배울 내용
- 숫자를 맞추는 방법: 회귀 분석의 원리
- 범주를 맞추는 방법: 분류 분석의 원리
- 머신러닝 전체 프로세스
- 더 많은 머신러닝 모델
- 딥러닝의 원리
1. 머신러닝의 기초
학습목표
- 머신러닝에 대한 기본 이해
- 실습환경 구축
머신러닝의 기본 정의 및 역사
- 머신러닝에 대한 기본 개념 알아보기
머신러닝의 정의
머신러닝? 딥러닝?
- 머신러닝 이미지
- ChatGPT?
- 기계 학습? → 컴퓨터(기계)가 공부해서 나한테 뭔가 알려줌
- 데이터 추출? → 데이터에서 어떤 결과를 나타내서 이를 의사결정에 사용
→ 셋 다 맞는 말(공통된 특성을 가지기 때문)
→ 하지만 Case by case로 머신러닝을 이해하려면 어려운 부분이 있음(워낙 다양하기 때문)
🡆 용어를 먼저 익히고 용어 간 상하관계, 군집할 수 있는 것 무엇인지 파악해 전체적인 틀 익히기
머신러닝 관련 용어 정리
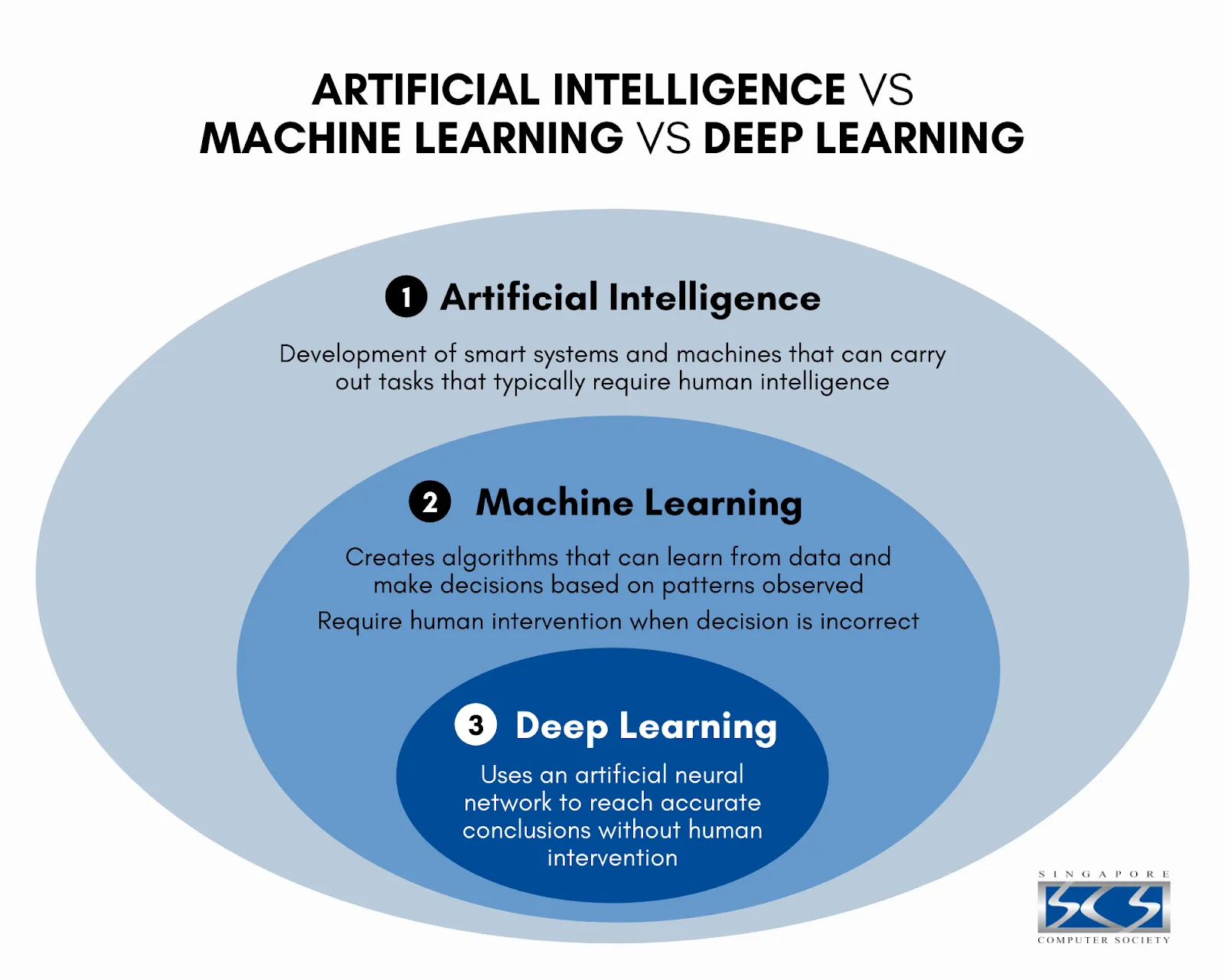
- AI ⊃ 머신러닝 ⊃ 딥러닝
- AI(Artificial Intelligence)
- 인간의 지능을 요구하는 업무를 수행하기 위한 시스템
: 사람이 일하다 실수(human error) 발생 → 업무를 단순화하여 기계(공장→hardware적인 것)에게 맡김 → HW만으로는 한계가 있음 → 지식 기반 업무를 SW(software)에게 맡기기
- 인간의 지능을 요구하는 업무를 수행하기 위한 시스템
- Machine Learning(머신 러닝; ML)
- 관측된 패턴을 기반으로 의사 결정을 하기 위한 알고리즘
: 관측된 패턴 → 추세, 상승, 하강 등 - 기술 통계 등을 통하여 집계된 정보로 의사결정을 했던 과거와 달리 데이터 수집과 처리 기술의 발전으로 대용량 데이터의 패턴을 인식하고 이를 바탕으로 예측, 분류하는 방법론
- 관측된 패턴을 기반으로 의사 결정을 하기 위한 알고리즘
- Deep Learning
- 인공신경망을 이용한 머신러닝
- 머신러닝의 하위 집합
- Data Science
- AI를 포괄하여 통계학과 컴퓨터 공학을 바탕으로 발전한 융합 학문
: "과학"이기 때문에 항상 '근거'와 '데이터'를 가지고 의사결정 진행
- AI를 포괄하여 통계학과 컴퓨터 공학을 바탕으로 발전한 융합 학문
- Data Analysis
- 데이터 집계, 통계 분석, 머신러닝을 포함한 행위
: 굉장히 포괄적인 용어
- 데이터 집계, 통계 분석, 머신러닝을 포함한 행위
- AI(Artificial Intelligence)
왜 머신러닝이 발전했을까?
- 인간은 데이터를 기반으로 한 의사결정을 내리고 싶어하기 때문!
인간 → 항상 (동일한) 실수를 함: 마음이 급함, 편향된 사고, 마음이 가는 데로 결정 등 → 이를 극복하고 싶어 함 → '통계'도 이런 이유로 발전함
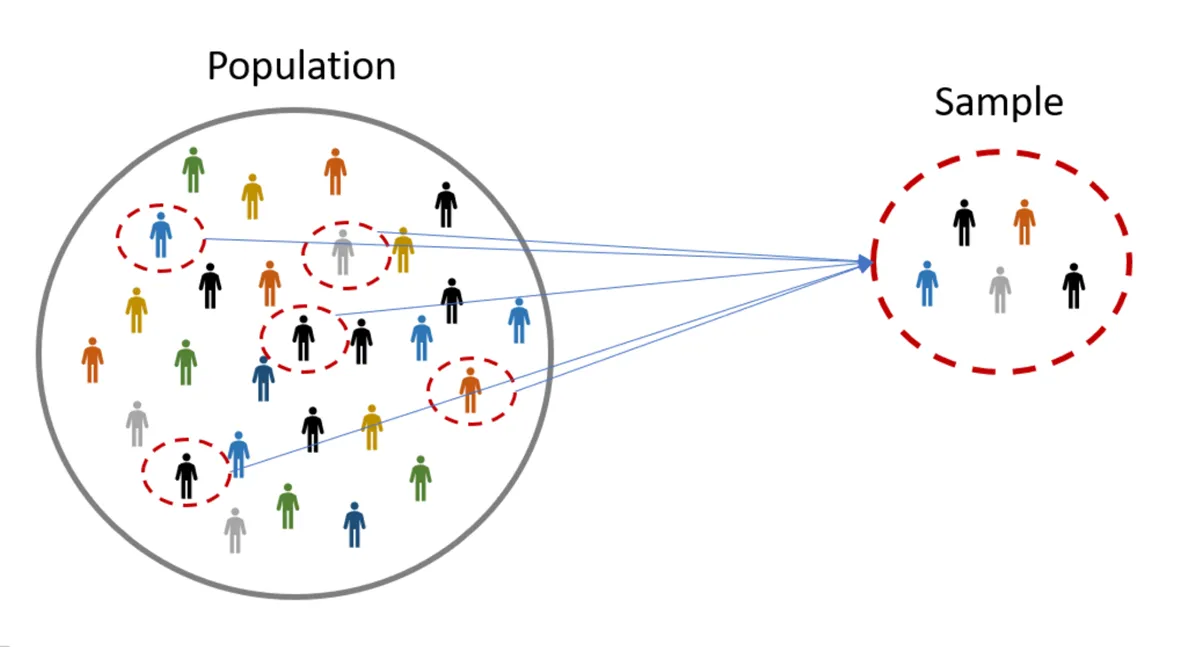
- 통계
- 모집단(전체 집단)의 성질을 표본집단으로부터 알기 위한 추론 방법
비용(돈&시간)의 한계 때문에 전체 모집단의 성질을 알 수 없음 → 표본을 뽑아 반대로 모집단의 성질을 알아 내기 위한 일련의 과정을 통해 통계학이 발전하게 됨
요즘은 왜 AI가 발달? → 데이터 처리 기술이 발달했기 때문!
- 데이터 처리 기술의 발전: 서비스
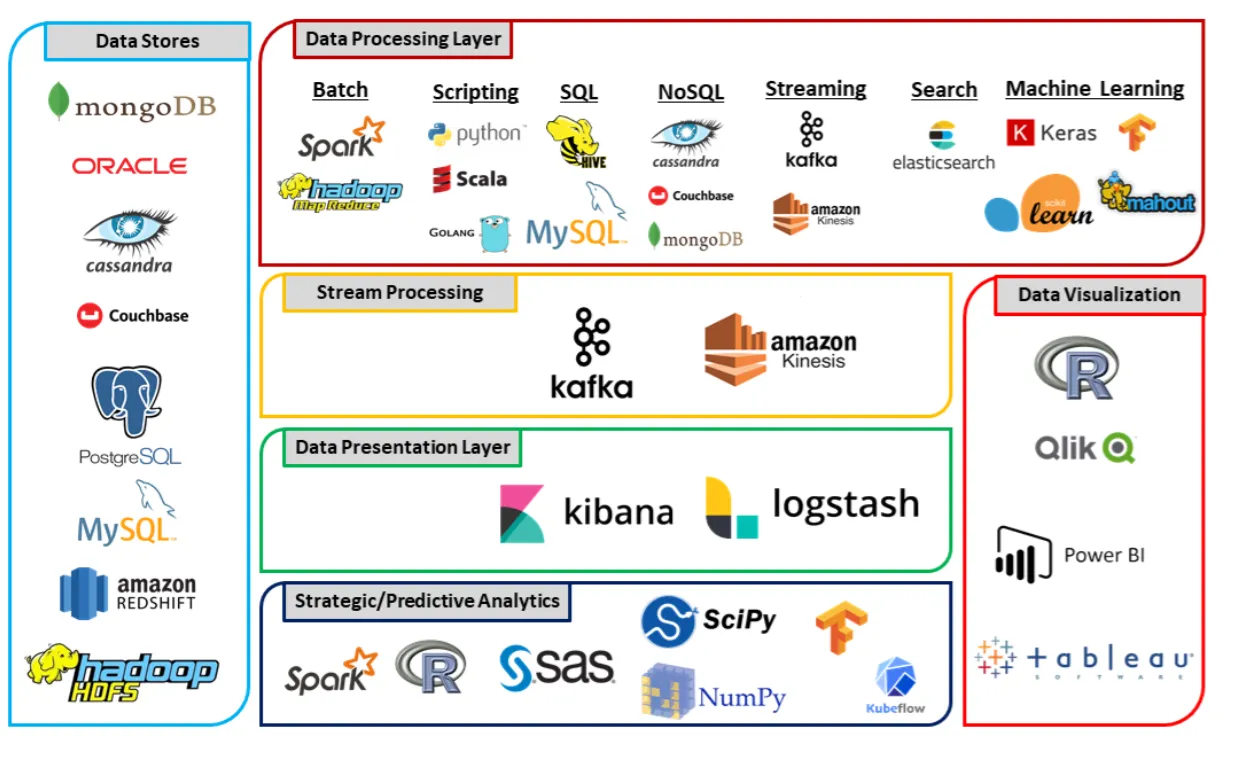
- 데이터 분석 관련 서비스
- 데이터 저장(파랑)
- 데이터 처리(빨강)
- 실시간 서비스(노랑) 등
- 데이터 분석 관련 서비스
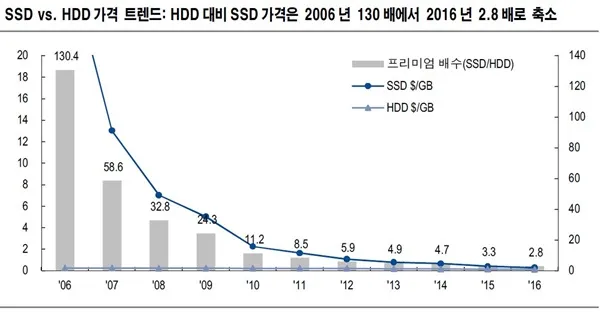
- 데이터 처리 기술의 발전 예시: 저장매체 가격의 하락
- AI 발달의 근본 원인 중 하나!
- 저장 공간 확보 → 방대한 양의 데이터 수집 가능 → 수집한 데이터 처리 가능 → ML/DL → 인사이트 도출
- AI 발달의 근본 원인 중 하나!
🡆 ML/DL 프로세스가 발전한 것은 데이터를 수집하기가 용이해졌기 때문!
- 머신러닝
- 전체 데이터에서 패턴을 파악하기 위한 방법
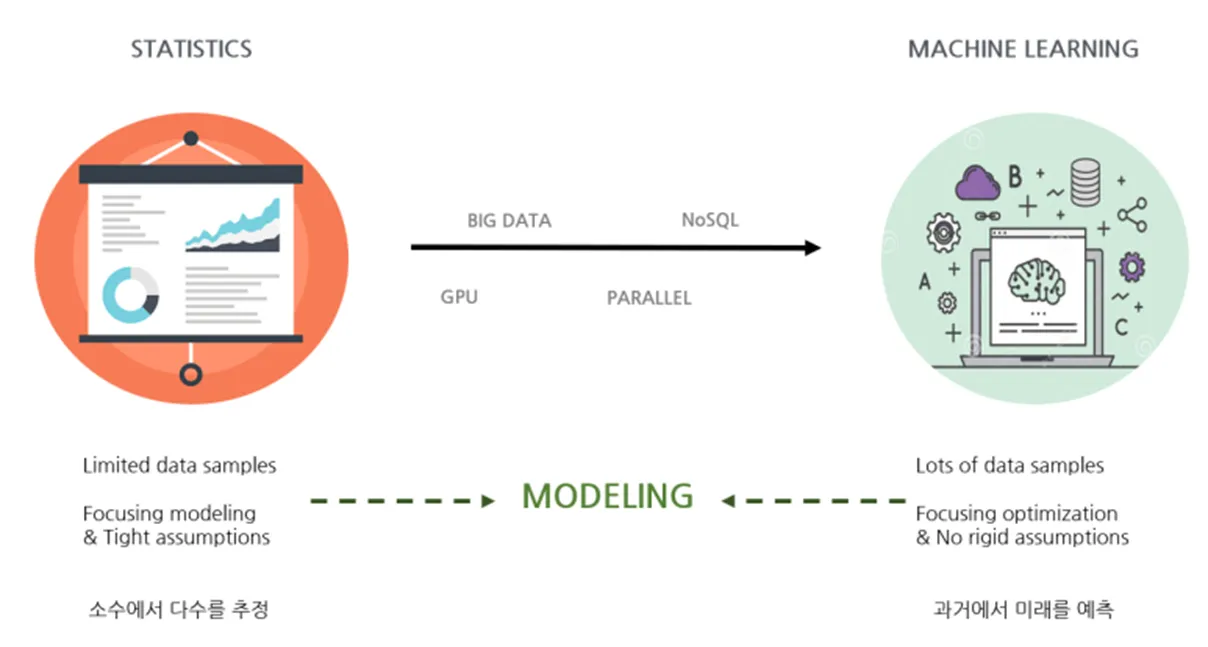
→ "통계학에서는 꼭 필요한 '가정' 없이 데이터를 싹 다 모아서 그걸로 패턴을 발견해 보자!"라는 것이 머신 러닝의 기조
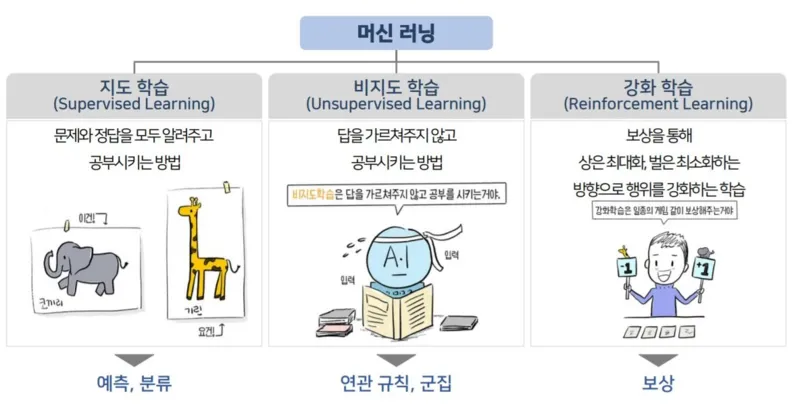
머신러닝 종류
- 지도 학습(Supervised Learning)
- 알려주고 학습
- 그림 데이터: RGB(256, 3) → 답: 코끼리
- 알려주고 학습
- 비지도 학습(Unsupervised Learning)
- (예) 군집, 연관 규칙(장바구니 분석→조건부 확률)
- 뭔가 하나가 틀리거나 맞았다는 건 아님 → 알아서 나누고 결과 판단만 사람이
- 강화 학습(Reinforcement Learning)
- 피드백을 통해 특정 행동 유도
머신러닝 적용 분야
ML
- 금융
- 신용평가, 사기탐지, 주식 예측
- 헬스케어
- 질병 예측, 환자 데이터 분석
- 이커머스
- 고객 구매 패턴 분석, 추천 시스템, 가격 최적화, 장바구니 분석
DL
- 자연어처리
- 번역, 챗봇, 텍스트분석
- 이미지 & 영상처리
- 얼굴인식(예: SNOW AI), 이미지 생성
- (예) 콜로라도 주립 박람회 대회 수상작: 스페이스 오페라극장
- Midjourney 사용
QnA
- 데이터 분석은 반드시 머신러닝을 해야 하나요?
- 데이터 분석은 데이터를 가지고 가치를 창출하는 포괄적인 행동입니다. 멋진 알고리즘과 복잡한 통계 지식이 없더라도 아니더라도 데이터 분석은 가능합니다.
- 그럼 머신러닝을 왜 배워야 하나요?
- 데이터 분석이라는 분야는 굉장히 다양합니다. 금융, 의료, 이커머스, 제조 등 어느 분야의 데이터 분석 직군으로 일하더라도 머신러닝을 활용한 업무와 밀접한 연관이 있기 때문에 전체 큰 그림을 볼 줄 알아야 합니다.
- 이 과목을 수강 하면 머신러닝 실무자가 될 수 있나요?
- 머신러닝을 포함한 데이터 사이언스의 학문은 특히나 깊이가 깊기 때문에, 통계학과 컴퓨터공학의 깊은 이해 없이 Data Scientist 가 될 순 없습니다. 머신러닝 실무자가 되기 위해서는 기반을 탄탄히 하는게 중요합니다.
머신러닝 실습 소프트웨어
- Visual Studio Code
- Microsoft가 제공하는 소스 코드 에디터
- Python 외에도 R, C, Java등 현존하는 대부분 프로그래밍 언어를 제공
- Copilot 등 다양한 extension이 있는 것이 장점
- 로컬 컴퓨터 자원을 사용하기 때문에 사용하는 컴퓨터 환경에 따라 머신러닝 모델 사용이 느릴 수 있음
- Google Colab
- Google이 만든 Jupyter Notebook 환경
- 무료로 GPU 등 고사양의 환경을 이용할 수 있음
- 다만, 사용할 수 있는 리소스가 임의로 설정되어, 딥러닝 모델 등 리소스를 많이 사용하려면 과금이 필수
- Anaconda
- 데이터 과학 및 머신러닝 분야에 적합한 Python과 R의 패키지/의존성 및 배포를 편리하게 해주는 오픈 소스 패키지
- 데이터 과학에 초점이 맞춰져 있으며, 역시 로컬 컴퓨터 자원을 사용합니다.
Jupyter Notebook
- Data Science를 위한 환경으로 오픈소프트웨어 웹 어플리케이션
- 코드작성, 시각화, Markdown을 이용한 문서 작성이 가능
- 구성요소
- Code Cell
- Markdown Cell
- print 쓰지 않고 변수명만 적어도 자동으로 print를 해 주는 기능이 있음
자연과학, 공과 대학 등 실험을 기반으로 하는 연구는 연구노트를 사용합니다. 기존 script 코드 파일은 실험과 연구에 대한 결과를 남기기엔 메모와 시각화 기능이 약하여 cell 기반으로 연구 노트북의 형태인 Jupyter Notebook이 개발되었습니다.
anaconda 가상환경
커널 추가 및 삭제
- 가상환경 생성
conda create -n venv python=3.8
: conda 명령으로 venv라는 이름의 Python 3.8 버전을 사용하는 가상환경을 생성
- 가상환경 활성화
conda activate venv
: 위에서 생성한 가상환경인 venv를 활성화
- ipykernel 설치
pip install ipykernel
- 커널 추가
python -m ipykernel install --user --name=venv
: 위에서 설치한 ipykernel을 이용해 가상환경 venv를 주피터 노트북의 커널로 추가
- 커널 목록 확인
jupyter kernelspec list
- 커널 삭제
jupyter kernelspec uninstall venv
python version 변경
- source activate (가상환경명) : 가상환경 실행.
- python -V : 파이썬 버전 확인.
- conda search python : 사용 가능한 python list 확인.
- conda install python=x.x.x : 입력 버전으로 파이썬 버전이 변경됨.
- source deactivate
- source activate (가상환경명) : 가상환경 실행.
- python -V : 변경된 파이썬 버전을 확인할 수 있음.
JSON
-
Java Script Object Notation 의 약자
-
데이터를 표시하는 방법 중 하나
- 단순한 데이터 포멧임: key-value 형태의 데이터 자료형
- JSON은 JavaScript에서 파생되지만 언어 독립적인 데이터 형식
-
사용 이유
- json 파일이 가지고 있는 데이터를 받아서 객체나 변수에 할당해서 사용
- 다른 포멧에 비해 경량화된 데이터 포멧임
-
구조
- JSON 데이터는 키/값 쌍으로 작성
- 키와 값은 중간에 콜론(:)으로 구분
- 왼쪽에는 키, 오른쪽에는 값
- 다른 키/값 쌍은 쉼표(,)로 구분
- 키는 “name"과 같이 큰따옴표로 묶인 문자열이고, 값은 다음 유형일 수 있음
- Object(객체)
- name/value 순서쌍
- set임
- {}로 정의
- Array(배열)
- 대괄호로 묶인 값 목록
- Boolean
- True/False
- String
- 큰따옴표로 묶인 유니코드 문자 시퀀스
- 번호
- JSON 데이터는 키/값 쌍으로 작성
-
예시
{
"name":"Jack",
"age":30,
"contactNumbers":[
{
"type":"Home",
"number":"123 123-123"
},
{
"type":"Office",
"number":"321 321-321"
}
],
"spouse":null,
"favoriteSports":[
"Football",
"Cricket"
]
}추가: JSON PARSING
- json 파일 내의 특정 data만 추출하는 것
머신러닝 라이브러리 설치/삭제
- 설치:
pip install {라이브러리명}- 설치 확인:
라이브러리명.__version__import pandas as pd pd.__version__
- 설치 확인:
- 삭제:
pip uninstall pandas- 셀에 바로 입력한다면
pip uninstall pandas -y- y 는 “삭제하겠는가?”라는 물음에 yes를 누른다는 의미
- 셀에 바로 입력한다면
2. 회귀분석: 선형회귀
학습 목표
- 머신러닝의 기본! 회귀분석 알아보기
- 평가척도 알아보기
선형회귀 사레
- 1차 방정식을 갓 배운 학생(→ 중·고등학생)이라고 가정하고 선형회귀를 적용해보는 사례 이해하기
몸무게와 키 상관관계 찾아내기
방정식을 배운 머신이는 몸무게와 키의 데이터를 획득했다. 일정하게 증가하는 패턴이 있어서 미리 몸무게를 알면 키를 알 수 있을 것이라고 생각했다.
- 키와 몸무게 간의 데이터
weights = [87,81,82,92,90,61,86,66,69,69]
heights = [187,174,179,192,188,160,179,168,168,174]- 키와 몸무게 간의 산점도
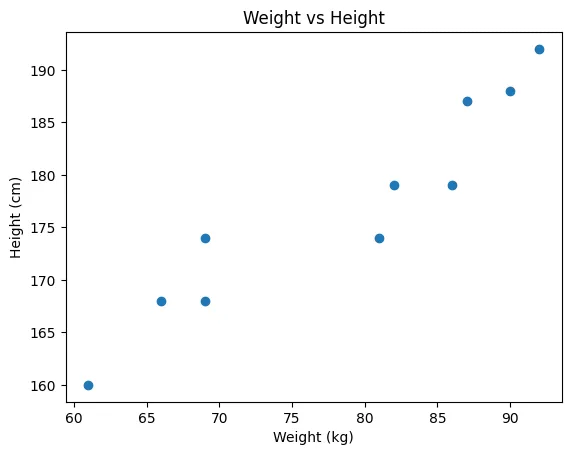
중학교 1학년 때 1차 방정식을 배운 머신이는 키와 몸무게에 대한 데이터가 너무 많아서 무슨 두 점을 이어 직선을 만들지 고민 되었지만, 수 많은 점들을 관통하는 여러 개의 직선을 많이 그려보기로 했다.
- 어떤 직선이 현재 데이터를 잘 "설명"한다고 할 수 있을까?
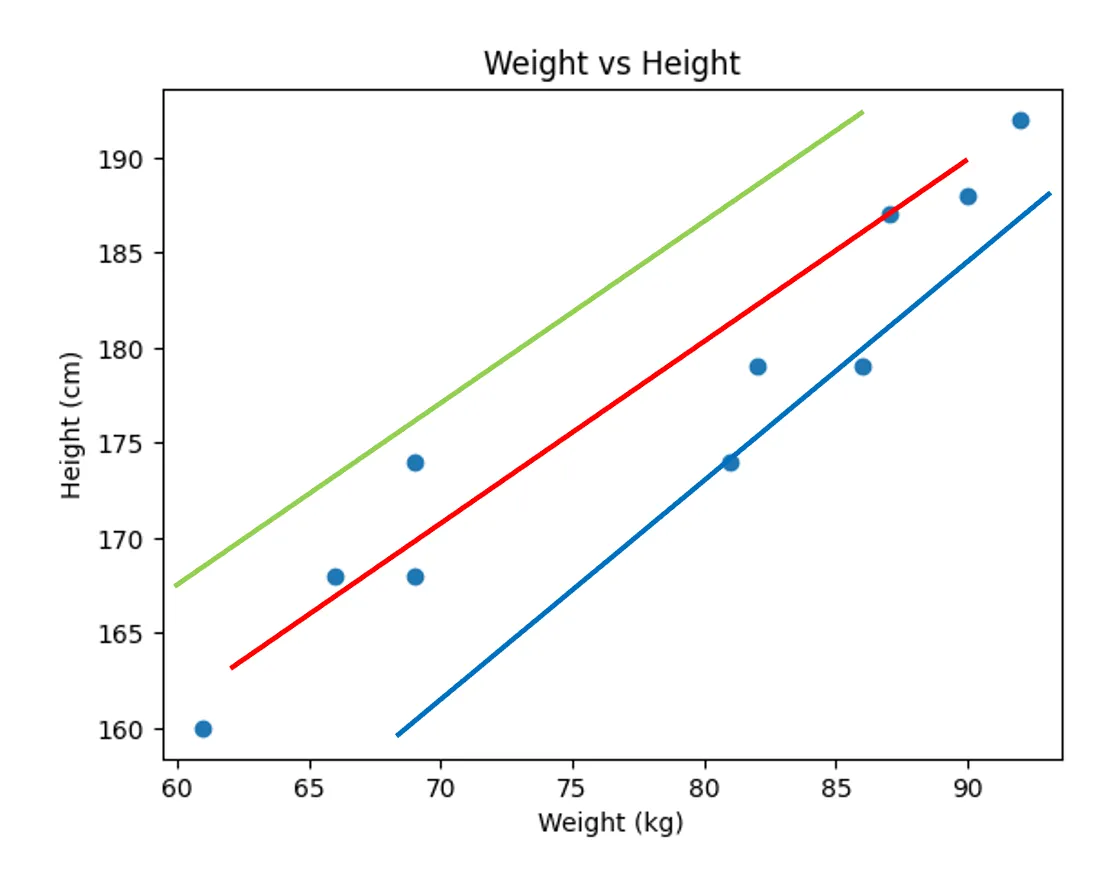
머신이는 3개의 그래프를 그려보니, 아무래도 초록색, 파란색 직선보다는 빨간색 그래프가 적절한 것 같다. 하지만 이렇게 대강 직선을 그리다 보면 적절한 그래프를 찾기 어려울 것 같아 고민에 빠졌다.
Data Scientific한 발상
머신이는 하나의 생각을 떠 올렸다. 바로 직선과 점의 간의 거리를 계산하는 것이다. 이를 Error 라고 정의하고 최소의 Error인 직선을 그리면 된다고 생각했다.
방법 1
- 실제 데이터 값 - 직선의 예측 값 = Error
- ①번 실제 데이터:187, 예측 데이터: 187 Error: 0
- ②번 실제 데이터: 174, 예측 데이터: 181 Error: -7
- ③번 실제 데이터: 174, 예측 데이터 : 169 Error: +5
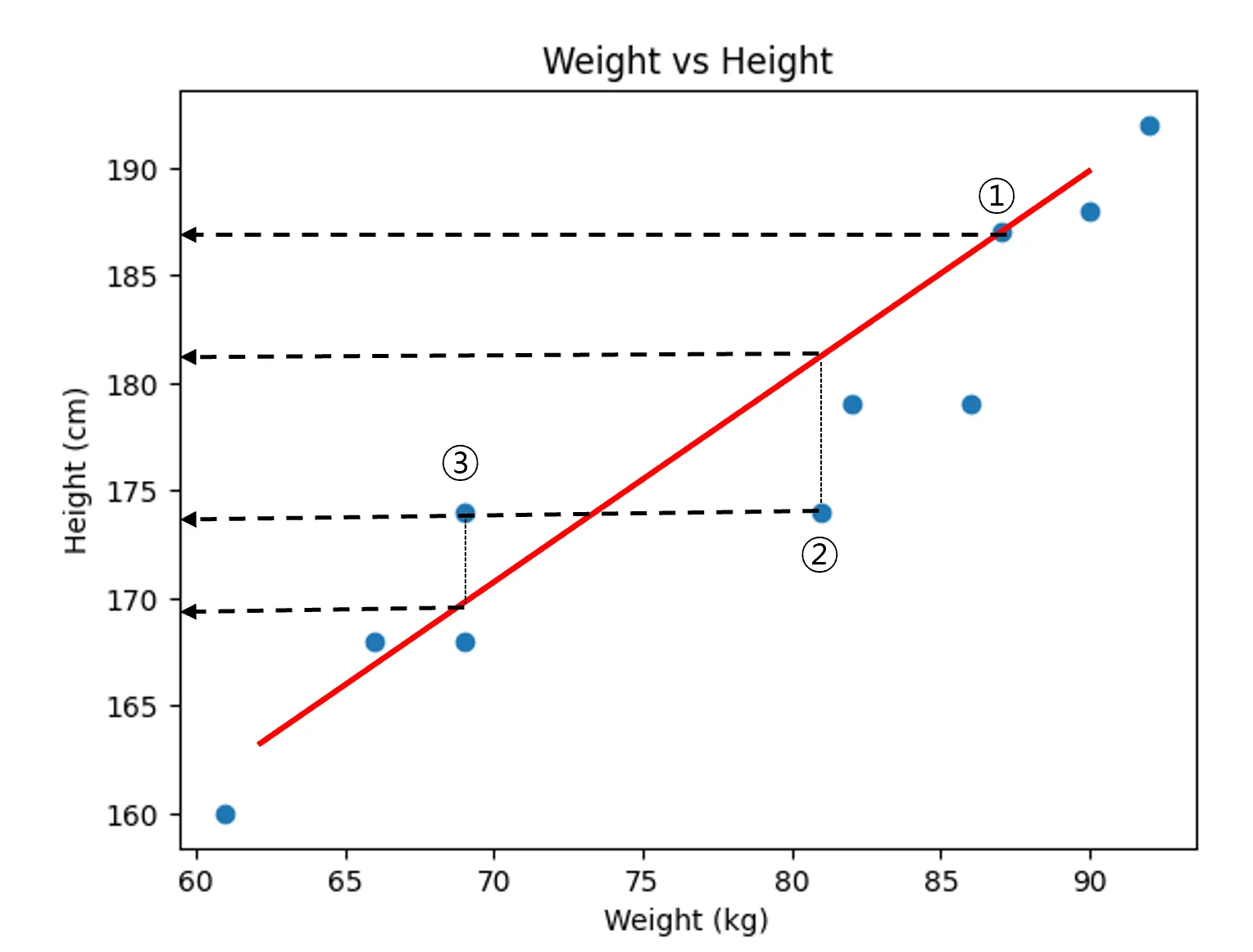
하지만 문제가 또 있었다. 선분을 기준으로 위에 있는 데이터의 거리를 계산하면 양수가 되고, 반대로 아래에 있는 것은 음수가 된다. 이 경우 모든 에러를 합치면 서로 상쇄되는 문제가 있었다. 따라서, 음수를 양수로 만들기 위해 제곱을 하는 방법이 있다는 걸 생각해 냈다.
방법 2
- 각각 Error를 제곱하여 모두 더하기
- ①, ②,③의 제곱 합: 49 +25 = 71
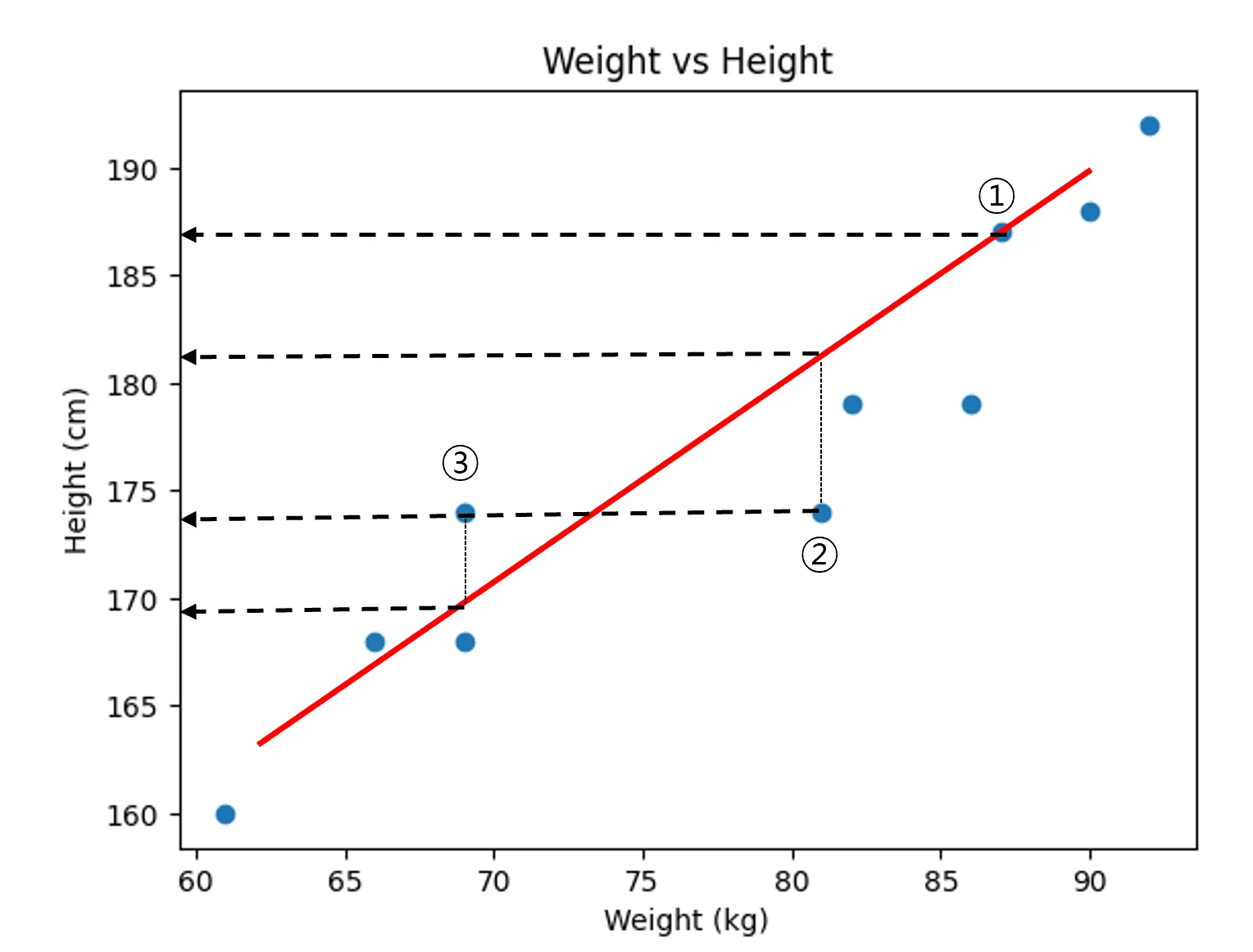
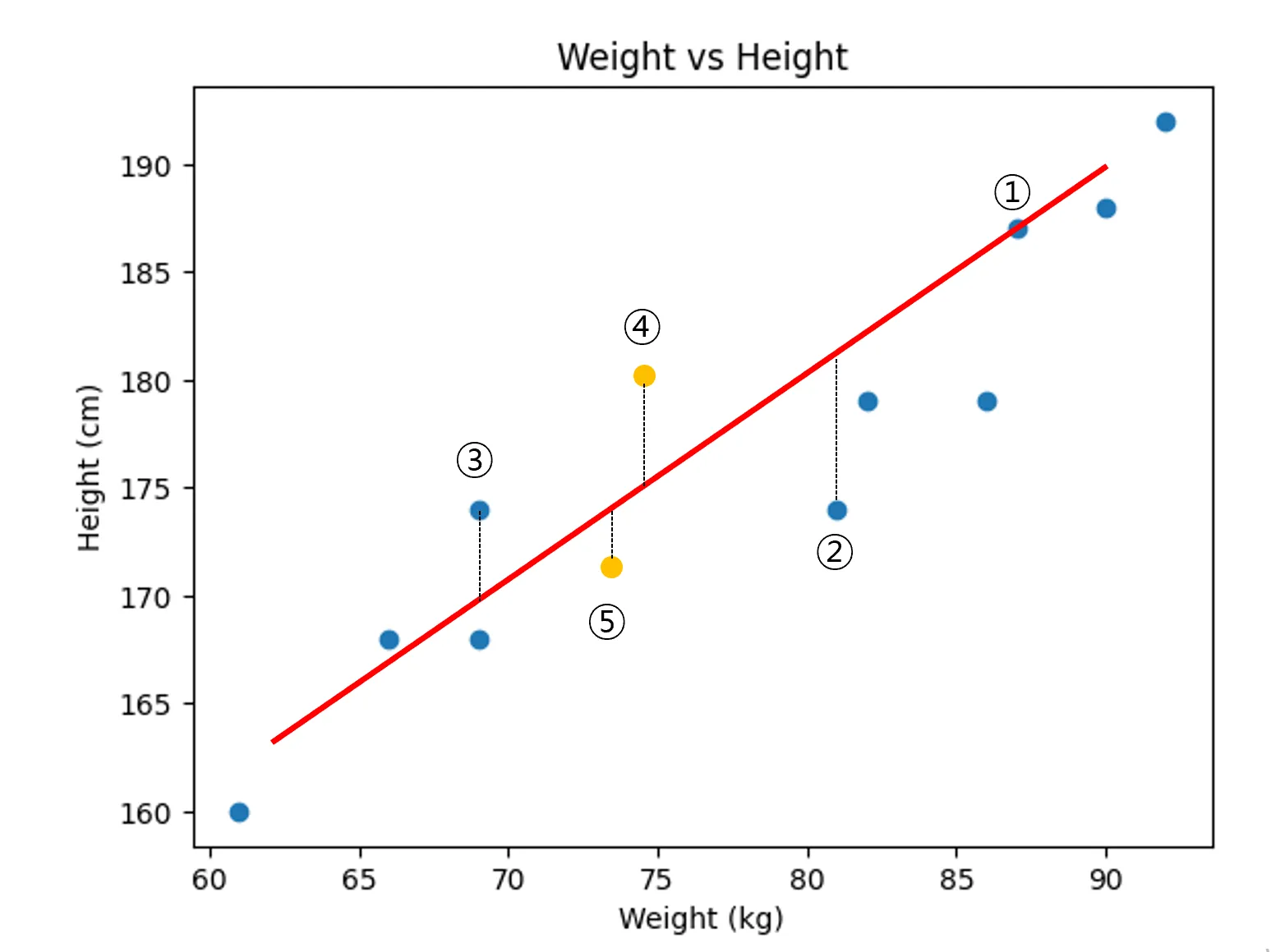
문제는 하나 더 있었다. 나중에는 데이터를 더 수집할 예정인데, 데이터가 더 늘어날 수록(④,⑤) 에러는 자연스럽게 값이 커질 수 밖에 없는 것이다! 그래서 데이터의 갯수로 나누기로 했다. 또한 데이터가 제곱 되어 있던 것을 줄이기 위해 root를 씌우기로 했다.
방법 3
- 전체 에러 합을 데이터의 갯수로 나누기
- ①, ②,③만 고려한다면 71/3 → 23.7
→ 오차 합의 평균
- ①, ②,③만 고려한다면 71/3 → 23.7
선형회귀 이론
- 머신이가 하려는 방법을 잘 이해했다면 이번에는 실제 일차 방정식을 통해 수식화 해보기
용어 정리
머신이는 몸무게를 알면 키를 알 수 있을 것이라 생각했어요. 이를 이용해서 방정식을 세우고 용어를 정리해볼게요.
통계학과 컴퓨터 공학 두 학문을 바탕으로 발전해와서 같은 원리지만 부르는 명칭이 살짝 달라요!
- 공통
- Y: 종속 변수, 결과 변수
- X: X는 독립 변수, 원인 변수, 설명 변수
- 통계학에서 사용하는 선형회귀 식
- : 편향(Bias)
- : 회귀 계수
- : 오차(error), 모델이 설명하지 못하는 Y의 변동성
→ 회귀 계수: 직선의 기울기, 편향+오차: y절편
- 머신러닝/딥러닝에서 사용하는 선형회귀 식
- : 가중치
- : 편향(Bias)
※ 머신러닝/딥러닝 모델에서 오차 항은 명시적으로 다루지 않음
결국 두 수식이 전달하려고 하는 의미는 같아요. 회귀 계수 혹은 가중치를 값을 알면 X가 주어졌을 때 Y를 알 수 있다는 것이죠!(→ True값은 모르지만 근사값은 알 수 있음)
우리는 편의를 위해 X의 계수는 가중치라고 지칭할게요!
QnA
- 수식 어떻게 계산되나요?
- 각 변수가 사실 행렬로 이루어진 값입니다.
(행렬 계산은 본 과정에서 다루지 않습니다!)

- 각 변수가 사실 행렬로 이루어진 값입니다.
- 는 1차 방정식의 Y절편에 해당하는 걸 알겠어요. 그런데 왜 은 따로 있는 건가요?
- 우리가 몸무게와 키에 대한 선형회귀식을 만들었지만, 해당 식이 모든 데이터를 완벽하게 설명할 수 없어요. 이때 완벽한 설명이란 실제 데이터값 = 예측 데이터 이라고 할 수 있어요. 다시 말해 에러(②,③)의 값을 표현하기 위해서 있는 것입니다.
- 가중치()를 알게 되면 X값에 대해서 Y값을 예측할 수 있다는 것은 이해가 되는데, 그럼 가중치는 어떻게 구하죠?
- 이런 물음이 들었다면 머신러닝을 관통하는 질문입니다. 데이터가 충분히 있다면 가중치를 “추정”할 수 있습니다. 이는 심화 내용에서 다루도록 할게요! 이 부분은 현재는 그래프를 수도 없이 그려서 에러를 “최소화”하는 직선을 구한다고 생각하시면 됩니다.
몸무게와 키 데이터를 이용해서 선형회귀 식을 만들면, y = 0.86x + 109.37 이 나와요. 이 뜻은, 1kg 증가할때마다 키가 0.86 cm 증가한다는 것으로 해석 할 수 있어요.
회귀분석 평가 지표
- 선형회귀를 수립하는 방법을 배웠으니 해당 모델이 좋은지 평가하는 방법도 알아보가
회귀 평가 지표
MSE(Mean Squared Error)
머신이가 똑똑하게 에러를 정의한 것을 바탕으로 회귀식의 평가지표를 만들어보겠습니다. 머신이가 정리한 내용을 다시 써볼까요?
- 에러 정의 방법
에러 = 실제 데이터 - 예측 데이터로 정의- 에러를 제곱하여 모두 양수로 만들기, 다 합치기
- 데이터만큼 나누기
→ 수식화
1.
2.
3.
※ y값의 머리에 있는 ^는 hat이라고 하며, 예측(혹은 추정)한 수치에 표기
- 3번째 방법을 Mean Squared Error(MSE)라고 정의
앞으로 만나는 숫자 예측 문제는 모델을 머신러닝이든 딥러닝이든 어떤 모델을 만들어도 위 MSE 지표를 최소화하는 방향으로 진행하고 평가합니다!
기타 평가 지표
- RMSE
- MSE에 Root를 씌워 제곱 된 단위를 다시 맞추기
- MSE에 Root를 씌워 제곱 된 단위를 다시 맞추기
- MAE
- 절댓값을 이용해 오차 계산
- 절댓값을 이용해 오차 계산
선형회귀만의 평가 지표: R Square
숫자를 예측하는 회귀분석에서, 선형회귀에서만 평가되는 지표가 1개 더 있어요. 그건 바로 R Square 지표입니다. R Square는 전체 모형에서 회귀선으로 설명할 수 있는 정도를 뜻합니다.
어떤 값을 “예측”한다는 건 어림짐작으로 평균값보단 예측을 잘해야한다는 것을 의미해요. 예컨대, 키의 평균 값이 176.9인데 이 값으로 모두 예측한 것보다는 잘해야겠죠?
회귀 == 숫자(y) 맞추기
↕
분류 == 범주(y=0, y=1) 맞추기
- 기초 용어
- : 특정 데이터의 실제 값
- : 평균값
- : 예측, 추정한 값
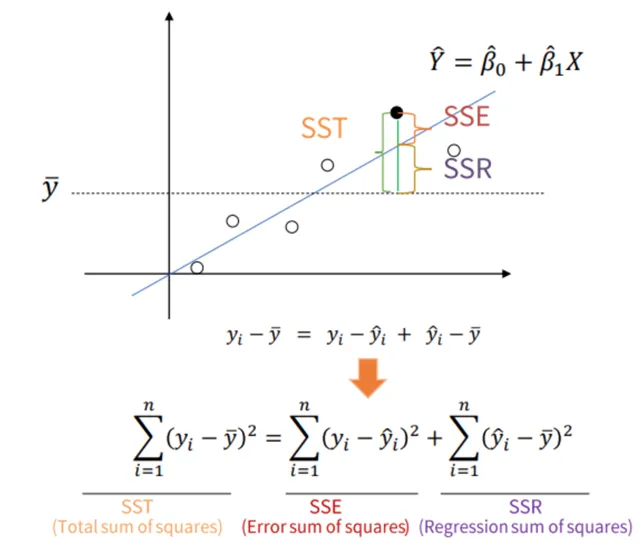
- R Square의 정의
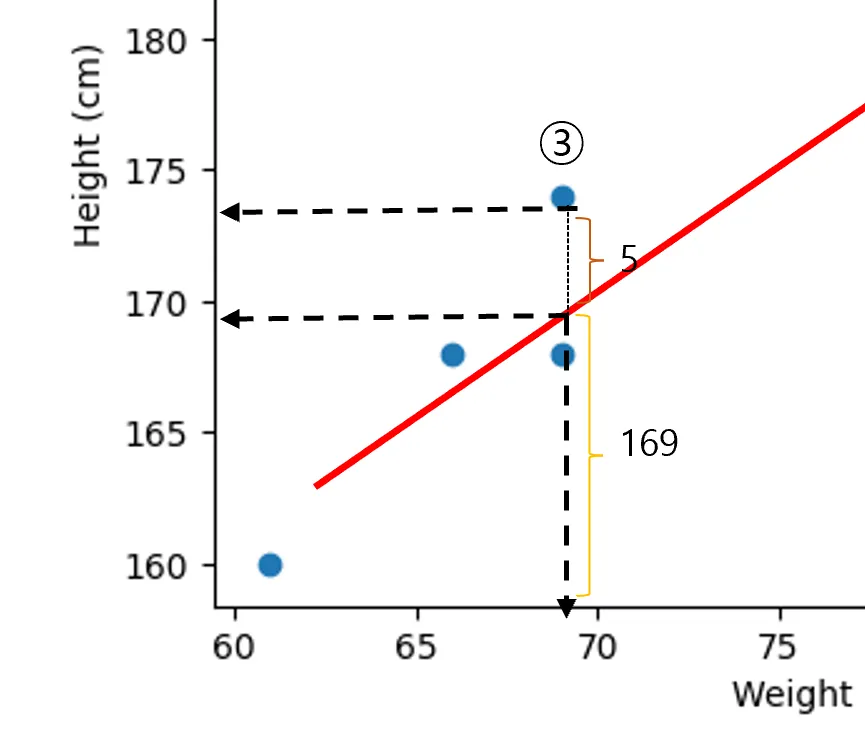
- 3번의 데이터 값은 ,
- 해당 값에 대한 설명력 = 94%
- 단, 모든 데이터에 대해서 위 계산을 수행
- 3번의 데이터 값은 ,
선형회귀 적용
- 선형회귀를 수립하는 방법을 배웠으니 데이터로 실습해보기
라이브러리 설치
머신러닝을 쉬행하기 위한 대표적인 라이브러리인 scikit-learn과 그 외에도 자주 쓰이는 대표적 라이브러리 설치하기
데이터 사이언스 파이썬 라이브러리
scikit-learn: Python 머신러닝 라이브러리numpy: Python 고성능 수치 계산을 위한 라이브러리pandas: 테이블 형 데이터를 다룰 수 있는 라이브러리matplotlib: 대표적인 시각화 라이브러리, 그래프가 단순하고 설정 작업 많음seaborn: matplot기반의 고급 시각화 라이브러리, 상위 수준의 인터페이스를 제공
자주 쓰는 함수
sklearn.linear_model.LinearRegression: 선형회귀 모델 클래스coef_: 회귀 계수intercept: 편향(bias)fit: 데이터 학습predict: 데이터 예측
실습
키-몸무게 데이터 실습
- 선형회귀 모델 불러오고 훈련하기
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
weights = [87,81,82,92,90,61,86,66,69,69]
heights = [187,174,179,192,188,160,179,168,168,174]
# dictionary 형태로 데이터 생성
body_df = pd.DataFrame({'height': heights, 'weight': weights})- 산점도 그리기
# weight와 height 간의 산점도(scatter plot)
sns.scatterplot(data = body_df, x='weight', y='height')
plt.title('Weight vs Height')
plt.xlabel('weight(kg)')
plt.ylabel('Height(cm)')
plt.show()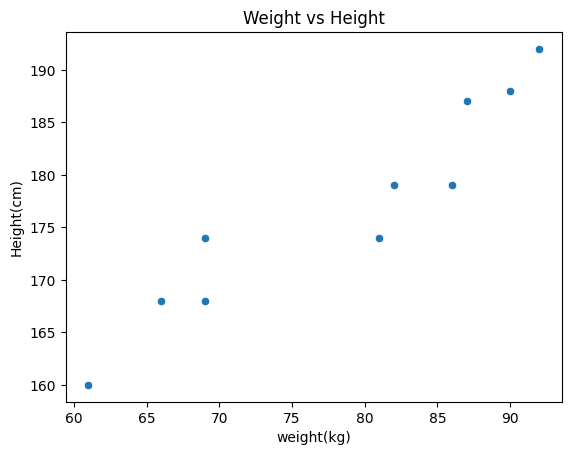
→ 두 개가 선형 관계가 있음을 확인: 선형회귀를 적용할 수 있다고 판단
# 선형회귀 훈련Train(적합Fit)
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression()
# DataFrame[]: Series(데이터프레임의 컬럼)
# DataFrame[[]]: DataFrame
X = body_df[['weight']]
y = body_df[['height']]
# 데이터 훈련
model_lr.fit(X=X, y=y)
w1 = model_lr.coef_[0][0]
w0 = model_lr.intercept_[0]
# print('y = {}x + {}'.format(w1.round(2), w0.round(2)))
print(f'y = {w1.round(2)}x + {w0.round(2)}')
# 실행 결과
# y = 0.86x + 109.37※ type(model_lr)하면 sklearn.linear_model._base.LinearRegression이라고 나와야 함
※ X는 대문자, y는 소문자로 적는 게 관습이라고 함
- 평가
y = 0.86x + 109.37- y(키)는 x(몸무게)에 0.86을 곱한 뒤 109.37을 더하면 된다.
- 해당 식 활용하여 MSE 구하기:
- 예측 컬럼을 추가
- 에러값을 각각 계산(error)
- 양수를 만들기 위해 제곱
- 모두 더할 예정(MSE)
# 예측값 만들기
body_df['pred'] = w1*body_df['weight'] + w0
# 에러
body_df['error'] = body_df['height'] - body_df['pred']
# 양수를 만들기 위해 제곱
body_df['error^2'] = body_df['error']*body_df['error']
# MSE 계산
body_df['error^2'].sum()/len(body_df)
# 실행 곃과:
# np.float64(10.152939045376309)# 산점도 그래프에 선형식(추세선)을 만들어서 그래프로 그래기
sns.scatterplot(data=body_df, x='weight', y='height')
sns.lineplot(data=body_df, x='weight', y='pred', color='red')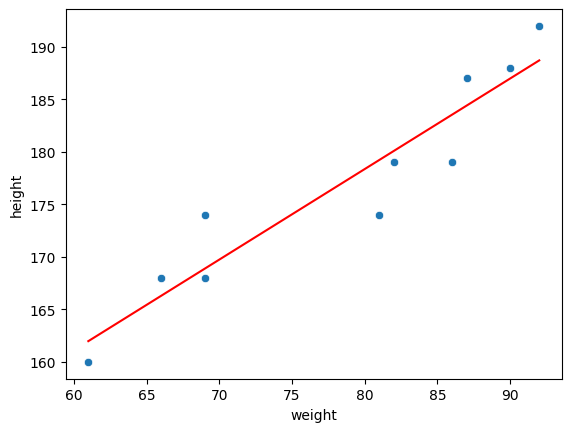
# 선형회귀 모델 평가
# 회귀(숫자를 맞추는 방법): MSE(수동 계산 결과는 10)
# R Square: 평귱 대비 설명력, 값이 0이면 제일 낮고 1일수록 높은 것
# from sklearn.metrics import mean_squared_error
# from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error, r2_score
# metrics: 평가함수 모음
# 평가함수는 공통적으로 정답(실제 true), 예측값(pred) 넣어야 함
y_true = body_df['height']
y_pred = body_df['pred']
mean_squared_error(y_true, y_pred)
# 실행 결과:
# np.float64(10.152939045376309)r2_score(y_true, y_pred)
# 실행 결과:
# 0.8899887415172141# 추가: 예측값(pred)을 함수로 만들 수도 있음
y_pred2 = model_lr.predict(body_df[['weight']])
y_pred2→ 실행 결과:
array([[184.40385835],
[179.22878362],
[180.09129608],
[188.71642061],
[186.99139571],
[161.97853455],
[183.54134589],
[166.29109682],
[168.87863418],
[168.87863418]])
모르는 걸 찾을 때 공식 문서를 읽는 습관을 들이면 좋아요!
- 구글링 → 블로그
- 단점: 늘 블로그가 바뀜, 형태가 일정하지 않음
- ChatGPT LLM
- 단점: 의존하게 되면 더 이상 공부를 안함, 거짓된 정보를 전달하는 경우도 있음(hallucination)
- 공식 문서
- 장점: 일관되게 정리되어 있어 동일한 위치(경로)에 똑같은 내용이 있음
- 자격증 시험: 공식 문서만 열람할 수 있음
- 단점: 초보자에게는 읽기 어려움
help(): 인터넷 안 될 때도 쓸 수 있다는 장점
→ 아니면 mouse over했을 때 나오는 내용 읽는 것도 추천
help(sklearn)help(sklearn.linear_model.LinearRegression)
tips로 실습
파이썬 라이브러리에 내장되어 있는 tip에 대한 데이터로 실제 회귀분석을 진행해봅시다.
식당에서 파트타임으로 일하고 있는 머신이는 이번에는 tip 데이터를 가지고 적용해보기로 했습니다. 돈을 많이 벌고 싶었던 머신이는 전체 금액(X)를 알면 받을 수 있는 팁(Y)에 대한 회귀분석을 진행해볼 예정입니다.
- seaborn 시각화 라이브러리는 기본적으로 데이터셋을 제공
tips_df = sns.load_dataset('tips')
tips_df.head(3)- 데이터 획득
tips_df.head()
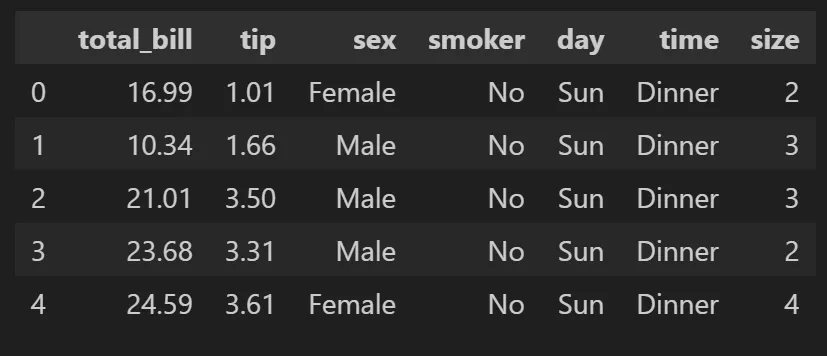
- 컬럼 설명
- total_bill: 전체 지불금액
- tip: 팁 금맥
- sex: 성별
- smoker: 흡연 유무
- day: 요일
- time: 식사 시간(점심, 저녁)
- size: 식사 인원
# 산점도 그리기
sns.scatterplot(data=tips_df, x='total_bill', y='tip')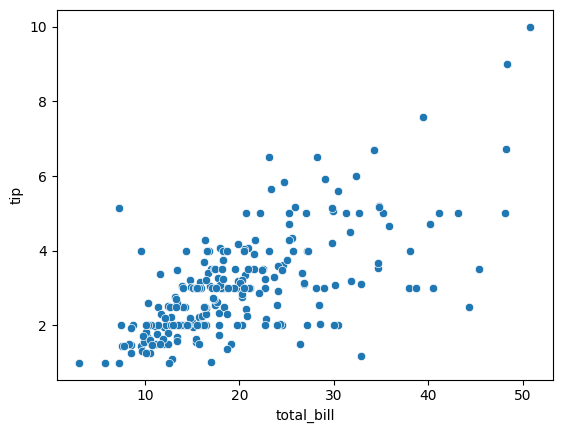
- 선형회귀 훈련
# X: total_bill, y: tip
model_lr2 = LinearRegression()
X = tips_df[['total_bill']]
y = tips_df[['tip']]
model_lr2.fit(X, y)
# y(tip) = w1_tip*x(total_bill) + w0_tip
w1_tip = model_lr2.coef_[0][0]
w0_tip = model_lr2.intercept_[0]
print(f'y = {w1_tip.round(2)}x + {w0_tip.round(2)}')
# 실행 결과:
# y = 0.11x + 0.92
# 해석: 전체 결제 금액이 1달러 오를 때, 팁은 0.11달러 추가된다.
# scaling: 전체 결제 금액이 100달러 오를 때, 팁은 11달러 추가된다.- 평가
# 예측값 생성
y_true_tip = tips_df['tip']
y_pred_tip = model_lr2.predict(tips_df[['total_bill']])
mean_squared_error(y_true_tip, y_pred_tip)
# 실행 결과:
# np.float64(1.036019442011377)
r2_score(y_true_tip, y_pred_tip)
# 실행 결과:
# 0.45661658635167657→ MSE는 스케일 다르면 1대 1로 비교 X 🡆 같은 데이터에서 다른 모델에 비교할 때만 사용
→ R Square는 '분야'마다 적정 기준치가 있음: 데이터가 사회·문화, 경제 쪽 통계라면 40%(0.4) 넘으면 좋다고 보기도 함
# 산점도와 선형회귀 선 그리기
tips_df['pred'] = y_pred_tip
sns.scatterplot(data=tips_df, x='total_bill', y='tip')
sns.lineplot(data=tips_df, x='total_bill', y='pred', color='red')🡆 문제: R Square가 낮은 게 문제임 → total_bill 말고 다른 변수를 넣어보고 싶다… 하지만 어떻게?
🡆 X 변수를 여러 개 넣고 싶다! → 다중선형회귀
- 선형회귀
- 단순선형회귀: x 변수가 1개
- 다중선형회귀: x 변수가 2개 이상
🡆 변수형 데이터를 어떻게 사용해야 하나?
선형회귀 심화
- 선형회귀를 좀 더 발전시켜 다중선형회귀와 범주형 데이터 넣어보기
다중선형회귀
지금까지는 X와 Y간의 데이터에 아주 간단한 단순회귀분석에 대해서만 배웠지만 실제의 데이터들은 비선형적 관계를 가지는 경우가 많습니다. 이를 위해서 X변수를 추가 할 수도, 변형할 수 도 있습니다.
단순선형회귀 vs. 다항회귀
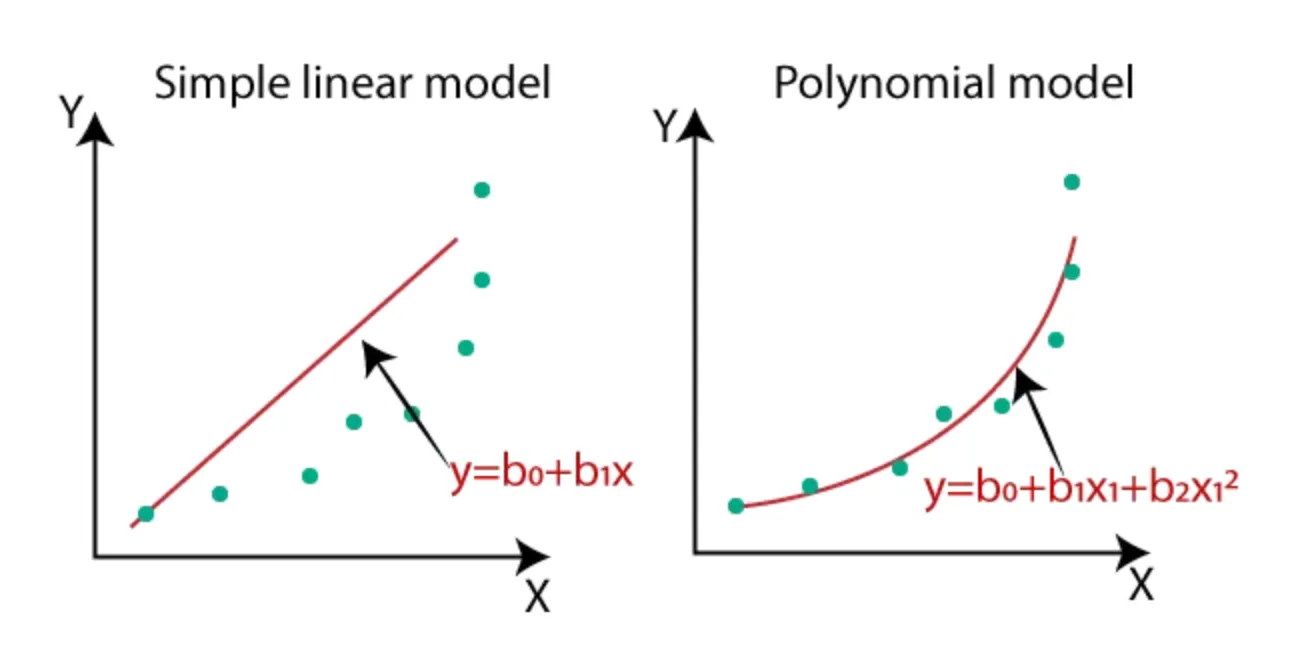
범주형 데이터 사용
수치형 데이터 vs. 범주형 데이터
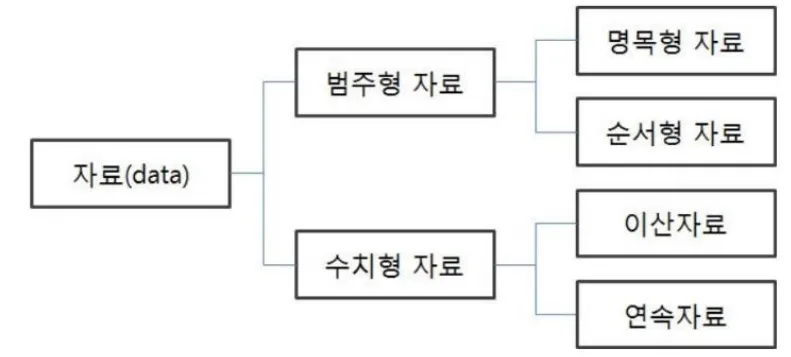
- 수치형 데이터
- 연속형 데이터: 두 개의 값이 무한한 개수로 나누어진 데이터
(예) 키, 몸무게 - 이산형 데이터: 두 개의 값이 유한한 개수로 나누어진 데이터
(예) 주사위 눈, 나이
- 연속형 데이터: 두 개의 값이 무한한 개수로 나누어진 데이터
- 범주형 데이터
- 순서형 자료: 자료의 순서 의미가 있음
(예) 학점,등급 - 명목형 자료: 자료의 순서 의미가 없음
(예) 혈액형, 성별
- 순서형 자료: 자료의 순서 의미가 있음
범주형 데이터 실습
머신이는 데이터 선형회귀를 훈련 시켰지만 성능이 별로 좋지 않다는 것을 알게 되었습니다. → R Square값이 0.4 정도 나왔음
그래서 성별과 같은 다른 데이터를 사용하고 싶어졌습니다. 그런데 문제는 성별 데이터는 문자형이여서 숫자로 표현할 방법이 필요해졌습니다.
- 머신러닝 모델에 데이터를 훈련시킬려면 해당 데이터를 숫자로 바꿔야함
- 성별, 날짜 와 같은 데이터를 범주형 데이터라고 부르며 이를 임의로 0,1 등에 숫자로 바꿀 수 있음
- 이를 Encoding 과정이라 함
- Encoding → 숫자로 바꾼다고 이해하면 쉬움
- 이를 Encoding 과정이라 함
실습: 회귀 심화
- 범주형 데이터로 실습해보기
- 범주형 데이터 인코딩
- 직접 함수를 쓸 수도 있고 sklearn에서 제공하는 함수를 쓸 수도 있음
- sklearn 제공 함수 사용은 심화 강의에서 할 것
- 직접 함수를 쓸 수도 있고 sklearn에서 제공하는 함수를 쓸 수도 있음
# 범주형 데이터 사용하기
# Female 0, Male 1
def get_sex(x):
if x == 'Female':
return 0
else:
return 1
# apply method는 매 행에 특정한 함수를 적용한다.
tips_df['sex_en'] = tips_df['sex'].apply(get_sex)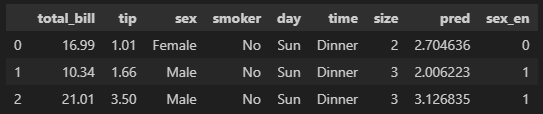
- 훈련
# 모델설계도 가져오기
model_lr3 = LinearRegression()
X = tips_df[['total_bill', 'sex_en']]
y = tips_df[['tip']]
# 훈련
model_lr3.fit(X,y)- 학습
# 예측
y_pred_tip2 = model_lr3.predict(X)
y_pred_tip2[:5]- 실행 결과:
array([[2.72117624],
[1.99477235],
[3.1176016 ],
[3.39857199],
[3.52094215]])
- 평가
# 단순선형회귀 mse: X 변수가 전체 금액
# 다중선형회귀 mse: X 변수가 전체 금액, 성별
print('단순선형회귀', mean_squared_error(y_true_tip, y_pred_tip))
print('다중선형회귀', mean_squared_error(y_true_tip, y_pred_tip2))- 실행 결과:
단순선형회귀 1.036019442011377
다중선형회귀 1.0358604137213614
# R Square
print('단순선형회귀', r2_score(y_true_tip, y_pred_tip))
print('다중선형회귀', r2_score(y_true_tip, y_pred_tip2))- 실행 결과:
단순선형회귀 0.45661658635167657
다중선형회귀 0.45669999534149974
→ 생각보다 성능이 좋아지지 않았음: 데이터를 살펴보지 않고 무작정 넣어서 돌렸기 때문임
🡆 사실 머신러닝 돌리기 전에 먼저 안에 있는 데이터가 어떤지 확인하고 전처리를 해서 해당 범주형 데이터가 분석을 진행할 만한지 확인하는 과정이 선행되어야 함!
- 성별에 따른 차이가 있는지 먼저 데이터를 확인하는 과정이 필요했음
sns.barplot(data=tips_df, x='sex', y='tip')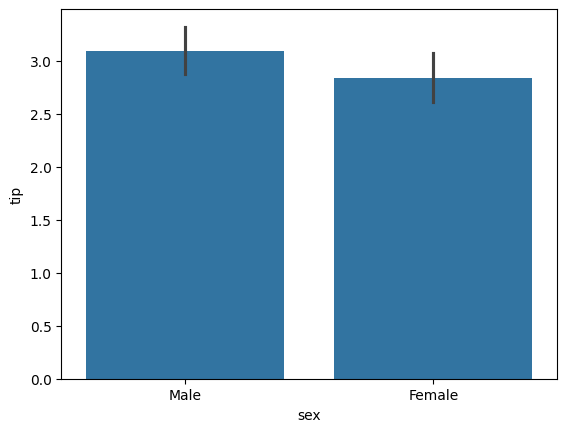
🡆 성별에 따른 Tip의 평균을 비교한 그래프 → 크게 차이가 나지 않음
🡆 전체 데이터에 대해 이러한 과정을 먼저 진행해 사전에 데이터를 확인한 후에 머신러닝 모델에 "의미가 있을 만한 것"을 넣는 게 올바른 흐름: 이 과정을 '변수 선택'이라고 함
정리
선형 회귀의 가정
머신러닝모델 중에 선형회귀는 이해하기 쉽고 방법도 쉬운 장점이 있지만 말 그대로 X-Y변수 간의 선형적 관계가 좋아아만 좋은 성능을 냅니다. → 선형회귀의 가정에 대해서 알아보자!
- '회귀'는 통계학에서 정말 많이 연구된 주제
- 통계학과 과목에 "회귀분석"이 따로 있음(3학점)
- 선형성 (Linearity): 종속 변수(Y)와 독립 변수(X) 간에 선형 관계가 존재해야 함
🡆 예시로 사용한 body_df의 경우 값이 0.9였고 tips_df는 0.4였음 → x, y 간 선형성이 더 있는 body_df 데이터가 값이 더 큼!(선형에 가깝다)
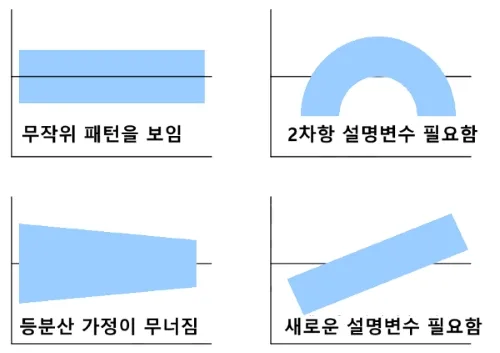
- 등분산성 (Homoscedasticity): 오차의 분산이 모든 수준의 독립 변수에 대해 일정해야 합니다. 즉, 오차가 특정 패턴을 보여서는 안 되며, 독립 변수의 값에 상관없이 일정해야 합니다.
☞ X축:독립변수, Y축: 에러
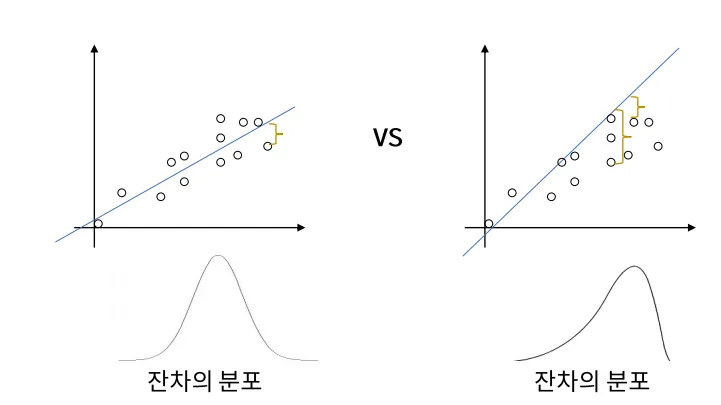
- 정규성 (Normality): 오차 항은 정규 분포를 따라야 합니다.
- 독립성 (Independence): X변수는 서로 독립적이어야 합니다.
-
다중공선성 문제
- 변수가 많아지면 서로 연관이 있는 경우가 많음
- 회귀분석에서 독립변수(X)간의 강한 상관관계가 나타나는 것을 다중공선성(Multicolinearity) 문제라고 함
- multi-: 여러 개가
- -co-: 같이
- linearity: 선형성을 띄는
문제라는 뜻
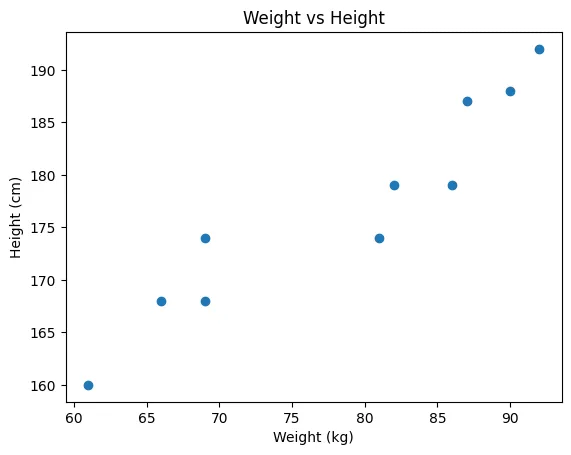
- 만약 위에서 예시를 들었던 Weight, Height 가지고 다른 Y(이를 테면 발사이즈)를 예측한다면 Weight, Height가 연관있는 변수이기 때문에 다중공선성 문제가 나타납니다.
-
Weight vs Height 산점도
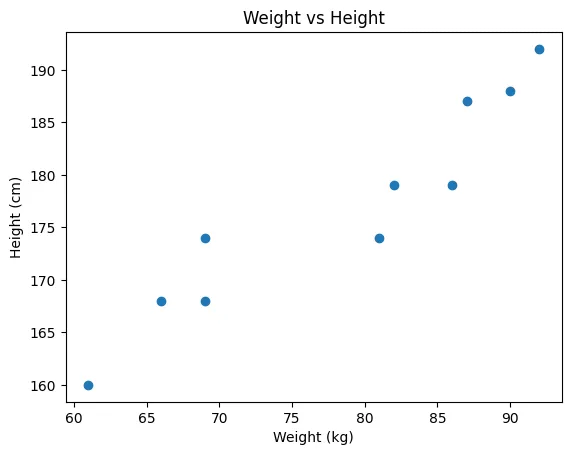
- 다중공선성 해결방법
- 서로 상관관계가 높은 변수 중 하나만 선택(산점도 혹은 상관관계 행렬)
- 두 변수를 동시에 설명하는 차원축소(Principle Component Analysis, PCA) 실행하여 변수 1개로 축소
☞ pairplot 기능을 이용한 산점도
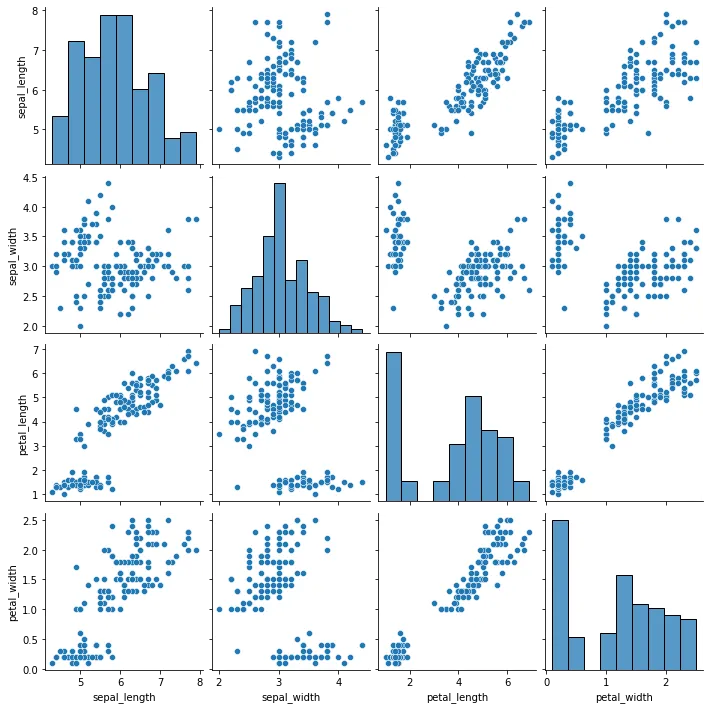
→ iris dataset: x값 4개 가짐
→ 같은 x값을 만나면 히스토그램을 그리고, 다른 x값을 만나면 산점도를 그림
→ petal_length와 petal_width가 강력한 선형 관계가 있음을 확인
🡆 따라서 다중공선성을 해결하려면 둘 중 하나만 가져가야 함!
☞ heatmap을 이용한 상관관계 행렬
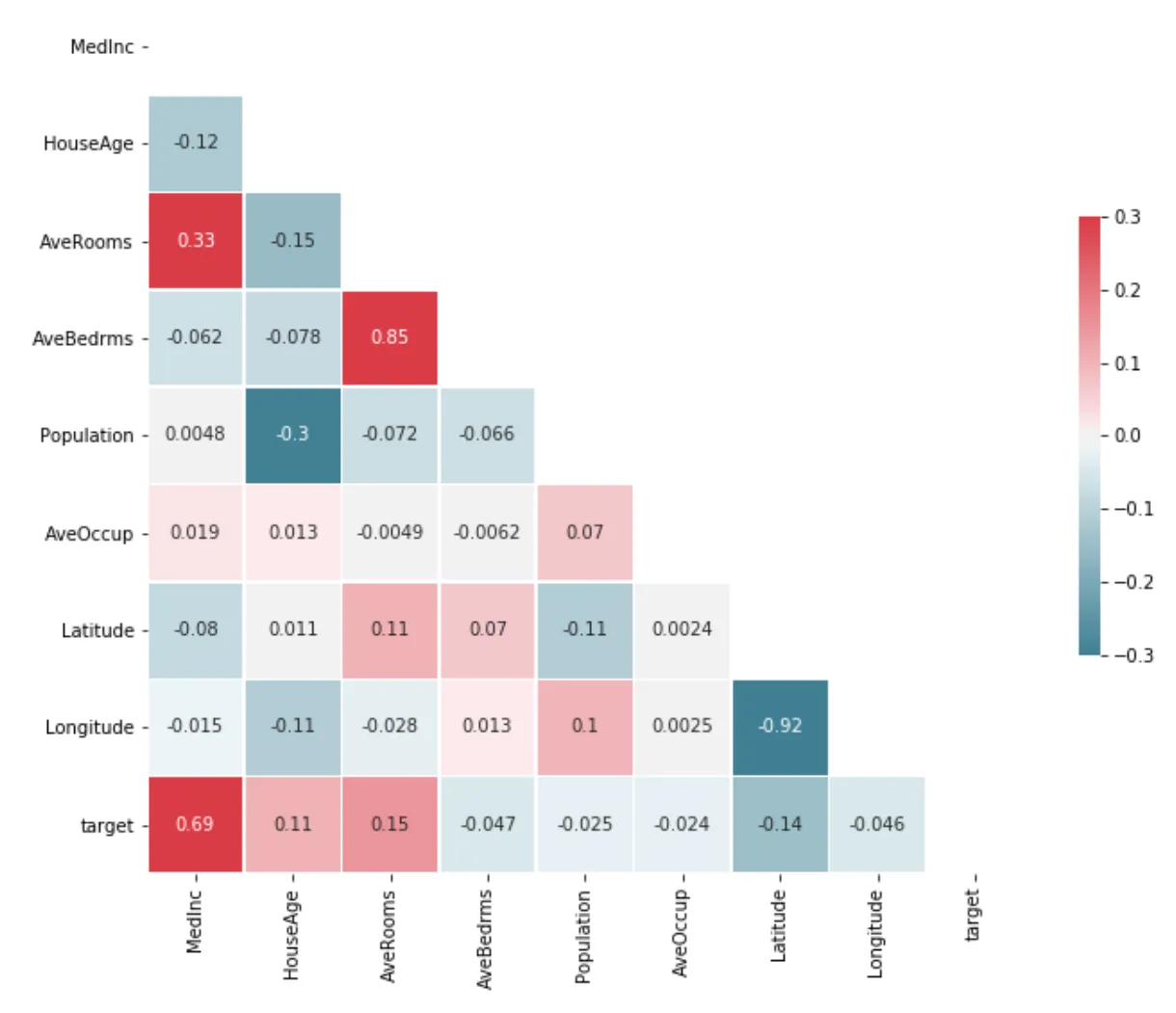
→ 산점도를 숫자로 표현한 것
→ 선형이 크면 클수록 +1에 가까워짐(음의 선형관계일 경우 -1에 가까워짐)
→ 관계가 없으면 0
☞ PCA를 이용한 차원축소
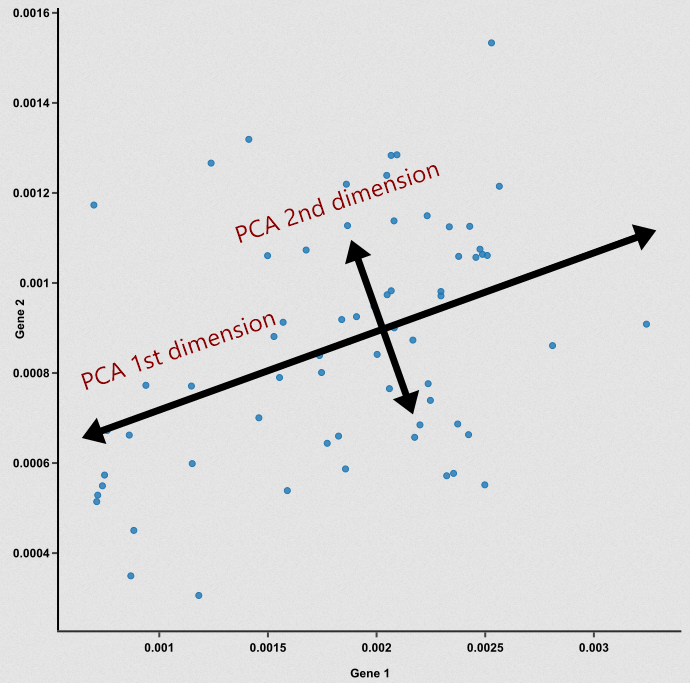
→ 주성분 분석(Principal component analysis; PCA)
→ 변수 두 개를 써서 설명할 걸 하나의 축으로 설명할 수 있음
: 아래 [그림 1] 에서 왼쪽에 있는 2차원 데이터를 오른쪽에 있는 1차원 데이터로 최대한 특징을 살리며 차원을 낮춰주는 것
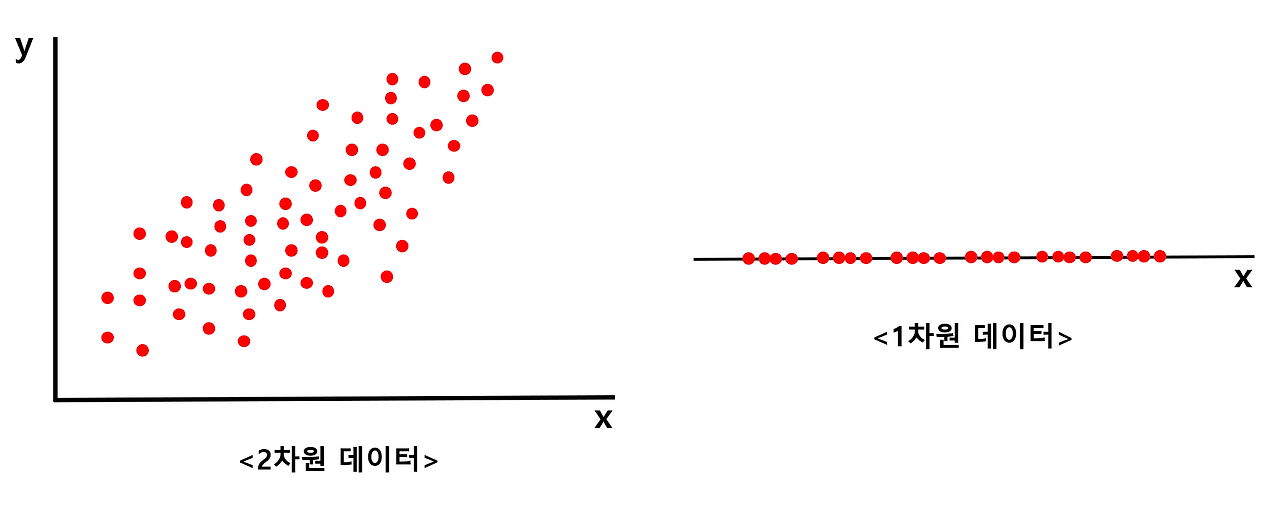
선형 회귀 정리
- 장점
- 직관적이며 이해하기 쉽다. X-Y관계를 정량화 할 수 있다.
- 모델이 빠르게 학습된다(가중치 계산이 빠르다) 🡆 행렬 계산을 함: 선형대수!
- 단점
- X-Y간의 선형성 가정이 필요하다.
- 평가지표가 평균(mean)포함 하기에 이상치에 민감하다.
- 범주형 변수를 인코딩시 정보 손실이 일어난다.
- Python 패키지
sklearn.linear_model.LinearRegression
숙제
- tips 데이터를 이용하여 다양한 변수를 넣고 빼면서, 가장 높은 r2 score를 만들어봅시다.
데이터 프로세스 개요
- 머신러닝 모델 하나를 배웠으니 데이터 프로세스에 대해서 알아보자
데이터 프로세스 개요
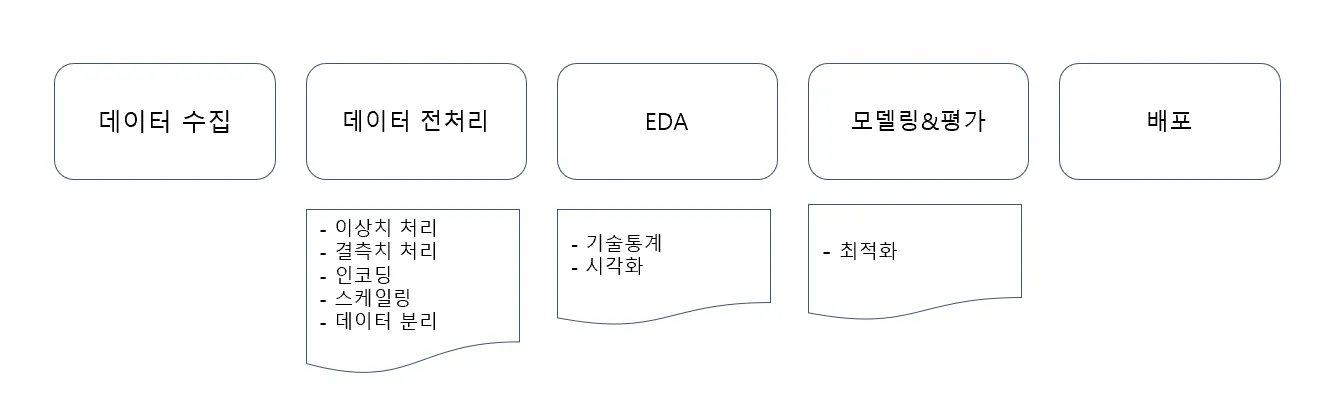
데이터 프로세스는 위와 같아요. 이번 과정에서는 데이터 전처리, 모델링, 평가에 대해서 배울 예정이예요. 또한, 해당 방법론을 적용하기 위한 라이브러리를 연습해볼 예정입니다.
