CodeKata
SQL
프로그래머스: FrontEnd 개발자 찾기
예를 들어 어떤 개발자의 SKILL_CODE가 400 (=b'110010000')이라면, 이는 SKILLCODES 테이블에서 CODE가 256 (=b'100000000'), 128 (=b'10000000'), 16 (=b'10000') 에 해당하는 스킬을 가졌다는 것을 의미합니다.
→ 이걸 어떻게 해결해야 하나 싶었는데 "비트 연산자"라는 게 있다고 함!
비트 연산자
- 논리 연산자와 비슷하지만, 비트(bit) 단위로 논리 연산을 수행
- 비트 단위로 전체 비트를 좌측이나 우측으로 이동시킬 때도 사용
- 종류
&- AND 연산
- 대응되는 비트가 모두 1이면 1을 반환
|- OR 연산
- 대응되는 비트 중에서 하나라도 1이면 1을 반환
^- XOR 연산
- 대응되는 비트가 서로 다르면 1을 반환
~- NOT 연산
- 비트를 반전시킴(1이면 0으로, 0이면 1로)
<<- Left Shift 연산
- 지정한 수만큼 비트를 전부 왼쪽으로 이동
>>- Right Shift 연산
- 부호를 유지하면서 지정한 수만큼 비트를 전부 오른쪽으로 이동
중요 포인트
- 한 개발자는 여러 언어 기술을 가질 수 있는데, 이로 인해 여러 프론트엔드 기술을 가진 한 개발자의 정보가 중복으로 나오게 되니 주의
- SKILLCODES 테이블과 DEVELOPERS 테이블이 N:1(다대일) 관계이기 때문에 발생하는 문제
작성한 쿼리
SELECT
id
, email
, first_name
, last_name
FROM
developers d
WHERE
skill_code & (
SELECT
sum(code)
FROM
skillcodes
WHERE
category = 'Front End'
)
ORDER BY
id
;참고할 만한 다른 풀이
- JOIN & GROUP BY
SELECT ID
,EMAIL
,FIRST_NAME
,LAST_NAME
FROM DEVELOPERS D, SKILLCODES S
WHERE 1 = 1
AND (D.SKILL_CODE & S.CODE) > 0
AND CATEGORY = 'Front End'
GROUP BY ID, EMAIL, FIRST_NAME, LAST_NAME
ORDER BY ID;- CTE
WITH FRONTEND AS (
SELECT SUM(CODE)
FROM SKILLCODES
WHERE CATEGORY = 'Front End'
)
SELECT ID, EMAIL, FIRST_NAME, LAST_NAME
FROM DEVELOPERS
WHERE SKILL_CODE & (SELECT * FROM FRONTEND) >= 1
ORDER BY 1- 비트 연산자 없이 해결 ★
with SKILLCODES_TMP as (
select CATEGORY, BIN(CODE) as CODE
from SKILLCODES
),
DEVELOPERS_TMP as (
select id, first_name, last_name, email, BIN(SKILL_CODE) as SKILL_CODE
from DEVELOPERS
)
select distinct a.id, a.email, a.first_name, a.last_name
from DEVELOPERS_TMP as a
left join SKILLCODES_TMP as b
on ((a.skill_code - b.code) not like '%9%')
where b.category = 'Front End'
order by a.id;- distinct
select
distinct
id,
email,
first_name,
last_name
from developers D
inner join skillcodes S on D.skill_code & S.code = S.code and S.category = 'Front End'
order by id asc;팀 프로젝트 관련
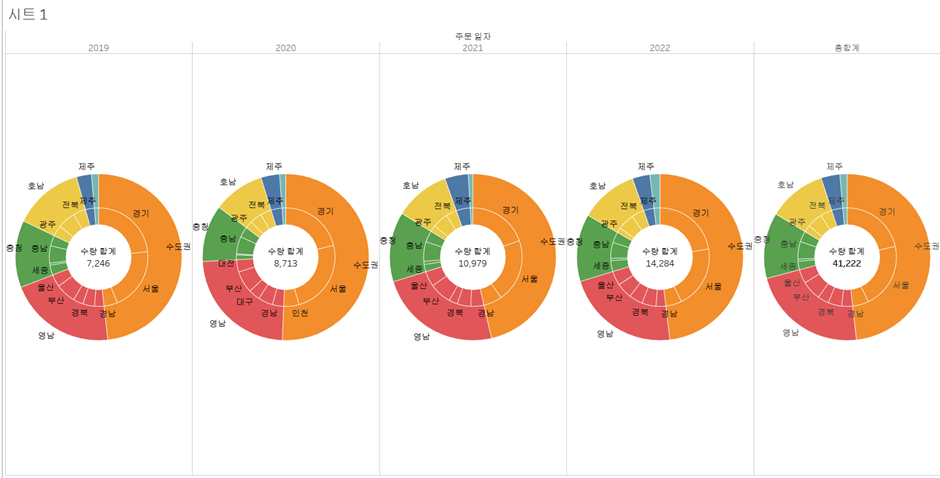
- 대시보드 최종 마무리
- 하남시 예측값 추가
- 폰트 통일
- 대시보드 제작 과정 공유
- 토글 버튼
- 하나의 대시보드에서 시트 변경
- 특정 조건의 그래프만 보이게 하는 법
- 참고할 만한 블로그 글 내용 정리
- 영역 차트
- 라인 차트 아래가 색칠되어 있는 차트
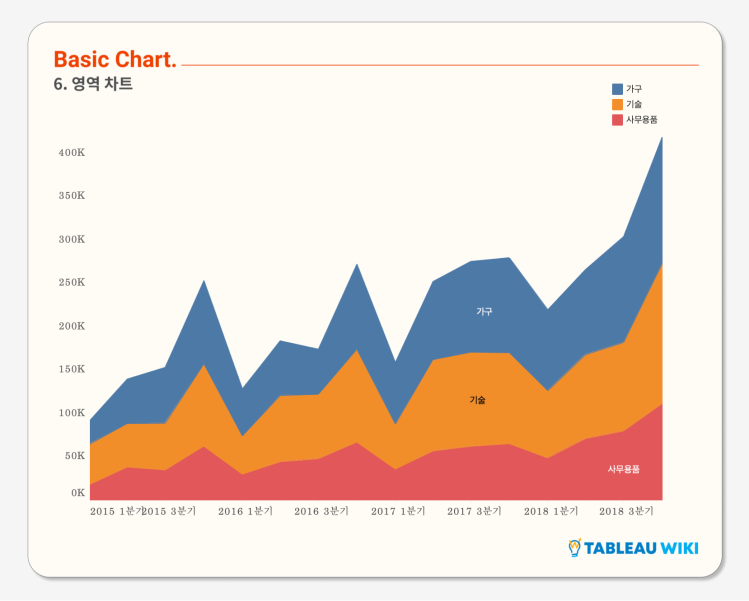
- 마크 > 차트 종류 > 영역 차트
- 라인 차트 아래가 색칠되어 있는 차트
- 그룹화 ★★★
- 특정 필드에 있는 값들을 그룹화하여 사용할 수 있음
(예) 지역을 수도권과 비수도권으로 그룹화
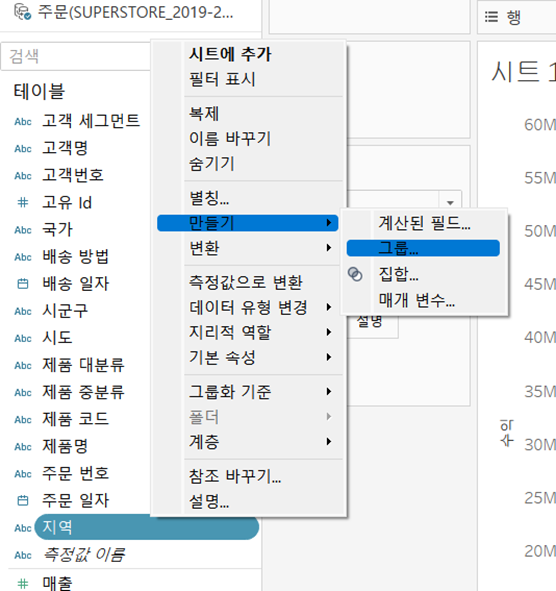
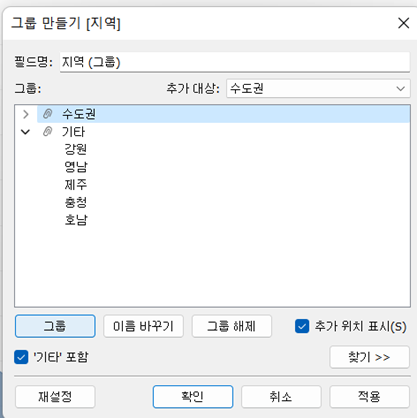
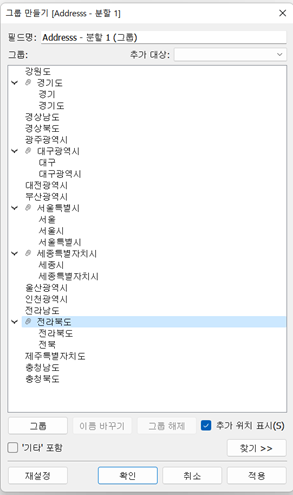
- 특정 필드에 있는 값들을 그룹화하여 사용할 수 있음
- 이중 축
- 선반에서 드롭다운 메뉴를 통해 설정 가능
※ 사용 시 축 동기화 설정 및 머리글 표시 해제 추천 - 두 차트를 합쳐서 봐야 할 때 많이 사용
(예) 라인 차트 위에 그림 추가 등
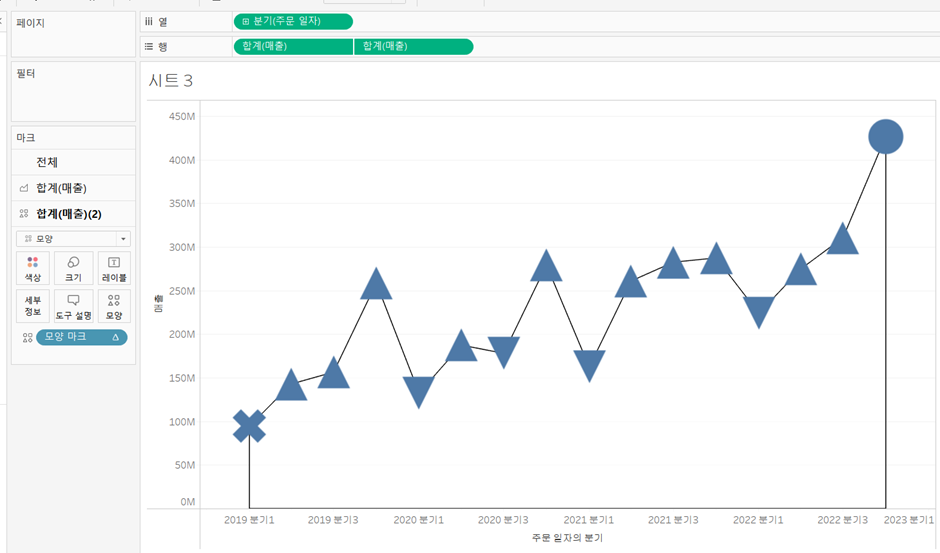
- 선반에서 드롭다운 메뉴를 통해 설정 가능
- 필터
- 필터를 추가하여 필터링
- 다양한 필터링 가능
- 특정 항목만 선택 후, '이 항목만 유지'를 선택하여 필터링
- 와일드카드를 이용해 필터링
- 조건을 이용해 필터링
- 상위 및 하위 몇 개 항목만 필터링
- 날짜 필터링
- 정렬
- 툴바에서 오름차순 및 내림차순 설정
- 마크나 선반에서 드롭다운 메뉴 이용해 정렬
- 머리글에서 버튼 눌러 정렬
- 차트에서 원하는 위치로 끌어 정렬
- 필드 만들어 수동으로 정렬
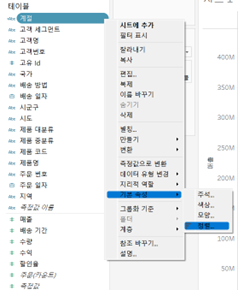
- 계층
- 앞에 + 표시가 있다 == 계층이 있다
- 날짜는 저절로 계층화됨
- 필드 두 개를 합치듯 끌어줘도 계층 형성 가능
- 계층 내에서 드래그를 통해 순서 변경 가능
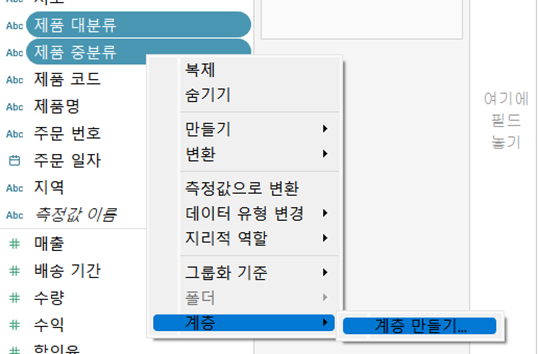

- 총계 추가
- 분석 탭에서 총계를 뷰로 드래그해 행 방향, 열 방향, 소계를 추가할 수 있음
- 테이블의 총계 중 아무거나 누른 후 마우스 우클릭 → 서식으로 들어가면 총계에 대한 서식 설정 가능
- 이름, 색상 등 변경 가능
- 분석 메뉴에서 총계를 테이블의 위와 왼쪽으로 불러오게 할 수도 있음
- 데이터 불러오기
- 데이터 해석기, 유니온, 필터, 숨기기 등 다양한 기능을 사용
- 시트와 필드 이름 잘 변경해야 함(자료형도)
- 시트와 시트 연결 시 관계를 생성해주는 것을 추천
- 데이터의 형태는 wide form보다는 long form으로
※ 한 사람에게서 시간을 따라서 얻어진 자료를 한 줄로 가로로 쓴 것을 wide form, 세로로 쓴 것을 long form이라고 함
- 파이 차트
- 시각화를 할 때 색상의 중요성 잊지 말기
- 크기에 차이를 주기 위해 크기 편집 사용 가능 → 크기 범위 바꿀 수 있음
- 레이블 추가를 통해 정보를 더 잘 살펴볼 수 있음
- 맵 차트
- 태블로에서는 시도, 시군구까지 맵 형태로 표현 가능
(지명을 통해 지리적 역할 추가) - 위도, 경도 있어도 가능
- 지역: 시도 기준으로 수도권, 영남 등으로 묶여 있는 필드 맵으로 표현할 때
지리적 역할 > 만들기 원본 > 시도 선택
※ 지리적 역할을 나타내는 것으로 만들어진 필드를 역시 지도에 표시할 수 있음 - 백그라운드 레이어 설정을 통해 원하는 부분만 표시 가능
- 배경 맵 설정을 통해 거리맵, 위성사진 등 다양한 지도 표현 간으
- 마크에서 색상 및 레이블에 들어갈 수준 조절하여 다양한 차트 표시 가능
- 태블로에서는 시도, 시군구까지 맵 형태로 표현 가능
- 맵 차트 다중 마크 계층 활용
- 여러 계층을 가지는 도넛 차트를 만들기 위해 이용하기도 함
(맵과는 관련 없는 시각화를 하지만 여러 계층으로 만들고 싶을 때 맵 차트를 이용하는 것) - 방법
- 기준 포인트 필드 추가
(계산된 필드 >MAKEPOINT(0,0)← 그냥 아무 점이나 맵 차트에 표시하는 것) - 마크의 빈 공간에 더블 클릭하여 min(1)을 추가, 크기로 지정
- 파이차트 만들기
- 도넛 차트를 위해 파이차트를 하나 더 추가하는데, 이때 원하는 필드를 맵 차트 위로 끌어와 "계층추가"가 나타나게 하여 그 곳으로 드래그

- 여러 계층을 가지는 도넛 차트 완성
- 여러 계층을 가지는 도넛 차트를 만들기 위해 이용하기도 함
- 퀵 테이블 계산
- 테이블 계산 편집을 통해 어떻게 계산을 진행할 건지 설정
(패널 아래로, 특정 차원 등) - 누계, 차이, 순위, 구성비율 등 다양
- 퀵 테이블 계산으로 만들어진 걸 더블 클릭하면 식 볼 수 있음(필드 추가도 가능)
- 테이블 계산 편집을 통해 어떻게 계산을 진행할 건지 설정
- 계산된 필드
※ 계산된 필드는 다양한 곳에 활용 가능 → 필터, 마크, 측정값, …
※ 문자열보다는 숫자형과 Boolean 연산이 더 빠르므로 이를 활용하기

- 시도 이름
IF ENDSWITH([시도], '남도') OR ENDSWITH([시도], '북도') THEN LEFT([시도], 1) + MID([시도], 3, 1) ELSE LEFT([시도], 2) END - 계절

- 수익 5천만원 이상인지

- FIXED를 통해 해당 필드를 고정시키고 그 내에서만 함수 적용시키기
{FIXED [시도]: MAX([시도별 확진자])} = [시도별 확진자]
- 시도 이름
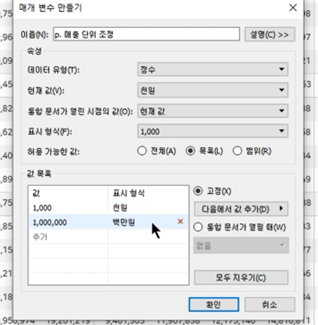
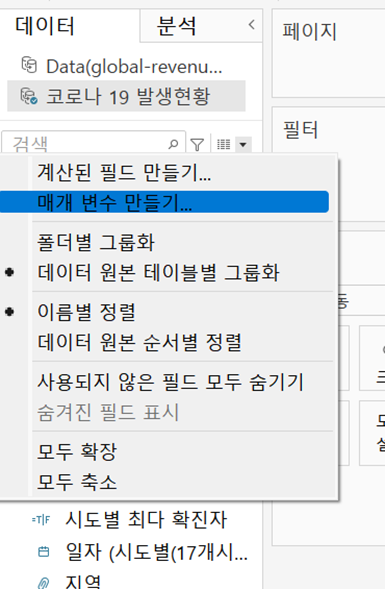
- 매개 변수 ★
- 데이터를 선택해주기 위해 사용하는 값
- 단독으로는 사용 불가능: 계산된 필드나 다른 무언가와 합쳐 사용해야 함
- 사용자 지정 분할
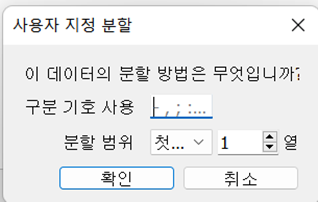
- 분할 범위의 경우 첫 번째는 처음부터 몇 열을 가져올지, 마지막은 뒤에서부터
- 인터랙티브 대시보드(대시보드 > 동작 > 동작 추가)
- 대시보드의 동작(Action)을 통해 다양한 동작 가능
- 필터, 매개변수와 함께 동작 만들기도 가능
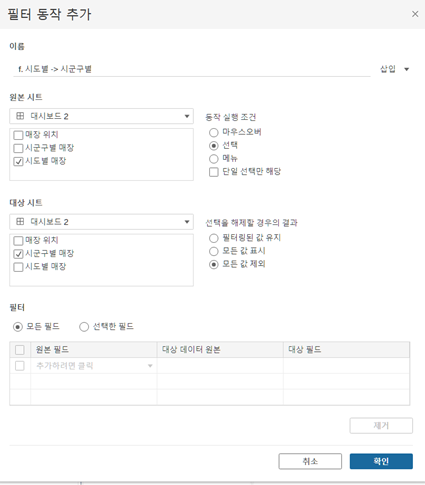
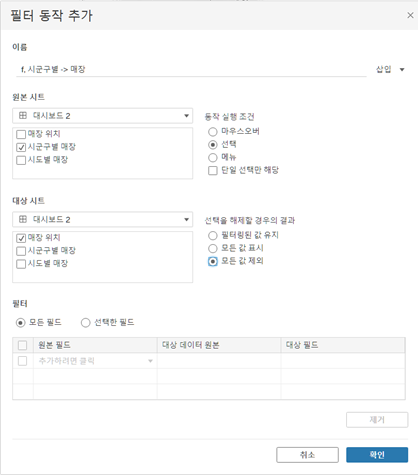
- 선택 해제 시 해당 차트가 날아가게 해주기 위해 제목 표시는 해제해야 함
(그래야 선택 해제 시 세부 차트가 보이지 않을 정도의 사이즈가 되어 시트가 변경된 것처럼 보임)
- 영역 차트
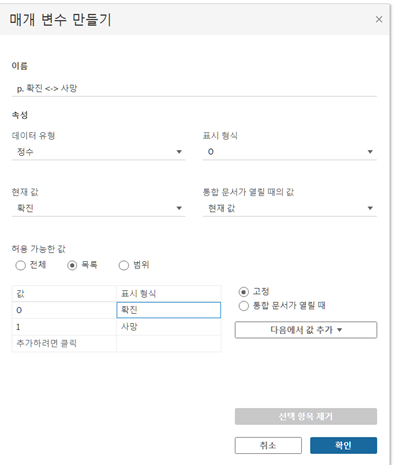
매개변수: 두 개의 매개변수를 통해 (신규와 누적), (확진자 수와 사망자 수) 선택해서 보게 하기
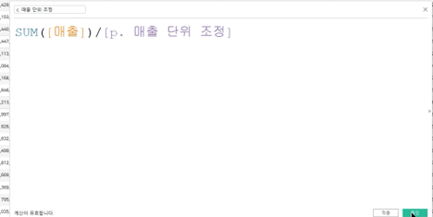
- 매개변수의 이름은 주로 p.로 시작하고 계산된 필드는 c.로 시작하게 적는다고 함
- 매개변수 표시 후 단일 값 목록으로 표시하게 해 주면 매개변수를 통해 선택 가능
- 매개변수는 혼자 쓸 수 없으므로 계산된 필드를 만들어야 함
- 매개변수는 계산, 필터 똔느 참조선에서 상수 값으로 대체할 수 있는 숫자, 날짜 또는 문자열과 같은 통합 문서 변수임
- 따라서 아래와 같은 계산된 필드가 필요
- (신규와 누적)도 동일한 방법으로 만들고 계산된 필드 만들기
CASE [p.신규 <-> 누적] WHEN 0 THEN [c.확진 <-> 사망] WHEN 1 THEN RUNNING_SUM([c.확진 <-> 사망]) END※ 'RUNNING_SUM( )': 파티션에 있는 첫 번째 행에서 현재 행까지 주어진 식의 누계 합계를 반환


SDL
: Self-Directed Learning
통계특강
선형대수학
→ 시간 날 때마다 강의 듣기!
회고
- 팀 프로젝트 마무리하고 프로젝트 기간 중 정리하지 못한 내용들을 정리하는 시간을 가졌음
- 대시보드 만드는 방법에 대해 설명하는 시간을 가졌음
- 남에게 설명할 수 있어야 해당 내용을 "안다"라고 말할 수 있는 것!
- 토글, 시트변경, 그래프 변경 모두 핵심은 Boolean Filter
- 진로에 대한 고민 중
- 좀 더 깊게 공부하고 싶은데 그럼 대학원을 가야 할까?
- 참고할 만한 글

2 B R 0 2 B