목표
- SQL 테이블 결합
- UNION 함수를 숙지하고 활용
- JOIN 함수를 숙지하고 활용
- UNION 과 JOIN 함수의 차이점을 이해하고 응용
- 세로로 붙이면 UNION, 가로로 붙이면 JOIN
UNION
- 테이블 수직 결합
1월과 2월 데이터가 다른 테이블에 있을 때
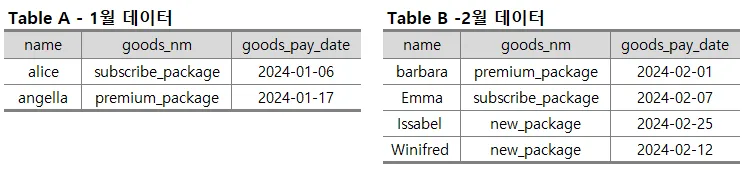
- UNION 또는 UNON ALL을 사용하면 두 개의 테이블이 아래와 같이 수직결합됨
- 두 개 이상의 테이블도 결합할 수 있음
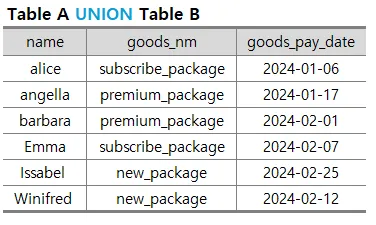
- 두 개 이상의 테이블도 결합할 수 있음
# union/union all 기본구조
# 컬럼 순서가 같고, 그 형식이 같아야 함
select
컬럼1
, 컬럼2
, 컬럼3
...
from
테이블명1
UNION (ALL) #수직결합 명시
select
컬럼1
, 컬럼2
, 컬럼3
...
from
테이블명2 - UNION을 이용한 두 테이블 결합 시 아래 두 가지 조건을 모두 만족해야 함
- 열의 개수와 순서가 모든 쿼리에서 동일해야 함
select 컬럼1, 컬럼2
from 테이블1
UNION
select 컬럼1, 컬럼2 -- 컬럼2, 컬럼1 순서로 적으면 합칠 수 없음
from 테이블2- 데이터의 형식이 일치해야 함(이름이 같아야 함)
select 이름, 성명
from 테이블1
UNION
select 이름이름 AS 이름, 성명 -- 이름이름, 성명이면 합칠 수 없음
from 테이블2→ 위 두 가지의 조건을 만족할 경우 UNION과 UNION ALL은 2개 이상의 테이블도 결합할 수 있음
→ 테이블이 완벽하게 똑같이 생길 필요는 없음(공통 컬럼만 골라서 하면 됨)
두 테이블에 중복되는 데이터가 있을 때
-
1월 매출 테이블과 2월 매출 테이블을 결합한다고 가정했을 때 아래와 같은 두가지 경우를 생각해 볼 수 있음
- 🔥1, 2월 모두 결제한 고객이 필요한 경우
- 🔥1, 2월 중 한번이라도 결제한 고객이 필요한 경우
-
UNION은 중복되는 데이터를 제거하여 하나의 결과값만을 OUTPUT 으로 반환
-
반면, UNION ALL 은 중복되는 데이터를 모두 표기해준다는 차이점이 있음
| 구분 | UNION | UNION ALL |
|---|---|---|
| 공통점 | 두 테이블을 수직 결합 | 두 테이블을 수직 결합 |
| 차이점 | 중복 제거하고 표기 | 중복을 제거하지 않고 표기 |
| 중복된 행을 하나로 표기 | UNION ALL은 모두 표현 |
JOIN
- 원하는 데이터를 추출하기 위해 두 개(또는 두 개 이상) 테이블을 결합하는 역할을 수행
조인의 첫번째 단계: 공통컬럼 찾기
-
공통컬럼 = 두 테이블에서 공통으로 존재하는 컬럼(열)
-
테이블과 테이블의 연결 고리로 작용
-
공통 컬럼의 이름이 달라도 JOIN 가능
-
공통 컬럼이 없다면, JOIN을 할 수 없음
-
공통 컬럼은 여러 개도 가능
- 테이블A: 이름컬럼과 나이컬럼
- 테이블B: 이름컬럼과 나이컬럼과 국가컬럼
공통컬럼: 이름, 나이
→ 공통컬럼 조건 1개 사용: 이름이 같은 경우를 확인하고 싶은 경우
→ 공통컬럼 조건 2개 사용: 이름과 나이가 같은 경우를 확인하고 싶은 경우
-
공통 컬럼이 꼭 SELECT절 뒤에 위치해야 하는 건 아님
- 두 개 또는 그 이상의 테이블을 연결하기 위한 조건으로 공통컬럼이 작용하므로 공통 컬럼이 select절에 나올 필요는 없음(공통 컬럼을 꼭 사용해야 하는 건 아님 → 값을 고르는 조건의 하나일 뿐)
- 복습: SQL이 내부적으로 인지하고 작동하는 순서
- FROM → ON → JOIN → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY
# JOIN 기본 구문
# 공통컬럼이 1개인 경우
select 컬럼1, 컬럼2..
from 테이블 a
join # join의 종류는 아래에서 설명할 예정입니다.
select 컬럼1, 컬럼2..
from 테이블 b
on a.공통컬럼=b.공통컬럼
--------------------------------------------------------------------------
# JOIN 기본 구문
# 공통컬럼이 2개 이상인 경우
select 컬럼1, 컬럼2..
from 테이블 as a
join # join의 종류는 아래에서 설명할 예정입니다.
select 컬럼1, 컬럼2..
from 테이블 as b
on a.공통컬럼=b.공통컬럼 and a.공통컬럼2=b.공통컬럼2 조인의 두번째 단계: 공통컬럼 관계찾기(PK와 FK 찾기)
- 공통컬럼을 찾았다면 두 번째로 어떤 공통컬럼이 기준이 되고, 어떤 공통컬럼이 종속되어있는지 파악해야 함 → PK(Primary key), FK(Foreign key)
- 이러한 관계들은 데이터분석가가 설정하는 것이 아닌, 데이터 수집/저장 단계에서 데이터 엔지니어가 정함
- 따라서 이렇게 명시되어 있는 관계를 잘 파악하는 것이 중요
| 구분 | 상세 |
|---|---|
| PK | • 기본키라고 부르며, NULL 일 수 없고, 유일한 값을 가짐 |
| • PK 컬럼은 모든 데이터를 식별하는 기준이 되는 컬럼 | |
| • 테이블 당 하나의 기본키만 가질 수 있음 | |
| FK | • FK 는 외래키라고 부르며, 다른 테이블의 PK 와 연결되어 테이블 간 관계를 나타내주는 컬럼 |
| • 기준이 되는 컬럼(PK)을 확인하기 위한 연결컬럼의 역할을 함 |
-
관계도: ERD(Entity Relationship Diagram)
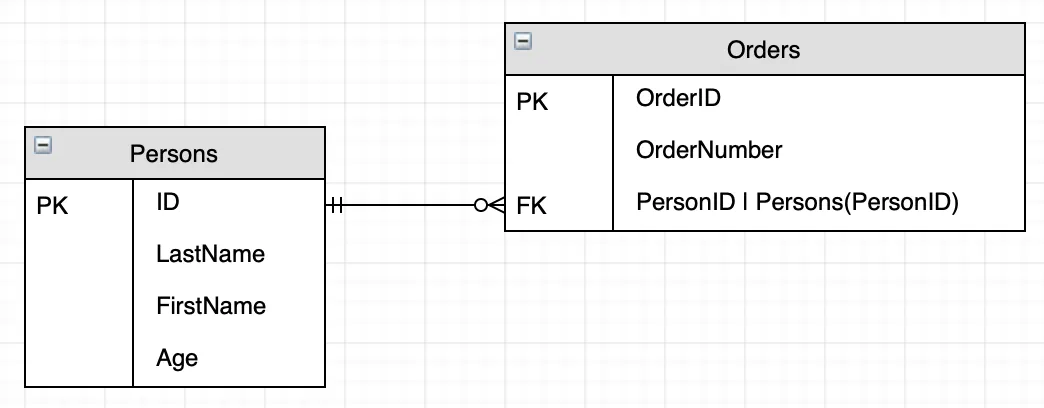
- ERD 내 기호들을 통해서, 각 테이블이 어떻게 대응되는 지 파악할 수 있음
- Mapping Cardinality
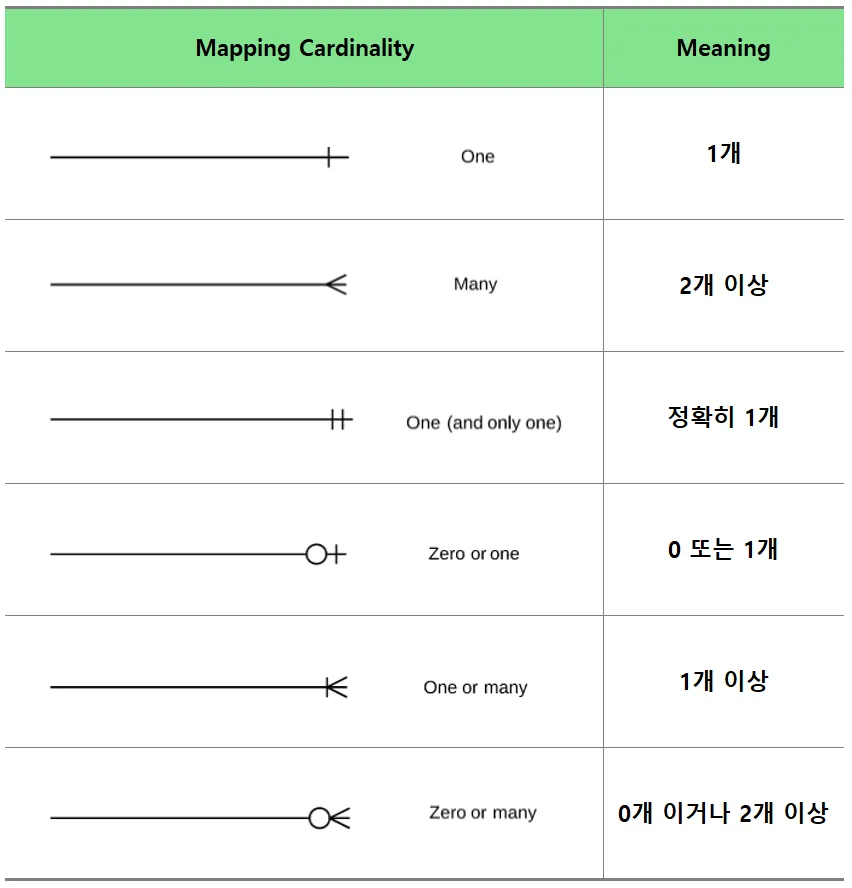
- ERD 내 기호들을 통해서, 각 테이블이 어떻게 대응되는 지 파악할 수 있음
-
해석하는 법을 알아두면 좋음
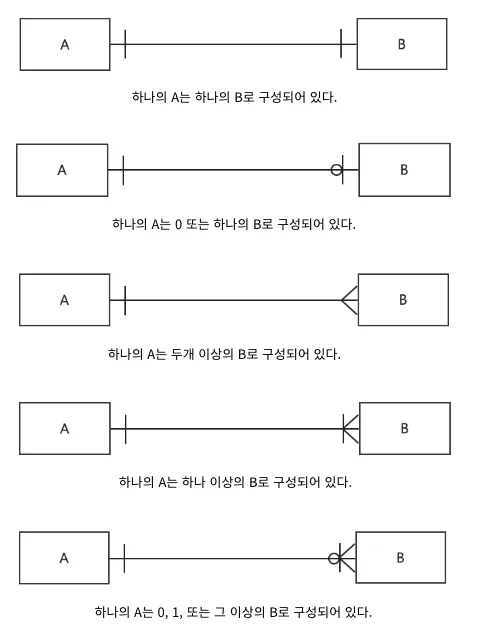
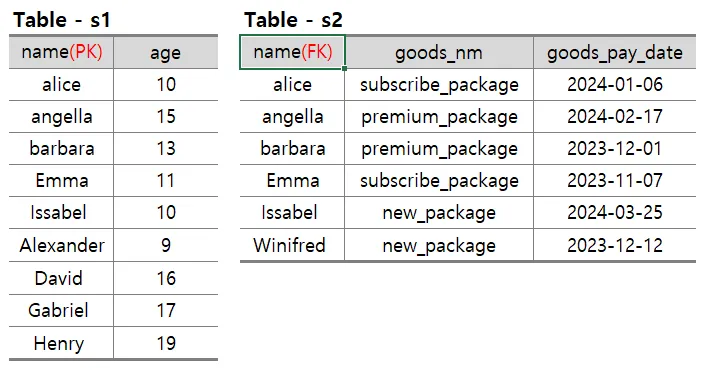
- 예시의 s1 테이블에는 name과 age가 있고, name 이 PK로 되어 있음
- s2 테이블은 name, good_nm, goods_pay_date가 있고, name이 FK로 되어 있음
그렇다면 기준 테이블은 s1 Table이 됨!
데이터 분석가는 공통 컬럼의 기준과 비교값을 찾아, 테이블 관계를 확인할 수 있음
조인의 세번째 단계: 적절한 조인 방식 찾기
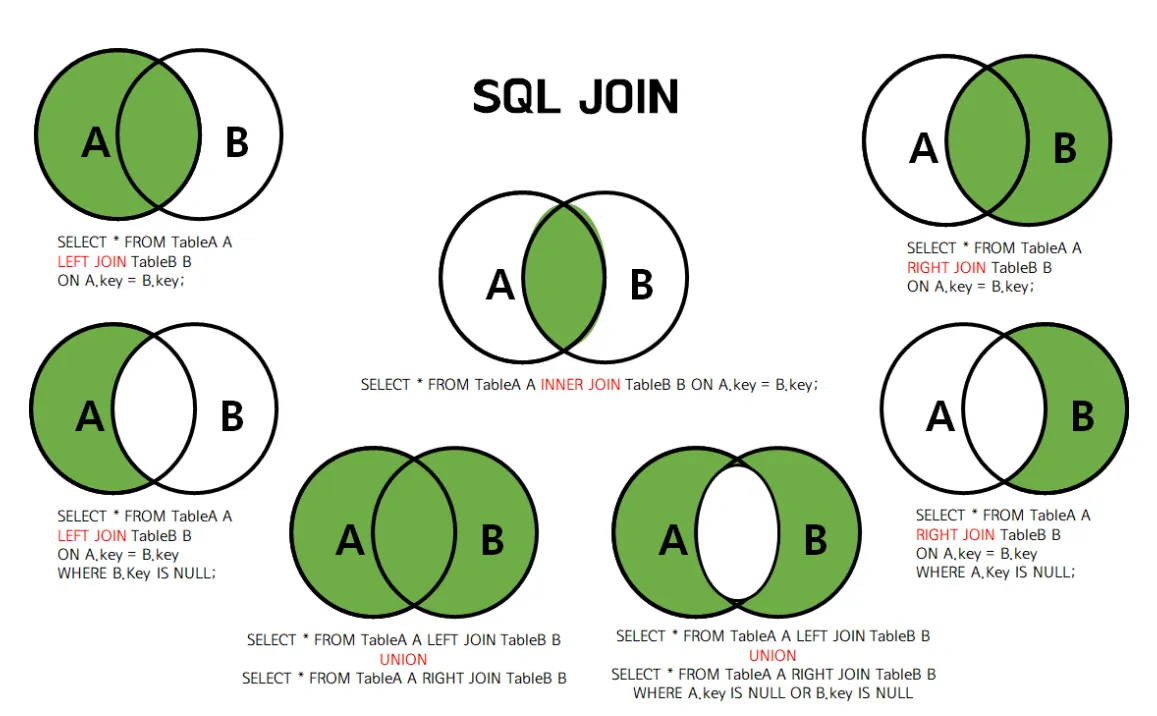
| 조인 종류 | 특징 |
|---|---|
| INNER JOIN | 두 테이블에서 일치하는 값을 가진 행을 출력 (교집합) |
| LEFT JOIN | 왼쪽 테이블의 모든 행과 오른쪽 테이블의 일치하는 행을 반환합니다. 일치하는 항목이 없으면 오른쪽 테이블의 열에 대해 NULL 값이 출력됩니다. |
| RIGHT JOIN | 오른쪽 테이블의 모든 행과 왼쪽 테이블의 일치하는 행을 반환합니다. 일치하는 항목이 없으면 왼쪽 테이블의 열에 대해 NULL 값이 출력됩니다. |
| FULL OUTER JOIN | 모든 데이터를 보고 싶을 때 사용합니다. 용량 이슈로 자주 사용하지 않아요! MySQL 환경에서는 제공하지 않아 LEFT JOIN 과 RIGHT 조인의 합집합으로 계산해야합니다. (합집합) |
- INNER JOIN과 LEFT JOIN을 가장 많이 사용
INNER JOIN
간단한 예: 두 테이블에 WHERE절이 없을 떄
# INNER JOIN 작성법(기초편)
select 컬럼1, 컬럼2...
from 테이블1 as 테이블명1
inner join 테이블2 as 테이블명2
on a.공통컬럼=b.공통컬럼
-- 원래는 아래와 같음
select 컬럼1, 컬럼2...
from 테이블1 as 테이블명1
inner join
select 컬럼1, 컬럼2...
from 테이블2 as 테이블명2
on a.공통컬럼=b.공통컬럼- s1, s2 테이블을 활용한 쿼리
select * from basic.s1 a inner join basic.s2 b on a.name=b.name- 결과값으로 a 테이블의 name = b테이블의 name 이 일치하는 경우 모든 데이터가 조회되는 것을 확인
복잡한 예: 인라인뷰 Subquery 사용
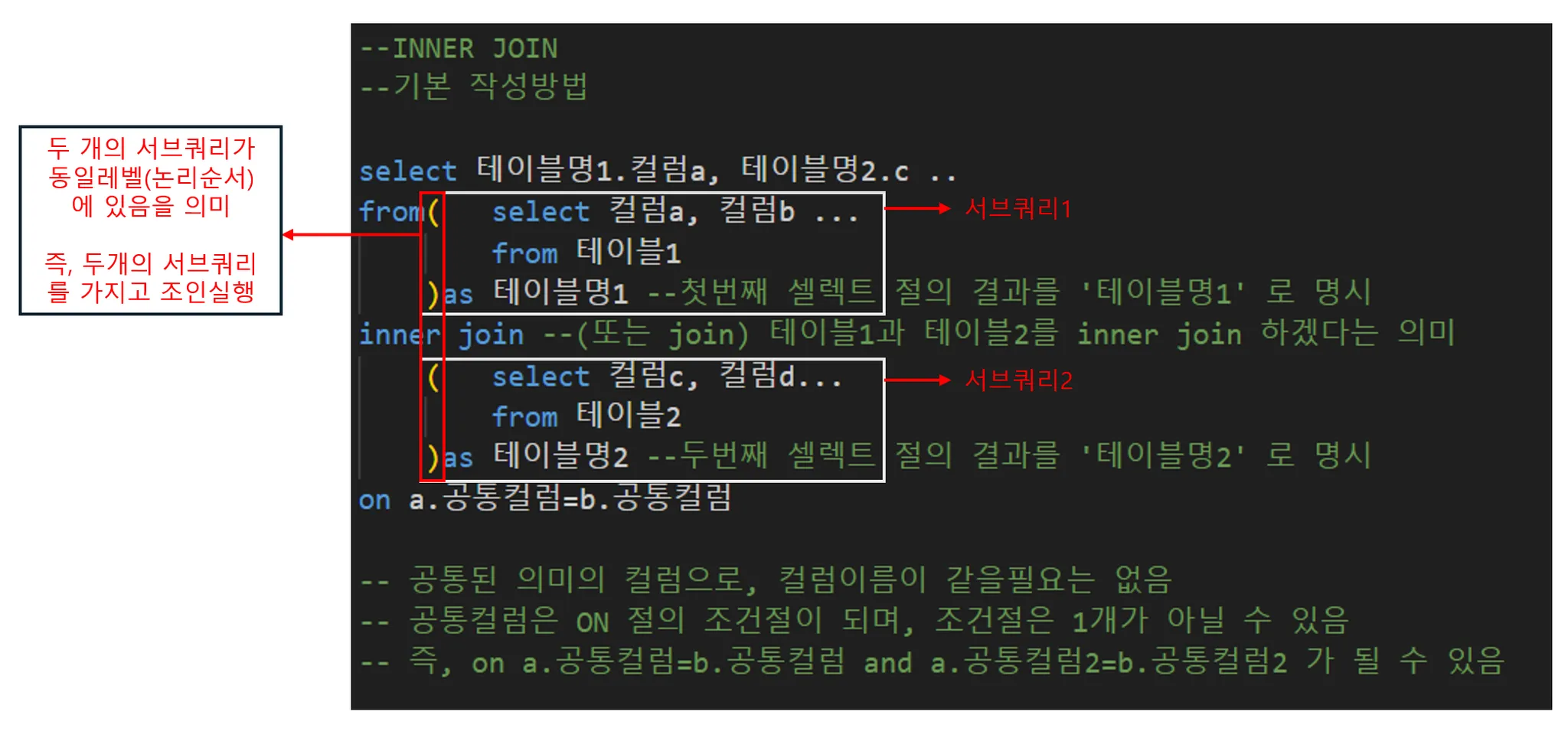
앞선 강의에서 말씀드렸던 서브쿼리가 활용된 것을 보실 수 있습니다. 추가로, 공유드렸던 ‘쿼리를 구조적으로 작성하기’를 떠올려볼게요. 서브쿼리 1과 서브쿼리2를 보시면, 동일 선상에서 괄호가 열리고, 닫힌 것을 보실 수 있어요. 쿼리를 구조적으로 작성하는 것은 필수요소는 아니나, 추후 다중 조인시 쿼리의 실행순서를 파악하는 데 많은 도움이 되므로, 명심해주세요!
서브쿼리1,2가 실행되고 드디어 조인문이 실행됩니다. INNER JOIN으로 두 서브쿼리를 결합해줄게요. 그 다음, 맨 마지막 ON절에 조건절을 넣어주시면, 테이블1과 테이블2의 조건을 만족하는 결과를 맨 바깥쪽 쿼리에서 SELECT할 수 있게 됩니다.
# INNER JOIN 작성법 (서브쿼리 활용편)
select 테이블명1.컬럼a, ....
from( select 컬럼a, 컬럼b ...
from 테이블1
)as 테이블명1 #첫번째 셀렉트 절의 결과를 '테이블명1' 로 명시
inner join #(또는 join) #테이블1과 테이블2를 inner join 하겠다는 의미
( select 컬럼c, 컬럼d...
from 테이블2
)as 테이블명2 #두번째 셀렉트 절의 결과를 '테이블명2' 로 명시
on a.공통컬럼=b.공통컬럼# 공통된 의미의 컬럼으로, 컬럼이름이 같을필요는 없음
# 공통컬럼은 ON 절의 조건절이 되며, 조건절은 1개가 아닐 수 있음
# 즉, on a.공통컬럼=b.공통컬럼 and a.공통컬럼2=b.공통컬럼2 가 될 수 있음 