Process와 Thread
- Process
- 프로그램의 실행 단위
- 4GB의 주소 공간 그리고 파일, 메모리, 스레드 등의 객체를 가짐
- Process가 종료될 때 운영체제에 의해 소유 자원이 파괴됨
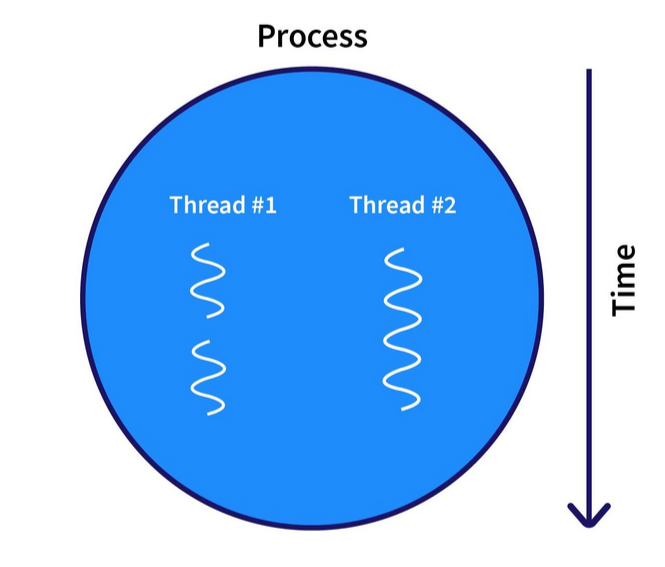
- Thread
- Process의 작업을 처리
- Thread별로 보통 1M의 Stack 공간이 할당됨
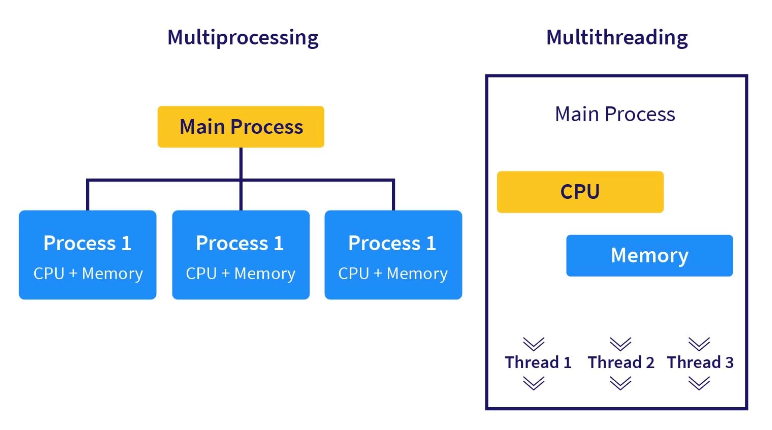
Multi-Process와 Multi-Thread

-
Multi-Process는 독립적인 메모리 공간을 가짐
-
Multi-Thread는 하나의 Process의 작업을 나누어 하므로 자원을 공유

읽어보면 좋을 내용 -
각각의 Process와 Thread들은 CPU에 의해 스케줄링됨
- Round-Robin
- Time Slice를 통해 정해진 시간만큼만 실행
- SFJ(Shortest First Job)
- 최소 작업을 우선으로 함
- Priority Scheduling
- 우선 순위에 따라 처리
- Round-Robin
-
작업 전환에는 Context Switching 시간이 포함
- Process Control Block, Thread Control Block에 현재 실행 중인 메모리의 주소, 코드의 위치 등을 기록하고 실행중인 Process나 Thread를 바꾸는 작업을 말함
- Thread의 경우, 자원을 공유하기 때문에 Process에 비해 작업 전환 속도가 빠름
발생 가능한 문제
- 작업 처리 중 자원을 공유하는 것은 다양한 문제를 발생시킬 수 있음
- 해결을 위해 Critical Section, Mutex, Semapore 등으로 공유 자원에 대한 접근을 제어
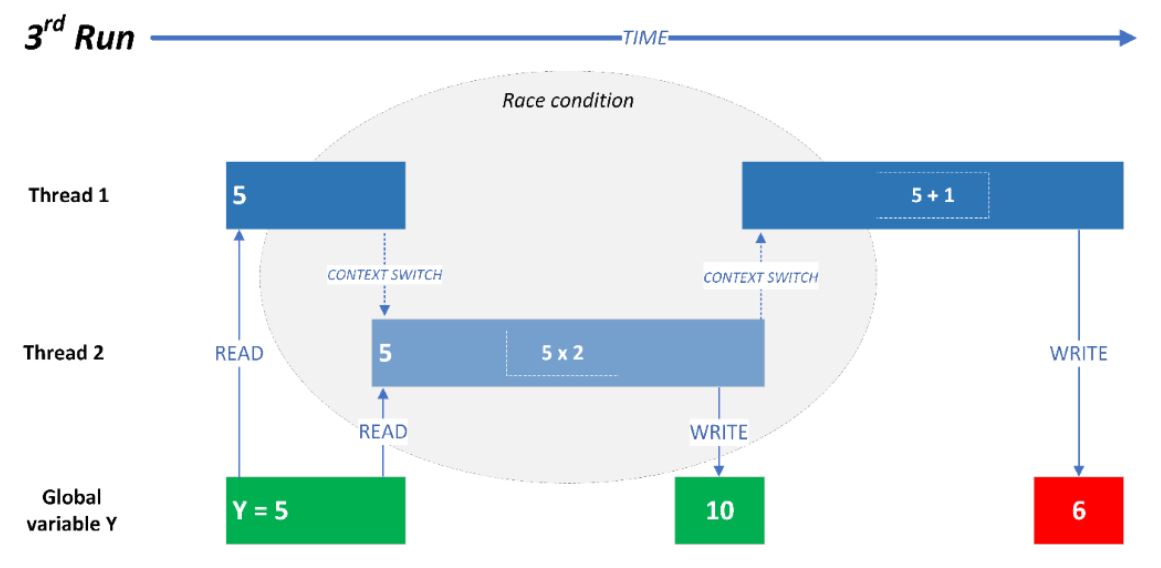
문제 1: RACE CONDITION
-
Race condition
- 둘 이상의 입력 또는 조작의 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태
- 공유(공통) 자원을 둘 이상의 스레드 혹은 프로세스가 읽거나 쓰면서 결과값이 의도와 달라질 수 있는 문제

-
Race condition의 문제점
- 예측 불가능한 결과
- 여러 스레드나 프로세스마다 실행 속도가 달라서 잘못된 값을 읽거나 수정할 수 있음
- A스레드가 수정 한 결과를 B가 수정하면서 A가 수정한 결과는 없어지게 됨
- 일관성 손실
- 여러 스레드나 프로세스가 데이터를 수정 시 예기치 않은 상태로 데이터가 변경될 수 있음
- 디버깅의 어려움
- 여러 스레드나 프로세스의 각각 다른 실행 속도로 인해 실행 흐름을 읽기 힘들어 디버깅이 힘듦
- 잠금 대기 시간
- Race condition을 방지하기 위해 무분별한 락(Lock)을 사용할 시, 대기 시간으로 인해 성능 저하가 발생할 수 있음
- 예측 불가능한 결과
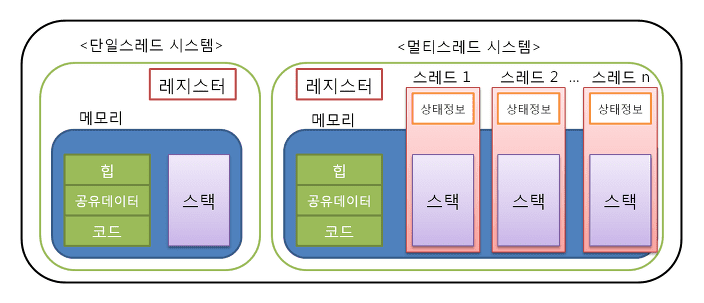
멀티 스레드에서의 공유 영역에는 대표적으로 데이터 영역과 힙 영역이 있습니다.
반대로 공유하지 않는 영역은 스택 영역입니다.
멀티 스레드 프로그래밍의 장점은 공유 영역을 여러 일들을 병렬로 처리 할 수 있는 것도 있지만, 자원을 공유하면서 생성과 관리의 중복성을 최소화 할 수 있는 장점도 있습니다.
하지만 이런 공유 영역이 양날의 검처럼 문제도 발생 할 위험이 있는 것입니다.
개념보다는 문제점을 직접 나열해보니 Race condition을 알아야 하는 이유가 좀 더 명확해지고, 멀티 스레드 프로그래밍이 어렵다고 하는 이유를 좀 더 알게 되는 것 같습니다.
- Race condition을 예방하는 방법
- 상호 배제(Mutual Exclusion)
- 공유 데이터에 접근하는 부분을 임계 영역(Critical Section)으로 지정하고, 한 번에 하나의 실행 흐름만 해당 영역에 들어가도록 함
- 공유 데이터를 최소화한 병렬 처리 설계
- 데이터를 적절히 분리하여 각 스레드가 독립적으로 처리하도록 함
- 스레드 안전성 보장(Thread Safe)
- 공유 데이터를 수정하는 함수나 메서드를 스레드 안전하도록 구현
- 스레드 동기화 기법을 사용하거나 불변 객체(Immutable Object) 패턴 적용
- 테스트와 검증
- 코드를 작성 후 테스트를 진행
- 테스트 코드를 작성해서 원하는 결과가 나오는지 확인
- 상호 배제(Mutual Exclusion)
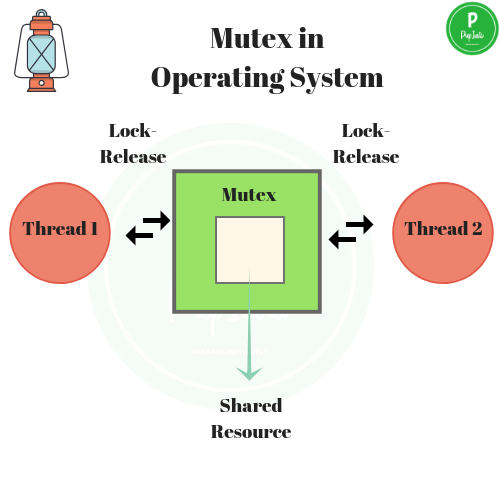
상호 배제(Mutual Exclusion, Mutex)
동시 프로그래밍에서 공유 불가능한 자원의 동시 사용을 피하기 위해 사용되는 알고리즘으로, 임계 구역(critical section)으로 불리는 코드 영역에 의해 구현된다.
- 공유된 자원의 데이터를 여러 스레드가 접근하는 것을 막는 방법
- 공유된 자원은 한 번에 한 프로세스(스레드)만이 사용할 수 있어야 함
- key에 해당하는 어떤 오브젝트(공유자원에 접근하기 위해 필요한 어떤 오브젝트)가 있으며 이 오브젝트를 소유한 (쓰레드, 프로세스) 만이 공유자원에 접근할 수 있음
임계 구역(Critical Section)
공유변수 영역은 병렬컴퓨팅에서 둘 이상의 스레드가 동시에 접근해서 안되는 공유 자원(자료 구조 또는 장치)을 접근하는 코드의 일부를 말한다.
- 간단하게 정리하면 병렬 컴퓨팅과 멀티스레드 프로그래밍에서 상호 배제를 적용하는 부분을 가리키는 용어
- 임계 구역을 효과적으로 사용하는 것은 Race condition과 같은 동시성 문제를 해결하기 위해 중요
- 임계 구역에 접근하기 전에 락(Lock)이나 세마포어(Semaphore)와 같은 동기화 메커니즘을 사용하여 한 번에 하나의 실행 흐름만이 임계구역에 들어갈 수 있도록 함
문제 2: STARVATION
문제 3: DEAD LOCK
Python Code 그리고 GIL
- Python에서 제공하는 모듈인 multiprocessing은 대부분 threading의 API를 복제하기 때문에 코드가 비슷함
- 하지만, Python의 GIL로 인해 Thread를 사용할 경우, 수행하는 작업에 따라 싱글 스레드와 차이가 없을 수 있음
- GIL(Global Interpreter Lock)
- CPython에서 여러 개의 thread들이 동시에 bytecode를 실행하는 것을 방지하기 위해 만들어진 것
- Thread safe 하지 않은 자원들을 보호하기 위함
- Bytecode를 실행하기 위해 interpreter의 lock을 획득해야 함 → multi-thread로 동작할 수 없음
- Python Runtime과 상호 작용하는 것(GIL의 영향을 받는 것)들은 GIL로 인해 Single Thread로 동작
- PEP 703 – Making the Global Interpreter Lock Optional in CPython 제안을 통해 GIL 제거 추진 중
- 읽어보면 좋을 글
CPython?
C파이썬(CPython)은 파이썬 프로그래밍 언어의 참조 구현체이다. C와 파이썬으로 작성된 C파이썬은 이 언어에 가장 널리 사용되는 기본 구현체이다.
C파이썬은 인터프리트 과정 이전에 파이썬 코드를 바이트코드로 컴파일하기 때문에 인터프리터이기도 하고 컴파일러이기도 하다. C를 포함한 여러 언어의 외부 함수 인터페이스를 보유하고 있으며 여기서 파이썬 외의 언어로 바인딩을 명시적으로 작성해야 한다.
- Python 그 자체
- Python 소프트웨어 재단에서 만드는 표준 Python 구현체
- C로 구현되어 있음
cf. pypy : Python Compiler를 Python으로 작성한 Python 구현체
Multi-Thread
import threading
import time
# CPU-bound 작업: 간단한 계산 작업을 시뮬레이션
def cpu_bound_task(start, end, result):
total = 0
for i in range(start, end):
total += i
result.append(total)
if __name__ == "__main__":
# CPU-bound 작업을 위한 범위 및 스레드 개수 설정
total_numbers = 10**7
num_threads = 2
chunk_size = total_numbers // num_threads
# 단일 스레드로 작업 실행
start_time_single = time.time()
cpu_bound_task(1, total_numbers + 1, [])
end_time_single = time.time()
execution_time_single = end_time_single - start_time_single
# 멀티스레딩으로 작업 실행
start_time_multi = time.time()
result_list = []
threads = []
for i in range(num_threads):
start = i * chunk_size + 1
# 실행 thread 개수만큼 데이터 나누기
end = (i + 1) * chunk_size + 1 if i < num_threads - 1 else total_numbers + 1
thread = threading.Thread(target=cpu_bound_task, args=(start, end, result_list))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
total_result = sum(result_list)
end_time_multi = time.time()
execution_time_multi = end_time_multi - start_time_multi
print(f"단일 스레드 실행 시간: {execution_time_single:.4f} 초")
print(f"멀티스레딩 실행 시간: {execution_time_multi:.4f} 초")
# 단일 스레드 실행 시간: 0.3817 초
# 멀티스레딩 실행 시간: 0.3829 초Multi-Process
import multiprocessing
from queue import Queue
import time
# CPU-bound 작업: 간단한 계산 작업을 시뮬레이션
def cpu_bound_task(start, end, result):
total = 0
for i in range(start, end):
total += i
result.put(total)
if __name__ == "__main__":
# CPU-bound 작업을 위한 범위 및 프로세스 개수 설정
total_numbers = 10**7
num_processes = 4
chunk_size = total_numbers // num_processes
# 단일 프로세스로 작업 실행
start_time_single = time.time()
single_result = Queue()
cpu_bound_task(1, total_numbers + 1, single_result)
end_time_single = time.time()
execution_time_single = end_time_single - start_time_single
# 멀티프로세스로 작업 실행
start_time_multi = time.time()
result_queue = multiprocessing.Queue()
processes = []
for i in range(num_processes):
start = i * chunk_size + 1
# 실행 process 개수만큼 데이터 나누기
end = (i + 1) * chunk_size + 1 if i < num_processes - 1 else total_numbers + 1
process = multiprocessing.Process(target=cpu_bound_task, args=(start, end, result_queue))
processes.append(process)
process.start()
for process in processes:
process.join()
total_result = sum([result_queue.get() for _ in range(num_processes)])
end_time_multi = time.time()
execution_time_multi = end_time_multi - start_time_multi
print(f"단일 프로세스 실행 시간: {execution_time_single:.4f} 초")
print(f"멀티프로세스 실행 시간: {execution_time_multi:.4f} 초")
# 단일 프로세스 실행 시간: 0.3874 초
# 멀티프로세스 실행 시간: 0.2981 초