[인공지능사관학교: 자연어분석A반] MFU 특강 (3)
최적화 기법 실습
1. Mixed Precision Training의 FLOPs 영향
- 가장 간단한 최적화 예제
- FP32 vs FP16 성능 비교
- GPU 성능 측정: model, data 모두 cuda에 있음
- FP16 측정에는
autocast()있음- 정밀도가 중요한 건 FP32
- 그 외 계산은 FP16: Mixed Precision Training → 계산 속도 좀 더 빨라짐 (이론상 FP16가 더 빠르기 때문)
- FP32 vs FP16 성능 비교
autocast는 FP32 → FP16 → FP32 간 dtype 변환 오버헤드가 있으며, 이 변환 과정에서 오히려 느려질 수 있음
2. Torch Script로 변환
- 인터프리터 없이도 돌아가게 → 더 빠른 속도!
- '그래프'가 생성됨 (정적 그래프)
scripted_model = torch.jit.trace(model, example_input)- Python 코드 없이 실행 가능한 ScriptModule 객체
- trace 해야 그래프 생성!
- 안 하면 파이썬 인터프리터가 있어야 구동
- '그래프'가 생성됨 (정적 그래프)
jit.trace의 의미
TorchScript는 Python이 없어도 모델을 실행할 수 있게 만든 “고정된 계산 그래프(frozen graph)” 형태
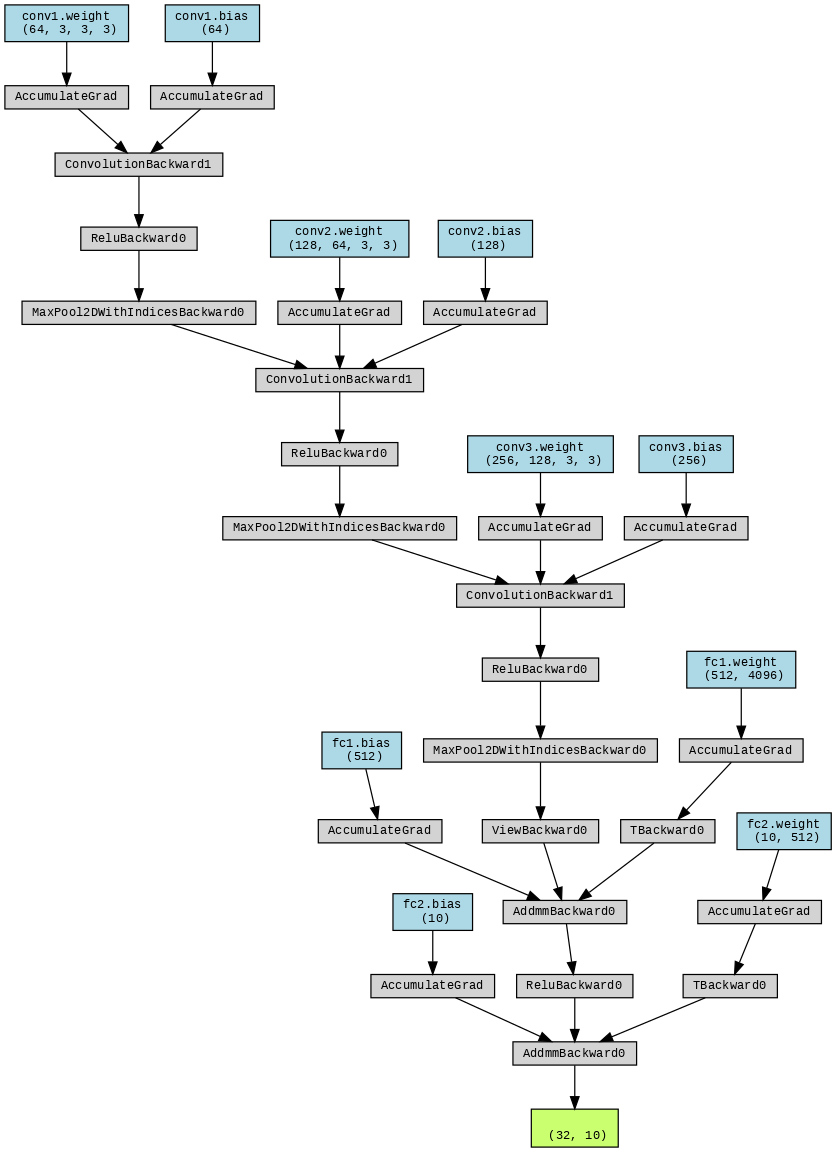
conv1.weight: 필터
합성곱 → repeat
미분은 sum!
MaxPooling
- 지정된 윈도우(커널) 영역 내에서 가장 큰 값만 선택하여 출력으로 남기는 연산
- 합성곱 신경망(CNN)에서 특징 맵(feature map)의 크기를 줄이고, 중요한 특징만 남기기 위해 사용하는 다운샘플링(downsampling) 기법
- pool size와 stride가 같음
pool_size=(2,2), sride=2- 가장 큰 특징만 추출
- 큰 값(특성이 강한 부분)을 선택하므로, 특징의 존재 여부를 더 잘 나타냄
MaxPooling의 미분 (Backpropagation of MaxPooling)
- 선택된 자리가 어딘가에 기록되어 있음
- 평면화시켜서 argmax로 저장
- relu랑 똑같다~
- img2col
(N*OH*OW, C*PH*PW)→ col(4,4)- window에서 보이는 순서대로 기록
핵심은 forward된 자리에만 미분한다는 점
(모든 선택적 연산은 미분이 동일)
핼렬곱의 backward & repeat의 backward
3. Operator Fusion
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x- x값을 넣고 빼는 과정 → 하나로 합치기
- 결과
- Unfused: 0.253 sec, Fused: 0.173 sec
프로파일링 도구 직접 구축하기
private 함수 만들기
- 훈련 가능한 파라미터만 뽑기
trainable_params = sum(p.numel() for p in self.model.parameters() if p.requires_grad)
모델 양자화(quantization)
point: 스케일 팩터, 영점(zero point)
“딥러닝의 양자화(quantization)”와 “물리학에서의 양자화(quantization)”는 공통된 철학적 뿌리를 공유하지만, 의미와 맥락은 완전히 다름
→ “연속적인 것을 이산 단위로 표현한다”는 공통된 사고에서 출발하지만, 적용되는 대상이 다릅니다.
1. 공통점: “연속적인 것을 유한한 단계로 나눈다”
- 두 양자화 모두 연속적인 값을 유한하고 이산(discrete)한 수준으로 표현한다는 점에서 개념적 유사성을 가집니다.
- 이는 “무한히 세밀한 값을 현실적으로 다루기 어렵기 때문에 근사(discretization)로 표현”한다는 철학에서 비롯됩니다.
| 구분 | 공통된 핵심 아이디어 |
|---|---|
| 용어 의미 | 연속적인 물리량 또는 수치를 한정된 단위(quantum)로 나눈다 |
| 이산화(Discretization) | 무한한 상태를 유한한 단계로 근사 표현함 |
| 적용 의도 | 계산 효율성 향상 또는 물리적 현실 반영 |
2. 물리학에서의 양자화 (Physical Quantization)
물리학에서 “양자화(quantization)”는 고전역학적 연속량(에너지, 운동량 등)이 불연속적인 에너지 준위(quantum)로만 존재한다는 이론적 전환을 의미합니다.
예:
- 전자의 에너지는 임의의 값이 아닌 hν 단위로 양자화됨
- 파동함수(ψ)의 에너지 고유값이 이산 스펙트럼으로 제한됨
핵심:
자연계의 연속적 현상을 근본적으로 이산적 단위(quantum) 로 설명하려는 물리학적 패러다임입니다.[5]
3. 딥러닝에서의 양자화 (Numerical Quantization)
딥러닝의 양자화는 모델의 가중치(weights)와 활성값(activations) 을
float32(32비트 부동소수점) 같은 연속적 실수 표현 대신,
int8, int4 등 이산적 정수 표현으로 근사하는 최적화 기법입니다.
즉, 연속적으로 표현된 실수값들을 작은 정수 집합으로 매핑하여:
- 모델 크기를 줄이고 (메모리 절감)
- 계산속도를 높이며 (정수 연산)
- 에너지 효율을 향상시킵니다.[2][3][6]
예:
실제 가중치: [-0.87, 0.11, 0.92]
양자화된 값: [-4, 0, 4] (INT4 기준)
스케일링 팩터: scale = 0.23이렇게 모델을 압축하지만, 신호의 의미는 유지됩니다.
4. 근본적 차이 비교
| 구분 | 물리 양자화 | 딥러닝 양자화 |
|---|---|---|
| 본질 | 자연 현상의 이산화 | 수치 근사(연속 → 정수) |
| 대상 | 에너지, 운동량 등 물리량 | 가중치·활성값 (실수 데이터) |
| 목적 | 자연 규칙 설명 | 계산 최적화, 속도·메모리 절약 |
| 수학적 성격 | 에너지 고유값 문제 해결 (양자역학 방정식) | 부호화/정규화, 스케일링 기반 근사 |
| 불연속 단위 | 플랑크 상수(h) | 정수 정밀도(INT8 등) |
| 수행 방식 | 물리 법칙의 본질적 성질 | 하드웨어 친화적 근사(압축, 효율화) |
5. 결론
-
관념적으로:
딥러닝의 양자화는 물리적 양자화 개념에서 “연속적인 것을 불연속적으로 표현한다(quantum)”는 철학을 차용한 비유적 확장 개념입니다. -
실질적으로:
물리학의 양자화는 자연의 근본 속성 설명,
딥러닝의 양자화는 계산 자원의 최적화를 위한 기술적 근사입니다.
즉, 두 개념은 이름과 철학적 기원은 같지만,
하나는 자연의 본질을 기술하고, 다른 하나는 계산의 효율을 높이는 수학적 기법입니다.
| 유형 | 스케일 s | 제로포인트 z | 특징 |
|---|---|---|---|
| Affine(비대칭) | 0.00784 | 0 | 일반적인 INT8 양자화 |
| Symmetric(대칭) | 0.00784 | -1(또는 0) | 0을 정확히 중앙으로 맞추는 경우 |
부동소수점
부동소수점 co-processor 있음
양자화 장단점
임베디드 장치에 심으려면 양자화 필수
양자화 인식 학습
실습
미니배치 782
- category cross entropy
- binary cross entropy의 loss 계산이 더 어렵다!
classification에서 이진분류/다중분류 중 다중분류가 더 어려운 거랑 헷갈려요
→ “loss 계산이 어렵다” 의미와 “문제가 어렵다” 의미가 다른 개념이라서 많이 혼동되는 부분 (계산 복잡도 vs. 학습 난이도)
동적 양자화
- 기본으로 weight만 양자화
- weight도 float32이기 때문
- 양자화 할 레이어 선택
정적 양자화
- 데이터 값까지 양자화
양자화 인식 학습
- QAT(Quantization Aware Training)
- 딥러닝 모델이 정수 연산 환경(INT8 등)에서 동작할 때 발생하는 양자화 오차(quantization error)를 훈련 단계에서 미리 보정하는 방법
- Post-Training Quantization(PTQ) 의 정확도 손실을 최소화하기 위해 고안된 학습 전략
프루닝(Pruning)
- 양자화 → 데이터 자체를 압축
- 프루닝 → 중요하지 않은 데이터 제거
- 특정 threshold 이하인 건 0.xxx값으로 있는 것보다 0으로 있는 게 계산상 나음
threshold = 0.01
if np.abs(w) < threshold:- generator
yield
- 지운다는 건 mask에 넣는다는 뜻임
- 영구적으로 적용하는 건 weight 자체에 실제로 넣는다는 것
- lottery ticket hypothesis
- 중요한 부분(우승 복권)만 찾고 나머지는 지우는 전략
- Pruning의 목적은 성능(속도, 메모리) 향상이며
정확도는 유지 또는 소폭 감소하는 것이 일반적인 결과- 하지만 실험적으로 일부 케이스에서는 정확도가 오히려 상승하기도 → why?
- 과적합(Overfitting) 완화
- 노이즈 필터 제거 효과
- 거대한 redundancy 제거
- 재학습 단계에서 fine-tuning 효과
- 주의: 반드시 올라가는 것은 아님
- 하지만 실험적으로 일부 케이스에서는 정확도가 오히려 상승하기도 → why?
미분 기반
- 그레디언트 사용
테일러 급수 기반
- 랜덤 가지치기 & re-growth 진행
동적 희소 학습
- 보통 pruning은 학습이 완료된 모델에게 적용 → 학습 중 동적으로 연결 추가/제거
모델 증류
- Teacher: 거대 모델
- Student → 출력 결과가 Teacher와 유사해지도록
- 확률과 확률을 비교하는 K Divergence Loss tkdyd
- 부모의 확률 분포를 자식이 따라가게
순환 신경망(RNN)
p.607
- 확률론에 근거
- 과거 단어를 알면 미래 단어 예측 가능
- feed-forward와 비교
- 과거 단어 부분이 추가됨 → weight가 두 개
- sigmoid 대신 tanh 사용
- repeat의 미분 → sum → 적당한 단계에서 잘라주기
- 역전파의 연경을 적당한 지점에서 끊음(보통 10) → tanh의 미분값 유지되는 정도까지만
- 자연어 처리는 미니배치 넣는 게 어려움
- 배치: 문장 개수 * 한 문장 속 단어 개수
RNN 계층 구현
- (V, D)
- 단어 수(vocabulary)
- 차원 수(Demention)
- 임베딩 벡터 학습이 핵심
- 동의어, 반의어 등을 수치로 나타냄
- Embedging Projector
- 주성분추출(PCA)
- h: 은닉 상태 벡터의 차원
- 행 리피트
- 의존 관계 기억하기
- 핵심은 미분
- 시간펼침층
- 임베딩도 '선택적 연산'임
- forward: repeat, backward: sum
- ★p.660★ → 같은 단어에 대해서 sum
LSTM
- p.681
- 20개 넘어가는 긴 문장은 RNN으로 학습 X
- tanh은 최대가 10번
- 문제는 행렬의 곱과 tanh
- 핼렬의 곱 weight는 하나 → 한 개로 계속 곱하면 증폭/소실
- p.685
- 핼렬의 곱 weight는 하나 → 한 개로 계속 곱하면 증폭/소실
- 기울기 폭발은 clipping으로 대처 가능 → 하지만 0이 된 건 어떻게 할 수 없음 → RNN의 태생적 한계
LSTM→ "기억 셀"- tanh, weight 곱셈 타지 않음!
- 아다마르 곱만 있음
- 게이트 이해하기
- weight 4개 → 다 학습해야 하나? → 실제 코드 보면 한 번에 처리함: 행렬곱 특성 이용
- slicing layer
- weight 4개 → 다 학습해야 하나? → 실제 코드 보면 한 번에 처리함: 행렬곱 특성 이용
- x도 repeat (총 4회 들어가니까)
- 4번의 repeat의 미분 sum까지 반영됨(p.706)
Seq2seq
(p.731)
- start of sentence/end of sentence
- 시간의 흐름이 4개라면 5개로 해야 함(eos까지 출력되어야 해서)
- pre-pedding
- peeky
객체 지향의 원칙: OCP
- 객체지향 프로그래밍의 5대 원칙(SOLID) 중 둘째 원칙으로 “확장에는 열려 있고, 수정에는 닫혀 있어야 한다” 를 의미
- 확장에 개방(Open for Extension):
새로운 기능을 추가하거나 기존 기능을 확장할 수 있어야 한다. - 수정에 폐쇄(Closed for Modification):
기존의 코드는 변경하지 않아야 한다.
- 확장에 개방(Open for Extension):
- LSTM은 x만 들어가게 설계되어 있는데 h가 필요하다고 입력값을 2개로 늘리는 건 원칙에 위배됨
- 입력값을 늘리지 않고 h 쓰는 방법: weight 고치기!
- (N, D+H)(D+H,H) → concat 노드 사용
- Affine의 경우:
- (N,H+H)(H+H,V) → 열로 합치기!
- 입력값을 늘리지 않고 h 쓰는 방법: weight 고치기!
어텐션
(p.775)
- seq2seq의 문제점
- 은닉 정보(h, 고정 길이의 벡터) 크기가 너무 작음
- p.780
- 어텐션 개념 (p.786 - )
- 내적을 통해 비슷한 벡터 파악('나'와 'I'가 비슷하다는 지표)
- query-key
- 병렬처리 불가(시계열 기반이라)
트랜스포머
- p.827
ONNX
- keras-PyTorch 호환을 위해
- ONNX 자체도 최적화가 잘 되어 있어 개선 목적으로 쓰는 경우도 많음
★★★ The C Programing Language
Chapter 1 언어 소개(A Tutorial Introduction)
Chapter 2 형, 연산자, 수식(Types, Operators, and Expressions)
Chapter 3 제어 흐름(Control Flow)
Chapter 4 함수와 프로그램 구조(Functions and Programm Structure)
Chapter 5 포인터와 배열(Pointers and Arrays)
Chapter 6 구조체(Structures)
Chapter 7 입력과 출력(Input and Output)
Chapter 8 UNIX 시스템과의 인터페이스(The UNIX System Interface)
Appendix A 참조 매뉴얼
Appendix B 표준 라이브러리
Appendix C 개선점 요약
찾아보기
CPU FLAG REGISTER
레지스터(register)는 컴퓨터 중앙처리장치(CPU) 내부에 존재하는 고속의 임시 저장 공간
레지스터는 CPU 내에 있으며 프로세서가 작업을 효율적으로 처리할 수 있도록 데이터, 주소, 명령 등 다양한 정보를 임시로 보관하는 매우 빠른 기억 장치임
- 역할과 특징
- CPU가 연산을 하거나 데이터를 처리할 때 필요로 하는 값을 매우 빠른 속도로 저장하고 불러오는 데 사용
- 메모리(RAM)보다 훨씬 적은 용량이지만, CPU와 직접 연결되어 있어서 데이터 접근 속도가 가장 빠름
- 산술 연산, 데이터 이동, 주소 지정, 명령 실행 흐름 제어 등 다양한 용도로 사용 → 프로그램 실행 효율을 크게 높임
- 종류 예시
- 범용 레지스터: 데이터 연산·저장 등 다목적으로 사용
- 프로그램 카운터(PC): 다음에 실행할 명령의 메모리 주소 저장
- 명령어 레지스터(IR): 현재 실행 중인 명령어 보관
- 상태/플래그 레지스터: 연산 결과 상태(오버플로우 등) 저장
- 플래그 레지스터(flag register)
- 중앙처리장치(CPU) 내부에 존재하는 상태 레지스터(status register)
- 산술·논리 연산의 결과나 CPU의 현재 상태를 나타내는 여러 개의 비트(flag bit)로 구성
- 역할
- 연산 결과에 따라 자동으로 설정됨
- 프로그램 흐름 제어나 조건 분기, 디버깅 등에 사용
- 특히 조건문(if, loop 등) 실행할 때 CPU가 특정 플래그 비트를 검사하여 다음 명령어 실행 여부를 결정함
CPU 플래그 레지스터는 연산 결과와 CPU 상태를 표현하는 핵심 제어 수단으로, 하드웨어적으로 자동 설정되어 프로그램의 흐름 제어 및 디버깅에 활용된다.
- 동작 이해하기: Flag Register
- carry flag
- overflow flag
- sign flag
- zero flag
zero flag
- 두 숫자가 같냐/다르냐 확인
a=3, b=3
a-b
if a == 3:| CF | OF | SF | ZF |
|---|---|---|---|
| 1 |
ZF==1이면 a와 b는 같다.
carry flag
- unsigned의 대소 비교
- 정상적인 뺄셈이라면 0
unsigned char a=5;
unsigned char b=2;
if a < b: // cmp a,b → a-b → 5-2
…- 위 예제는 unsigned라서 진짜 뺄셈을 해야 함
- 이전에 배운 2의 보수 개념 x
| 2 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | ||
| - | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
▽
| CF | OF | SF | ZF |
|---|---|---|---|
| 0 | 0 |
CF==0이면 a가 b보다 크다!
unsigned char a=2;
unsigned char b=5;
if a < b: // cmp a,b → a-b → 2-5
…| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |
| - | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
▽
- unsigned라서 이대로는 연산이 안 됨 → 최상위 bit에서 빌려왔다고 가정하기: carry flag가 1!
- 연산 결과 보지 않고 플래그만 확인해도 크기 비교 가능
| 2 | 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | ||
| - | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 |
▽
| CF | OF | SF | ZF |
|---|---|---|---|
| 1 | 0 |
carry flag가 1이면 a가 b보다 작다!
| CF | OF | SF | ZF |
|---|---|---|---|
| 1 | 0 |
sign flag
signed char a=5;
signed char b=2;
if a < b: // cmp a,b → a-b → 5+(-2)
…| s | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | |
| + | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
▽
| CF | OF | SF | ZF |
|---|---|---|---|
| 1 | 0 | 0 | 0 |
SF == 0(=OF의 값)이면 a가 b보다 크다 → SF==OF이면 a가 b보다 크다!
signed char a=2;
signed char b=5;
if a < b: // cmp a,b → a-b → 2+(-5)
…| s | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |
| + | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 |
▽
| CF | OF | SF | ZF |
|---|---|---|---|
| 1 | 0 | 1 | 0 |
SF != 0(=OF의 값)이면 a가 b보다 작다 → SF != OF면 a가 b보다 작다!
| CF | OF | SF | ZF |
|---|---|---|---|
overflow flag
signed char a=100;
signed char b=-100;
if a < b: // cmp a,b → a-b → 100-(-100)
…| s | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | |
| + | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
→ overflow 발생!
| CF | OF | SF | ZF |
|---|---|---|---|
| 0 | 1 | 1 | 0 |
SF==OF 이면 a가 b보다 크다.
signed char a=-100;
signed char b=100;
if a < b: // cmp a,b → a-b → -100+(-100)
…| 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | |
| + | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 |
→ overflow 발생!
| CF | OF | SF | ZF |
|---|---|---|---|
| 1 | 1 | 0 | 0 |
SF!=OF 이면 a가 b보다 크다.
주요 플래그 비트 종류
| 플래그 이름 | 기능 설명 |
|---|---|
| CF (Carry Flag) | 덧셈 시 자리올림 또는 뺄셈 시 자리내림이 발생하면 1로 설정됨 |
| PF (Parity Flag) | 결과의 1인 비트 개수가 짝수면 1, 홀수면 0 |
| AF (Auxiliary/Adjust Flag) | 하위 4비트에서 자리올림이 발생하면 1로 설정됨 (BCD 연산에 사용) |
| ZF (Zero Flag) | 연산 결과가 0이면 1로 설정됨 |
| SF (Sign Flag) | 결과가 음수면 1, 양수면 0 (결과의 최상위 비트와 동일) |
| OF (Overflow Flag) | 부호 있는 연산에서 오버플로우가 발생하면 1로 설정됨 |
| DF (Direction Flag) | 문자열 처리 시 주소 증가/감소 방향 제어 (0=증가, 1=감소) |
| IF (Interrupt Flag) | 외부 인터럽트를 허용(1) 또는 차단(0) |
| TF (Trap Flag) | 디버깅용 플래그로, 1이면 명령어 단위로 인터럽트 발생 |
- 아키텍처별 명칭
- 16비트 CPU: FLAGS 레지스터 (예: 8086)
- 32비트 CPU: EFLAGS 레지스터
- 64비트 CPU: RFLAGS 레지스터
함수 호출 규약(Calling Convention)
- 함수 호출 시 인자 전달, 반환값 처리, 스택 정리 방식 등 함수 호출에 관련된 다양한 저수준 규칙을 정의한 약속
- 보통 코드에서 명시하지 않아도 됨
- OS/컴파일러/CPU에 따라 기본값이 다를 수 있음
- 시스템 해킹/저수준 디버깅, 라이브러리 개발 시에는 호출 규약 차이가 버그 원인이 될 수 있으니 유의
- 함수 호출 규약의 핵심 요소
- 인자 전달 방식: 함수에 인자를 어떻게 넘길지
- 예: 스택이나 레지스터 사용
- 인자 전달 순서: 인자를 왼쪽에서 오른쪽, 또는 반대로 전달하는 순서
- 스택 프레임 정리: 함수 호출 이후 누가(호출자caller/피호출자callee) 스택을 정리하는지
- 반환값 처리: 반환값을 어떤 레지스터나 메모리 위치에 저장할지
- 인자 전달 방식: 함수에 인자를 어떻게 넘길지
- 대표적인 함수 호출 규약
| 규약명 | 인자 전달방식 | 스택 정리 주체 | 특징 |
|---|---|---|---|
| cdecl | 스택(오른→왼) | 호출자(caller) | C언어 기본, 가변인자 지원 |
| stdcall | 스택(오른→왼) | 피호출자(callee) | WinAPI 주로 사용 |
| fastcall | 레지스터+스택 | 피호출자(callee) | 일부 인자 레지스터 사용 |
| thiscall | 레지스터+스택 | 피호출자(callee) | C++ 클래스 멤버함수 |
| x64 System V | 레지스터+스택 | 호출자(caller) | 리눅스 64bit 규약 |
| MS x64 | 레지스터+스택 | 호출자(caller) | 윈도우 64bit 규약 |
- 아키텍처별 차이
- x86(32비트): 스택 위주, 레지스터 사용 제한적
- x86-64(64비트): 인자 여러 개는 레지스터에 전달 후, 남는 인자만 스택 이용. 운영체제와 컴파일러마다 적용 규약이 다름
- ARM: 별도 표준(AAPCS) 채택
- 용도와 중요성
- 함수 호출 규약은 소스 코드 간, 라이브러리, 혹은 언어 및 아키텍처가 다를 때 상호 운용성과 올바른 실행을 보장
- 직접 어셈블리로 코딩하거나 크로스 언어/플랫폼 시스템 개발 시 필수로 이해해야 함
- 컴파일러가 대부분 적합한 호출 규약을 자동 적용
- ABI(Application Binary Interface)의 중요한 부분
Caller와 Callee는 함수 호출 관계에서의 두 주체를 구분하는 개념으로, 호출 규약(Calling Convention)의 핵심 요소
스택 프레임 관리, 레지스터 보존, 반환 경로 설정 등 함수 호출의 정합성을 유지하는 핵심 구조
- Caller
- 다른 함수를 호출하는 함수
- 호출을 준비하고 결과를 받는 주체
- 호출 시 인자를 스택 또는 레지스터에 넣고, 필요한 경우 caller-saved 레지스터를 저장해야 함
- 호출 후에는 callee가 반환한 결과를 지정된 레지스터(보통 RAX 또는 EAX)에서 읽음
- 호출이 끝난 뒤 스택을 정리해야 하는 규약(cdecl 등)에서는 caller가 스택을 복원
- Callee
- 호출된 함수, 즉 실행되는 함수
- 호출되어 작업을 수행한 뒤 결과를 반환하는 주체
- 호출되면 자신의 스택 프레임을 구성하고, 지역 변수나 임시 데이터를 저장할 공간을 확보
- 연산 결과는 일정한 규칙에 따라 반환 레지스터(예: RAX)에 저장
- callee-saved 레지스터의 경우, 함수 실행 중 값을 변경했다면 반환 전에 반드시 원래대로 복원해야 함
- 실행이 끝난 뒤
ret명령으로 caller에게 제어를 반환
| 구분 | 책임 주체 | 예시(x86-64 Linux) | 설명 |
|---|---|---|---|
| Caller-saved | Caller | RAX, RCX, RDX, R8–R11 | 함수 호출 시 변동 가능. 필요 시 caller가 직접 백업 필요 |
| Callee-saved | Callee | RBX, RBP, R12–R15 | 함수 내에서 사용 가능하되, 변경 시 반드시 원래 값 복원 |
예시: a.c
a.c코드 작성- 리눅스에서
gcc a.c로 실행 파일을 만듦- 코드가 컴파일되어
a.out같은 실행 파일이 됨 - 실행 파일 이름을 원하는 대로 지정하려면
gcc -o myfile a.c처럼-o옵션을 사용
- 코드가 컴파일되어
- 실행:
./a.out./는 "현재 디렉토리"를 의미하고, 뒤의a.out은 그 디렉토리에 있는 실행 파일을 실행하라는 뜻
- 리눅스에서
- objdump로
a.out파일을 분석할 수 있음
#include <stdio.h>
void foo()
{
printf("foo()\n");
}
int main()
{
foo(); // call foo
}컴파일이란 "사람이 작성한 소스코드(C, C++, Java 등 고급 언어)"를 컴퓨터가 직접 실행 가능한 "기계어(실행 파일, .exe, .out 등)"로 변환하는 과정입니다.
- 컴파일 과정 4단계
- 전처리(Preprocessing) : #include, #define 등의 지시문을 처리하고, 헤더 파일 삽입, 주석 제거, 매크로 치환 작업을 합니다. 결과는 .i 파일에 저장됩니다.
- 컴파일(Compilation) : 전처리된 코드를 어셈블리어(.s)로 변환합니다. 문법 검사와 의미 분석이 이루어지며, 오류를 체크합니다.
- 어셈블(Assembly) : 어셈블리어 파일을 목적 파일(.o)로 변환합니다. 이는 CPU가 이해할 수 있는 명령어 집합으로 작성된 기계어.
- 링킹(Linking) : 목적 파일(.o)과 필요한 라이브러리 파일을 합쳐서 하나의 실행 파일(.exe, .out 등)로 만듭니다.
- 핵심 의미
- 사람이 쓴 코드를 컴퓨터가 실행할 수 있는 형태로 만드는 과정이 바로 컴파일입니다.
- C컴파일러(gcc), C++컴파일러(g++), 자바컴파일러(javac) 등 여러 종류가 있으며, 각 언어별로 조금씩 과정이 다릅니다.
- 컴파일이 끝나면, 컴퓨터는 소스코드가 아닌 실행 파일을 직접 읽어서 동작합니다.
- objdump
- C로 작성한 프로그램이 실제로 컴파일되어 어떻게 "바이너리(기계어)"로 변환되는지 내부 구조와 동작 방식을 보여주기 위한 명령
- 리눅스에서 바이너리 파일(컴파일된 실행 파일이나 오브젝트 파일)의 내부를 분석·출력해주는 도구
- 주로 기계어, 섹션 헤더, 심볼 테이블, 파일 헤더 등 소스코드에서는 볼 수 없는 “실행 파일 수준”의 자세한 정보를 보여줌
- 주요 옵션 및 역할
objdump -d a.out: 실행 파일의 “실행 가능한 코드 부분”을 어셈블리(기계어에 가까운 명령어)로 보여줘 foo, main 같은 함수가 실제 어떤 명령어로 구현되어 있나 볼 수 있음objdump -h a.out: 바이너리 내 각 “section”(코드, 데이터, 심볼 등)의 크기와 위치 정보를 보여줌objdump -x a.out: 헤더·섹션 정보를 포괄적으로 보여줌objdump -s a.out: 바이너리 각 섹션의 원본 “hex”(16진수) 데이터를 보여줌
소스코드만 보면 추상적인 함수 호출이, 실제로는 call, ret와 같은 명령의 연속, 주소점프(JMP) 등으로 상세하게 작동함을 볼 수 있습니다
출력 결과를 깊이 이해하면, 컴파일러 동작, 최적화, 시스템 내부 원리, 보안 분석, 디버깅 등에 큰 도움이 됩니다.
- 상수 폴딩(constant folding): 상수만 있을 때 미리 계산해서 저장
- 컴파일러의 대표적인 최적화 기법
- 코드에 있는 상수끼리의 계산을 컴파일 시간에 미리 처리해서, 실행 파일에는 이미 계산된 결과만 남기도록 해주는 것
- “상수만 있는 연산”을 미리 계산해서 코드에서 제거하는 것과 같음(컴파일러가 코드의 상수끼리 연산을 미리 계산해서 결과값으로 바꾸는 것)
- 예:
int x = 2 + 3 * 4;→ 실행파일에는 x = 14;로만 저장됨. 실제 계산 명령은 없음.
- 죽은 코드 제거(Dead Code Elimination): 실행에 필요 없는 코드를 아예 제거
- 실행 흐름상 절대 도달하지 않는 코드, 변수에 영향을 주지 않는 코드, 필요없는 임시 변수 등 “실행 결과에 영향을 주지 않는 코드”를 컴파일 과정에서 아예 삭제
- 의미없는 코드는 컴파일 과정에서 지워짐
#include <stdio.h>
void foo()
{
printf("foo()\n");
}
int main()
{
foo; // foo → 1149
}- 함수 이름은 argument(인자, 매개변수)와 반환형 사이에 위치
- 다시 말해, 함수의 기본 구조는 아래처럼 정의됨
반환형 함수이름(매개변수) {
// 함수 몸체
return 반환값;
}- 반환형: 함수가 실행 후 돌려주는 값의 데이터 타입 (예: int, float, void 등)
- 함수이름: 함수의 이름이며, 매개변수와 반환형 사이에 위치
- 매개변수(argument): 함수에 전달되는 입력값, 함수이름 뒤 괄호 안에 위치.
- return: 함수가 work(연산 등)를 끝내고 호출한 곳으로 값을 돌려줌, 함수 몸체 안에서 사용.
int sum(int a, int b) {
return a + b;
}→ sum이 함수 이름이고, int a, int b가 argument, int가 return type
#include <stdio.h>
void foo()
{
printf("foo()\n");
}
// *p++ : 전치와 후치가 만나면 후치부터 묶는다
// (*p)++로 써야 원하는 방식으로 작동함
int main()
{
void (*a)() = foo; // foo → 1149
a();
}gcc, g++
gcc와 g++는 모두 GNU에서 제공하는 컴파일러이지만, "지원하는 언어"와 "링킹 방식"에 주요 차이가 있음
- 핵심 차이점
- gcc: "C 언어"를 기본적으로 지원하며, .c 파일은 C로, .cpp 파일은 C++로 각각 컴파일
- C 코드 컴파일에 최적화되어 있고, 기본적으로 C 라이브러리만 링크합니다. C++ 라이브러리는 자동적으로 링크되지 않음
- g++: "C++ 전용" 컴파일러로 .c와 .cpp 파일을 모두 C++ 언어로 컴파일하며, C++ 표준 라이브러리까지 자동으로 링크
- 실질적 의미
- C 코드, .c 파일: gcc 사용이 기본이며, g++도 가능하나 내부적으로 C++ 방식으로 처리됨
- C++ 코드, .cpp 파일: g++ 사용이 안정적이며 권장됨. gcc로 컴파일 시 C++ 라이브러리 미링크로 인해 에러가 날 수 있음
제어의 흐름을 어셈블리 구조로 이해하기
- program counter register(PC)
- 다음에 실행할 명령어의 번지수
# if 1
#include <stdio.h>
void foo()
{
printf("foo()\n");
}
int main()
{
foo();
}
# endif
# if 0
#include <stdio.h>
void foo()
{
printf("foo()\n");
}
int main()
{
foo; // 함수 이름만 쓰면, "함수의 주소"—즉, 함수 코드가 시작하는 메모리 위치—를 의미
}
# endif
- 함수 이름 자체가 "코드 섹션의 주소"
- foo라고 쓰면 함수의 시작 주소가 “값”이 되어서, 주소를 출력하거나 함수 포인터로 쓸 수 있음
- 함수 이름을 함수 포인터로 쓸 때에도 별도의 & 연산자가 필요없으며, 이 점은 배열과도 비슷
- C 언어의 “조건부 컴파일(conditional compilation)”
#if,#endif,#if 0,#if 1은 “전처리기(preprocessor)”가 어떤 코드 블록을 컴파일할지 선택하는 역할- 특정 코드 블록을 쉽게 “켜고 끄는” 용도
- 목적
- 디버그용 코드와 실제 배포용 코드를 구분:
#if DEBUG - 운영체제나 플랫폼에 따라 다른 코드를 넣을 때:
#if defined(WINDOWS) - 특정 기능을 켜거나 끌 때 (#define으로 연결 가능):
#define USE_LOG 1#if USE_LOG
- 디버그용 코드와 실제 배포용 코드를 구분:
jmp가 call로 바뀐 이유는 프로그램의 제어 흐름을 함수 호출 방식으로 변경하기 위해서입니다. jmp는 단순히 프로그램의 위치를 무조건 이동시키는 반면, call은 함수를 호출하고 실행이 끝난 후 원래 위치로 돌아갈 수 있도록 복귀 주소(Return IP)를 스택에 저장한 후 함수로 점프합니다. 따라서 call은 함수 실행 후 원래 코드로 복귀해야 할 경우에 사용됩니다.
| PC |
|---|
| 1170 |
0000000000001149 <foo>:
1149: endbr64
114d: push %rbp
114e: mov %rsp,%rbp
1151: lea 0xeac(%rip),%rax # 2004 <_IO_stdin_used+0x4>
1158: mov %rax,%rdi
115b: call 1050 <puts@plt>
1160: nop
1161: pop %rbp
1162: ret
0000000000001163 <main>:
1163: endbr64
1167: push %rbp
1168: mov %rsp,%rbp
116b: mov $0x0,%eax
🡆 1170: call 1149 <foo>
1175: mov $0x0,%eax
117a: pop %rbp
117b: ret
| PC |
|---|
| 1149 |
- call이 없던 시절을 생각해보자
0000000000001149 <foo>:
1149: endbr64
114d: push %rbp
114e: mov %rsp,%rbp
1151: lea 0xeac(%rip),%rax # 2004 <_IO_stdin_used+0x4>
1158: mov %rax,%rdi
115b: call 1050 <puts@plt>
1160: nop
1161: pop %rbp
1162: jmp 1175
0000000000001163 <main>:
1163: endbr64
1167: push %rbp
1168: mov %rsp,%rbp
116b: mov $0x0,%eax
1170: jmp 1149 <foo>
1175: jmp 1149 <foo>
117a: pop %rbp
117b: jmp→ jump 쓰면 loop가 됨
- 해결하려면:
- 돌아올 위치를 정해주자 (단, 돌아올 위치는 변할 수 있어야 함) → eax 레지스터에 값 넣어두기
- BUT 이것만으로는 함수 내부에서 함수를 호출하는 경우 대응할 수 없음: 함수 내부에서 loop 생김
- stack 이용: %rsp와 push, pop %eax → trace
- rsp: stack 가리키는 포인터
- push: stack으로 값 넣기
- pop: stack에서 빼서 register에 넣어줌
- 돌아올 위치를 정해주자 (단, 돌아올 위치는 변할 수 있어야 함) → eax 레지스터에 값 넣어두기
| eax |
|---|
| 1175 |
| PC |
| 1149 |
0000000000001149 <foo>:
1149: endbr64
114d: push %rbp
114e: mov %rsp,%rbp
1151: lea 0xeac(%rip),%rax # 2004 <_IO_stdin_used+0x4>
1158: mov %rax,%rdi
115b: call 1050 <puts@plt>
1160: nop
1161: pop %rbp
1162: jmp %eax
0000000000001163 <main>:
1163: endbr64
1167: push %rbp
1168: mov %rsp,%rbp
116b: mov $0x0,%eax
1170: jmp 1149 <foo>
1175: jmp 1149 <foo>
117a: pop %rbp
117b: jmpeax 레지스터는 x86 CPU에서 가장 중요한 범용 레지스터 중 하나로, 주로 산술 연산(더하기, 빼기, 곱하기, 나누기 등)의 결과를 저장하거나 함수의 반환값을 담는 데 사용
CPU가 “즉시 접근”하고 “초고속으로 데이터 처리”할 수 있는 공간이 바로 EAX 같은 레지스터
프로그램 내부 어셈블리에서는 함수 반환, 계산 결과, 중간값 저장 등 다양한 목적으로 활용
- 크기: 32비트(4바이트)
- 하위 16비트는 AX, 그 아래는 AL/AH로 구분 가능
- x86-64에서는 RAX로 확장되어 64비트
- 하지만 32비트 프로그램에서는 EAX로 사용
- 용도
- 산술·논리 연산에 최적화되어 있어서, 연산 결과가 자동으로 EAX에 저장되는 경우가 많음
- 함수 실행 후 반환값을 전달하거나, 시스템 호출 같은 특수 연산에서도 결과값을 담는 컨벤션에 이용
mov eax, 5 // EAX에 5 저장 add eax, 3 // EAX에 3 더함 (결과: 8) ret // 함수 반환 시 EAX에 반환값 들어있음실제로 C에서 int 함수 반환 → eax에 값 저장
def bar():
pass
def foo():
bar()
foo()| eax |
|---|
| 1175 |
| PC |
| 1149 |
rsp 위치를 잘 따라가보자
- 스택은 위에서 아래 방향(주소가 낮아지는 쪽)으로 쌓여감
- 86-64 아키텍처에서 스택은 “낮은 주소 방향으로 자라며” rsp는 항상 스택의 최상단(top)을 가리킴
- rsp가 맨 위에 있는 위치로 이동했다는 것은 함수 프롤로그에서 보통 16바이트만큼 감소(sub rsp, 16)가 발생해서, 그 만큼 더 낮은 주소를 가리키고 있다는 의미
+-------+
| rsp | # rsp(Stack Pointer): 현재 1175를 가리킴
+-------+
| 1175 | # main에서 push됨 (리턴 주소 등)
+-------+
| 1160 | # foo에서 push됨
+-------+
| . | # 아직 사용되지 않은, 혹은 이후 추가될 공간
+-------+
| . |
+-------+
| . |
+-------+
| . |
+-------+
| . |
+-------+
- register는 16개 정도만 쓸 수 있음 → 스택이 필요하다!
- push-jmp, pop-jmp 반복되는 걸 쉽게 쓰기 위해 call과 ret (return address 줄임말) 사용
인자 넣기
- stack
- call 하기 전에 인자 먼저 쌓아야 함! (push-call 순)
- argument와 지역변수 구분 필수
- 지역변수가 있을 때 대처하기 위해
rpb사용- 지역변수의 최하단에 고정되어 있음
- 참고하면 좋을 내용
jmp 명령과 call 명령
| 명령어 | 기능 | 특징 |
|---|---|---|
| jmp | 지정한 주소로 단순히 점프 | 되돌아올 주소를 저장하지 않음 → 복귀 불가능 |
| call | 함수 또는 서브루틴을 호출 | 복귀할 주소를스택에 push후 점프 →ret명령으로 복귀 가능 |
- jmp somewhere는 “그냥 그리로 간다”이지만 call somewhere는 “그리로 가기 전에 지금 있던 위치를 저장하고 갔다가 되돌아온다”는 차이가 있음
- jmp만으로 제어할 때
- 복귀 불가능성 (Return Address 부재)
- jmp 명령은 현재 위치를 저장하지 않기 때문에 점프한 후 원래 코드의 다음 위치로 돌아올 방법이 없음
- 서브루틴 호출 후 복귀가 불가능해져 프로그램 흐름이 깨집니다.
- 중첩 호출 문제 (Nested Calls 불가능)
- 여러 함수가 서로 호출되면, “어디서 어디로 돌아와야 하는지”를 기억해야 하지만 jmp에는 이를 추적할 공간이 없음
- 전역 변수를 사용해 임시로 저장할 수도 없고, 함수 중첩(call stack 구조) 표현도 불가능
- 복귀 불가능성 (Return Address 부재)
jmp만으로는 “돌아올 길이 없는 흐름 제어” 문제를 해결할 수 없기 때문에, CPU는 스택을 사용해 복귀 주소를 저장하는 call/ret 체계를 도입 → 현대적인 함수 호출, 스택 프레임, 재귀 함수 호출 등의 기반 마련
스택과 스택 프레임의 역할
- 함수가 호출될 때 스택에는 다음 정보가 차례로 저장
- 복귀 주소 (Return Address) — call 명령에 의해 자동으로 push 됨
- 이전 함수의 프레임 포인터 (EBP/RBP) — 현재 함수의 기준 주소를 만들기 위해 이전 포인터를 저장
- 함수의 지역 변수 및 매개 변수 — 함수 실행 중에 임시로 필요한 값
- 이렇게 형성된 메모리 블록이 스택 프레임(stack frame)
- 함수가 끝날 때 ret 명령은 스택의 top에 있는 복귀 주소를 pop해서 CPU의 명령 포인터(EIP/RIP)에 복구함으로써 정확히 원래 위치로 복귀
레지스터만으로 전달이 한계인 이유
- 초기엔 함수 인자나 지역 데이터를 레지스터만으로 주고받는 fastcall 방식이 쓰였지만, 다음과 같은 한계가 존재:
- 레지스터 개수가 한정적이라 모든 인자나 변수를 저장할 수 없음
- 레지스터를 덮어쓰면 이전 값이 사라지므로 함수 중첩 시 백업(push/pop)이 필요.
- 레지스터에 데이터를 넣기 위해 오히려 stack을 써야 하는 모순 발생
- 이 때문에 인자와 복귀 정보를 전부 스택에 push하는 규약(calling convention)이 정착됨
스택 포인터 vs. 프레임 포인터
| 레지스터 | 역할 |
|---|---|
| SP (Stack Pointer) | 현재 스택의 최상단 위치를 가리킴. push/pop으로 값이 변함 |
| BP/FP (Base Pointer / Frame Pointer) | 현재 함수의 스택 프레임 시작점을 가리킴. 지역변수와 매개변수를 참조할 기준점으로 사용됨 |
- 스택 + call + ret 구조가 만들어져야 프로그램이 안전하게 중첩 호출, 지역변수 사용, 재귀 호출 가능
- call func → 복귀 주소를 스택에 push하고, SP 감소
- 새 함수 실행 → EBP를 push하고 SP를 복제해 새 프레임 기준 설정
- 함수 종료(leave, ret) → SP와 EBP를 복원, 복귀 주소를 pop
- CPU는 원래 위치로 돌아감
