[인공지능사관학교: 자연어분석A반] JavaScript (7) / LangChain
목차
Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
2. JS 코드 파일로 분리하기
3. jQuery 라이브러리
B. 2교시
1. jQuery 라이브러리 (cont.)
C. 3교시
1. jQuery 라이브러리 (cont.)
Ⅱ. 오후 수업
A. 4교시: LangChain
1. LLM 이해하기
B. 5교시
1. LLM 이해하기 (cont.)
C. 6교시
1.LangChain으로 LLM 연동하기
Ⅲ. CARRER UP
A. 네이버 클라우드 특강
Ⅳ. 하루 돌아보기Ⅰ. 오전 수업
A. 1교시: JavaScript
1. 지난 시간 복습
- 속성(attribute) 제어
- 요소를 먼저 가져온 다음 속성의 이름을 키 값으로 명시하면 됨! (js로 특정 속성에 접근할 때는 속성명을 키 값으로 활용)
- input 태그는 value라는 속성에 입력된 값을 저장
- cf. innerHTML, innerText → 컨텐츠 제어
- class 속성명은 사용 불가 → className(자주 사용), classList로 조회 가능
- img 태그 src 속성
- style 속성
- 이미 안쪽에 너무 많은 값들이 존재하고 의미가 다른 데이터가 있음 → style 자체가 객체 구조임
- 인라인 방식 제어: 단순 스타일(1-2개) 제어에는 효율적이나 여러 개의 스타일을 제어할 때는 가독성 X, 유지 보수 X
- 현업에서는 CSS 파일을 미리 만들어 놓고 조건에 따라 다르게 적용 (클래스 값을 변경 → 변경된 class에 해당하는 CSS 적용됨)
vanila JS: 프론트엔드 라이브러리(리엑트, 뷰, 앵귤러 등) 사용하지 않고 작업한 경우를 지칭
jQuery 라이브러리
비동기 통신
2. JS 코드 파일로 분리하기
- CSS 파일은
<link rel="stylesheet" href="style.css">로 연결하고 head에 쓰지만 JS 파일은<script src="function.js"></script>로 연결하고 body 맨 밑에 작성한다- 주의점: script 태그에서 src를 통해 파일과 HTML을 연결한 경우(import 용도의 script 태그를 사용한 경우) script 코드 안(컨텐츠)에 코드 쓰면 절대 안 됨! → 내부에 코드를 적으면 충돌 발생
- HTML, CSS, JS를 완벽하게 분리해 사용하면 좋은 점
- 가독성: 코드가 깔끔
- 노출이 되지 않음
- 파일 불러오는 한 줄만 있으면 어떤 파일에서든 내용을 끌어올 수 있음
- Q. script 태그를 head에 쓰면 안 되나요?
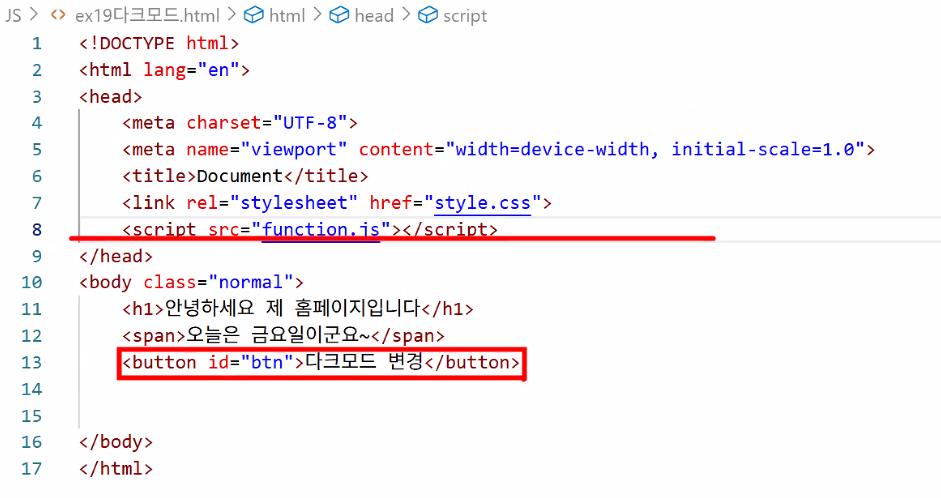
- A. 코드의 실행 순서가 바뀌면 오류 발생
- 개발자 모드의 콘솔창 열어 오류 확인하기

- 컴퓨터가 코드를 위에서부터 아래로 읽어들이면서 동작 → btn이 없음 → null에는 addEventListener를 붙일 수 없습니다 <오류 출력>
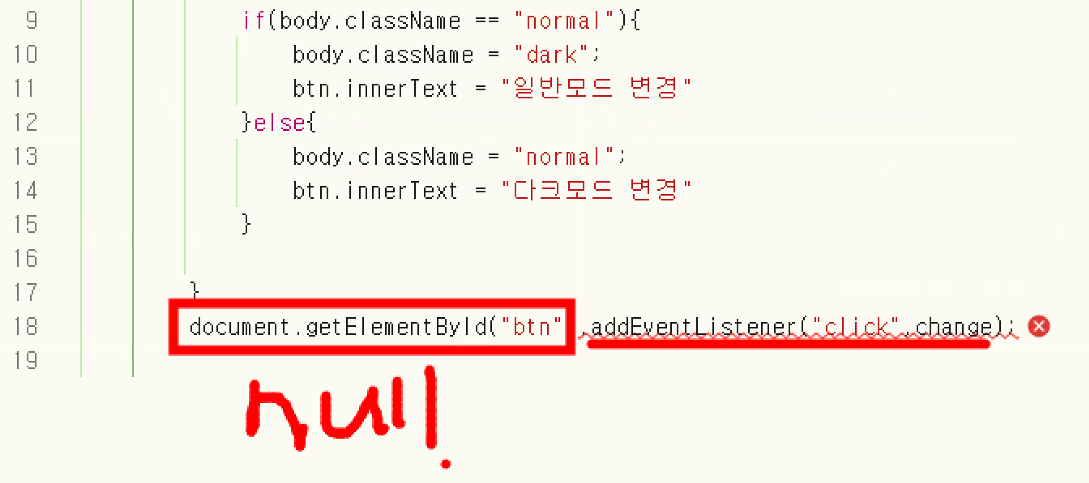
- 동작 순서: CSS는 앞에 있어도 마지막에 실행됨(DOM 생성 이후 랜더링이 진행되기 때문)
- js에서 버튼에 이벤트 리스너를 연결시켰으니까 버튼 먼저 만들어진 다음에 js 파일을 불러와야 함
- 개발자 모드의 콘솔창 열어 오류 확인하기
- A. 코드의 실행 순서가 바뀌면 오류 발생
- js 파일 실행 순서의 중요성
- 자바스크립트 api는 head에서 불러옴: 코드로 실행 순서를 맨 마지막으로 보낸다는 내용이 구현되어어 있어서 앞에 적어도 괜찮음 (코드 처리가 이미 되어 있는 상태)
- 우리가 작성한 파일은 그런 내용이 없기 때문에 순서를 잘 지켜야 함
- JS 외부 방식 주의점 2가지
- 파일을 불러올 때는 src에 경로를 작성 → 불러오는 script 태그에는 절대 코드를 적지 않는다.
- 실행 위치가 매우 중요하다
- 외부 라이브러리를 활용할 때는 보통 head에 작성
- 내가 작성한 파일은 body 태그 끝나기 전에 작성한다. → 맨 밑에 작성한다.
3. jQuery 라이브러리
- 등장 배경
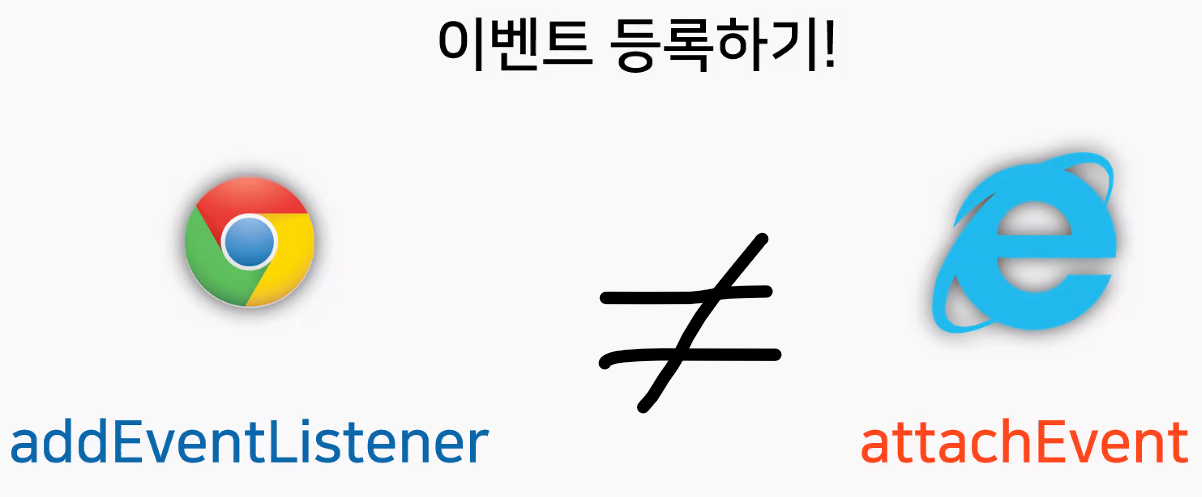
- John Resig: "Cross Browser Javascript 작성이 너무 어려워!" → 자체 JS 라이브러리 작성의 계기 → jQuery
- Cross Browser 문제 때문에 만들었지만 지금은 이것 때문에 잘 안 쓴다고 함(아이러니…) → explorer가 사라지면서 'attachEvent'가 사라졌기 때문
- JS 기본 문법 자체가 너무 길어요! → 쉽게 쓰자: "write less, do more"
- explore 살아있던 시절 이벤트 등록
B. 2교시
1. jQuery 라이브러리 (cont.)
- 라이브러리 설치: 공식 홈페이지
- 버전 2가지
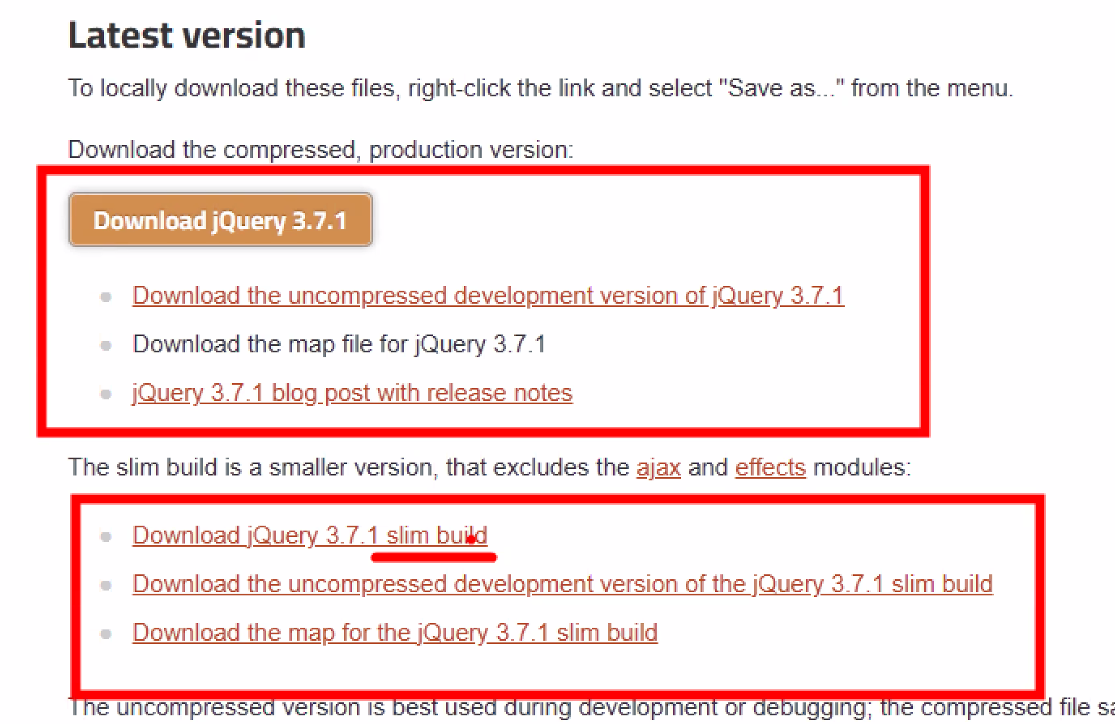
- 우리는 ajax가 필요해서 compressed, production version 쓸 거임
- compressed와 uncompressed 차이
- compressed

- uncompressed

- compressed
- 버전 2가지
이래서 세미콜론 잘 적으라고 하신 거구나!

C. 3교시
1. jQuery 라이브러리 (cont.)
-
접근을 jQuery로 했다면 명령도 모두 jQuery로 처리해야 함!
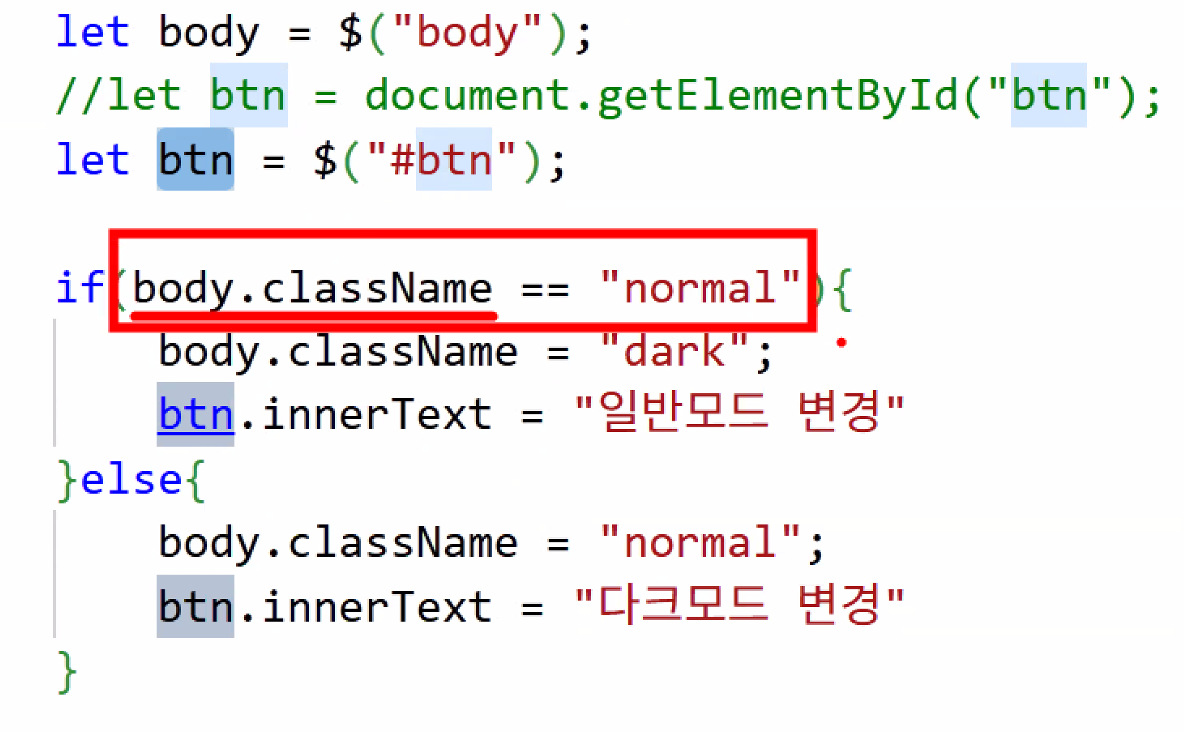
- JavaScript 부분을 jQuery 문법으로 바꾸기
- body는 3인칭 →
hasClass
- body는 3인칭 →
- JavaScript 부분을 jQuery 문법으로 바꾸기
-
추가: 토글 클래스라는 기법도 있음(add와 remove가 합쳐진 형태)
- 중요한 건 로직을 이해하는 것
- jQuery로 디자인 변경하기
- 클래스 값을 조회 → hasClass()
- 클래스 값을 더해주기 → addClass()
- 주의점: 클래스는 복수개를 가질 수 있다 → removeClass()
- 포인트: 순수 js와 jquery는 혼합해서 사용하지 말자
함수를 연결해서 쓰는 것도 가능
요즘 쓰는 라이브러리(라액트, 뷰, 앵귤러 등)는 document를 직접 제어하지 않고 가상 DOM을 이용해 함수로 접근하기 때문에 jQuery 사용 빈도도 줄어들었습니다.
Ⅱ. 오후 수업
A. 4교시: LangChain
1. LLM 이해하기
LangChain이란?
이제까지 배운 건 대규모 언어 모델 개발 과정 → 여기부터는 '활용법'!
- 대규모 언어 모델(LLM)을 활용하여 애플리케이션 개발을 돕는 라이브러리
- 다양한 기능을 할 수 있도록 구성 요소를 만드는 역할
- LangChain은 여러 구성 요소들을 사슬(chain)처럼 연결하여 복잡한 작업을 처리함
- 블록 코드처럼 묶어서 챗봇을 만들 수 있음
- LLM을 통하여 데이터를 분석하고, 질문하거나 답을 주는 작업을 진행
- LLM 모델의 한계를 극복하기 위해 등장
주요 기능
- 문맥 인식을 통한 추론
- 제공된 문맥에 기반하여 어떤 대답을 해야 하는지 결과를 내는 것 (→ ChatGPT)
대규모 언어 모델(LLM)의 한계
- 일반적인 상황(== 모델이 학습한 상황)에서의 응답 능력은 탁월하나, 훈련한 적이 없는 영역에서의 성능이 떨어짐 → 환각(Hallucination) → Data Sources로 보완
- LLM 모델은 상태를 저장하지 않으므로 이전 대화 내용을 기억하지 못함 → Vector Database가 보완
- 메모리 기능, 프롬프트 기능, RAG 기능 추가
- 서로 다른 시나리오(task)에 특화된 다양한 모델을 사용해야 함
LLM의 한계점 극복 → LangChain
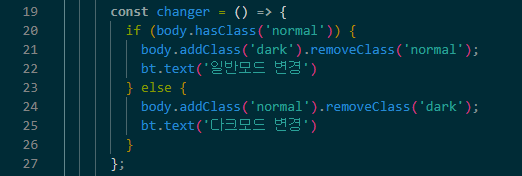
- LangChain은 다양한 문제점을 해결하는 방안을 제공
- Data Sources
- LangChain은 서로 다른 데이터에 엑세스하고 검색할 수 있는 모듈과 원활하게 통합
- PDF 파일, 웹 페이지, CSV 파일 같은 외부 소스에서 데이터 검색이 가능
- Word Embeddings
- 선택한 LLM을 기반으로 최적의 임베딩 모델을 선택
- Vector Database
- 메모리를 저장하고 검색하여 사용할 수 있도록 지원
- 이전 대화에 대해 memeory를 가져 기억 능력을 가지게 됨
- LLM
- 랭체인은 OpenAI에서 제공하는 다양한 LLM 모델들을 활용 가능. 업데이트도 빠름.
API key 발급 및 사용
- OpenAI platform 확인
- OpenAI API 키 발급 및 테스트
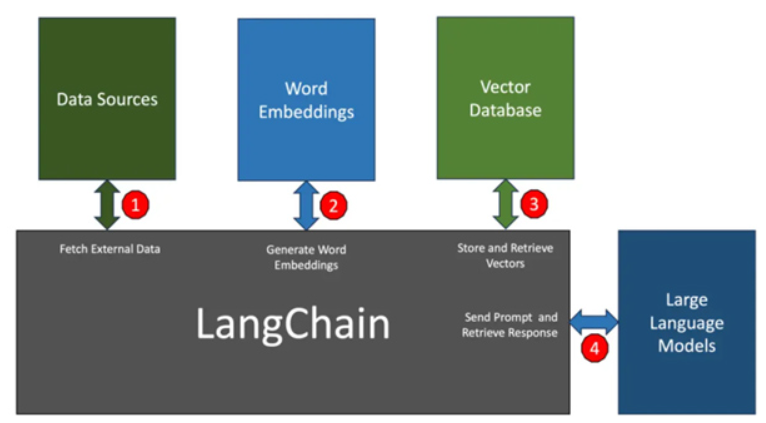
- 우측 프로필 이미지 클릭 →
Your profile클릭 User API keys클릭 →Create new secrete key버튼을 클릭
- 이름 입력
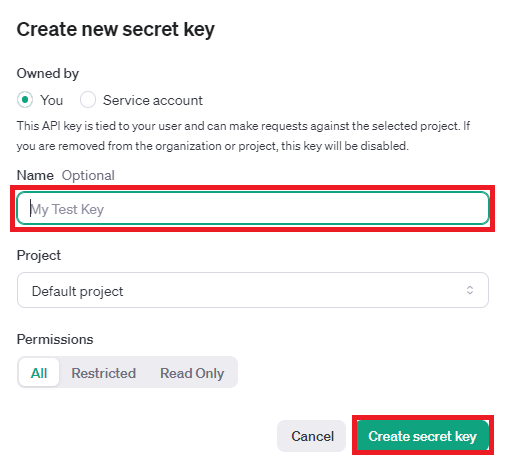
- API 키 복사

- 우측 프로필 이미지 클릭 →
⚠️주의사항 : API 키는 한 번만 제공됨, 복사하여 개인 메모장(또는 마크다운)에 저장해둘 것을 권장
# api key 파일로 저장(최초 1회만)
import os
if not os.path.exists("./key"):
os.mkdir("./key")
# api_key
api_key = "★자신의 API 키 입력★"
with open("./key/.openai_api_key", 'w') as f:
f.write(api_key)- api 키를 파일로 저장해 두고 아래와 같이 불러와 쓰면 편함
# 앞으로 사용할 때에는
# 구글 마운트 → 저장된 api_key 불러서 사용
with open("./key/.openai_api_key", 'r') as f:
api_key = f.read().strip()
# 환경 변수 설정
# 환경 변수는 딕셔너리 형태
os.environ["OPENAI_API_KEY"] = api_key # environ: an abbreviation for environment라이브러리 설치
!pip install -U langchain langchain-openai- langchain: 랭체인 기본 라이브러리
- langchain-openai: open-ai의 llm 모델을 연동할 수 있는 라이브러리
B. 5교시: LangChain
1. LLM 이해하기 (cont.)
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
llm.invoke("오늘 저녁 메뉴 추천해 줘.")AIMessage(content='저녁 메뉴로는 불고기와 삼겹살을 함께 먹는 "삼겹살 불고기 세트"를 추천해 드립니다. 쫄깃한 삼겹살과 고기가 어우러진 맛은 일품이에요. 쌈과 상추, 마늘 등과 함께 식사하면 더욱 맛있답니다. 많이 드세요.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 133, 'prompt_tokens': 25, 'total_tokens': 158, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'id': 'chatcmpl-C8K2tRGMy0YbXYdYHm0nDroZv3uLb', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='run--91ea209b-cd3b-486b-8064-755f12d67418-0', usage_metadata={'input_tokens': 25, 'output_tokens': 133, 'total_tokens': 158, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})res = llm.invoke("영어 단어 'invoke' 뜻이 뭔가요? 해당 단어는 어디에서 유래했나요? 혹시 라틴어인가요?")
res.content'invoke'는 누군가를 부르거나 참조하거나, 또는 법적인 권리나 규칙을 새롭게 활용하거나 요청하는 것을 의미합니다. 이 단어는 라틴어에서 유래되었으며, "invocare"라는 라틴어 동사에서 파생되었습니다. "invocare"는 "호출하다"나 "기도하다"를 의미하며, 영어로 번역되면 'invoke'가 됩니다.res.response_metadata{'token_usage': {'completion_tokens': 153,
'prompt_tokens': 57,
'total_tokens': 210,
'completion_tokens_details': {'accepted_prediction_tokens': 0,
'audio_tokens': 0,
'reasoning_tokens': 0,
'rejected_prediction_tokens': 0},
'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}},
'model_name': 'gpt-3.5-turbo-0125',
'system_fingerprint': None,
'id': 'chatcmpl-C8K5Ny4FjvEZ0Ark3IWwVuRdi45gd',
'service_tier': 'default',
'finish_reason': 'stop',
'logprobs': None}stream 기능 맛보기
- 다양한 stream 기능이 존재
llm.stream("★질문 내용★)하면 실시간으로 입력하듯이 출력됨
모델 변경해보기
llm_model4o = ChatOpenAI(model="gpt-4o-mini", max_tokens=1000, temperature=0)- model: 사용할 모델을 지정하는 부분
- max_tokens: 한 번 응답 시 최대 생성할 토큰 수 제한 (토큰 사용량이 많아질 수 있음)
- temperature: 창의성 → 0에 가까울수록 일관된 답변을 함
- 모델 더 알아보기
llm_model4o.invoke("불닭볶음면이 전 세계에서 얼마나 유명하니?")AIMessage(content='불닭볶음면은 전 세계적으로 매우 유명한 한국의 인스턴트 면 중 하나입니다. 이 제품은 특히 매운 맛과 독특한 풍미로 많은 사람들에게 사랑받고 있습니다. \n\n불닭볶음면은 유튜브와 소셜 미디어에서 다양한 챌린지와 리뷰 영상으로 인기를 끌었으며, 많은 외국인들이 매운 음식을 도전하는 콘텐츠에서 자주 등장합니다. 또한, 한국 음식에 대한 관심이 높아지면서 불닭볶음면은 해외에서도 쉽게 구할 수 있는 제품이 되었습니다.\n\n이 외에도 불닭볶음면은 다양한 맛과 형태로 출시되어 소비자들의 선택 폭을 넓혔고, 이를 통해 더욱 많은 사람들에게 알려지게 되었습니다. 전 세계적으로 한국 음식의 인기가 높아짐에 따라 불닭볶음면도 그 인기를 이어가고 있습니다.', additional_kwargs={'refusal': None}, (이하생략)→ max_token을 사용해 content 내용이 길어졌음
C. 6교시: LangChain
1. LangChain으로 LLM 연동하기
프롬프트 작성 원칙
- 모델이 최대한 정확하고 유용한 정보를 제공할 수 있도록 효과적인 프롬프트를 작성하는 것이 매우 중요
- 명확성과 구체성
- 질문은 명확하고 구체적이어야 함 (모호한 질문은 LLM 모델의 혼란을 초래)
- 예시: "주식 시장은 ?" -> "다음 주 주식 시장에 영향을 줄 수 있는 예정된 이벤트들은 무엇일까?"
- 배경 정보 포함
- 모델이 문맥을 이해할 수 있도록 필요한 배경 정보 제공 (환각 현상(hallucination) 감소 및 관련성 높은 응답 생성)
- 예시: "2020년 미국 대선의 결과를 바탕으로 현재 정치 상황에 대한 분석을 해주세요"
- 간결함
- 핵심 정보에 초점을 맞추고, 불필요한 정보는 배제 (복잡하면 덜 중요한 부분에 집중하거나 상당한 영향을 받는 문제 발생)
- 예시: "2021년에 발표된 삼성전자의 ESG 보고서를 요약해주세요."
- 열린 질문 사용
- 열린 질문을 통해 모델이 자세하고 풍부한 답변을 제공하도록 유도 (예/아니오로 답변하는 질문보다는 많은 답변을 요구하는 질문)
- 예시: "신재생에너지에 대한 최신 연구 동향은 무엇인가요?"
- 명확한 목표 설정
- 얻고자 하는 정보나 결과의 유형을 정확하게 정의 (명확한 지침에 따라 응답을 생성)
- 예시: "AI 윤리에 대한 문제점과 해결 방안을 요약하여 설명해주세요."
- 언어와 문체
- 대화의 맥락에 적합한 언어와 문체를 선택 (상황에 맞는 표현 선택)
- 예시: 공식적인 보고서를 요청하는 경우, "XX 보고서에 대한 전문적인 요약을 부탁드립니다."와 같이 정중한 문체를 사용
- 페르소나 설정
- llm에게 역할을 부여
- 예시: "당신은 인공지능 전문 강사입니다. ~"
- 맞춤 설정 가능
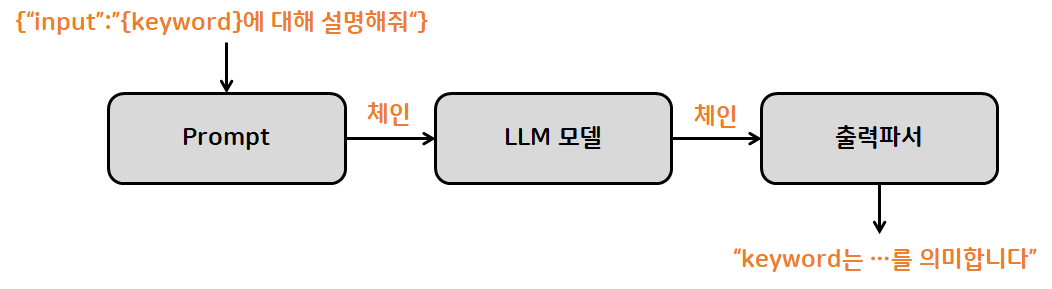
LCEL (LangChain Expression Language)
- 체인을 구성하고 기본적으로 사용하는 방법
- 파이프라인(|)으로 체인 생성
|(vertical bar) 기호를 사용하여 체인 연결을 진행- 예:
prompt | llm | OutputParser와 같이 체인이 연결된 경우
- 예:
# 프롬프트 탬플릿 지정
from langchain_core.prompts import PromptTemplate
# 수도를 물어보는 템플릿에 모델을 연결하는 체인 생성
prompt = PromptTemplate.from_template("{country}의 수도는 어디야?")
# 모델 불러오기
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
chain = prompt|llm
# 체인
print(chain.invoke({"country":"한국"}))content='한국의 수도는 서울이다.' additional_kwargs={'refusal': None} (이하생략)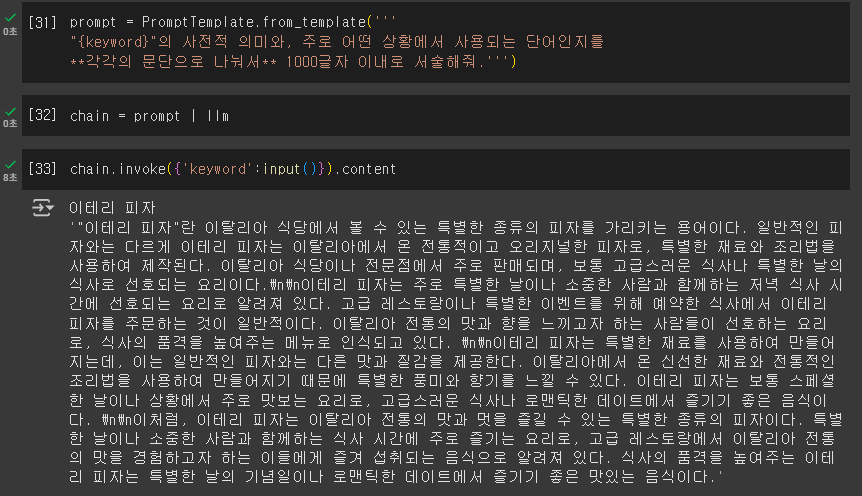
# 기본 LLM 사용 시
llm.invoke("오늘은 기분이 좋아").content요! 기분이 좋으시다니 정말 좋아요. 좋은 일 있으셨나요? 함께 기쁨을 나눌 수 있어서 기뻐요. 웃음 가득한 하루 보내세요! 😊template = "{sentence} 문장의 감성을 분석해 줘"
# 템플릿 객체 생성
pormpt2 = PromptTemplate.from_template(template)
# 체인 연결
chain2 = pormpt2|llm
# 결과 확인
print(chain2.invoke({"sentence": "오늘은 기분이 좋아"}))content='오늘은 기분이 좋아\n\n긍정적인 감성을 풍깁니다. 오늘의 기분이 양호하고 즐거운 것으로 보입니다.행복한 일이 있었을 가능성이 높아보입니다. 오늘 하루가 기분 좋게 지내셨으면 좋겠습니다.' additional_kwargs={'refusal': None} (이하생략)Ⅲ. CARRER UP
A. 네이버 클라우드 특강
네이버 클라우드
- 전신: 네이버 비즈니스 플랫폼
- CSAP
- DAN (네이버 행사)
CSP vs. MSP
- Cloud Service Provider(클라우드 서비스 제공자)
- Managed Service Provider(클라우드 운영 대행사)
- 메가존, 디딤365, 네오텍 등
csp → iaas
- AI 자원
- 엔비디아 → GPU
- 하이닉스 반도체 → HBM
국가대표 AI 정예팀
- 네이버 클라우드
- 업스테이지
- SK 텔레콤
- NC AI
- LG AI연구원
하루 돌아보기
👍 잘한 점
- 수업 시간 참여 열심히 함
- 질문하기
- 대답 많이 하기
👎 아쉬웠던 점
- 몸이 안 좋음…
🔬 개선점
- 약 먹고 푹 쉬자!

2 B R 0 2 B