선정 아티클
확실히 알아두면 만사가 편해지는 머신러닝 10가지 알고리즘
→ 원문
요약
[아티클 요약 및 주요 내용]
요약 : 아티클의 핵심 내용을 요약해보세요.
- 현업에서 정형 데이터를 가지고 머신러닝으로 원활히 데이터를 분석하려면 10가지 알고리즘만으로도 충분히 좋은 성과를 낼 수 있다.
- 10가지 알고리즘 목록
- 선형 회귀(Linear Regression)
- 로지스틱 회귀(Logistic Regression)
- K-최근접 이웃(KNN)
- 나이브 베이즈(Naive Bayes)
- 결정 트리(Decision Tree)
- 랜덤 포레스트(Random Forest)
- XG부스트(XGBoost)
- 라이트GBM(LightGBM)
- K-평균 군집화(K-Means Clustering)
- 주성분 분석(PCA)
주요 포인트 : 아티클에서 강조하는 주요 포인트는 무엇인가요?
- 실무에서 원할히 머신러닝으로 데이터를 분석하기 위해 필요한 것
- 기본 개념 이해
- 선형
- 군집
- 트리 등
- 알고리즘 이해
- 지도 학습 알고리즘
- 비지도 학습 알고리즘
- 최신 알고리즘 알고 가기: XGBoost, LightGBM
- 지속적으로 발표되는 논문 등을 이용해 추가 공부
- 기본 개념 이해
[핵심 개념 및 용어 정리]
- 핵심 개념: 아티클에서 언급된 중요한 개념을 정리하세요.
- 용어 정리: 생소하거나 중요한 용어의 정의를 적어보세요.
-
핵심 개념:
-
선형 회귀(Linear Regression)
- 종속변수와 독립변수가 선형 관계에 있는 데이터에 적합
- 예측할 종속변수만 연속형 변수이면 됨
- 기본 분석 모델(기초 알고리즘)
-
로지스틱 회귀(Logistic Regression)
- 두 가지로 나뉘는 분류 문제를 다룸: 이진분류
- 종속변수와 독립변수가 선형 관계에 있는 데이터에 적합
- 기본 분석 모델(기초 알고리즘)
-
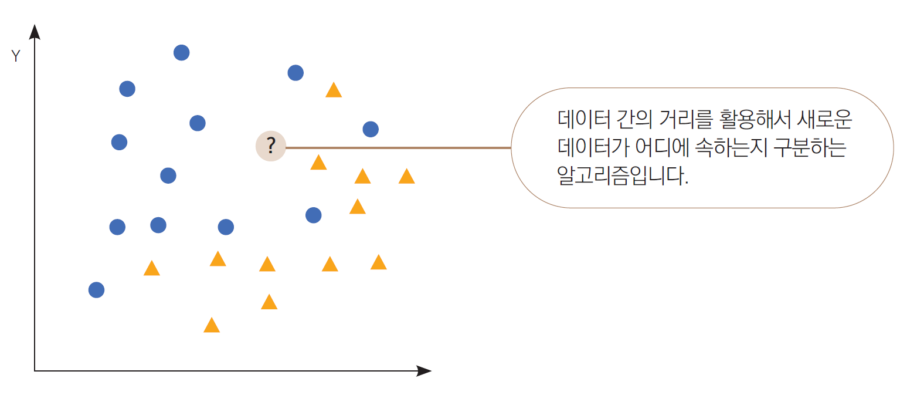
K-최근접 이웃(KNN)
- 각 데이터 간의 거리를 활용해 새로운 데이터를 예측
- K개의 가장 가까운 이웃 데이터에 의해 예측됨
- 아웃라이어가 적은 데이터에 적합
- 다중분류 문제에 가장 간편히 적용 가능
-
나이브 베이즈(Naive Bayes)
- 베이즈 정리를 적용한 조건부 확률 기반 분류 모델
- 스팸 필터링을 위한 대표적인 모델
- 독립변수의 종류가 매우 많은 경우 적합
-
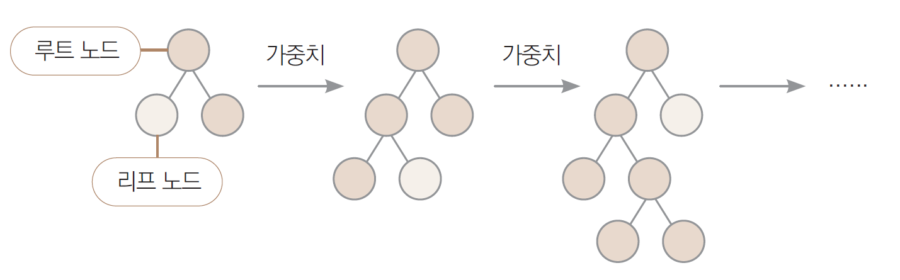
결정 트리(Decision Tree)
- 관측값과 목푯값을 연결시켜주는 예측 모델
- 각 변수의 특정 지접을 기준으로 데이터를 분류해가며 예측 모델을 만듦
- 일반적인 데이터에 적합
- 아웃라이어 영향 거의 없음
- 시각화가 매우 뛰어남
- 예측력, 성능만 따지면 쓸 일 없지만 다른 트리 기반 모델을 설명하려면 필수로 알아야 함!
- Non-parametric Model
-
랜덤 포레스트(Random Forest)
- 결정 트리의 단점인 오버피팅 문제를 완화시켜주는 발전된 형태의 트리 모델
-
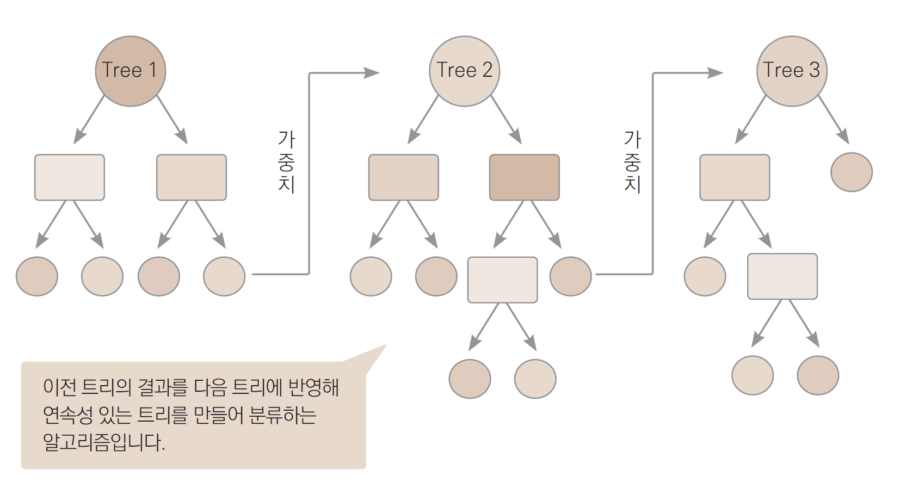
XG부스트(XGBoost)
- 트리 모델을 기반으로 한 최신 알고리즘 중 하나
- 손실함수뿐만 아니라 모형 복잡도까지 고려
- 가장 인기 있는 모델이라 참고 자료(활용 예시, 다양한 하이퍼파라미터 튜닝 등)가 많음
-
라이트GBM(LightGBM)
- XGBoost 이후로 나온 최신 부스팅 모델
- 리프 중심 트리 분할 방식을 사용
-
K-평균 군집화(K-Means Clustering)
- 비지도 학습의 대표적인 알고리즘
- 목표 변수가 없는 상태에서 데이터를 비슷한 유형끼리 묶음
- 거리 기반으로 작동
- 적절한 K값(=전체 그룹의 수)을 사용자가 지정해야 함
-
주성분 분석(PCA)
- 비지도 학습에 속하기 때문에 종속 변수는 존재하지 않고, 어떤 것을 예측하지도 분류하지도 않ㅇ므
- 목적: 데이터 차원 축소(변수 개수를 줄이되, 가능한 그 특성을 보존해내는 기법)
-
선형 회귀 (Linear Regression)
종속변수와 독립변수 간의 선형 관계를 모델링하는 알고리즘. 예측 값은 직선 형태로 나타냄.
로지스틱 회귀 (Logistic Regression)
이진 분류 문제에서 각 클래스의 확률을 예측. 시그모이드 함수를 사용하여 예측 값을 0과 1 사이의 확률로 변환.
K-최근접 이웃 (KNN)
새로운 데이터 포인트를 K개의 가장 가까운 이웃과 비교하여 분류하거나 예측.
나이브 베이즈 (Naive Bayes)
확률적 분류 모델. 각 특성이 독립적이라는 가정 하에 조건부 확률을 계산.
결정 트리 (Decision Tree)
데이터를 여러 조건으로 분할하여 예측을 수행하는 트리 구조.
랜덤 포레스트 (Random Forest)
여러 개의 결정 트리를 결합하여 예측 성능을 개선하는 앙상블 모델
서포트 벡터 머신 (SVM)
데이터를 가장 잘 분리하는 초평면을 찾는 분류 모델. 커널 기법을 통해 비선형 분리도 가능.
XGBoost
부스팅 기법을 활용한 모델로, 여러 약한 모델을 결합하여 강한 예측 모델을 생성.
LightGBM
XGBoost의 개선된 버전으로, 빠르고 메모리 효율적인 학습을 지원
K-means
데이터를 K개의 클러스터로 분할하는 비지도 학습 알고리즘.
- 용어 정리 :
- 베이즈 정리
- 새롭게 얻은 정보를 토대로 어떤 사건이 발생했다는 확률을 업데이트하는 방법
- 사후 확률(posterior probability)을 구하기 위해 사전 확률(prior probability)를 이용하여 새롭게 표현
- 베이즈 정리
선형 회귀 (Linear Regression)
- 회귀선: 데이터를 가장 잘 표현하는 직선
- 최소제곱법: 예측 값과 실제 값 간의 차이의 제곱을 최소화하는 방법
로지스틱 회귀 (Logistic Regression)
- 시그모이드 함수: 확률 값으로 변환하는 함수
- 로지스틱 함수: 출력값을 0과 1 사이로 제한하는 함수
K-최근접 이웃 (KNN)
- 유클리드 거리: 두 점 간의 거리 측정 방법
- K 값: 이웃의 수
나이브 베이즈 (Naive Bayes)
- 베이즈 정리: 사후 확률을 계산하는 공식
- 조건부 확률: 주어진 조건 하에서의 확률
결정 트리 (Decision Tree)
- 루트 노드: 트리의 최상위 노드
- 리프 노드: 예측 결과가 나오는 최하위 노드
- 정보 이득: 데이터를 분할할 때의 효율성 측정 기준
랜덤 포레스트 (Random Forest)
- 배깅(Bagging): 데이터 샘플을 중복 허용으로 여러 번 샘플링하여 모델을 학습
- 앙상블 학습: 여러 모델을 결합하여 성능 향상
서포트 벡터 머신 (SVM)- 초평면: 데이터를 분리하는 기준이 되는 선
- 마진: 초평면에서 각 데이터 포인트까지의 거리
XGBoost
- 부스팅: 여러 약한 모델을 순차적으로 학습시키는 기법
- 정규화: 모델의 과적합을 방지하기 위한 방법
LightGBM
- 리프 우선 학습: 트리에서 리프 노드를 먼저 확장하는 학습 방식
- 히스토그램 기반: 데이터를 효율적으로 처리하는 방법
K-means
- 클러스터: 비슷한 데이터를 그룹화한 집합
- 유클리드 거리: K-최근접과 동일
[(선택)실무 적용 사례]
아티클에서 다룬 분석 방법을 실제 업무에서 어떻게 적용할 수 있을까요?
관련 사례를 찾아보거나, 가상의 시나리오를 만들어보세요.
생략 → 핵심 개념 정리하는 데 시간을 다 썼음…
인사이트
해당 아티클을 읽고 새롭게 알게 된 것, 앞으로 나의 방향성에 대한 회고가 있다면 적어주세요. 인사이트가 가장 중요합니다.
- 데이터 유형에 따라 알맞은 머신러닝 알고리즘을 사용해야 한다는 것을 알았음
- 내가 가진 데이터의 유형을 어떻게 파악하고 적합한 알고리즘을 결정할 것인지 실제 데이터들을 확인해보며 몸에 익혀야 할 것 같음
