선정 아티클
요약
[아티클 요약 및 주요 내용]
요약 : 아티클의 핵심 내용을 요약해보세요.
-
데이터 수집과 분석의 효율성을 높이기 위해서 양질의 데이터를 판별할 줄 아는 능력이 중요함
-
분석에 유리한 데이터를 양질의 데이터라고 정의한다면, 양질의 데이터는 5가지 정도의 특징을 가짐 → 분석하기 쉬운 데이터, 분석 결과물을 이해하기 쉬운 데이터, 분석 결과를 수용하기 용이한 데이터들이 가지는 공통적인 특징
- 데이터의 수가 충분히 많다.
- 데이터 자체의 오류가 적다.
- 관계형데이터베이스 형식을 잘 지키고 있다.
- 수치형 데이터 형식을 많이 보유하고 있다.
- 활용 목적에 적합하다.
주요 포인트 : 아티클에서 강조하는 주요 포인트는 무엇인가요?
-
데이터 양의 중요성
- 적은 데이터 수는 곧바로 분석 결과의 신뢰성 하락으로 연결
- 하지만 데이터 양이 적은 것이 문제가 되지 않을 때도 있고, 적은 데이터로도 충분히 문제를 해결할 수도 있음
- 따라서 '양질의 데이터'와 '데이터의 양'의 관계를 이해하기 위해 데이터의 양이 중요한 상황이 언제인지 알고 충분한 양의 데이터란 어느 정도인지 답할 수 있어야 함!
- 적은 데이터 수는 곧바로 분석 결과의 신뢰성 하락으로 연결
-
데이터 양을 중요하게 고려해야 하는 경우
- 표본이 모집단을 대표해야 하는 경우 데이터 양을 중요하게 고려해야 함
- 데이터 수 자체가 너무 작다면 표본의 대표성에 대해 의구심을 가질 수 있음
- AI 알고리즘을 적용해야 하는 경우
- 머신러닝, 딥러닝 기술이 반드시 필요하다면 데이터의 양을 우선적으로 확인해야 함
- 표본이 모집단을 대표해야 하는 경우 데이터 양을 중요하게 고려해야 함
-
어느 정도의 데이터가 충분한 양일까?
- 절대적인 기준이 없음
- 상황에 따라, 데이터를 분석하는 목적과 방법에 따라 다름!
- 통계적 분석을 할 때는 최소 500개 이상의 데이터가 필요
- 머신러닝 분야에서는 변수의 수에 100을 곱한 것보다 많은 양의 데이터가 필요
-
데이터 양은 분석 결과의 신뢰도로 연결되는 중요한 부분임
[핵심 개념 및 용어 정리]
- 핵심 개념: 아티클에서 언급된 중요한 개념을 정리하세요.
- 용어 정리: 생소하거나 중요한 용어의 정의를 적어보세요.
- 핵심 개념:
- 양질의 데이터
- 통계적 유의미성
- 용어 정리
- 통계적 유의미성
- 분석 결과를 통계절으로 신뢰할 수 있는가에 대한 지표
- 통계적 유의미성
[(선택)실무 적용 사례]
아티클에서 다룬 분석 방법을 실제 업무에서 어떻게 적용할 수 있을까요?
관련 사례를 찾아보거나, 가상의 시나리오를 만들어보세요.
- 실무 적용 : AI HEROES
- 관련 사례 :
SK 주식회사 C&C
양질의 데이터 서비스를 위한 데이터 통합 관리체계 - 가상 시나리오 :
인사이트
해당 아티클을 읽고 새롭게 알게 된 것, 앞으로 나의 방향성에 대한 회고가 있다면 적어주세요. 인사이트가 가장 중요합니다.
- 머신러닝 수업에서 과적합 방지 방법 중 하나로 데이터 증강(보다 다양하고 많은 양의 데이터를 활용)이 있는 이유도 여기에 속하지 않을까?
추가 정리
- 빅데이터를 모두 쉽게 활용할 수 있는 것은 아님
- 어떤 데이터는 다른 데이터와 반드시 연결되어야 함
- 어떤 데이터는 심각한 오류를 가지고 있어 애초에 활용이 불가능할 때도 있음
- 양질의 데이터란 무엇인가?
- 데이터의 품질이 높을수록 활용 가치가 높음
- 데이터가 명확하고 깔끔해 해석이 용이한 경향이 있기 때문
- 양질의 데이터가 아니라고 해서 분석이 아예 불가능한 건 아님
- 정말 필요한 데이터가 품질이 낮을 경우 가공하고 보완해 활용 가능
- 데이터의 품질이 높을수록 활용 가치가 높음
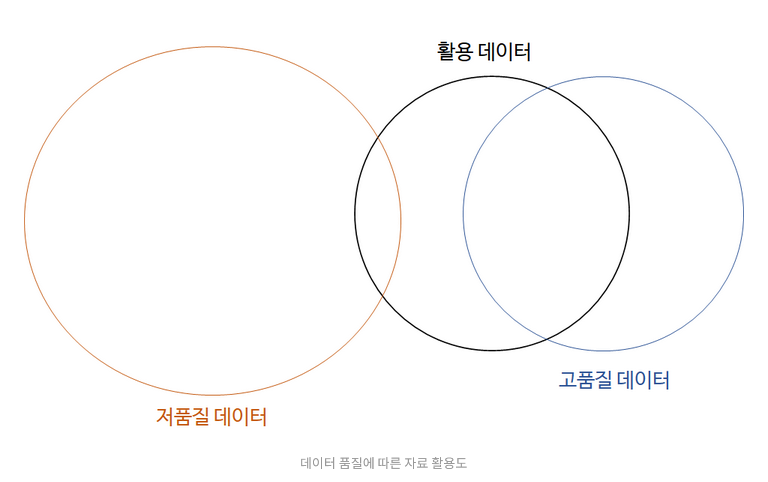
→ 저품질 데이터라고 모두 활용되지 않는 것은 아니지만 고품질의 데이터일수록 실제로 활용될 확률이 높음
-
생각보다 저품질 데이터가 많음
- 데이터 분석가의 실력이나 창의성과는 별개로 도저히 활용이 불가능한 데이터가 상당수 존재하는 것이 현실
-
데이터를 무작정 많이 수집하는 것이 분석 소스 확보 측면에서 장점이 있는 것은 맞지만 효율성을 고려하면 그리 추천할 만한 행동이 아님
- 활용 가치가 없는 혹은 활용하기에 너무나 애로 사항이 많은 데이터는 애초에 수집을 하지 않거나 분석을 시도하지 않는 것이 경제적인 비용과 시간적인 비용 측면에서 우수
-
양질의 데이터를 판단하는 기준 5가지
- 양질의 데이터라고 해서 5가지의 모든 조건을 철저히 지키고 있는 것은 아니며, 낮은 품질의 데이터라고 해서 5가지의 조건과 모두 어긋나는 것은 아니지만 5가지 특징을 명확히 이해한다면 보편적인 양질의 데이터를 판별하는 데 큰 도움이 됨
-
통계적 분석을 할 때는 대부분의 분석 알고리즘이 "통계적 유의미성"을 산출
- 분석 결과를 통계적으로 신뢰할 수 있는가에 대한 지표
- 보통 데이터 수가 약 300~500개 이상이 될 때부터 이 수치가 안정적인 흐름으로 산출
- 따라서 학계에서도 통계적 분석을 할 때 해당 숫자 이상의 데이터를 이용했다면 결과를 어느 정도 신뢰함
-
머신러닝 분야에서는 충분한 양의 데이터를 논의하는 것이 조금 더 어령무
- 기본 전제: 데이터가 많을 수록 좋음
- 최소한의 수준은 존재
- 컬럼(변수)의 개수에 따라 수준이 결정됨
(변수의 수가 많을수록 이를 학습하기 위한 데이터도 많이 필요하기 때문) - 일반적으로 변수의 수에 100을 곱한 것보다 데이터 수가 많다면 데이터 수 자체에 의구심을 가지지 않음
- 컬럼(변수)의 개수에 따라 수준이 결정됨
추가로 읽어볼 만한 내용

2 B R 0 2 B