 앞서 말한 plusThree에 전달되는 숫자 4가 바로 인자
- 매개변수는 이렇게 전달된 인자가 함수 내부에서 사용될 수 있도록 함수를 선언하는 선언부에 지정하는 변수를 말함
- 인자: 함수를 호출할 때 전달되어야 하는 값이 있을 경우 해당 함수에 전달되는 값
def plusThree(num):
return num+3
one = 1
plusThree(one)- 위 코드에서 함수에 전달되는 1이라는 값을 가진 변수 one은 인자, 그리고 함수 내부에서 사용되는 선언부의 num이 매개변수
- 쉽게 말해 함수를 호출할 때 전달되는 값은 인자, 전달받은 값을 함수 안에서 사용할 때는 매개변수임
- 매개변수(parameter)
- 함수 정의 부분에 나오는 변수
- def plusThree(num):에서 num
- plusThree 함수가 호출될 때 전달받는 값을 받아주는 역할
- 인자(argument)
- 함수를 호출할 때 전달하는 값
- plusThree(one)에서 one
- 실제로 함수에 넘겨주는 값
- one의 값은 1
- 즉, 매개변수: num / 인자: one (값은 1)
스택 메모리(Stack Memory), 힙 메모리(Heap Memory)
- 프로그램을 실행하게 되면 프로그램의 코드들이 메모리에 로드되어 실행됨 == 프로세스
- 프로세스는 Code, Data, Stack, Heap 4가지의 영역으로 나뉘어 메모리 내에 위치
- Code 영역
- 컴파일러가 번역한 기계어로 이루어진 코드가 저장됨
- Data 영역
- 프로그램 전체에서 사용하는 전역 변수나 변하지 않는 정적 변수, 상수 등이 저장됨
- Code 영역
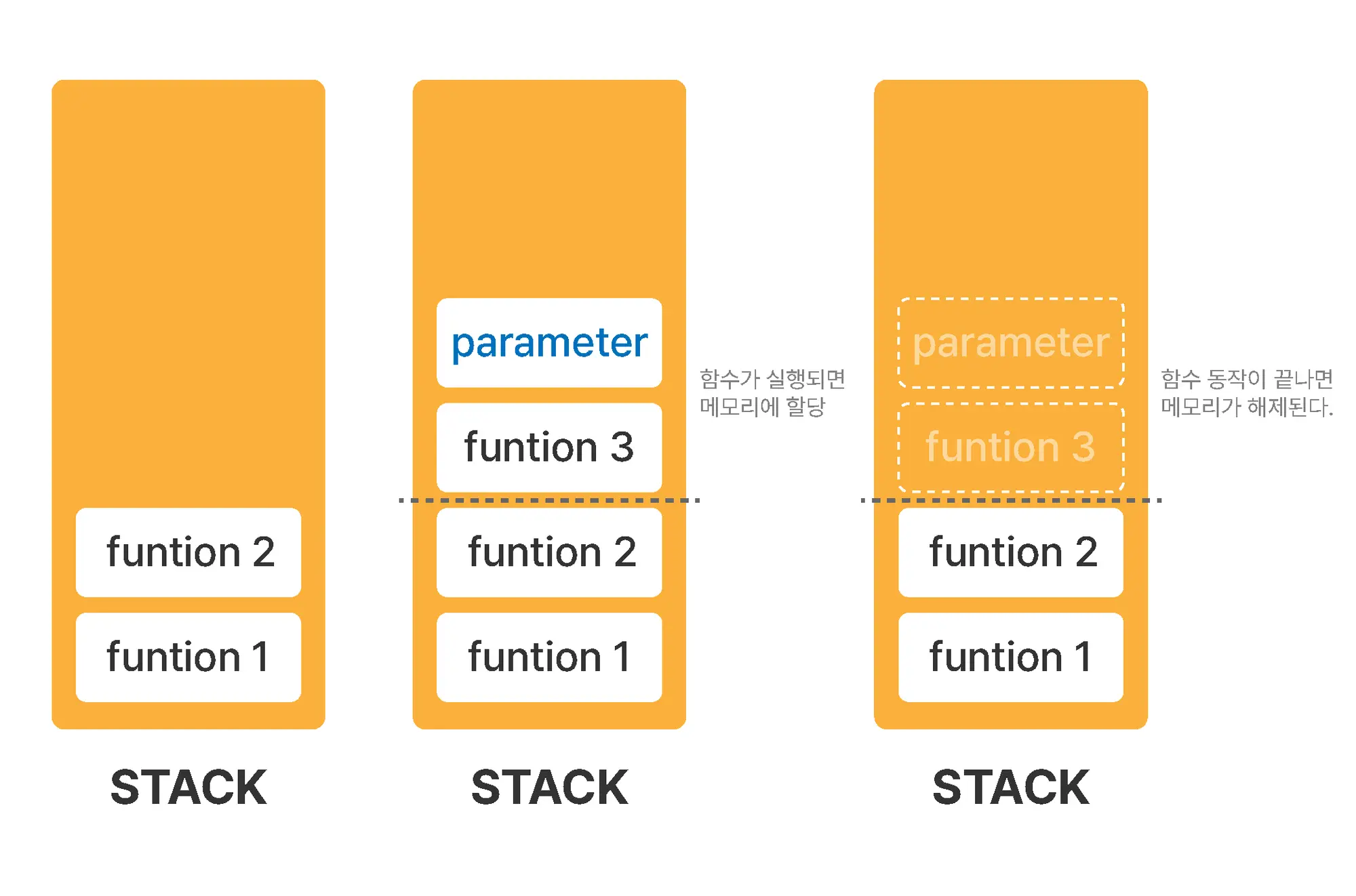
스택(Stack)
 \
\
- 프로그램이 동작하며 함수가 호출되거나, 해당 함수와 관련 있는 지역변수, 매개변수 등이 저장되는 영역
- 즉, 함수를 호출하면 해당 함수와 관련된 것들이 스택 메모리에 차곡차곡 로드되고 함수의 동작이 끝나면 해당 함수가 사용하던 메모리가 해제됨
- 이름에서 알 수 있듯 쌓아가는 식으로 메모리를 관리
- 메모리 크기에 제한이 있어 해당 크기를 넘어갈 경우(예: 재귀함수가 무한하게 호출되는 경우처럼 해제 없이 로드만 되는 경우) 스택 오버플로우가 발생할 수 있음
스택에서 쓰이는 용어
- Top: 삽입과 삭제가 일어나는 위치
- Push: 새로운 데이터를 Stack에 쌓는 연산
- Peek: Top 이 가리키는 데이터를 단순 확인하는 연산
- Pop: Top 이 가리키는 데이터를 삭제하고 확인하는 연산
스택의 특징
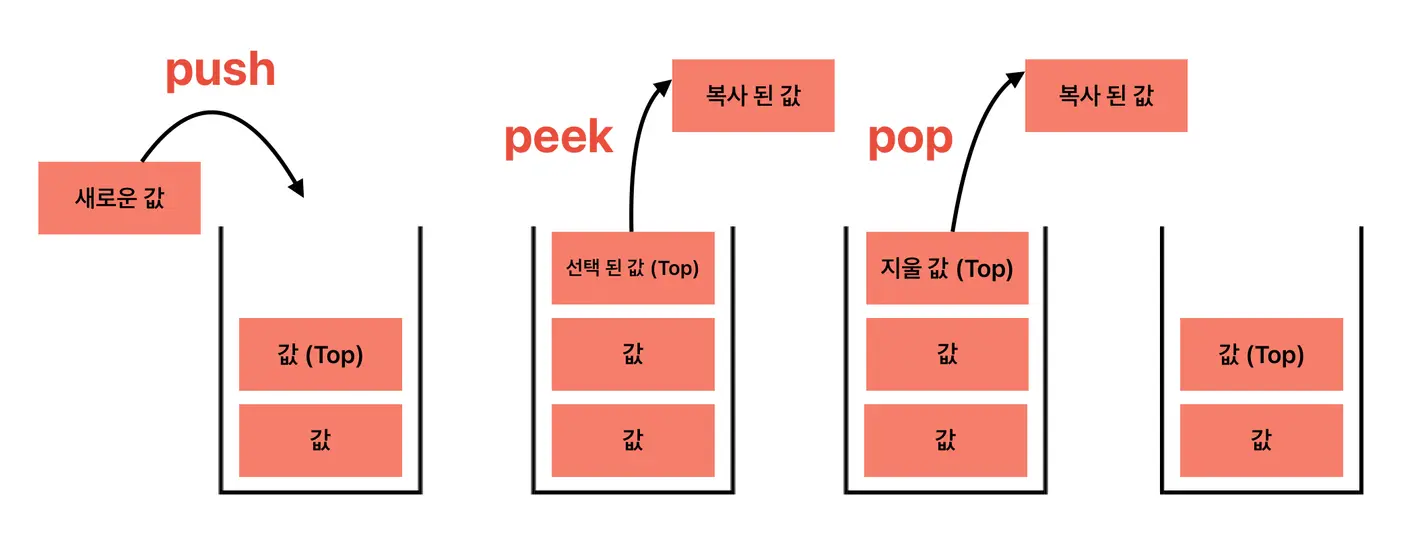
- 후입선출(LIFO, Last In First Out) 구조
- 가장 마지막에 삽입된 데이터가 가장 먼저 삭제됨
- 스택에 새로운 데이터를 삽입하면, 해당 데이터는 스택의 가장 위에 위치
- 스택에서 데이터를 삭제할 때는 가장 위에 있는 데이터부터 삭제됨
- 삽입과 삭제가 한쪽에서만 이루어짐
- 스택의 한쪽 끝에서만 데이터의 삽입과 삭제가 이루어짐
- 이 한쪽 끝을 스택의 top이라고 함
- 새로운 데이터를 삽입할 때는 top을 통해 삽입되고, 데이터를 삭제할 때도 top에서 삭제됨
- 스택의 한쪽 끝에서만 데이터의 삽입과 삭제가 이루어짐
- top 포인터의 이동
- 스택에 새로운 데이터가 삽입되면 top 포인터는 새로 삽입된 데이터를 가리키도록 이동함
- 스택에서 데이터가 삭제되면 top 포인터는 그 아래에 있는 데이터를 가리키도록 이동함
- 데이터의 접근 제한
- 스택에서는 top 포인터가 가리키는 데이터에만 접근 가능
- 스택 내부의 다른 데이터에 접근하고 싶다면 top부터 시작해 차례대로 데이터를 삭제해야 함
- 재귀 알고리즘과의 유사성
- 스택의 동작 원리는 재귀 함수 동작 원리와 유사
- 재귀 함수에서는 함수가 자기 자신을 호출하면서 호출 정보를 스택에 저장하고, 함수가 종료되면 스택에서 이전 호출 정보를 꺼내 실행을 이어감
- 스택의 동작 원리는 재귀 함수 동작 원리와 유사
- 깊이 우선 탐색(DFS)과의 관련성
- 스택은 깊이 우선 탐색(DFS) 알고리즘에서 유용하게 사용됨
- DFS에서는 한 방향으로 깊이 탐색을 진행하다가 더 이상 팀색할 수 없을 때 이전 상태로 돌아가는데, 이때 스택을 활용해 탐색 경로를 저장하고 관리함
- 스택은 깊이 우선 탐색(DFS) 알고리즘에서 유용하게 사용됨
cf. 큐(Queue)
- 이터를 저장할 때는 큐의 뒤쪽(rear)에 새로운 데이터를 추가하고, 데이터를 꺼낼 때는 큐의 앞쪽(front)에서 데이터를 꺼내는 방식
- 큐에서 쓰이는 용어
- Rear: 큐의 가장 끝 데이터 영역
- Front: 큐의 가장 앞 데이터 영역
- Add: Rear 부분에 새로운 데이터를 삽입하는 연산
- Peek: Front 부분에 있는 데이터를 확인하는 연산
- Poll: Front 부분에 있는 데이터를 삭제하고 확인하는 연산
- 큐의 특징
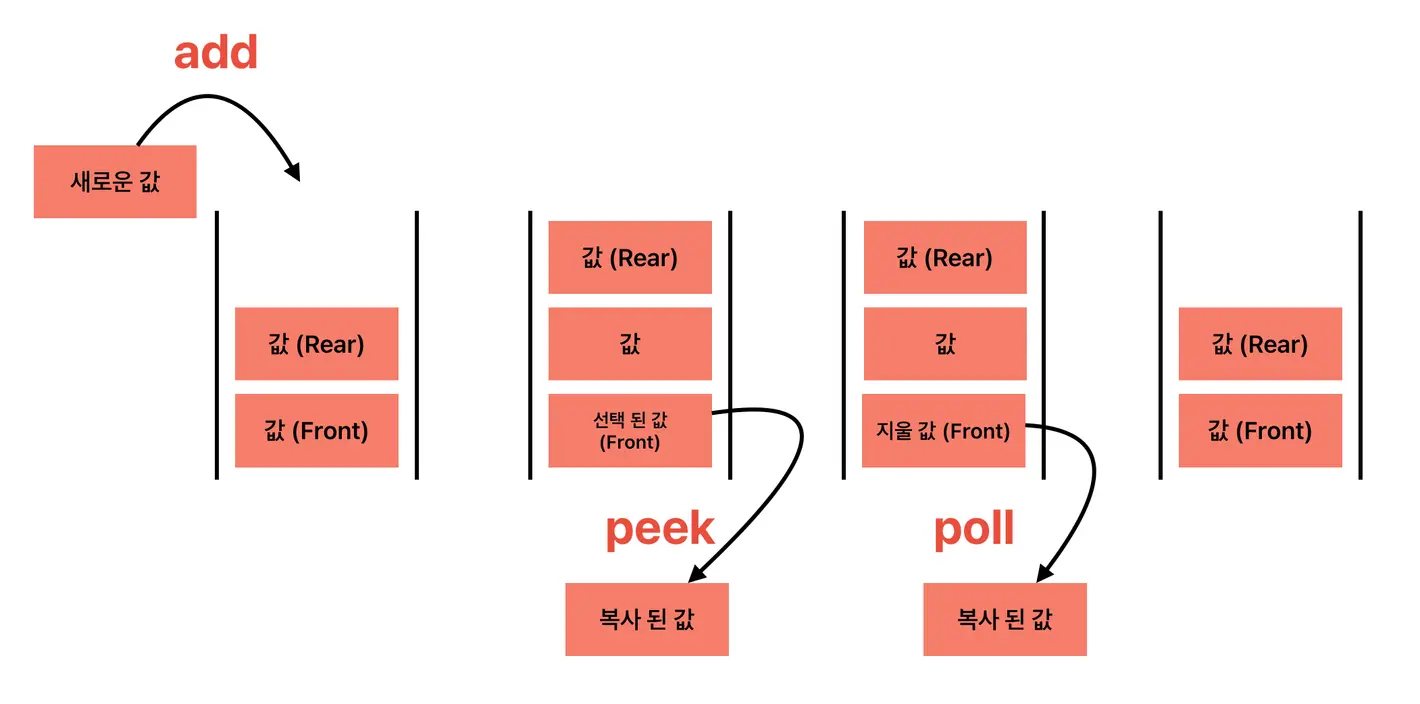
- 선입선출(FIFO - First In First Out) 구조
- 가장 먼저 삽입된 데이터가 가장 먼저 삭제됨
- Queue에 새로운 데이터를 삽입하면, 해당 데이터는 Queue의 맨 뒤(Rear)에 위치함
- Queue에서 데이터를 삭제할 때는 맨 앞(Front)에 있는 데이터부터 삭제됨
- 삽입과 삭제가 양방향에서 이루어짐
- Queue의 한 쪽 끝(Rear)에서는 데이터의 삽입이 이루어지고, 다른 쪽 끝(Front)에서는 데이터의 삭제가 이루어짐
- 새로운 데이터는 항상 Rear에 추가되며, 삭제는 Front에서부터 진행
- Front와 Rear 포인터의 이동
- Queue에 새로운 데이터가 삽입되면, Rear 포인터는 새로 삽입된 데이터를 가리키도록 이동
- Queue에서 데이터가 삭제되면, Front 포인터는 그 다음 데이터를 가리키도록 이동
- 데이터의 접근 제한
- Queue에서는 Front 포인터가 가리키는 데이터와 Rear 포인터가 가리키는 데이터에만 직접적으로 접근할 수 있음
- Queue 내부의 다른 데이터에 접근하기 위해서는 Front부터 시작하여 차례대로 데이터를 삭제해야 함
- 너비 우선 탐색(BFS)과의 관련성
- Queue는 너비 우선 탐색(BFS) 알고리즘에서 유용하게 사용
- BFS에서는 시작 노드부터 인접한 노드를 먼저 탐색하고, 이후 다음 레벨의 노드들을 순차적으로 탐색하는데, 이때 Queue를 활용하여 탐색 순서를 관리
- 선입선출(FIFO - First In First Out) 구조
힙(Heap)
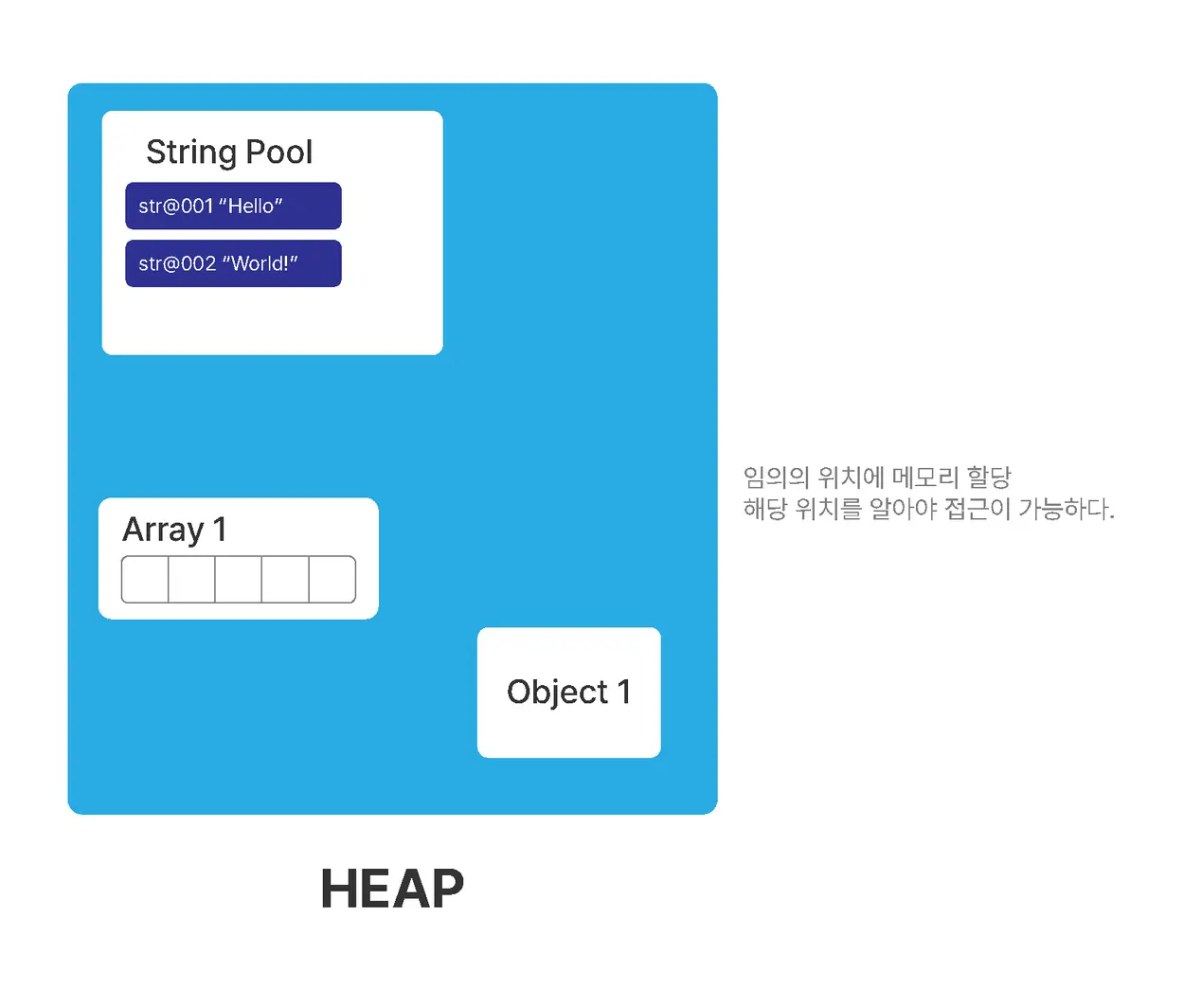
- 동적인 데이터, 즉 크기가 변할 수 있는 정보들을 저장하는 공간
- 스택의 경우 메모리의 크기가 제한되어 있어 배영이라 리스트 같은 타입처럼 데이터에 계속해서 값이 추가될 경우 메모리의 크기를 초과할 수 있음
- 따라서 동적 데이터는 힙 영역에 저장
- 스택에서는 차지하는 메모리 자체에 값이 저장되기 때문에 해당 변수가 어떤 값을 가지고 있는지 바로 알 수 있음
- 하지만 힙의 경우 순서가 없어 힙 영역 내의 데이터를 확인하려면 해당 값이 어디에 있는지 확인해야 함 == 힙 영역 내의 주소(위치)를 알아야 함
- 스택에서는 가장 마지막에 호출된 함수가 실행되고 나면 알아서 메모리에서 해제되었지만 힙에서는 순서가 따로 없기 때문에 사용되지 않는 값의 경우 개발자가 직접 메모리에서 해당 값을 해제해야 함

2 B R 0 2 B