문제 1
테이블 설명
students 테이블은 학생에 대한 정보를 담고 있습니다.
테이블 구조와 각 컬럼의 의미는 다음과 같습니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| STUDENT_ID | INT | 학생 ID (PK) |
| NAME | VARCHAR | 학생 이름 |
| GENDER | CHAR(1) | 성별 (M/F) |
| AGE | INT | 나이 |
| SCORE | DECIMAL | 시험 점수 |
분석해야 할 내용
각 성별(GENDER) 기준으로 시험 점수가 높은 상위 3명의
학생 성별, 이름과 점수를 반환하는 SQL 문을 작성하세요.
두 학생이 동점일 경우, 나이가 많은 학생을 우선합니다.
결과는 성별(GENDER) 오름차순, 순위 오름차순으로 정렬하여 출력하세요.
출력 값 예시
students테이블이 다음과 같다면 :
| STUDENT_ID | NAME | GENDER | AGE | SCORE |
|---|---|---|---|---|
| 1 | Alice | F | 20 | 95 |
| 2 | Bob | M | 25 | 90 |
| 3 | Charlie | M | 23 | 92 |
| 4 | Diana | F | 19 | 85 |
| 5 | Eve | F | 22 | 93 |
| 6 | Frank | M | 22 | 90 |
| 7 | Grace | F | 21 | 89 |
- 성별이 F인 경우, 시험 점수가 높은 상위 3명은 Alice(95), Eve(93), Grace(89)입니다.
- 성별이 M인 경우, 시험 점수가 높은 상위 3명은 Charlie(92), Bob(90), Frank(90)입니다.
- Bob 과 Frank는 동점이지만, Bob이 나이가 더 많아 먼저 출력됩니다.
다음과 같이 결과 출력이 되어야 합니다.
(해당 테이블은 예시이며, 실제 정답과 다를 수 있습니다.)
| GENDER | NAME | SCORE |
|---|---|---|
| F | Alice | 95 |
| F | Eve | 93 |
| F | Grace | 89 |
| M | Charlie | 92 |
| M | Bob | 90 |
| M | Frank | 90 |
내가 작성한 쿼리
/*
문제 1
성별 기준 시험 점수 높은 상위 3명의 성별, 이름, 점수
동점자는 나이 우선으로 → 나이 DESC
결과는 성별 asc, 순위 asc
*/
WITH students_rank AS (
SELECT
, name
, score
, RANK() OVER (PARTITION BY gender ORDER BY score DESC, age DESC) AS rnk
FROM
students
)
SELECT
gender
, name
, score
FROM
students_rank
WHERE
rnk <= 3
ORDER BY
gender
, rnk
;→ 제출한 코드에는 age라고 잘못 적어서 틀렸음
해설
with student_ranks as (
select *, rank() over (partition by gender order by score desc, age desc) student_rank
from qcc.students
)
select GENDER, NAME, SCORE
from student_ranks
where student_rank <= 3
order by gender, student_rank RANK나ROW_NUMBER를 쓰면 됩니다!- ROW_NUMBER: 고유 순위 출력
- RANK, DENSE_RANK: 동점이면 둘 다 공동 X위
1) 테이블 확인
SELECT
*
FROM
qcc.students
;2) rank로 공동 순위 있는지 확인
SELECT
*
, rank() OVER (
PARTITION BY GENDER
ORDER BY SCORE DESC
) AS rn
FROM
qcc.students
;3) order by에 age 추가
SELECT
*
, rank() OVER (
PARTITION BY GENDER
ORDER BY
SCORE DESC
, AGE DESC
) AS rn
FROM
qcc.students
;4) 확인한 내용 cte로 넣고 필요한 내용만 호출
WITH student_rank AS (
SELECT
*
, rank() OVER (
PARTITION BY GENDER
ORDER BY
SCORE DESC
, AGE DESC
) AS rn
FROM
qcc.students
)
SELECT
GENDER
, NAME
, SCORE
FROM
student_rank
WHERE
rn <= 3
ORDER BY
GENDER
, rn
;문제 2
테이블 설명
books 테이블은 도서에 대한 정보를 담고 있습니다.
테이블 구조와 각 컬럼의 의미는 다음과 같습니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| ID | INT | 도서 ID (PK) |
| TITLE | VARCHAR(255) | 도서 제목 |
| AUTHOR | VARCHAR(255) | 저자 |
| PRICE | DECIMAL(8,2) | 가격 |
| COPIES_IN_STOCK | INT | 재고 수량 |
book_orders 테이블은 주문에 대한 정보를 담고 있습니다.
테이블 구조와 각 컬럼의 의미는 다음과 같습니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| ID | INT | 주문 ID (PK) |
| CUSTOMER_ID | INT | 고객 ID |
| ORDER_DATE | DATETIME | 주문 날짜 |
| DUE_DATE | DATETIME | 결제 기한 |
| PAID_DATE | DATETIME | 결제 완료 날짜 |
book_order_items 테이블은 주문 항목에 대한 정보를 담고 있습니다.
테이블 구조와 각 컬럼의 의미는 다음과 같습니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| ID | INT | 주문 항목 ID (PK) |
| ORDER_ID | INT | 주문 ID (FK) |
| BOOK_ID | INT | 도서 ID (FK) |
| QUANTITY | INT | 수량 |
| PRICE | DECIMAL(8,2) | 개별 가격 |
| LINE_TOTAL | DECIMAL(8,2) | 총 가격 (수량 * 가격) |
분석해야 할 내용
모든 도서에 대해 도서 제목(TITLE)과 다음 정보를 반환하는 SQL 쿼리를 작성하세요 :
- 미결제 금액 (
DUE): 아직 결제되지 않은 총 금액을 계산합니다.- 계산 기준 : PAID_DATE 가 NULL인 주문 항목의 총 금액 합계
- 결과는 반올림하여 정수로 반환하세요.
- 결제 완료 금액 (
PAID): 결제 완료된 총 금액- 계산 기준 : PAID_DATE 가 NULL이 아닌 주문 항목의 총 금액 합계
- 결과는 반올림하여 정수로 반환하세요.
결과는 도서 제목(TITLE)을 기준으로 오름차순 정렬하세요.
출력 값 예시
books,book_orders,book_order_items테이블이 다음과 같다면:
books
| ID | TITLE | AUTHOR | PRICE | COPIES_IN_STOCK |
|---|---|---|---|---|
| 1 | The Great Gatsby | F. Scott | 10.00 | 20 |
| 2 | To Kill a Mockingbird | Harper Lee | 12.00 | 15 |
| 3 | 1984 | George Orwell | 15.00 | 30 |
book_orders
| ID | CUSTOMER_ID | ORDER_DATE | DUE_DATE | PAID_DATE |
|---|---|---|---|---|
| 1 | 101 | 2023-01-01 | 2023-01-07 | 2023-01-05 |
| 2 | 102 | 2023-01-10 | 2023-01-15 | NULL |
| 3 | 103 | 2023-01-20 | 2023-01-25 | NULL |
| 4 | 104 | 2023-01-30 | 2023-02-05 | NULL |
book_order_items
| ID | ORDER_ID | BOOK_ID | QUANTITY | PRICE | LINE_TOTAL |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 2 | 10.00 | 20.00 |
| 2 | 2 | 1 | 1 | 10.00 | 10.00 |
| 3 | 3 | 2 | 3 | 12.00 | 36.00 |
| 4 | 4 | 3 | 1 | 15.00 | 15.00 |
- The Great Gatsby:
- 주문 1: 결제 완료 (PAID_DATE가 존재하므로 PAID = $20)
- 주문 2: 미결제 (PAID_DATE가 NULL이므로 DUE = $10)
- To Kill a Mockingbird:
- 주문 3: 미결제 (PAID_DATE가 NULL이므로 DUE = $36)
- 결제 금액 없음 (PAID = $0)
- 1984
- 주문 4: 미결제 (PAID_DATE가 NULL이므로 DUE = $15)
- 결제 금액 없음 (PAID = $0)
다음과 같이 결과 출력이 되어야 합니다.
(해당 테이블은 예시이며, 실제 정답과 다를 수 있습니다.)
| TITLE | DUE | PAID |
|---|---|---|
| 1984 | 15 | 0 |
| The Great Gatsby | 10 | 20 |
| To Kill a Mockingbird | 36 | 0 |
내가 작성한 쿼리
/*
문제 2
출력해야 하는 것: 도서 제목, 미결제 금액, 결제 완료 금액
결과는 반올림하여 정수로 반환, 도서 제목 기준 asc
*/
WITH book_orders_type AS (
SELECT
id
, CASE
WHEN paid_date IS NULL THEN 'DUE'
ELSE 'PAID'
END AS type
FROM
book_orders
)
SELECT
b.title
, ROUND(SUM(IF(t.TYPE = 'DUE', i.line_total, 0))) AS due
, ROUND(SUM(IF(t.TYPE = 'PAID', i.line_total, 0))) AS paid
FROM
books b
LEFT JOIN book_order_items i
ON i.book_id = b.id
LEFT JOIN book_orders_type t
ON i.order_id = t.id
GROUP BY
b.title
ORDER BY
b.title
;→ 제출한 코드에는
1. IF 안에 i.line_total 써야 하는데 b.price라 썼음
2. books에 LEFT JOIN 해야 하는데 book_order_items에 INNER JOIN 했음
해설
SELECT
b.TITLE,
ROUND(COALESCE(SUM((o.PAID_DATE IS NULL) * oi.LINE_TOTAL), 0), 0) AS DUE,
ROUND(COALESCE(SUM((o.PAID_DATE IS NOT NULL) * oi.LINE_TOTAL), 0), 0) AS PAID
FROM qcc.books b
LEFT JOIN qcc.book_order_items oi ON b.ID = oi.BOOK_ID
LEFT JOIN qcc.book_orders o ON oi.ORDER_ID = o.ID
GROUP BY b.ID, b.TITLE
ORDER BY b.TITLE ASC;- Point
- 책이 100권 있으니까 결과도 100건 있어야 함!
- 모든 책에 대한 결과값을 얻길 원하므로 books 기준으로 모두 "left join"하면 됨
- 책이 100권 있으니까 결과도 100건 있어야 함!
1) books를 왼쪽에 두고 나머지 테이블을 다 left join하기
SELECT
b.*
, i.*
, o.*
FROM
qcc.books b
LEFT JOIN qcc.book_order_items i
ON b.ID = i.BOOK_ID
LEFT JOIN qcc.book_orders o
ON i.ORDER_ID = o.ID
;2) 몇 개가 'DUE'고 몇 개가 'PAID'인지 확인하기
SELECT
sum(
CASE
WHEN PAID_DATE IS NULL THEN 1 ELSE 0
END
) AS paid
, sum(
CASE
WHEN PAID_DATE IS NOT NULL THEN 1 ELSE 0
END
) AS not_paid
FROM
qcc.book_orders 3) 확인한 logic을 적용
SELECT
b.TITLE
, round(COALESCE(sum(
CASE
WHEN o.PAID_DATE IS NULL THEN i.LINE_TOTAL
END
), 0), 0) AS due
, round(COALESCE(sum(
CASE
WHEN o.PAID_DATE IS NOT NULL THEN i.LINE_TOTAL
END
), 0), 0) AS paid
FROM
qcc.books b
LEFT JOIN qcc.book_order_items i
ON b.ID = i.BOOK_ID
LEFT JOIN qcc.book_orders o
ON i.ORDER_ID = o.ID
GROUP BY
b.TITLE
ORDER BY
b.TITLE
;문제 3
테이블 설명
customer_orders 테이블은 고객의 주문 데이터를 포함하고 있습니다.
테이블 구조와 각 컬럼의 의미는 다음과 같습니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| ORDER_ID | INT | 주문 ID (PK) |
| CUSTOMER_ID | INT | 고객 ID |
| ORDER_DATE | DATE | 주문 날짜 |
| ORDER_AMOUNT | DECIMAL(10,2) | 주문 금액 |
분석해야 할 내용
고객의 첫 주문 월을 기준으로 Cohort 그룹을 만들고,
각 Cohort 그룹에서 시간이 지남에 따라 활성 사용자 수를 계산하는 SQL 문을 작성하세요.
USER_COUNT_1_MONTH_LATER ~ USER_COUNT_12_MONTH_LATER 까지 계산해야 합니다.
- 각 Cohort 그룹에 대해 1개월 후부터 12개월 후까지의 활성 사용자 수를 추적합니다
- Cohort 정의: FIRST_ORDER_MONTH
- First Order Month: 각 고객의 첫 주문이 발생한 월을 의미합니다.
- COHORT_USER_COUNT:
- 각 Cohort 그룹의 [활성 사용자] 수를 계산합니다.
- [활성 사용자]는 주문을 한 고객을 의미합니다.
- 각 Cohort 그룹의 [활성 사용자] 수를 계산합니다.
- USER_COUNT_X_MONTHS_LATER:
- 해당 COHORT가 X개월 이후에 주문한 고객 수를 계산합니다.
- 예:
- FIRST_ORDER_MONTH = 2023-01
- COHORT_USER_COUNT = 50
- USER_COUNT_1_MONTH_LATER = 20
- USER_COUNT_2_MONTH_LATER = 33
- 2023-01 에 첫 주문을 한 고객이 50명,
이들 중 1개월 뒤 주문한 고객이 20명, 2개월 뒤 주문한 고객이 33명
출력 값 예시
customer_orders 테이블이 다음과 같다면 :
| ORDER_ID | CUSTOMER_ID | ORDER_DATE | ORDER_AMOUNT |
|---|---|---|---|
| 1 | 101 | 1/1/23 | 120.5 |
| 2 | 102 | 1/15/23 | 200 |
| 3 | 101 | 2/10/23 | 100 |
| 4 | 103 | 2/5/23 | 75 |
| 5 | 104 | 3/1/23 | 50 |
| 6 | 102 | 3/12/23 | 150 |
Cohort 2023-01 :
- COHORT_USER_COUNT: 2명 (CUSTOMER_ID 101, 102).
- USER_COUNT_1_MONTH_LATER: 1명 (CUSTOMER_ID 101이 2023-02에 다시 주문)
- USER_COUNT_2_MONTH_LATER: 1명 (CUSTOMER_ID 102가 2023-03에 다시 주문)
Cohort 2023-02 :
- COHORT_USER_COUNT: 1명 (CUSTOMER_ID 103)
- USER_COUNT_1_MONTH_LATER: 1명 (CUSTOMER_ID 103이 2023-03에 다시 주문)
- USER_COUNT_2_MONTH_LATER: 0명 (2023-04에 재구매 없음)
Cohort 2023-03 :
- COHORT_USER_COUNT: 1명 (CUSTOMER_ID 104)
- 이후 활동 없음
다음과 같이 결과 출력이 되어야 합니다.
(해당 테이블은 예시이며, 실제 정답과 다를 수 있습니다.)
| FIRST_ORDER_MONTH | COHORT_USER_COUNT | USER_COUNT_1_MONTH_LATER | USER_COUNT_2_MONTH_LATER | … | USER_COUNT_12_MONTH_LATER |
|---|---|---|---|---|---|
| 2023-01 | 2 | 1 | 1 | … | 0 |
| 2023-02 | 1 | 1 | 0 | … | 0 |
| 2023-03 | 1 | 0 | 0 | … | 0 |
내가 작성한 쿼리
/*
문제 3
customer_orders 테이블
1. 코호트 그룹 만들기
2. 시간이 지남에 따라 활성 사용자 수를 계산
→ 각 Cohort 그룹에 대해 1개월 후부터 12개월 후까지의 활성 사용자 수를 추적
(USER_COUNT_1_MONTH_LATER ~ USER_COUNT_12_MONTH_LATER 까지 계산)
*/
WITH firstOrder AS (
SELECT
customer_id
, MIN(order_date) AS first_order_date
FROM
customer_orders
GROUP BY
customer_id
)
, day_cnt AS (
SELECT
o.order_date
, f.first_order_date
, COUNT(DISTINCT o.customer_id) AS user_cnt
FROM
customer_orders o
JOIN firstOrder f
USING(customer_id)
GROUP BY
o.order_date
, f.first_order_date
)
SELECT
DATE_FORMAT(first_order_date, '%Y-%m') AS first_order_month
, SUM(IF(DATE_FORMAT(first_order_date, '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS cohort_user_count
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 1 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_1_month_later
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 2 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_2_month_later
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 3 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_3_month_later
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 4 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_4_month_later
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 5 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_5_month_later
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 6 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_6_month_later
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 7 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_7_month_later
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 8 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_8_month_later
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 9 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_9_month_later
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 10 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_10_month_later
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 11 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_11_month_later
, SUM(IF(DATE_FORMAT(DATE_ADD(first_order_date, INTERVAL 12 MONTH), '%y%m') = DATE_FORMAT(order_date, '%y%m'), user_cnt, 0)) AS user_count_12_month_later
FROM
day_cnt
GROUP BY
first_order_month
ORDER BY
first_order_month
;→ 제출 10초 남아서 못 냈음
- 해설과 결과가 조금 다르게 나오는데 왜지?
- 나는 first order date를 그대로 써서 문제가 생긴 것 같음(해설 테이블보다 cohort_user_count가 200건 더 많음)
- 2013년 7월 데이터부터 2014년 6월 데이터까지가 증가되어 있음… 왜일까?
→ 일까지 넣어 계산해서 그런 것 같음! 달 기준으로 볼 때는 튜터님 풀이처럼 전체 데이터의 '일' 날짜를 고정시켜야 함!
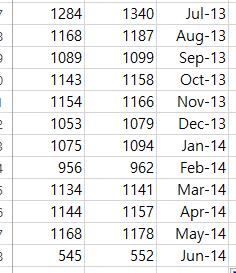
- 2013년 7월 데이터부터 2014년 6월 데이터까지가 증가되어 있음… 왜일까?
- 나는 first order date를 그대로 써서 문제가 생긴 것 같음(해설 테이블보다 cohort_user_count가 200건 더 많음)
해설
WITH cohort AS (
SELECT
CUSTOMER_ID,
DATE(DATE_FORMAT(MIN(ORDER_DATE), '%Y-%m-01')) AS first_order_month
FROM customer_orders
GROUP BY CUSTOMER_ID
), active_orders AS (
SELECT
o.CUSTOMER_ID,
c.first_order_month,
DATE(DATE_FORMAT(o.ORDER_DATE, '%Y-%m-01')) AS active_month
FROM customer_orders o
JOIN cohort c
ON o.CUSTOMER_ID = c.CUSTOMER_ID
), cohort_counts AS (
SELECT
first_order_month,
active_month,
COUNT(DISTINCT CUSTOMER_ID) AS user_count
FROM active_orders
GROUP BY first_order_month, active_month
)
SELECT
DATE_FORMAT(first_order_month, '%Y-%m') FIRST_ORDER_MONTH,
COALESCE(SUM(CASE WHEN active_month = first_order_month THEN user_count ELSE 0 END), 0) AS COHORT_USER_COUNT,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 1 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_1_MONTH_LATER,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 2 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_2_MONTH_LATER,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 3 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_3_MONTH_LATER,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 4 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_4_MONTH_LATER,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 5 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_5_MONTH_LATER,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 6 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_6_MONTH_LATER,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 7 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_7_MONTH_LATER,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 8 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_8_MONTH_LATER,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 9 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_9_MONTH_LATER,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 10 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_10_MONTH_LATER,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 11 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_11_MONTH_LATER,
COALESCE(SUM(CASE WHEN active_month = DATE_ADD(first_order_month, INTERVAL 12 MONTH) THEN user_count ELSE 0 END), 0) AS USER_COUNT_12_MONTH_LATER
FROM cohort_counts
GROUP BY first_order_month
ORDER BY first_order_month;1) 전체 테이블 확인
select *
from qcc.customer_orders2) first order month 찾기
- Point
- 모든 데이트를 1일을 기준으로 통일시키기
- 월별 데이터를 보고 싶은 거니까 '일'은 통일시켜야 데이터의 차이 등을 구할 수 있음
- 모든 데이트를 1일을 기준으로 통일시키기
select CUSTOMER_ID, date_format(min(ORDER_DATE), '%Y-%m-01') first_order_month
from qcc.customer_orders
group by 13) order_date도 month로 통일
with cohort as (
select CUSTOMER_ID, date_format(min(ORDER_DATE), '%Y-%m-01') first_order_month
from qcc.customer_orders
group by 1
)
select ch.first_order_month, date_format(co.ORDER_DATE, '%Y-%m-01') order_month, co.CUSTOMER_ID
from qcc.customer_orders co
join cohort ch
on co.CUSTOMER_ID = ch.CUSTOMER_ID4) first_order_month, order_month로 집계 진행: user_count
with cohort as (
select CUSTOMER_ID, date_format(min(ORDER_DATE), '%Y-%m-01') first_order_month
from qcc.customer_orders
group by 1
)
, order_month as (
select ch.first_order_month, date_format(co.ORDER_DATE, '%Y-%m-01') order_month, co.CUSTOMER_ID
from qcc.customer_orders co
join cohort ch
on co.CUSTOMER_ID = ch.CUSTOMER_ID
)
select first_order_month, orders_month, count(distinct CUSTOMER_ID) user_count
from order_month
group by 1, 25) 최종
with cohort as (
select CUSTOMER_ID, date_format(min(ORDER_DATE), '%Y-%m-01') first_order_month
from qcc.customer_orders
group by 1
)
, order_month as (
select ch.first_order_month, date_format(co.ORDER_DATE, '%Y-%m-01') order_month, co.CUSTOMER_ID
from qcc.customer_orders co
join cohort ch
on co.CUSTOMER_ID = ch.CUSTOMER_ID
)
, cohort_counts as (
select first_order_month, orders_month, count(distinct CUSTOMER_ID) user_count
from order_month
group by 1, 2
)
select first_order_month
, coalesce(sum(case when first_order_month = order_month then user_count else 0 end), 0) COHORT_USER_COUNT
, coalesce(sum(case when date_add(first_order_month, interval 1 month) = order_month then user_count else 0 end), 0) USER_COUNT_1_MONTH_LATER
, coalesce(sum(case when date_add(first_order_month, interval 2 month) = order_month then user_count else 0 end), 0) USER_COUNT_2_MONTH_LATER
, coalesce(sum(case when date_add(first_order_month, interval 3 month) = order_month then user_count else 0 end), 0) USER_COUNT_3_MONTH_LATER
, coalesce(sum(case when date_add(first_order_month, interval 4 month) = order_month then user_count else 0 end), 0) USER_COUNT_4_MONTH_LATER
, coalesce(sum(case when date_add(first_order_month, interval 5 month) = order_month then user_count else 0 end), 0) USER_COUNT_5_MONTH_LATER
, coalesce(sum(case when date_add(first_order_month, interval 6 month) = order_month then user_count else 0 end), 0) USER_COUNT_6_MONTH_LATER
, coalesce(sum(case when date_add(first_order_month, interval 7 month) = order_month then user_count else 0 end), 0) USER_COUNT_7_MONTH_LATER
, coalesce(sum(case when date_add(first_order_month, interval 8 month) = order_month then user_count else 0 end), 0) USER_COUNT_8_MONTH_LATER
, coalesce(sum(case when date_add(first_order_month, interval 9 month) = order_month then user_count else 0 end), 0) USER_COUNT_9_MONTH_LATER
, coalesce(sum(case when date_add(first_order_month, interval 10 month) = order_month then user_count else 0 end), 0) USER_COUNT_10_MONTH_LATER
, coalesce(sum(case when date_add(first_order_month, interval 11 month) = order_month then user_count else 0 end), 0) USER_COUNT_11_MONTH_LATER
, coalesce(sum(case when date_add(first_order_month, interval 12 month) = order_month then user_count else 0 end), 0) USER_COUNT_12_MONTH_LATER
from cohort_counts해설 QnA
-
근데 어디까지 잔존하는 줄 알고 넣어야 하는 건가용? First order month 맨 끝까지??
- 유저별로 최초 구매일자를 구하니까, 그거 기준으로 12달이 나와서 따로 고려하지 않아도 다 나올겁니다
-
TIMESTAMPDIFF는 첫 번째 인자로 받는 단위로, 2개 날짜 간의 차를 계산하는 함수입니다. 입력 시간값의 형식이 연-월-일로 입력해야 에러없이 계산되더라구요
-
윈도우 함수 아무거나 상관 없죠?
- 문제 1에 한해서는 아무 문제 없습니다. (order by 두 개 걸면 결과가 다 동일함)
-
limit을 써도 되나요?
- 데이터를 보고 차이가 없다면 상관 없음
- 하지만 데이터 자체의 특성이 다르다면 상관이 있겠죠?
-
sum은 null인 값을 skip하기 때문에 굳이 'else 0' 안 써도 됩니다.
