filtering
- 정제 작업
- 시각의 확장/Paradigm shift 필요
- logic을 많이 동원해야 하는 단계
import os
import re
from re import findall
try:
t3 = open('data/tx_000.txt', mode='r', encoding='UTF8')
t3_txt = t3.read()
name = findall('[가-힣]{1,}',t3_txt) # (1)
print('이름 name ->',name)
print()
date = (findall('[0-9]{1,}',t3_txt)) # (2)
print('입사일자8자리 date ->',date)
print()
_6date = []
for i in range(len(date)): # (3)
_6date.append(date[i][2::])
print('입사일자6자리 _6date ->',_6date)
print()
print('하이픈(-)제거 t3_txt ->',findall('[^-]+',t3_txt)) # (4) 서비스 코드
print()
ls = []
for i in range(10):
ls.append(name[i] + "-" + _6date[i]) # (5)
print('최종결과 ls ->',ls)
print()
except Exception as e:
print('Error 발생 :',e)
finally:
t3.close()(1) 이름 분리
- t3_txt에서 한글인 것만 가져와서 name 리스트를 만듦
- 간헐적으로 이름 앞에 붙어있는 알파벳 문자를 지우는 효과
- 실제로 노이즈가 첨가된 열(컬럼, 필드)가 많음
- 간헐적으로 이름 앞에 붙어있는 알파벳 문자를 지우는 효과
(2) 입사 일자 분리
- t3_txt에서 숫자인 것만 가져와서 date 리스트를 만듦
(3) 6자리 형식으로 수정
- 직전에 만든 date리스트에 요소들을 차례로 꺼내서 8자리로 구성된 년월일 정보를 6 글자로 줄이는 효과
- '가공'에 더 가까움
- 처리를 효율적으로 하기 위함
(4) 서비스 코드
- t3_txt에서 하이픈을 지우는 효과
(5)
- 이전에서 만든 두 개의 리스트를 결합하여 ls리스트를 만듦
import pandas as pd
import re
from re import findall, match, sub
try :
txt1 = open('data/test00_00.txt', mode= 'r', encoding = 'UTF8')
txt2 = txt1.readlines()
post = [ i[0:7] for i in txt2] # (1)
txt_addr = [ i[7:] for i in txt2] # (2)
txt3 = [re.sub('[$%!^?+\n]','', i) for i in txt_addr] # (3)
addr = [re.sub('\t',' ', i) for i in txt3] # (4)
df = pd.DataFrame({
'우편번호': post,
'주소': addr
}) # (5)
print(df)
except Exception as e :
print("오류 발생 : ",e)
finally :
txt1.close()(1) 우편번호를 추출함
(2) 주소를 추출함
(3) 주소 안의 특수문자를 제거함
(4) 주소 안의 \t 를 제거함
(5) 데이터프레임을 생성함
tabulate 라이브러리
- Python Pandas : Tabulate, DataFrame을 가독성 좋게 print하기
- DataFrame을 terminal에서 더 가독성 좋게(이쁘게) 출력하는 방법
- DataFrame의 출력 양식을 표 형식으로 출력하도록 도와줌
import pandas as pd
import re
from re import findall, match, sub
try :
txt1 = open('data/test00_00.txt', mode= 'r', encoding = 'UTF8')
txt2 = txt1.readlines()
post = [ i[0:7] for i in txt2]
txt_addr = [ i[7:] for i in txt2]
txt3 = [re.sub('[$%!^?+\n]','', i) for i in txt_addr]
addr = [re.sub('\t',' ', i) for i in txt3]
df = pd.DataFrame({
'우편번호': post,
'주소': addr
})
pd.set_option("colheader_justify", "left") # (1)
print(tabulate(df, headers='keys', tablefmt='psql', showindex=True, stralign='center')) # (2)
print(tabulate(df, headers='keys', tablefmt='psql', showindex=True, stralign='left')) # (3)
print(tabulate(df, headers='keys', showindex=True, stralign='left')) # (4)
except Exception as e :
print("오류 발생 : ",e)
finally :
txt1.close()(1) 데이터 프레임의 컬럼 해더를 우측으로 자리맞추기
(2)
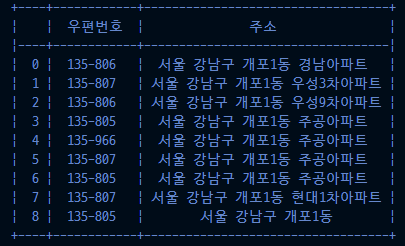
(3)

(4)
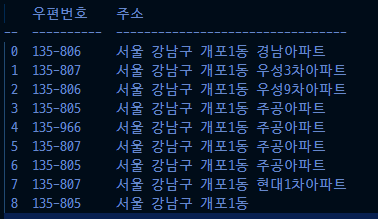
from re import match
flag1, flag2, flag3 = False, False, False # (1)
jumin = '123456-3234567'
# jumin = '123456-323456700'
print('jumin-->',jumin)
if len(jumin[0:]) > 14 : # (2)
flag1 = False
else:
flag1 = True
print('flag1',flag1)
jj=[]
jj = jumin.split('-')
if len(jj[0]) == 6 : # (3)
flag2 = True
else:
flag2 = False
print('flag2',flag2)
if len(jj[1]) == 7 : # (4)
flag3 = True
else:
flag3 = False
if flag1 and flag2 and flag3: # (5)
print('주민번호 길이 정상 ')
result = match('[0-9]{6}-[1-4][0-9]{6}', jumin)
if result :
print('=====')
print('result',result)
print('=====')
print('정상인 주민번호')
else :
print('=====')
print('result',result)
print('=====')
print('잘못된 주민번호')
else :
print('****주민번호 길이 비정상 ')(1) 필터(filter) → 길이 오류 필터링
- '다층 검사 방식'
- flag1 : 주민번호 전체자릿수 유효/무효 필터 선언(True, False)
- flag2 : 주민번호 앞 6자리 유효/무효 필터 선언(True, False)
- flag3 : 주민번호 뒷 7자리 유효/무효 필터 선언(True, False)
(2) 주민번호의 모든 자릿수를 필터링
(3) 주민번호 앞 6자리 길이를 필터링
(4) 주민번호 뒷 7자리의 길이를 필터링
(5) 3종류 필터링 결과를 종합하여 판단함
정규표현식
^(?:[0-9]{2}(?:0[1-9]|1[0-2])(?:0[1-9]|[1,2][0-9]|3[0,1]))-[1-4][0-9]{6}$
- 유효성 검사: 주민등록번호
- 주민등록번호 13자리 중 출생 월, 일을 나타내는 3~6번째 자리 숫자와 성별을 나타내는 7번째 자리를 유효한 숫자 범위로 제한하여 최소한의 잘못된 주민등록번호 숫자 판별
- 앞의 여섯 자리 중 각 두자리는 출생 연, 월, 일을 나타내며 생년월일이라 함
- 생년월일 중 연도는 모든 숫자가 될 수 있으나 유효 월은 1~12월 유효 일은 1~31일로 범위가 제한됨
- 뒤의 일곱 자리 중 맨 앞의 숫자는 성별을 나타냄
- 출생연도가 20~21세기(1900~2000년대)인 내국인은 1~4, 외국인은 5~8 범위 안의 숫자를 갖게 되며, 19세기에 등록된 내국인은 9와 0의 숫자를 갖게됨
- 예컨대, 정규식으로 1900년대 이후 출생한 내국인의 주민등록번호만 유효한 것으로 일치되게 허용하려면 해결책의 정규식처럼 1~4 범위로 제한하면 됨
- 뒤의 일곱자리 중 성별 뒤의 4자리 숫자는 출생지를 나타내는 지역번호
- 0001~9999 사이의 번호가 부여됨
- 지역번호 뒤의 한 자리는 해당 출생지에서의 접수 순번
- 마지막 한자리 숫자는 검증 번호
- 즉, 성별 뒤 6자리 숫자는 각각 0~9 범위의 수가 될 수 있음
\b(?:[0-9]{2}(?:0[1-9]|1[0-2])(?:0[1-9]|[1,2][0-9]|3[0,1]))-[1-4][0-9]{6}\b
- 문서나 더 긴 입력 문자열에 들어있는 주민등록번호를 검색하려면 ^ 과 $ 앵커 대신에 단어 경계를 (
\b)를 사용- 정규식 엔진은 모든 영수 문자와 언더바를 단어 문자로 간주
정규식 연습
/: 시작 기호01([0|1|6|7|8|9])([0-9]{3,4})([0-9]{4}): 조합하여 사용할 패턴/: 종료 기호i: 패턴변경자
예시 1
"hacker"라는 문자열을 포함한 아이디를 가진 이메일 주소를 정규식으로 잡아내기
(단, 이메일의 아이디는 영문 소문자+숫자로만 이루어진다.)
\d*(hacker)\d*[@]([a-z]+\.)+(com|net|kr)
\d*(hacker)\d*: hacker라는 문자열 앞뒤에 정수 숫자가 올 수 있음[@]: 이메일 형식에 반드시 '@'를 포함([a-z]+\.): 영문 소문자에.을 포함(com|net|kr): 마지막 자리는 com or net or kr로 끝남
예시 2
/^[0-9a-zA-Z]([-_.]?[0-9a-zA-Z])*@[0-9a-zA-Z]([-_.]?[0-9a-zA-Z])*\.[a-zA-Z]{2,3}$/i
^ / $ : 입력 시작과 종료
[0-9a-zA-Z] : 숫자, 영어소문자, 영어대문자로 시작
([-_.]?[0-9a-zA-Z])*- [-_.]? : '-_.' 특수문자는 없거나 하나만 포함 가능
[0-9a-zA-Z]) : 숫자, 영어 소문자, 영어 대문자가 있거나 없거나, 여러 개 가능
*@: 무조건 골뱅이 포함.[a-zA-Z]{2,3}:.다음에 영어 소문자와 영어 대문자가 2개 or 3개 가능/i: 대소문자 구분 X
주민번호
예시 1
입력값이 유효한 주민번호인지 검사한다.
주민번호 생년월일중 월은 당연히 1~12, 일은 1~31 값이 들어올 수 있다.
주민번호 뒷자리의 첫글자는 1~4만 가능하고
앞/뒷자리를 구분하는 하이픈(-)은 있을 수도, 없을 수도 있다.
\d{2}([0]\d|[1][0-2])([0][1-9]|[1-2]\d|[3][0-1])[-]*[1-4]\d{6}
\d{2}: 맨 앞 정수 2자리(생년)는 어떤 정수값이 와도 상관없음([0]\d|[1][0-2]): 첫 자리가 0인 경우는 뒤에 어떤 정수가 와도 괜찮고 첫 자리가 1인 경우 뒷자리는 0,1,2만 올 수 있ㅇ음 (01-12 생월을 표현)([0][1-9]|[1-2]\d|[3][0-1]): 생일은 첫자리가 0이면 뒷자리가 0이 될 경우 0일이 되기 때문에 0 다음에는 1-9만 올 수 있음
-[-]*: 하이픈은 0개 or 1개[1-4]: 주민번호 뒷자리 첫 번째 숫자는 1~4만\d{6}: 주민번호 첫 자리를 제외한 숫자는 총 6자리
예시 2
/^d{2}([0]\d|[1][0-2])([0][1-9]|[1-2]\d|[3][0-1])[-]*[1-4]\d{6}$/
d{2}: 앞 2자리는 어떤 정수값이 와도 상관없음([0]\d|[1][0-2]): 첫 자리가 0인 경우는 뒤에 어떤 정수도 상관없음 or 첫자리가 1인경우 뒷자리는 0, 1, 2만 가능([0][1-9]|[1-2]\d|[3][0-1]): 생일은 첫자리가 0이면 1~9까지, 첫자리가 1~2이면 어떤 정수도 상관 없음, 첫자리가 3일 경우엔 0과 1만 가능[-]*: 하이픈은 0개 or 1개[1-4]: 주민번호 뒷자리 첫번째 숫자는 1~4만 가능\d{6}: 주민번호 첫자리를 제외한 숫자는 총 6자리
핸드폰 번호
하이픈 무관
/^01([0|1|6|7|8|9])-?([0-9]{3,4})-?([0-9]{4})$/
^ / $: 입력 시작과 종료-?: - 은 있어도 되고 없어도 됨01([0|1|6|7|8|9]): 01 다음에 오는 숫자는 0, 1, 6, 7, 8, 9 중 하나여야 함([0-9]{3,4}): 그 다음에 들어갈 수 있는 숫자는 0부터 9사이 숫자들이며 3자리 or 4자리 가능([0-9]{4}): 다음 숫자는 0부터 9 사이의 숫자들이 들어갈 수 있고 4자리여야 함
하이픈 입력 없을 때
/^01([0|1|6|7|8|9])([0-9]{3,4})([0-9]{4})$/
생년월일
8자리(YYYYMMDD)
/^(19[0-9][0-9]|20\d{2})(0[0-9]|1[0-2])(0[1-9]|[1-2][0-9]|3[0-1])$/
^ / $: 입력 시작과 종료(19[0-9][0-9]|20\d{2}): 년도- 앞자리가 19라면 다음에 오는 숫자 두 자리는 0~9 중 하나여야 함 or 앞자리가 20이라면 뒤의 두자리는 어떤 정수 값이 와도 상관 없음
(0[0-9]|1[0-2]): (월) 앞자리가 0이면 뒤는 0~9까지 or 앞자리가 1이면 뒤는 1~2까지의 숫자가 와야함(0[1-9]|[1-2][0-9]|3[0-1]): (일) 앞자리가 0이면 뒤는 0~9까지 or 앞자리가 1~2 사이 숫자이면 뒤는 0~9까지 or 앞자리가 3이면 0~1까지의 숫자가 들어가야 함
6자리(YYMMDD)
/^([0-9]{2}(0[1-9]|1[0-2])(0[1-9]|[1,2][0-9]|3[0,1]))$/
