
Time Table
| 시간 | 내용 |
|---|---|
| 09:00-10:00 | 코드가타 |
| 10:00-10:30 | 발제 확인 |
| 10:30-12:00 | 오전 스크럼 및 팀 과제 분석 |
| 12:00-13:00 | 점심식사 |
| 13:00-14:00 | ADsP 강의 수강 |
| 14:00-15:00 | SQL 라이브 세션 |
| 15:00-18:00 | 팀 과제 데이터 분석 |
| 18:00-19:00 | 저녁식사 |
| 19:00-20:00 | ADsP 강의 수강 |
| 20:00-20:30 | 저녁 스크럼 |
| 20:30-21:00 | TIL 작성 |
| 21:00-23:00 | 부족한 부분 보충 |
Code kata
SQL 코드가타
43. 조건에 맞는 사용자와 총 거래금액 조회하기
-
문제
- USED_GOODS_BOARD와 USED_GOODS_USER 테이블에서 완료된 중고 거래의 총금액이 70만 원 이상인 사람의 회원 ID, 닉네임, 총거래금액을 조회하는 SQL문을 작성해주세요. 결과는 총거래금액을 기준으로 오름차순 정렬해주세요.
- 완료된 → used_goods_board의 status가 "DONE"인 경우만
- 총 금액 70만원 이상 → SUM(PRICE) >= 700000
- 결과는 총 거래 금액을 기준으로 오름차순 정렬 → ORDER BY
- USED_GOODS_BOARD와 USED_GOODS_USER 테이블에서 완료된 중고 거래의 총금액이 70만 원 이상인 사람의 회원 ID, 닉네임, 총거래금액을 조회하는 SQL문을 작성해주세요. 결과는 총거래금액을 기준으로 오름차순 정렬해주세요.
-
작성한 코드
SELECT
ugb.writer_id
, ugu.nickname
, SUM(ugb.price) as total_sales
FROM
used_goods_board ugb JOIN used_goods_user ugu ON ugb.writer_id = ugu.user_id
WHERE
ugb.status = 'DONE'
GROUP BY
ugb.writer_id
HAVING
`total_sales` >= 700000
ORDER BY
`total_sales`
;- 추가: WITH(CTE, Common Table Expressions) 활용
- CTE(공통 테이블 식): 서브 쿼리로 쓰이는 파생 테이블(derived table)과 비슷한 개념으로 임시로 쿼리 결과를 저장해 놓고 여러 번 참조해서 사용하는 용도로 씀
WITH used_cte AS (
SELECT
writer_id
, SUM(price) AS sum_price
FROM
used_goods_board
GROUP BY
writer_id
, status
HAVING
sum_price >= 700000
AND status = 'DONE'
)
SELECT
u.user_id
, u.nickname
, c.sum_price AS total_sales
FROM
used_cte c JOIN used_goods_user u
ON c.writer_id = u.user_id
ORDER BY
3
;Python 코드가타
3. 몫 구하기
- 작성한 코드
solution = lambda num1, num2 : num1 // num2- 다른 사람의 풀이
solution = int.__floordiv__- 파이썬 매직 메서드(Magic Method)
- 파이썬의 클래스에서 특별한 역할을 수행하는 메서드
- 이름 앞뒤에 더블 언더스코어(__)가 있는 것이 특징
- 파이썬의 기본 동작을 재정의하거나 추가적인 기능을 제공할 수 있음
- 객체 간의 연산을 수행하거나, 더 읽기 쉽고 간결한 코드를 작성할 수 있음
- 하나의 클래스에서 정의할 수 있는 매직 메서드는 매우 다양함
- 연산자 오버로딩(Operator Overloading)
- 클래스 내부에서 특정 연산자가 별도의 동작 방식을 가지도록 하는 것을 의미
- 파이썬에서는 매직 메서드를 사용하여 연산자 오버로딩을 쉽게 구현할 수 있음
# 예제1: 두 점을 나타내는 Point 클래스의 객체간 덧셈을 지원하는 클래스
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __add__(self, other):
if isinstance(other, Point):
return Point(self.x + other.x, self.y + other.y)
else:
raise ValueError(f"Unsupported operand type(s) for +: '{type(self)}' and '{type(other)}'")
def __str__(self):
return f"({self.x}, {self.y})"
point1 = Point(1, 2)
point2 = Point(3, 4)
print(point1 + point2) # 출력: (4, 6)# 예제2: 비교 연산자 오버로딩 예제
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, other):
if isinstance(other, Person):
return self.name == other.name and self.age == other.age
else:
return False
person1 = Person("Alice", 30)
person2 = Person("Bob", 30)
person3 = Person("Alice", 30)
print(person1 == person2) # 출력: False
print(person1 == person3) # 출력: True- 몇 가지 주요 매직 메서드
- __init__(self, ...): 객체 초기화
- __str__(self): 간략한 문자열 형태로 객체 표현
- __repr__(self): 완전한 문자열 형태로 객체 표현
- __add__(self, other): 덧셈 연산 오버로딩
- __sub__(self, other): 뺄셈 연산 오버로딩
- __mul__(self, other): 곱셈 연산 오버로딩
- __truediv__(self, other): 나눗셈 연산 오버로딩
- __floordiv__(self, other): 내림 나눗셈 연산 오버로딩
- __mod__(self, other): 모듈로 연산 오버로딩
def solution(num1, num2):
answer = num1 / num2
return int(answer)- int는 소수점 제거용
def solution(num1, num2):
return divmod(num1, num2)[0]발제 확인: 온보딩 2주차
-
기초 분석 팀 과제
- 주제 선택: 2024.10.07 (월)
- 최종 제출 마감: 2024.10.11. (금) 11:00까지
- 과제 발표회: 2024.10.11. (금) 14:00 ~ 17:00
-
EDA(탐색적 데이터 분석; Exploratory Data Analysis)
- 수집한 데이터가 들어왔을 때, 이를 다양한 각도에서 관찰하고 이해하는 과정
팀 과제
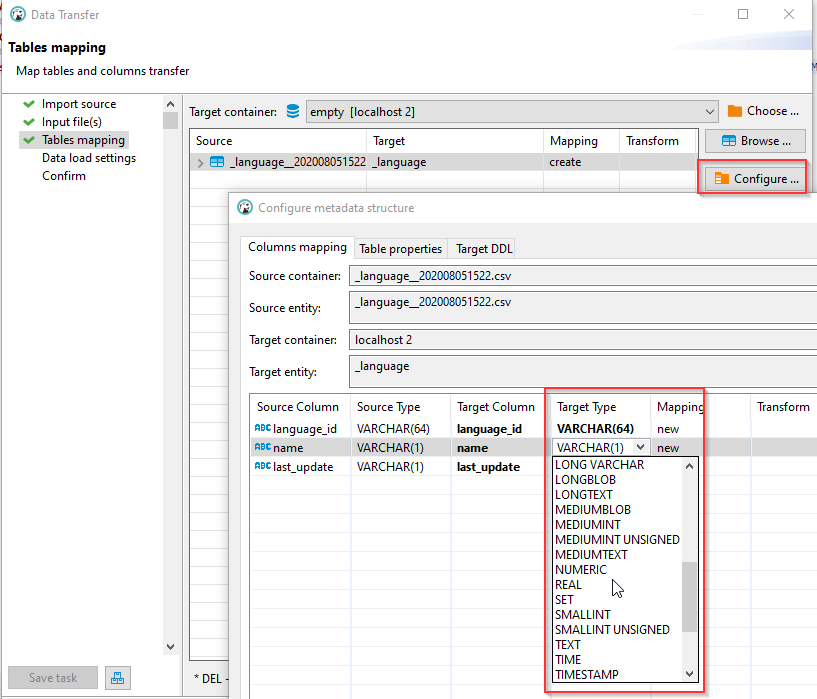
Error occurred during batch insert
(you can disable batch insert in order to skip particular rows).
Reason:
SQL Error [1264][22001]: Data truncation: Out of range value for column 'category_id' at row 1
- SQL Error [1264][22001]
- 데이터 insert 시 해당 테이블의 컬럼 길이가 작아서 데이터가 들어가지 않음
- 오류가 발생한 해당 컬럼의 길이를 늘려주면 됨
- Table mapping에서 Configure 눌러서 target type 변경
1. 데이터 추출 및 탐색
- 목적: 데이터베이스에서 원하는 데이터를 추출하고 필터링하여 특정 부분 확인
- 예시:
- 특정 날짜에 판매된 제품 리스트 추출
- 특정 조건에 맞는 사용자 목록 탐색
- 중복 데이터 제거:
- 주요 명령어:
DISTINCT - 목적: 중복된 데이터 제거하여 고유한 값만 추출
- 예시: 특정 제품 카테고리의 고유한 제품 리스트 조회
- 주요 명령어:
2. 데이터 필터링 및 조건부 검색
- 주요 명령어:
WHERE,NOT - 조건부 검색 기법:
BETWEEN: 범위 검색LIKE: 패턴 검색IN: 특정 값 목록 검색
- 예시:
- 최근 1년 동안 매출이 1,000만 원 이상인 고객 목록 추출
- 특정 조건을 만족하지 않는 데이터 검색 (예: 매출이 500만 원 미만인 고객)
3. 데이터 집계 및 그룹화
- 주요 명령어:
GROUP BY,HAVING - 목적: 데이터를 그룹별로 집계하고 요약
- 예시:
- 각 지역별 매출 총합
- 시간대별 자전거 이용량 평균
4. 통계량 계산
- 집계 함수:
COUNT,SUM,AVG,MIN,MAX - 목적: 기초 통계량 계산
- 예시:
- 상품의 평균 판매량
- 최고 매출을 기록한 고객 조회
5. 데이터 변환
- 주요 명령어:
JOIN,UNION,서브쿼리 - 목적: 여러 테이블을 결합하거나 복잡한 데이터 처리
- 예시:
- 고객 테이블과 구매 테이블을 결합해 고객별 구매 이력 분석
- 두 개의 다른 테이블에서 같은 구조의 데이터를 결합하여 전체 사용자 목록 조회
6. 데이터 정렬 및 분류
- 주요 명령어:
ORDER BY - 목적: 특정 열을 기준으로 오름차순 또는 내림차순 정렬
- 예시:
- 가장 많이 팔린 제품 상위 10개 리스트
- 가장 많이 대여된 자전거 공유소 순위
7. 데이터 변형 및 계산
- 주요 명령어:
CASE WHEN - 목적: 특정 조건에 따라 데이터 분류 또는 계산
- 예시:
- 매출이 500만 원 이상인 고객을 VIP로 분류
- 날짜를 년, 월, 일로 분리하여 분석
- 데이터 파악하기
-
일별 판매금액
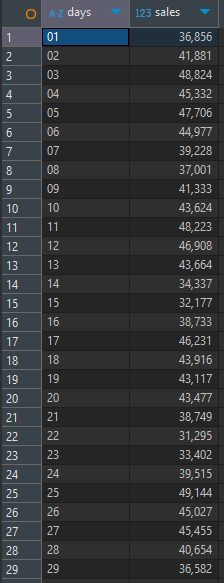
-
느낀점
- price의 값이 음수인 경우가 있어서 음수, 0은 무시하고 데이터 분석해야 함
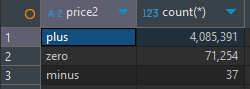
- event_time의 type이 날짜가 아니라 verchar여서 날짜 관련 함수를 못 쓰는 게 아쉽다.
- price의 값이 음수인 경우가 있어서 음수, 0은 무시하고 데이터 분석해야 함
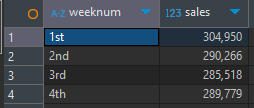
What day of the month do people make the most purchases? and what time of the day?
- 주별 판매량, 뷰잉, 장바구니 담은 횟수, 장바구니 뺀 횟수
-
주의 기준은 2020년 2월의 데이터를 최대한 많이 활용하기 위해 주의 시작을 일요일로 정했음
- 2월 첫째 주: 2020/02/02 - 2020/02/08
- 2월 둘째 주: 2020/02/09 - 2020/02/15
- 2월 셋째 주: 2020/02/16 - 2020/02/22
- 2월 넷째 주: 2020/02/23 - 2020/02/29
-
금액 합계는 소수점 첫째 자리에서 반올림
-
판매량에 유의미한 차이가 없는 것 같아서 다른 내용도 찾아보기로
-
사용자가 제품을 본 횟수
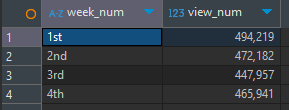
-
사용자가 카트에 제품을 담은 횟수
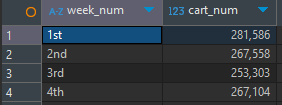
-
사용자가 카트에서 제품을 뺀 횟수
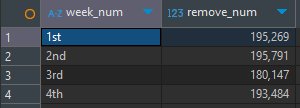
-
사용자가 제품을 구매한 횟수
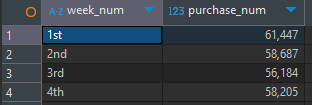
-
- 시간별 비교 → Pivot Table
- 가격별
- 상표별
강의 수강
SQL 라이브 세션

2 B R 0 2 B