Q1
숫자 리스트의 평균을 계산하는 방법
배경
전자 상거래 플랫폼에서 고객의 평균 주문을 계산해야 합니다. 이를 위해 숫자 리스트의 평균을 계산하는 방법을 연습합니다.
목표
주어진 숫자 리스트의 평균을 계산하는 함수를 작성하세요.
데이터
numbers: 숫자가 담긴 리스트
# 예시 데이터
numbers = [10, 20, 30, 40, 50]
def calculate_avg(numbers):
# 여기에 코드를 작성하세요
return total_avg
total_avg = calculate_avg(numbers)
print("숫자들의 평균:", total_avg)A1
- 작성 코드
# 예시 데이터
numbers = [10, 20, 30, 40, 50]
def calculate_avg(numbers):
total_avg = sum(numbers)/len(numbers)
return total_avg
total_avg = calculate_avg(numbers)
print("숫자들의 평균:", total_avg)Q2
가장 낮은 기온과 가장 높은 기온을 활용하여 일교차를 함수로 작성
배경
기상청에서는 하루 동안의, 가장 높았던 기온과 가장 낮았던 기온을 확인하고 일교차를 보고하고자 합니다.
목표
하루 동안 기록된 기온 목록을 받아, 가장 낮은 기온과 가장 높은 기온을 활용하여 일교차를 함수를 작성하세요.
데이터
하루 동안 기록된 기온의 리스트
# 예시 데이터
numbers = [10, 20, 30, 40, 50]
def calculate_diff_temperature(numbers):
# 여기에 코드를 작성하세요
return diff_temp
diff_temp= calculate_diff_temperature(numbers)
print("일교차:", diff_temp)A2
- 작성 코드
# 예시 데이터
numbers = [10, 20, 30, 40, 50]
def calculate_diff_temperature(numbers):
diff_temp = max(numbers) - min(numbers)
return diff_temp
diff_temp= calculate_diff_temperature(numbers)
print("일교차:", diff_temp)튜터님 해설
"최대값을 찾는 알고리즘" 외워 두면 좋음numbers = [10, 70, 30, 60, 20] max_n = 0 for n in numbers: if n > max_n: max_n = n print(max_n)
.items()활용이 핵심
Q3
가장 많이 판매된 제품의 이름과 수량을 반환하는 함수를 작성
배경
한 소매점에서는 다양한 제품을 판매하고 있습니다. 매월 판매된 제품들의 목록과 각 제품의 판매 수량이 기록됩니다. 이 데이터를 분석하여 가장 많이 판매된 제품을 찾아내려고 합니다.
목표
제품 명과 판매 수량이 담긴 목록을 받아, 가장 많이 판매된 제품의 이름과 수량을 반환하는 함수를 작성하세요.
데이터
제품 이름과 해당 제품의 판매 수량을 담은 딕셔너리로 구성되어 있음
def find_top_seller(sales_data):
# 여기에 코드를 작성하세요
return top_product
# 테스트
sales_data = {"apple": 50, "orange": 2, "banana" : 30}
print(find_top_seller(sales_data)) # 출력: 'apple'A3
SELF QnA
- 딕셔너리 value의 최대값이 여러 개이면 어떻게 함?
- 고려해서 함수 만들어 보았음
- 대괄호 없이 목록 인쇄
def find_top_seller(sales_data):
max_key= [k for k, v in sales_data.items() if max(sales_data.values()) == v]
max_value = sales_data.get(max_key[0])
key_str = str(max_key)[1:-1]
top_product = f"제품 이름:{key_str}, 수량: {max_value}"
return top_product
sales_data = {"apple": 50, "orange": 2, "banana" : 30, "peach": 50, "cherry": 50}
print(find_top_seller(sales_data))Q4
사칙연산을 수행할 수 있는 프로그램 구현
배경
컴퓨터 과학 수업에서 학생들은 기본적인 프로그래밍 원리를 익히고, 실제 생활에 적용할 수 있는 간단한 프로그램을 만드는 연습을 합니다. 간단한 계산기를 만들어서 사칙연산을 수행할 수 있는 프로그램을 구현하는 것은 기본적인 프로그래밍 실습에 적합합니다.
목표
두 숫자와 연산자를 입력받아, 해당 연산을 수행하고 결과를 반환하는 함수를 작성하세요.
데이터
num1,num2: 숫자 입력값operator: 문자열 형태의 연산자('+', '-', '*', '/')
def simple_calculator(num1, num2, operator):
# 여기에 코드를 작성하세요
pass
# 테스트
print(simple_calculator(10, 5, '+')) # 출력: 15
print(simple_calculator(10, 5, '-')) # 출력: 5
print(simple_calculator(10, 5, '*')) # 출력: 50
print(simple_calculator(10, 0, '/')) # 출력: 'Cannot divide by zero'A4
def simple_calculator(num1, num2, operator):
if operator == '+':
return num1 + num2
elif operator == '-':
return num1 - num2
elif operator == '*':
return num1 * num2
elif operator == '/':
if num2 == 0:
return "Cannot divide by zero"
else:
return num1 / num2
else:
return "숫자와 문자열 형태의 연산자('+', '-', '*', '/')를 입력해 주세요"
# 테스트
print(simple_calculator(10, 5, '+'))
print(simple_calculator(10, 5, '-'))
print(simple_calculator(10, 5, '*'))
print(simple_calculator(10, 5, '/'))
print(simple_calculator(10, 4, '/'))
print(simple_calculator(10, 0, '/'))
print(simple_calculator(10, 2, '%')) 튜터님 해설
try / except를 알고 있으면 더 좋아요
→ python을 더 유용하게 쓸 수 있음!
Q5
이메일 주소가 올바른 형식을 갖추고 있는지 판단하는 프로그램 구현
배경
당신은 회사의 고객 데이터베이스를 관리하고 있습니다. 데이터베이스에 저장된 고객의 이메일 주소가 유효한 형식을 갖추고 있는지 검증하는 작업이 필요합니다.
목표
문자열 형태의 이메일 주소 목록을 분석하여, 각 이메일 주소가 올바른 형식을 갖추고 있는지 판단하는 프로그램을 작성하세요.
데이터
- 이메일 주소는 문자열 리스트로 제공됩니다.
- 올바른 이메일 주소의 형식은 다음과 같습니다:
- 하나의 '@' 기호를 포함해야 합니다.
- '@' 기호 앞에는 하나 이상의 문자가 있어야 합니다.
- '@' 기호 뒤에는 도메인명이 와야 하며, 도메인명은 '.'을 포함한 하나 이상의 문자로 구성되어야 합니다.
요구사항
- 각 이메일 주소가 올바른 형식을 갖추고 있는지 검사합니다. (문자열 메소드 사용)
- 올바른 형식의 이메일 주소인 경우, "유효한 이메일 주소입니다."를 출력합니다.
- 올바르지 않은 형식의 경우, "유효하지 않은 이메일 주소입니다."를 출력합니다.
def validate_emails(email_list):
# 여기에 코드를 작성하세요
pass
# 이메일 목록
email_list = [
"example@example.com",
"wrongemail@com",
"anotherexample.com",
"correct@email.co.uk"
]
# 이메일 유효성 검사 실행
validate_emails(email_list)# 함수 실행 결과
example@example.com 유효한 이메일 주소입니다.
wrongemail@com 유효하지 않은 이메일 주소입니다.
anotherexample.com 유효하지 않은 이메일 주소입니다.
correct@email.co.uk 유효한 이메일 주소입니다.A5
def validate_emails(email_list):
for i in email_list:
if i.count('@') != 1:
print(f'{i} 유효하지 않은 이메일 주소입니다.')
else:
user_id = i.split('@',1)[0]
root_domain = i.split('@',1)[1]
if len(user_id) == 0:
print(f'{i} 유효하지 않은 이메일 주소입니다.')
else:
if root_domain.count('.') == 0:
print(f'{i} 유효하지 않은 이메일 주소입니다.')
else:
domain_2nd = root_domain.split('.', 1)[0]
domain_1st = root_domain.split('.', 1)[1]
if domain_2nd.isalnum() == 0:
print(f'{i} 유효하지 않은 이메일 주소입니다.')
else:
if len(domain_1st) == 0:
print(f'{i} 유효하지 않은 이메일 주소입니다.')
else:
if domain_1st.count('.') > 1:
print(f'{i} 유효하지 않은 이메일 주소입니다.')
else:
print(f'{i} 유효한 이메일 주소입니다.')
email_list = [
"example@example.com",
"wrongemail@com",
"anotherexample.com",
"correct@email.co.uk",
"asdf@@@@molar...",
"asdf@molar...",
"@meow.bowwow",
"aaa@aaa",
"aaa@aaa.",
"aaa@a_aa.",
"aaa@.co.kr",
"aaa@bbb.net"
]
validate_emails(email_list)SELF QnA
- for문을 써서 여러개의 리턴값을 주는 함수를 만들고 싶은데 리턴값이 하나만 나와요. 어떻게 해결할 수 있을까요?
- return 값이 하나만 나오는 이유는, return 을 만나면 값을 반환하면서 함수를 종료시키기 때문
- 그러니 반복을 하지 못하고 바로 함수호출이 종료되는거죵
- 흐름 제어와 관련된 다양한 키워드
- 작성 쿼리가 너무 길고 유효하지 않은 이메일 주소 출력이 계속 반복되어서 다른 방법이 있나 찾아봐야겠음
튜터님 해설
split() 활용이 중요!
packing & unpacking → 파이썬에서만 가능!parts = email.split('@') username, domain = parts # username = parts[0] # domain = parts[1] break와 continue를 잘 활용해야 함 반복과 조건에서 매우 유용 이번 문제에서는 continue를 쓰세요
Q6
숫자 리스트의 평균을 계산하는 방법
배경
당신은 대규모 텍스트 데이터를 분석하는 프로젝트를 진행하고 있습니다. 텍스트 데이터에서 특정 패턴을 찾아내는 작업을 수행해야 합니다. 이번 작업에서는 중복된 문자를 제거하고 각 문자가 한 번씩만 나타나게 하는 프로그램을 작성하는 것이 목표입니다. 하지만 각 문자는 처음 등장한 순서를 유지해야 하며, 추가적으로 각 문자가 등장하는 빈도를 함께 계산해야 합니다.
목표
주어진 문자열에서 중복된 문자를 제거하고, 각 문자가 처음 등장한 순서대로 한 번씩만 나타나게 하며, 각 문자가 등장하는 빈도를 함께 출력하는 프로그램을 작성하세요.
데이터
- 입력 문자열은 알파벳 대문자와 소문자, 숫자, 공백으로 구성될 수 있습니다.
요구사항
- 주어진 문자열에서 중복된 문자를 제거합니다.
- 각 문자가 처음 등장한 순서를 유지합니다.
- 각 문자가 등장하는 빈도를 함께 출력합니다.
- 결과는 (문자, 빈도수) 형태의 튜플 리스트로 반환합니다.
def remove_duplicates_and_count(s):
result_with_frequency = []
# 여기에 코드 작성
return result_with_frequency # 튜플 리스트로 변환# 예시 문자열
input_string = "abracadabra123321"
# 중복 문자 제거 및 빈도수 계산 실행
result = remove_duplicates_and_count(input_string)
print(result)
#실행 결과
[('a', 5), ('b', 2), ('r', 2), ('c', 1), ('d', 1), ('1', 2), ('2', 2), ('3', 2)]A6
def remove_duplicates_and_count(s):
result_with_frequency = []
freq_dict = {}
for char in s:
if char in freq_dict:
freq_dict[char] += 1
else:
freq_dict[char] = 1
for key, value in freq_dict.items():
result_with_frequency.append((key, value))
return result_with_frequency
input_string = "abracadabra123321"
result = remove_duplicates_and_count(input_string)
print(result)튜터님 해설
핵심은 "빈도"입니다.
(문자, 빈도수) 형태 → key, value → 딕셔너리!
.keys()는 빼먹으면 파이썬이 알아서 키에 넣어주는데 .values()는 절대 빼먹으면 안 됩니다~
Q7
경기 동안 각 선수가 이동한 총 누적 거리를 계산하는 프로그램 구현
배경
축구 경기 데이터 분석가로서, 선수들의 위치 데이터를 활용하여 그들의 활동 범위와 이동 효율성을 계산하는 것은 팀 전략을 세우는 데 중요합니다. 선수들의 이동 패턴을 분석하고 이를 통해 그들의 총 누적 이동 거리를 계산하여 선수의 활동량을 평가할 수 있습니다.
목표
선수들의 위치 데이터가 주어졌을 때, 해당 데이터를 분석하여 경기 동안 각 선수가 이동한 총 누적 거리를 계산하는 프로그램을 작성하세요.
데이터
- 위치 데이터는 선수의 이름과 그에 따른 위치 좌표의 리스트를 포함하는 딕셔너리 형태로 제공됩니다. 각 좌표는
(x, y)튜플로 표현됩니다. - 선수는 경기 동안 여러 번 위치가 변경될 수 있으며, 각 위치는 이전 위치에서의 이동 거리를 기록합니다.
요구사항
- 유클리드 거리 공식을 사용하여 각 위치 변경 시 이동 거리를 계산합니다.
- 각 선수별로 경기 동안 이동한 총 누적 거리를 출력합니다.
def calculate_total_distances(player_positions):
# 여기에 코드를 작성하세요
return# 선수별 위치 데이터
player_positions = {
"John Doe": [(0, 0), (1, 1), (2, 2), (5, 5)],
"Jane Smith": [(2, 2), (3, 8), (6, 8)],
"Mike Brown": [(0, 0), (3, 4), (6, 8)]
}
# 총 누적 이동 거리 계산 실행
calculate_total_distances(player_positions)
#실행 결과
John Doe의 총 누적 이동 거리: 7.07 미터
Jane Smith의 총 누적 이동 거리: 9.08 미터
Mike Brown의 총 누적 이동 거리: 10.00 미터A7
def calculate_total_distances(player_positions):
player_name = player_positions.keys()
positions = player_positions.values()
player_distance = []
for i in positions:
distance_data = []
for j in range(len(i)-1):
route = ((i[j+1][0] - i[j][0])**2 + (i[j+1][1] - i[j][1])**2)**(1/2)
distance_data.append(route)
player_distance.append(sum(distance_data))
result = dict(zip(player_name, player_distance))
for key, value in result.items():
print(f'{key}의 총 누적 이동 거리: {round(value, 2)}미터')SELF QnA
- 유클리드 거리 공식?
- 유클리디안 거리 ( Euclidean Distance )
- n차원의 공간에서 두 점간의 거리를 알아내는 공식
- "L2 Distance"라고도 함
- 참고: 두 점 사이의 거리
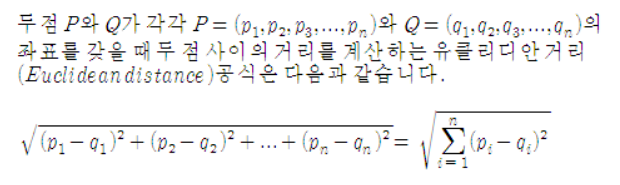
Q8
언어를 확인하여 암호를 해독하는 프로그램 구현
배경
르탄이는 팀스파르타의 대표 캐릭터 입니다 :)
어느날, 르탄이가 당신의 길을 막고 암호를 말할테니 이 암호를 풀어야 길을 비켜준다고 합니다.
르탄이가 알려주는 암호는 한글과 영어로 쓰여있는 숫자들을 나열한 것인데 이를 알려주면 여러분이 아라비아 숫자 형태로 바꾸어서 르탄이한테 다시 알려주어야 합니다.
또한 숫자로 바꾸기 전에 한글로 이루어진 숫자가 몇개인지, 영어로 이루어진 숫자가 몇개인지를 함께 알려주어야 합니다.
목표
이렇게 영어와 한글이 섞인 숫자들이 문자열 형태로 주어집니다. 이를 아라비아 숫자형태로 바꾸어서 출력하고, 한글로 적인 숫자의 개수, 영어로 적인 숫자의 개수를 차례로 반환하는 함수를 완성해주세요!
데이터
참고로, 암호로 주어질 수 있는 영어숫자와 한글숫자의 범위는 아래와 같습니다.
- 영어숫자의 범위 : zero ~ nine
- 한글숫자의 범위 : 영 ~ 구
또한 입출력 값은 다음의 범위를 가집니다. - 입력으로 주어지는 문자의 길이는 1에서 4까지 가질 수 있습니다.
- 출력값으로 나올 수 있는 정수는 0~9999 입니다
def password_decryptor(password_list):
# 여기에 코드를 작성하세요
return# 암호 목록
password_list = [
"삼five이사",
"zero오six칠",
"foureight삼구",
"이sevenfour팔",
"nine일이삼"
]
# 실행 결과
[삼five이사]에 대한 암호는 [3524]로, 한글은 [3]개, 영어는 [1]개 입력되었습니다.
[zero오six칠]에 대한 암호는 [0567]로, 한글은 [2]개, 영어는 [2]개 입력되었습니다.
[foureight삼구]에 대한 암호는 [4839]로, 한글은 [2]개, 영어는 [2]개 입력되었습니다.
[이sevenfour팔]에 대한 암호는 [2748]로, 한글은 [2]개, 영어는 [2]개 입력되었습니다.
[nine일이삼]에 대한 암호는 [9123]로, 한글은 [3]개, 영어는 [1]개 입력되었습니다.A8
def password_decryptor(password_list):
unit_kor = ['영', '일', '이', '삼', '사', '오', '육', '칠', '팔', '구']
unit_eng = ['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine']
decode_list_kor = []
cnt_num_kor = []
decode_list = []
cnt_num_eng = []
for i in password_list:
cnt_kor = 0
for j in range(len(i)):
if i[j] in unit_kor:
cnt_kor += 1
i = i.replace(i[j], str(unit_kor.index(i[j])))
decode_list_kor.append(i)
cnt_num_kor.append(cnt_kor)
for e in decode_list_kor:
cnt_eng = 0
for eng in unit_eng:
if eng in e:
cnt_eng += 1
e = e.replace(eng, str(unit_eng.index(eng)))
decode_list.append(e)
cnt_num_eng.append(cnt_eng)
for n in range(len(password_list)):
print(f'[{password_list[n]}]에 대한 암호는 [{decode_list[n]}]로, 한글은 [{cnt_num_kor[n]}]개, 영어는 [{cnt_num_eng[n]}]개 입력되었습니다.')
password_list = [
"삼five이사",
"zero오six칠",
"foureight삼구",
"이sevenfour팔",
"nine일이삼"
]SELF QnA
