R 데이터 구조
행렬
- 2차원 구조를 가진 벡터
- 행렬에 저장된 모든 데이터는 같은 타입이어야 함
행렬의 선언
- 명령어 matrix를 사용
- ncol을 사용하여 열(column)의 수를 정하거나 nrow를 사용하여 행(row)의 수를 정할 수 있음
- matrix를 사용하여 행렬을 만들 경우 행렬의 값들이 열로 저장되는 것을 확인할 수 있음
- 만약 byrow 옵션에 T(TRUE)를 지정하면 값들이 열이 아닌 행으로 저장됨
> mx = matrix(c(1:6), ncol=2)
> mx
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> mx2 = matrix(c(1:6), nrow=2, byrow=T)
> mx2
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
- 벡터에 차원을 주는 방법
- dim 함수를 사용하면 행의 개수와 열의 개수를 지정하여 벡터를 행렬로 변환할 수 있음
> a1 = c(1:6)
> a1
[1] 1 2 3 4 5 6
> dim(a1) = c(2,3)
> a1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
- 명령어 rbind와 cbind를 사용하여 이미 만들어진 벡터를 행렬로 합치기
- rbind의 ‘r’은 ‘row’를 의미
- 기존의 행렬에 행을 추가하는 형태로 데이터를 결합
- cbind의 ‘c’는 ‘column’을 의미
- 기존의 행렬에 열을 추가하는 형태로 데이터를 결합
> a2 = matrix(c(1:6), ncol=2)
> a2
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> r1 = c(10, 10)
> c1 = c(20, 20, 20)
> rbind(a2, r1)
[,1] [,2]
1 4
2 5
3 6
r1 10 10
> cbind(a2, c1)
c1
[1,] 1 4 20
[2,] 2 5 20
[3,] 3 6 20
배열과 리스트
배열
- 3차원 이상의 구조를 갖는 벡터
- 배열 또한 벡터의 성질을 가지고 있으므로 하나의 배열에 포함된 데이터는 모두 같은 타입이어야 함
- array를 사용하여 배열을 만들 수는 있지만 몇 차원의 구조를 갖는지 dim 옵션에 명시해 줘야 함
(명시하지 않을 경우 1차원 벡터가 생성됨)
> b1 = array( c(1:12) , dim = c(2, 3, 2) )
> b1
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
리스트
- 데이터 타입, 데이터 구조에 상관없이 사용자가 원하는 모든 것을 저장할 수 있는 자료구조
- 여러 자료형의 원소들이 포함될 수 있는 이질적인 특징을 가지고 있음
- 각각의 원소가 인덱스를 가짐: L[[3]] 는 L 리스트의 3번째 원소
- 리스트의 원소들은 이름을 가질 수 있음: L[[”red”]]과 L$red는 둘 다 ‘red’라는 이름의 원소를 지칭
> L = list()
> L[[1]]=5
> L[[2]]=c(1:6)
> L[[3]]=matrix(c(1:6),nrow=2)
> L[[4]]=array(c(1:12),dim=c(2,3,2))
> L
[[1]]
[1] 5
[[2]]
[1] 1 2 3 4 5 6
[[3]]
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
[[4]]
, , 1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
, , 2
[,1] [,2] [,3]
[1,] 7 9 11
[2,] 8 10 12
🡆 list()를 사용해서 list를 담을 변수를 선언하고 첫 번째 성분으로 숫자형 데이터를, 두 번째 성분으로 벡터를, 세 번째 성분으로 행렬을, 네 번째 성분으로 배열을 담은 뒤 리스트를 출력한 결과
데이터 프레임(df)
- 행렬과 유사한 2차원 목록 데이터 구조
- 다루기 쉽고 한 번에 많은 정보를 담을 수 있어 R에서 가장 많이 활용되는 데이터 구조
- 행렬과는 다르게 각 열이 서로 다른 데이터 타입을 가질 수 있기 때문에 데이터의 크기가 커져도 다루기 수월
- 명령어 data.frame을 이용하면 여러 개의 벡터를 하나의 데이터 프레임으로 합쳐 입력할 수 있음
> d1 = c(1:5) # 숫자가 저장된 벡터
> d2 = c('red','yellow','blue','purple','pink') # 문자가 저장된 벡터
> df = data.frame(d1,d2)
> df
d1 d2
1 1 red
2 2 yellow
3 3 blue
4 4 purple
5 5 pink
R 기본 문법
연산자
대입 연산자
| 대입 연산자 | 설명 |
|---|
| <-, <<-, = | 오른쪽 값을 왼쪽에 대입 |
| ->, ->> | 왼쪽 값을 오른쪽에 대입 |
> a <- 'abc'
> "adsp" -> b
> number1 <<- 10
> Inf ->> d
> logical = NA
비교 연산자
| 비교 연산자 | 설명 |
|---|
| == | 두 값이 같은지 비교 |
| != | 두 값이 다른지를 비교 |
| < , > | 초과, 미만을 비교 |
| < = , = > | 이상, 이하를 비교 |
| is.character | 문자형인지 아닌지를 비교 |
| is.numeric | 숫자형인지 아닌지를 비교 |
| is.logical | 논리형인지 아닌지를 비교 |
| is.na | NA인지 아닌지를 비교 |
| is.null | NULL인지 아닌지를 비교 |
> a == 'abc'
[1] TRUE
> a != 'abcdefg'
[1] TRUE
> b > 'adsp'
[1] FALSE
> number1 <= 20
[1] TRUE
> is.na(logical)
[1] TRUE
> is.null(NULL)
[1] TRUE
산술 연산자
| 산술 연산자 | 설명 |
|---|
| + | 두 숫자의 덧셈 |
| (*문자끼리 덧셈 : ‘A’ + ‘B’) |
| - | 두 숫자의 뺄셈 |
| * | 두 숫자의 곱셈 |
| / | 두 숫자의 나눗셈 (소수점까지 표현) |
| %/% | 두 숫자의 나눗셈의 몫 |
| %% | 두 숫자의 나눗셈의 나머지(modulo) |
| ^ , ** | 거듭제곱 |
| exp( ) | 자연상수의 거듭제곱 |
> 7+3
[1] 10
> 7-3
[1] 4
> 7*3
[1] 21
> 7/3
[1] 2.333333
> 7%/%3
[1] 2
> 7%%3
[1] 1
# 만약 벡터의 길이가 동일하지 않은 경우, 원소가 많은 쪽이 기준이 된다
x = c(1, 2, 3)
y = c(1, 2, 3, 4, 5, 6)
x + y
# 2, 4, 6, 5, 7, 9
# 원소가 많은 y가 기준이 되어 x가 2번 반복되어 길이를 맞추게 됨 (1, 2, 3, 1, 2, 3)
기타 연산자
| 기타 연산자 | 설명 |
|---|
| ! | 부정 연산자 : 현재의 논리값에 반대되는 값 |
| & | AND 연산자 : 두 값이 모두 참일 때만 참 |
| |
> !TRUE
[1] FALSE
> TRUE&TRUE
[1] TRUE
> TRUE&FALSE
[1] FALSE
> !(TRUE&FALSE)
[1] TRUE
> TRUE|FALSE
[1] TRUE
R 내장 함수
기본 함수
| 함수 | 설명 |
|---|
| help ( ) 또는 ? | 함수들의 도움말 확인 |
| paste ( ) | 문자열 이어 붙이기 |
| seq ( ) | 시작값, 끝값, 간격으로 수열 생성 |
| rep ( ) | 주어진 데이터를 일정 횟수만큼 반복 |
| rm ( ) | 대입 연산자에 의해 생성된 변수 삭제 |
| ls ( ) | 현재 생성된 변수들의 리스트 확인 |
| print ( ) | 해당 값을 콘솔창에 출력 |
> help (paste)
> ?paste
> paste('banana','juice')
[1] "banana juice"
> seq(1,16,2)
[1] 1 3 5 7 9 11 13 15
> rep(1,6)[1] 1 1 1 1 1 1
> a <- 1
> a[1] 1
> rm(a)
> aError: object 'a' not found
> ls()
[1] "b" "d" "logical" "number1"
> print(5)
[1] 5
통계 함수
| 함수 | 설명 |
|---|
| sum | 값의 합 |
| mean | 값의 평균 |
| median | 값의 중앙값 |
| var | 값의 표본 분산 |
| sd | 값의 표본 표준편차 |
| summary | 값의 요약값 |
| range | 값의 최솟값과 최댓값 |
> vector1 <- c(1:9)
> sum(vector1)
[1] 45
> mean(vector1)
[1] 5
> median(vector1)
[1] 5
> var(vector1)
[1] 7.5
> sd(vector1)
[1] 2.738613
> summary(vector1)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1 3 5 5 7 9
> range(vector1)
[1] 1 9
R 데이터 핸들링
벡터형 변수
> a = c("a","b","c","d")
> a
[1] "a" "b" "c" "d"
- 벡터 뒤에 대괄호 [ ]를 붙여 숫자를 지정해주면 a 벡터 내에서 n번째 원소에 해당하는 값을 불러옴
> a [2]
[1] "b"
- a[-n]처럼 대괄호 안에 -를 붙이고 숫자를 지정해 주면 n번째 원소에서 해당하는 값만 제외하고 a 벡터를 불러옴
> a[-4]
[1] "a" "b" "c"
- c 명령어를 사용하여 원소값이 있는 위치를 나열할 경우 여러 개의 원소를 불러옴
> a[c(2,3)] #벡터의 2, 3번째 위치 값을 선택한다
[1] "b" "c"
데이터 이름 변경
- colnames와 rownames 함수를 사용하여 행과 열의 이름을 확인하고 지정
> v1 <- matrix(c(1:6),nrow=2)
> colnames(v1) <- c('a1','a2','a3')
> rownames(v1) <- c('b1','b2')
> v1
a1 a2 a3
b1 1 3 5
b2 2 4 6
데이터 추출/결합 응용
- [ , ] 기호를 사용하여 원하는 위치의 데이터를 구할 수 있고 행과 열의 이름으로도 데이터를 얻을 수 있음
> v2 <- matrix(c(1:6),nrow=3)
> v2[3,2]
[1] 6
> colnames(v2) <- c('c1','c2')
> v2[,'c1']
[1] 1 2 3
> rownames(v2) <- c('r1','r2','r3')
> v2['r3','c2']
[1] 6
- 행렬과 행렬, 데이터프레임과 데이터프레임의 경우 행의 수 혹은 열의 수가 같을 경우 결합 가능
- 하지만 벡터와 벡터의 결합에서는 재사용 규칙으로 인하여 부족한 데이터를 재활용하여 사용하며 결과를 반환
> r1 <- c(1,2,3)
> r2 <- c(4,5,6,7,8)
> rbind(r1,r2)
[,1] [,2] [,3] [,4] [,5]
r1 1 2 3 1 2
r2 4 5 6 7 8
Warning message:
In rbind(r1, r2) :
number of columns of result is not a multiple of vector length (arg 1)
제어문
반복문
for 반복문
- 괄호 안의 조건 하에서 1값을 하나씩 증가시켜가며 중괄호 { } 안의 구문을 반복 실행
> e = c() #아무런 값도 포함되지 않는 벡터 선언
> for (i in 1:9) {
+ e[i] = i * i
+ }
> e
[1] 1 4 9 16 25 36 49 64 81
- 괄호의 조건 (1 in 1:9)는 11 구문 안의 1 변수가 1:9, 즉 (1, 2, 3, 4, 5, 6, 7, 8, 9)의 값을 순서대로 하나씩 가지며 반복된다는 것을 의미
while 반복문
- 괄호 안의 조건 하에서 중괄호 { } 안의 구문을 반복
- for 구문과 다르게 While 구문은 괄호 안의 조건이 만족되어 있는 동안 중괄호 안의 구문을 반복
- 따라서 for 구문은 선언과 동시에 몇 회 반복될지 처음부터 정해지는 반면 while 구문은 중괄호 안의 구문이 괄호 안의 조건을 만족하지 않을 때까지 반복되므로 몇 회 반복될지 미리 정해지지 않음
> f = 1
> while(f<5){
+ f=f+1
+ print(f)
+ }
[1] 2
[1] 3
[1] 4
[1] 5
조건문
- if ~ else 구문을 이용하면 if의 조건이 만족되지 않는 경우 else 이하의 조건을 이용해 또 다른 조건을 부여할 수 있음
# score 벡터에서 성분값이 70 이상인 경우만을 남겨 70이상인 값들만의 개수를 구하는 코드
> score = c(88, 90, 78, 84, 76, 68, 50, 48, 33, 70, 48,
66, 88, 96, 79, 65, 27, 88, 96, 33, 64, 48, 77, 18, 26, 44,
48, 68, 77, 64, 88, 95, 79, 88, 49, 30, 29, 10, 49, 88)
> over70 = rep (0, 40)
> for (i in 1:40) {
+ if (score[i] >= 70) {
+ over70[i] <- 1
+ } else {
+ over70[i] <- 0
+ }
+ }
> over70
[1] 1 1 1 1 1 0 0 0 0 1 0 0 1 1 1 0 0 1 1 0 0 0 1 0 0 0 0 0
[29] 1 0 1 1 1 1 0 0 0 0 0 1
> sum(over70)
[1] 18
사용자 정의 함수
- '함수 이름 = function (x, y, z)’의 형식으로 선언
- 괄호 안의 x, y, z는 함수 구문에서 인수(argument)로 사용
# 입력한 인수 a까지의 합을 계산해주는 함수 addto를 선언
> addto = function (a) {
+ isum=0
+ for (i in 1:a) {
+ isum=isum + i
+ }
+ print (isum)
+ }
> addto ( 100 )
[1] 5050
> addto ( 50 )
[1] 1275
그 외 유용한 기능들
substr
- 주어진 문자열에서 일부분을 추출하는 기능
- paste와는 반대
> substr("dataanylysis",2,8)
[1] "ataanyl"
cov
- 두 수치 벡터의 공분산을 구하는 기능
- 공분산(covariance)
- 두 변수 간의 관계를 나타내는 통계적 개념
- 두 변수의 평균값을 중심으로 퍼져 있는 평균적인 거리
- 변수가 함께 어떻게 변하는지를 측정
> height <- c(150, 160, 170, 180, 190)
> weight <- c(50, 60, 70, 80, 90)
> covariance <- cov(height, weight)
> cat("키와 몸무게 간의 공분산:", covariance, "\n")
키와 몸무게 간의 공분산: 250
*
cat : "concatenate"의 약어로, R에서는 하나 이상의 인자를 연결하여 출력하는 함수이다.
cat 함수는 화면에 문자열이나 값을 출력할 때 주로 사용된다.
✏️ 공분산(共分散, 영어: covariance)은 2개의 확률변수의 선형 관계를 나타내는 값이다. 만약 2개의 변수중 하나의 값이 상승하는 경향을 보일 때 다른 값도 상승하는 선형 상관성이 있다면 양수의 공분산을 가진다. 공분산은 두 개 또는 그 이상의 랜덤 변수에 대한 의존성을 의미한다.
= 공변량(공변량은 오차에서 나뉘어지는 변량으로 공변량이 유의하다면 오차 변량이 줄어들고 공변량의 변량은 증가된다.)
cor
- 두 수치 벡터의 상관계수를 구하는 기능
- 상관계수(correlation coefficient)
- 두 변수 사이의 통계적 관계를 표현하기 위해 특정한 상관 관계의 정도를 수치적으로 나타낸 계수
- 상관관계 분석에서 두 변수 간에 선형 관계의 정도를 수량화하는 측도
- 산점도에서 점들이 얼마나 직선에 가까운가의 정도를 나타내는데 쓰이는 측도
- 상관계수(r)는 -1에서 1사이의 값을 가지며 1에 가까울 수록 양의 관계가 강하고, -1에 가까울 수록 음의 관계가 강하며 0에 가까우면 아무런 관계가 없다는 것을 의미함
> x <- c(1, 2, 3, 4, 5)
> y <- c(2, 3, 5, 4, 6)
> correlation <- cor(x, y)
> cat("두 변수의 상관계수:", correlation, "\n")
두 변수의 상관계수: 0.9
날짜
Sys.Date ()
> Sys.Date( ) #현재 날짜를 출력한다
[1] "2023-11-10"
Sys.time ()
> Sys.time()
[1] "2023-11-10 00:17:05 KST"
as.Date ()
- 주어진 데이터를 날짜 형식으로 변환
- ‘2024-01-01’ 처럼 문자열 표현으로 된 날짜 데이터를 실제 날짜의 의미를 지니는 Date 객체로 변환하는 기능
> as.Date ("2024-01-01")
[1] "2024-01-01"
✏️ as.Date 라는 함수를 잘 쓰려면 문자열의 형식에 대해 먼저 알기 → SQL이랑 비슷함!
: as.Date는 기본 문자열이 yyyy-mm-dd 라고 가정한다면, 그 외의 다른 형식을 처리하려면 ‘format=’ 옵션을 통해 형식을 지정해 주어야 합니다. 예를 들어 mm/dd/yy 형태로 구성되어 있다면 ‘format=”%m/%d/%Y”’를 사용해야 합니다.
# %Y는 연도 네 자리, %y는 연도 두 자리, %m은 월, %d는 일, %A는 요일
format(Sys.Date(),'%Y/%m/%d')
[1] "2023/11/10"
자료형 데이터 구조 변환
as.data.frame ()
> names <- c("Alice", "Bob", "Charlie")
> ages <- c(25, 30, 22)
> data_frame_example <- as.data.frame(cbind(names, ages))
> print(data_frame_example)
names ages
1 Alice 25
2 Bob 30
3 Charlie 22
as.list ()
> numbers <- c(1, 2, 3)
> characters <- c("a", "b", "c")
> list_example <- as.list(c(numbers, characters))
> print(list_example)
[[1]]
[1] "1"
[[2]]
[1] "2"
[[3]]
[1] "3"
[[4]]
[1] "a"
[[5]]
[1] "b"
[[6]]
[1] "c"
as.matrix ()
> numbers <- c(1, 2, 3, 4)
> characters <- c("a", "b", "c", "d")
> matrix_example <- as.matrix(cbind(numbers, characters))
> print(matrix_example)
numbers characters
[1,] "1" "a"
[2,] "2" "b"
[3,] "3" "c"
[4,] "4" "d"
as.vector ()
> matrix_example <- matrix(1:6, nrow = 2)
> vector_example <- as.vector(matrix_example)
> print(vector_example)
[1] 1 2 3 4 5 6
as.factor ()
- 팩터 형식으로 변환
- 팩터(factor; 요인): 범주형 데이터를 표현하기 위한 데이터 타입
- 범주형 데이터: 통계학에서 데이터를 구분할 때 사용하는 개념
- 성별(남자와 여자), 직급(사원, 주임, 대리, 과장, 차장, 부장), 혈액형(A, B, O, AB)과 같이 사전에 정해진 몇 개의 범주(레벨값levels)로 분류되는 경우
> categories <- c("A", "B", "A", "C", "B", "C")
> factor_example <- as.factor(categories)
> print(factor_example)
[1] A B A C B C
Levels: A B C
as.numeric ()
> numeric_string <- c("1", "2", "3", "4", "5")
> numeric_example <- as.numeric(numeric_string)
> print(numeric_example)
[1] 1 2 3 4 5
as.character ()
- 숫자, 날짜, 논리값 등 다양한 데이터 타입을 문자열로 변환
> numeric_vector <- c(42, 27, 15)
> character_example <- as.character(numeric_vector)
> print(character_example)
[1] "42" "27" "15"
그래픽 기능
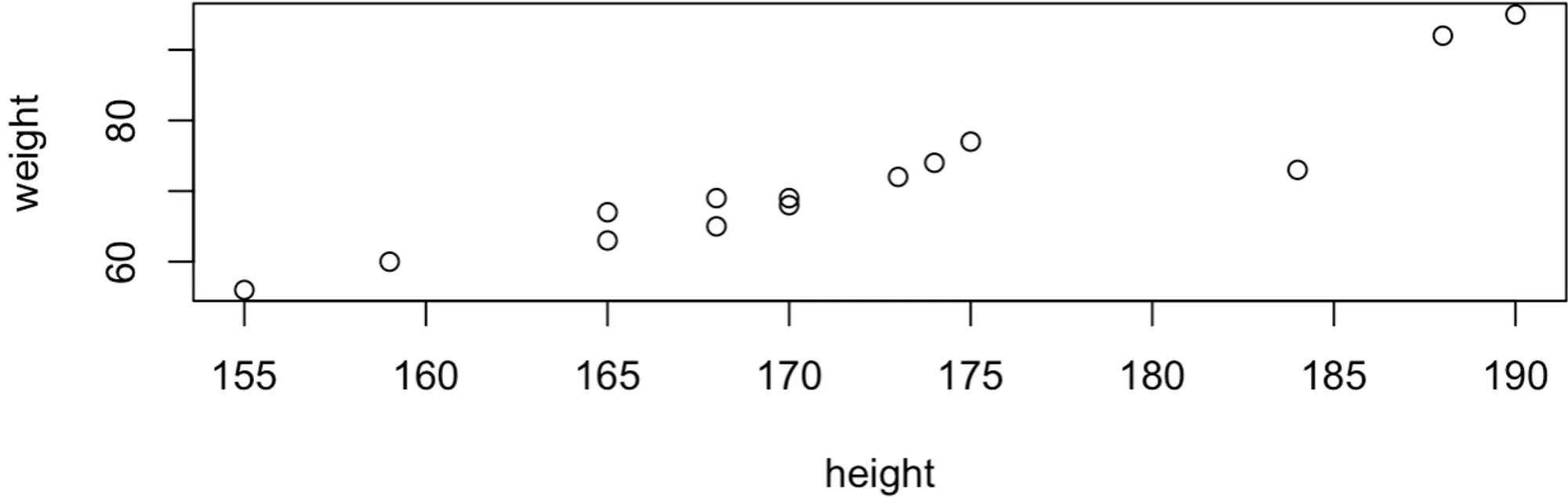
산점도 그래프
- 산점도: x변수와 y변수의 값을 한눈에 살펴볼 수 있도록 평면에 점을 찍어 표현한 것
- plot (x, y) 함수: x에 대한 y의 그래프를 그려주는 함수
# 키와 몸무게 데이터를 활용하여 산점도 그래프 명령문
> height = c(170,168,174,175,188,165,165,190,173,168,159,170,184,155)
> weight = c(68,65,74,77,92,63,67,95,72,69,60,69,73,56)
> plot(height, weight)
🡆 결과값
기출 문제 내용 정리
- 배열
- 하나의 배열에 포함된 데이터는 모두 같은 타입
- 몇 차원의 구조를 갖는지 dim 옵션에 명시
- array를 사용하여 배열 생성
- 리스트
- 리스트에 저장되는 모든 데이터는 서로 다른 형식의 데이터를 저장
- 데이터 프레임
- 각 열이 다른 타입을 가질 수 있음
- R에서 가장 많이 사용되는 데이터 구조
- 벡터에 결측값이 존재하는 경우 평균값을 계산할 수 없음
- %Y는 연도 네 자리, %y는 연도 두 자리, %m은 월, %d는 일, %A는 요일
