CodeKata
SQL
174. Challenges
- 작성한 쿼리
WITH cte AS (
SELECT
h.hacker_id
, name
, COUNT(challenge_id) AS challenges_created
FROM
hackers h
JOIN challenges c
USING(hacker_id)
GROUP BY
h.hacker_id
, name
)
SELECT
*
FROM
cte
WHERE
challenges_created = (
SELECT
MAX(challenges_created)
FROM
cte
)
OR challenges_created IN (
SELECT
challenges_created
FROM
cte
GROUP BY
challenges_created
HAVING
COUNT(*) = 1
)
ORDER BY
challenges_created DESC
, hacker_id
;참고할 만한 다른 풀이
- window function
select
hacker_id
, name
, total_number
from
(
select
h.hacker_id
, h.name
, count(*) total_number
, rank() over(order by count(h.hacker_id) desc) rnk
from
hackers h
, challenges c
where
h.hacker_id = c.hacker_id
group by
h.hacker_id, h.name
) handc
where
rnk = 1
union all
select
hacker_id
, name
, total_number
from
(
select
h.hacker_id
, h.name
, count(*) total_number
, dense_rank() over(order by count(*) desc) rnk
, count(count(*)) over(partition by count(*)) cnt
from
hackers h
, challenges c
where
h.hacker_id = c.hacker_id
group by
h.hacker_id, h.name
) hc
where
cnt = 1
and rnk > 1
order by
3 desc
, 1
;- challenge 수가 최대인 부분(수가 겹쳐도 출력)
- name을 얻기 위한 hackers
- hackers와 challenges를 조인하여 group by 한 테이블
- 최대 수를 가진 one컬럼 one데이터 테이블
- challenge 수가 최대가 아닌 부분(수가 겹치는 것은 제거)
- name을 얻기 위한 hackers
- challenge 수를 랭크하고 중복되는 갯수를 계산한 테이블
- 윈도우 함수의 동작방식을 이해하면 위와 같은 쿼리를 작성할 수 있다.
- 윈도우 함수도 기본적으로 group by의 컬럼구분을 따라가기 때문에 다시 그 안에서 count(count(*))를 하는 방식으로 중복수를 구한다.
- ★★★
-- 1
SELECT
hacker_id
, name
, totalcount
FROM
(
SELECT
Hackers.hacker_id,
name,
COUNT(challenge_id) AS totalcount,
COUNT(COUNT(challenge_id)) OVER (PARTITION BY COUNT(challenge_id)) as dupes,
MAX(COUNT(challenge_id)) OVER () as max
FROM
Hackers
LEFT JOIN Challenges USING(hacker_id)
GROUP BY
Hackers.hacker_id, name
) B
WHERE
NOT (dupes >1 && totalcount < max)
ORDER BY
totalcount desc
, hacker_id
-- 2
WITH cte AS (
SELECT
h.hacker_id
, name
, COUNT(challenge_id) AS cnt
, COUNT(COUNT(challenge_id)) OVER (
PARTITION BY COUNT(challenge_id)
) AS dup
, MAX(COUNT(challenge_id)) OVER () AS max
FROM
hackers h
JOIN challenges c
USING(hacker_id)
GROUP BY
h.hacker_id
, name
)
SELECT
hacker_id
, name
, cnt
FROM
cte
WHERE
NOT (dup > 1 && cnt < max)
ORDER BY
cnt DESC
, hacker_id
;with base as (
SELECT a.hacker_id
, COUNT(DISTINCT a.challenge_id) as c_cnt
FROM Challenges a
GROUP BY a.hacker_id
)
SELECT t1.hacker_id
, t2.name
, t1.c_cnt
FROM base t1
JOIN Hackers t2 on t2.hacker_id = t1.hacker_id
WHERE 1 = 1
and (
t1.c_cnt = (SELECT MAX(d1.c_cnt) FROM base d1 )
or
t1.c_cnt NOT IN (
SELECT d2.c_cnt
FROM base d2
GROUP BY d2.c_cnt HAVING COUNT(DISTINCT d2.hacker_id) >= 2
)
)
ORDER BY t1.c_cnt DESC, t1.hacker_id ASC- Step1. Hacker ID별로 만든 문제 수를 계산한다.
- Subquery에서 이를 수행했고, COUNT DISTINCT 로직을 통해서 계산했다.
- 이렇게 되면 우리가 다루어야 할 숫자는 모두 만든 상태이다.
- Step2. MAX를 통해서 최대값을 가져온다.
- SELF JOIN을 하는 방법이 여러개가 있지만, 여기서는 정수하나만 가져오면 되기 때문에 WHERE 절에서 바로 다루었다.
- Step3. IN을 통해 원하는 숫자를 가져온다.
- SELF JOIN하는 방법은 위와 동일하다.
- 그 중에서 GROUP BY ~ HAVING ~을 통해서 중복되는 숫자를 모두 제거한다.
- 또한 위의 Step과 병렬로 조건이 처리되어야 하기 때문에 OR로 묶어두었다.
Python
67. 둘만의 암호
- 작성한 코드
def solution(s, skip, index):
answer = ''
skip_num = [ord(i)-97 for i in skip]
for i in s:
num = ord(i)-97
for _ in range(index):
num = (num+1)%26
while num in skip_num:
num = (num+1)%26
answer += chr(num+97)
return answer→ a-z ASCII: 97-122
→ 알파벳은 26글자
참고할 만한 다른 풀이
def solution(s, skip, index):
answer = ''
abc = [chr(i) for i in range(97, 123) if not chr(i) in skip] * 3
for i in s:
answer += abc[abc.index(i)+index]
return answer- 영어 a, b, c 순으로 알파벳을 생성하되 skip에 포함된 글자는 제외
- 아스키 코드 97번이 a라는 것을 이용해 배열 생성
- s에 들어오는 값을 for문을 통해 순회하면서 생성된 abc 배열에서 찾아서 새로운 알파벳으로 변환
def solution(s, skip, index):
alpha = "abcdefghijklmnopqrstuvwxyz"
answer = ""
for i in list(skip):
alpha = alpha.replace(i,"")
for a in s:
answer += alpha[(alpha.find(a) + index) % len(alpha)]
return answer- a~z 문자열을 만들어 skip의 문자 빼기
- 그 후, index + 만큼 진행하고, 문자열의 최대 길이가 넘어갈 경우 a로 돌아가도록 모듈러 연산(%)을 적용
from string import ascii_lowercase
def solution(s, skip, index):
result = ''
a_to_z = set(ascii_lowercase)
a_to_z -= set(skip)
a_to_z = sorted(a_to_z)
l = len(a_to_z)
dic_alpha = {alpha:idx for idx, alpha in enumerate(a_to_z)}
for i in s:
result += a_to_z[(dic_alpha[i] + index) % l]
return resultdef solution(s, skip, index):
alphas = [chr(a) for a in range(ord("a"), ord("z")+1) if chr(a) not in skip]
return "".join([alphas[(alphas.index(a) + index) % len(alphas)] for a in s])def solution(s, skip, index):
atoz = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
for i in skip:
atoz.remove(i)
ans = ''
for i in s:
ans += atoz[(atoz.index(i)+index)%len(atoz)]
return ans태블로 개인 과제용 공부
분산형 차트, 버블 차트 만들기
분산형 차트(Scatter plot)
- 두 변수 간의 관계를 2차원 공간 상에서 시각적으로 나타내는 데 사용하는 차드
- 데이터의 분포를 확인하여 두 변수 간의 관계, 군집, 이상치 등의 데이터 패턴을 쉽게 파학할 수 있음
버블 차트(Bubble chart)
- 분산형 차트에 세 번째 변수를 더해 시각적으로 나타낸 차드
- 가로축과 세로축을 기반으로 2차원 공간 상에 데이터를 표시하고, 세 번째 변수는 버블의 크기로 표현
- 데이터의 다양한 특면을 비교할 수 있으며, 데이터의 상대적 중요성을 표현할 때 유용
분산형 차트와 버블 차트 만들기
※ 분산형 차트를 그리기 위해서는 2개 이상의 연속형 변수가 필요
1. 마크는 원으로 설정하고 열, 행에 원하는 연속형 변수 보내기
- 가로축을 GDP per Capita로, 세로축을 Happiness Score로 하여 GDP per Capita와 Happiness Score의 관계를 확인하기 위해 GDP per Capita를 열로, Happiness Score를 행으로 보냄
- 이때 마크는 드롭다운 메뉴를 클릭해 원으로 바꿔줌 → 점 차트가 그려지도록 하기 위함
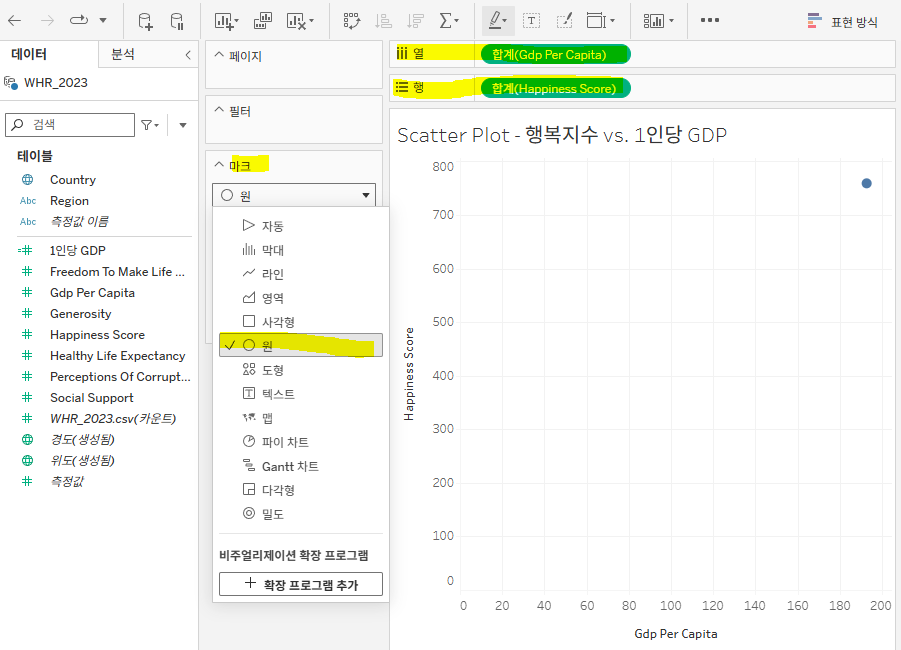
-
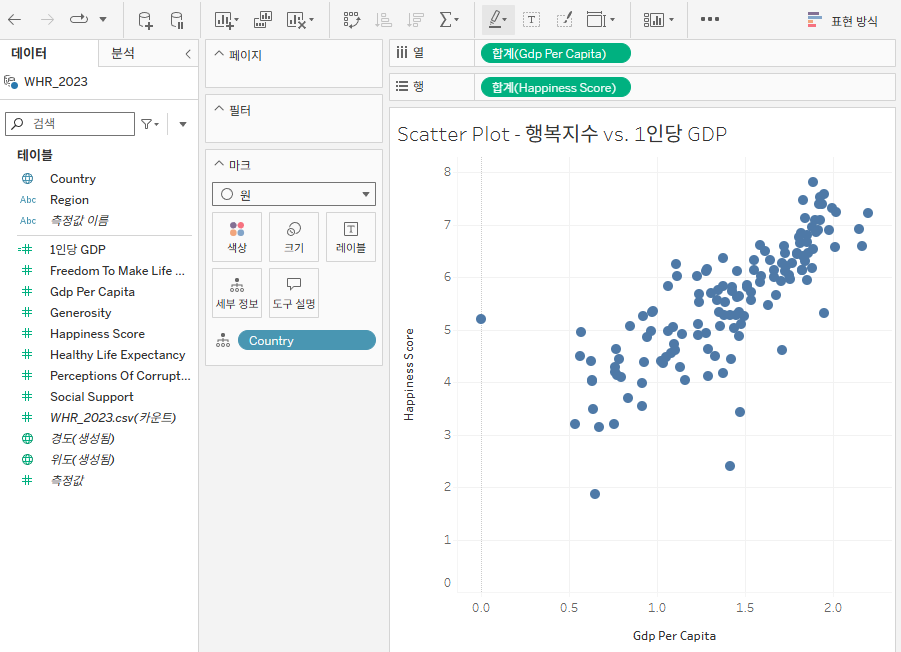
Country를 세부정보로 보내기
- Country를 세부정보로 보내게 되면 모든 Country의 GDP per Capita와 Happiness Score에 맞춰 Scatter Plot이 그려짐
- 여기에 Region(지역)별 색상을 추가해야 함
- 색상은 기존의 GDP per Capita나 Happiness Score가 아닌 Region이라는 새로운 정보를 포함하기 때문에 일종의 버블 차트로 볼 수 있음
- Country를 세부정보로 보내게 되면 모든 Country의 GDP per Capita와 Happiness Score에 맞춰 Scatter Plot이 그려짐
-
Region을 색상으로 보내고 원의 불투명도와 테두리 설정
- 마크의 색상을 클릭하면 불투명도를 조절할 수 있음 → 불투명도를 낮추면 투명도가 올라감
- 테두리를 클릭해 테두리 설정 지정 가능 → 불투명도가 낮은 경우 테두리를 적절하게 활용하면 좋음
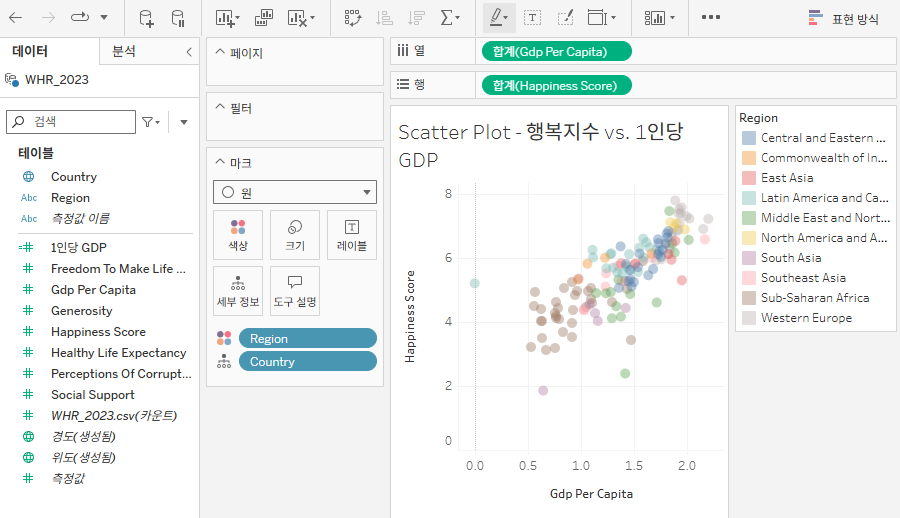
-
Trend Line(추세선)
- 분석 탭에서 '추세선'을 드래그
평균 라인 만들기
평균 라인
- 전체 추세에 따라 변화하는 화면에서 평균값을 기준으로 표현하는 라인
- 라인 차트 변경, 레이블 표시 변경, 값이 평균보다 높은지 낮은지에 따라 개별적으로 색깔로 구분 가능
- 분석 탭에서 '평균 라인'을 드래그하면 '테이블', '패널', '셀'의 참조선 추가 범위가 나타남
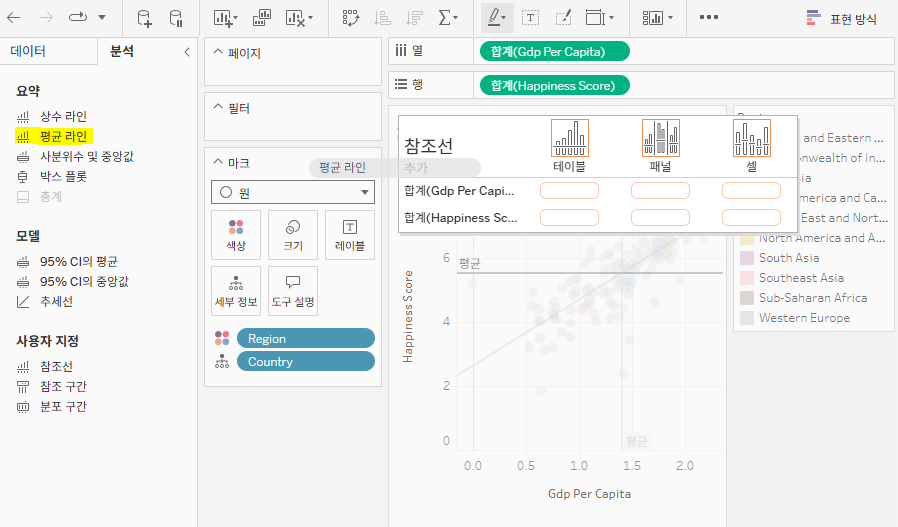
- 테이블: 전체 영역을 기준으로 평균 계산
- 패널: 패널별로 평균 계산(예: 년도별, 분기별, 월별, …)
- 셀: 열에 들어가 있는 최소 단위 기준으로 평균 계산
(예: 주문 날짜(년), 주문 날짜(월) → 연월 기준으로 평균 계산)
- 평균 라인에 대한 레이블을 변경하기 위해서는 평균 라인 우클릭>편집 상자 눌러서 라인의 레이블 부분을 수정
- '▼' 버튼을 누르면 <필드명>, <필드 레이블>, <계산>, <값> 이외에도 원하는 값을 넣어 레이블 수정 가능
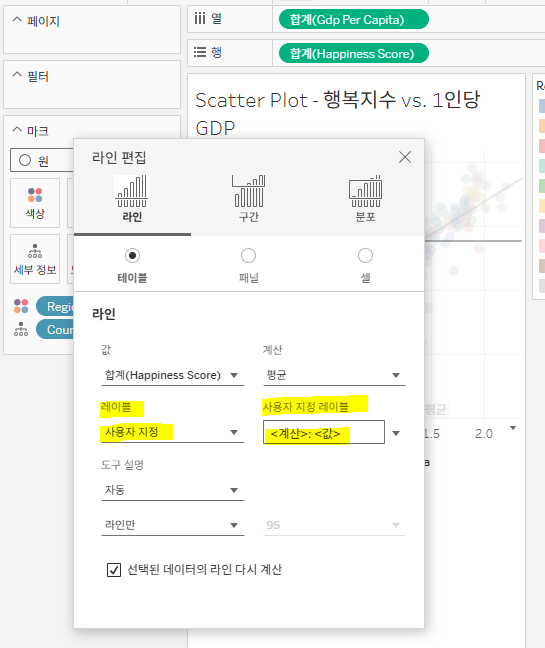
- '▼' 버튼을 누르면 <필드명>, <필드 레이블>, <계산>, <값> 이외에도 원하는 값을 넣어 레이블 수정 가능
회고
- 내일 태블로 개인 과제 마무리하고 캠프에서 배운 내용 복습!

2 B R 0 2 B