
강의 개요
- Web Scraping, API 활용, 그리고 MySQL 문법을 익혀 데이터 수집(Extract), 정제(Transform), 그리고 적재(Load) 과정을 다룹니다.
- 초반에는 웹 스크래핑 기술을 통해 원하는 데이터를 직접 수집하는 방법과 HTML 구조를 분석하고 필요한 정보를 추출하는 기술을 배웁니다.
- 이후에는 API를 활용해 외부 서비스와의 데이터 연동을 통해 효율적인 데이터 수집 방법을 소개하고, JSON 응답 형식을 다루는 실습을 진행합니다.
- 마지막으로, MySQL을 활용하여 수집된 데이터를 전처리하고 데이터베이스에 저장하고 관리하는 방법을 배우며, 실무 환경에 가까운 예제를 통해 ETL 파이프라인을 자연스럽게 배웁니다.
- 모든 단계는 실제 사례와 프로젝트 기반의 실습을 통해 진행되어, 이론과 실습이 조화롭게 이루어집니다.
한마디:
ML(Machine Learning) 배우기 전 익히는 Python 심화반이라고 생각해 주세요.커리큘럼 소개
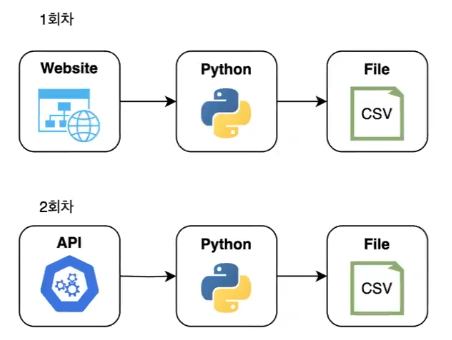
- 1회차: 웹 스크래핑(Web Scraping) 기초와 실습
- HTML 구조 분석 및 웹 데이터 추출
- 객체지향 프로그래밍(OOP) 개념 학습
- 2회차
- API 호출의 기본 개념
- JSON 응답 처리
- 데이터 전처리 및 클래스, 모듈화 코드 실습
→ API 방식은 사내외를 가리지 않고 웹사이트나 다른 팀의 협조 없이도 가장 편리하게 데이터를 수집할 수 있는 방법
→ 공공 데이터 세트는 API를 사용해 제공하는 경우가 많음
☞ API(Application Programming Interface)
🡆 두 프로그램이 서로 대화하기 위한 방법을 정의한 것
"예를 들어 우리가 사용하는 윈도우나 맥OS 같은 운영체제는 문서 작성 프로그램이 디스크에 있는 파일을 읽고 쓸 수 있도록 API를 제공한다. 또 기상청에서 제공하는 API를 사용하면 지역별, 실시간 날씨 정보를 얻을 수 있다.
데이터 분석가가 종종 데이터베이스에 직접 접근하기 어려울 때가 있다. 데이터베이스 접근 권한이 엄격히 관리되거나, 민감한 개인 정보가 있거나, 아예 네트워크가 분리되어 물리적인 접근이 불가할 수도 있다. 이럴 때 인증된 URL만 있으면 언제든지 필요한 데이터에 편리하게 접근할 수 있는 방식이 API다."
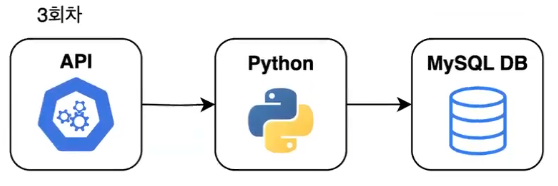
- 3회차: MySQL 기초 문법 학습
- 데이터베이스 테이블 설계 및 쿼리 실습
- 클래스와 모듈화된 코드로 데이터 처리 실습
→ CSV 파일이 아닌 데이터베이스에 연결을 하는 게 핵심!
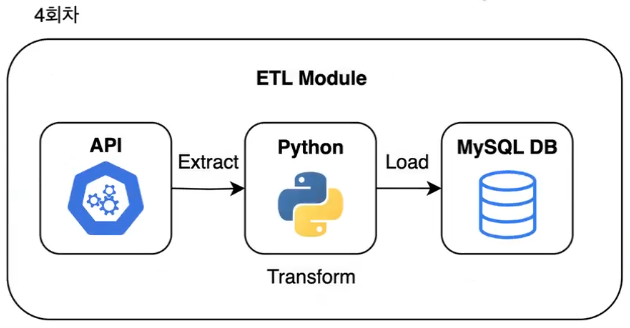
- 4회차: ETL 파이프라인 구축 및 모듈화
- 수집, 정제, 적재 프로세스를 연결하여 하나의 파이프라인 완성
→ 1~3회차 내용 종합해서 하나의 프로그램(Python Module) 만들기
→ ETL Module- 5회차: ETL 파이프라인의 스케줄링 및 로깅
- 자동화 및 오류 관리 실습과 복습을 통해 전체 흐름을 다지는 시간
- 5회차에 다룰 수 있는 내용:
- error handling
- unit tests, intergration tests
- logging
- scheduling
- AWS
- docker
목적
- 웹 스크래핑(Web Scrapting)을 활용하여 데이터를 수집하고 CSV 파일로 저장
- Requests로 웹페이지에 요청 보내기
- BeautifulSoup 라이브러리를 사용하여 HTML 파싱 및 데이터 추출
- 파싱(parsing): 비구조화된 데이터 소스에서 관련 정보를 추출하고 쉽게 분석할 수 있는 구조화된 형식으로 변환하는 과정
- 웹페이지에서 원하는 데이터를 추출하여 가공하기 쉬운 상태로 바꾸는 것
- 데이터를 깨끗하게 전처리 해주는 것이라 보면 됨
- 파싱(parsing): 비구조화된 데이터 소스에서 관련 정보를 추출하고 쉽게 분석할 수 있는 구조화된 형식으로 변환하는 과정
- 수집한 데이터를 CSV 파일로 저장
웹 스크래핑(Web Scraping)
- http request를 통해 웹 페이지의 데이터를 수집하는 기술
- 다양한 웹사이트의 데이터를 효율적으로 모을 수 있음
- 비정형 데이터, 회사 외부 데이터를 가져 오고 싶을 때 많이 사용
- 특정 웹사이트 같은 곳에서 데이터를 뽑고 싶을 때 활용
- 다양한 웹사이트의 데이터를 효율적으로 모을 수 있음
- 비정형 데이터를 정형 데이터로 변환하여 데이터 분석에 활용할 수 있는 중요한 도구
- 특정 웹사이트를 탐색하며 데이터를 수집하고, 이를 분석하거나 저장할 수 있도록 도움
Web Scraping? Web Crawling?
A crawler’s purpose is to follow links to reach numerous pages and analyze their meta data and content. Scraping is possible out of the web. For example you can retrieve some information from a database. Scraping is pulling data from the web or a database.
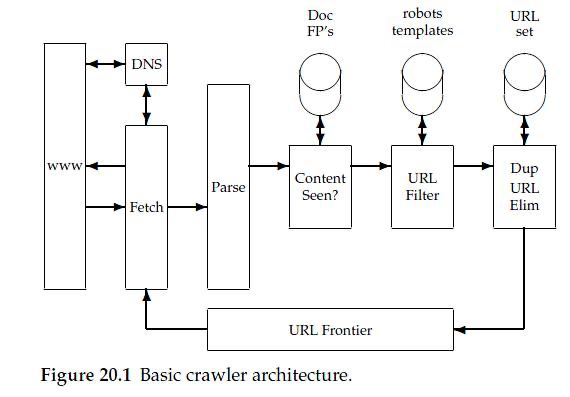
- '크롤러' (또는 '웹 프론티어')
- 어떻게 하면 www의 수천 수백만개의 웹 페이지들을 잘 수집할 수 있을까에 대한 고민
"웹 크롤러란 seed URL을 주면 관련된 URL을 찾아 내고, 그 URL들에서 또 다른 하이퍼 링크를 찾아내고 계속해서 이 과정을 반복하며 하이퍼 링크들을 다운로드하는 프로그램이다."
A web crawler is a program that, given one or more seed URLs, downloads the web pages associated with these URLs, extracts any hyperlinks contained in them, and recursively continues to download the web pages identified by these hyperlinks.
📎 Web Crawler Architecture, MARC NAJORK
Microsoft Research, 2009

- Web Crawler: A Review 논문 2.1에 있는 'The History of Web Crawler' 읽어 보기
- robots.txt 윤리
- 긁으려는 페이지 루트 도메인에서 /robots.txt에 들어가서 내용 꼭 확인하기
- 검색엔진 크롤러에서 사이트에 요청할 수 있거나 요청할 수 없는 페이지 또는 파일을 크롤러에 지시하는 파일(크롤러가 요청해도 되는 것/요청하면 안 되는 것 정리)
- 몇 초 간격으로 요청을 보내도 되는지 등 다양한 내용이 있음
읽어보면 좋을 내용
데이터분석가에게 Web Scraping이란?
- 회사 외부에서 방대하고 다양한 정보를 수집할 수 있는 강력한 도구
- e.g. 증권가 → 뉴스 scrap해서 외부 정보 수집
- 경쟁사 분석, 시장 조사, 고객 리뷰 등 분석에 필요한 자료를 웹에서 신속히 확보할 수 있음
- 경쟁사, 시장 파악 시 scrap 기술 많이 사용
- 데이터를 지속적으로 수집함으로써 실시간 데이터 모니터링과 트렌드 분석이 가능
- 데이터 분석가가 다양한 데이터 소스를 활용할 수 있는 능력을 키우는 데 중요한 기술
request 라이브러리
request라이브러리를 사용하여 URL에 요청을 보내고 응답을 확인할 수 있음
import requests
url = "<URL>" # 예제 URL
response = requests.get(url)
print(response.status_code) # 상태코드 출력- 자주 나오는 GET 요청 관련 상태 코드
| 코드 | 의미 | 설명 |
|---|---|---|
| 200 | OK | 요청이 성공적으로 처리되었으며, 요청된 리소스를 반환합니다. |
| 400 | Bad Request | 클라이언트의 잘못된 요청으로 서버가 요청을 처리할 수 없습니다. |
| 401 | Unauthorized | 인증이 필요하지만 제공되지 않았거나 인증이 실패한 경우 발생합니다. |
| 403 | Forbidden | 클라이언트가 리소스에 접근할 권한이 없습니다. |
| 404 | Not Found | 요청한 리소스를 찾을 수 없습니다. 잘못된 URL이거나 리소스가 존재하지 않는 경우입니다. |
| 500 | Internal Server Error | 서버에서 요청을 처리하는 중에 예기치 못한 오류가 발생했습니다. 주로 서버 측 문제입니다. |
| … | … | … |
★ 원하는 웹페이지에서 개발자 도구 열고 내용을 확인해 보세요.
-
Ctrl+SHift+C또는F12-
Network Tab 열고 홈페이지 refresh하면 HTTP requests 내용 확인 가능
- 패키지 이름도 page request에서 온 것
- 일종의 emulrator(한 시스템에서 다른 시스템을 복제해 두 번째 시스템이 첫 번째 시스템을 따라 행동하는 것) → 클라이언트의 행위를 따라해준 것
-
e.g.
네이버 홈페이지 열고 개발자 도구 > 네트워크 탭 → https request emulate
'기념일'이라는 쿼리를 입력한 것부터 내가 서버에 날린 내용이 기록되고 결과가 돌아온 걸 Response에서 확인 가능(html 파일 확인 가능 → 우리가 눈으로 보는 결과 화면이 html 파일!) -
GET Request가 보내진 다음에 Response로 html을 받아 홈페이지 화면이 보이는 것!
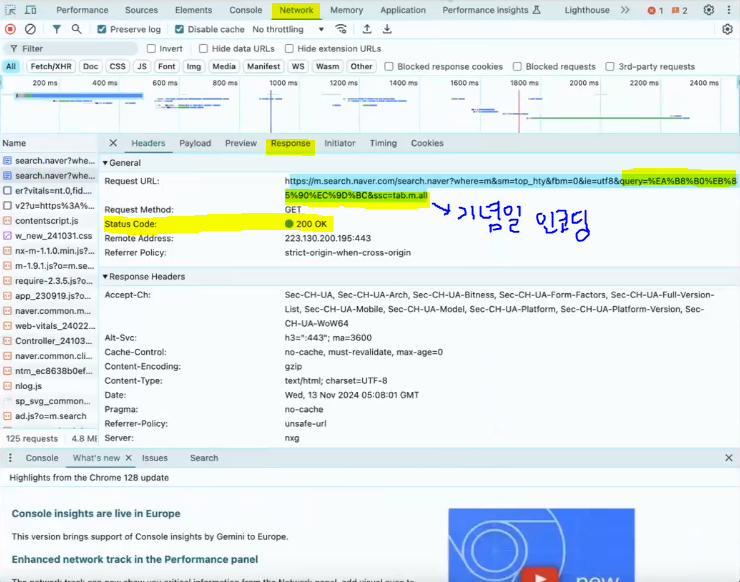
→ 내가 보낸 거
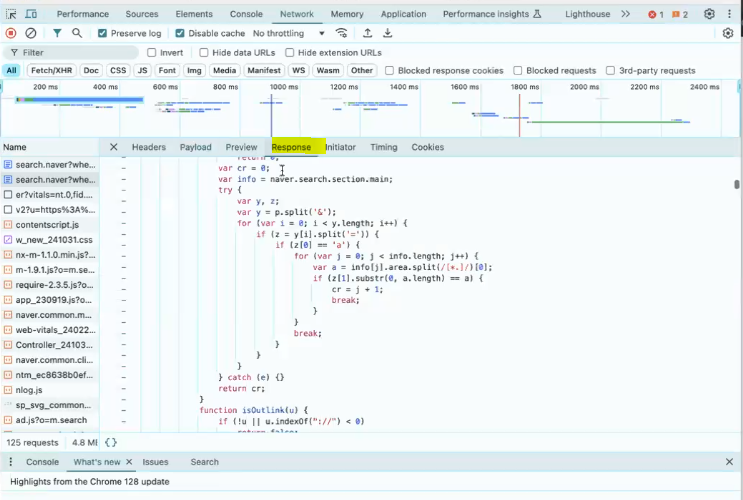
→ 내가 받은 거
-
실습
01. 패키지 불러오기
import requests
import pandas as pd
from bs4 import BeautifulSoup02. Requests를 통해 웹사이트 HTML 가져오기
url = "https://search.naver.com/search.naver?query=서울날씨" # 예제 URL
response = requests.get(url)
print(response.status_code) # 상태코드 출력
# 실행 결과: 200BeautifulSoup을 사용하여 HTML 파싱 및 데이터 추출
- HTML에서 필요한 데이터를 추출하려면
BeautifulSoup이 필요- HTML을 쉽게 탐색하고 데이터를 가져오는 데 유용한 라이브러리
- HTML 태그 종류를 알아야 우리가 원하는 데이터를 가져올 수 있음
- parsing 작업을 하는 게 BeautifulSoup이라고 생각하면 됨
- HTML을 쉽게 탐색하고 데이터를 가져오는 데 유용한 라이브러리
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')| 함수 | 설명 | 활용방법 | 파라미터 설명 |
|---|---|---|---|
| soup.select_one(selector) | CSS 셀렉터로 일치하는 첫 번째 요소를 반환합니다. | 특정 HTML 클래스, 태그 또는 id 값을 가진 첫 번째 요소를 선택할 때 유용합니다. | - selector: CSS 선택자 문자열을 사용하여 태그, 클래스, id 등을 선택. 예) 'div > p.intro' |
| soup.find(name, attrs) | 지정된 조건과 일치하는 첫 번째 태그를 찾고 반환합니다. | 특정 HTML 태그나 특정 속성 값을 가진 요소를 탐색할 때 사용합니다. | - name: 찾으려는 태그의 이름 (예: 'div'). |
- attrs: 특정 속성을 가진 태그를 찾기 위한 속성 딕셔너리 (예: {'class': 'example-class'}). | |||
| soup.findAll(name, attrs) | 지정된 조건과 일치하는 모든 태그를 리스트로 반환합니다. | 문서 내에서 여러 개의 HTML 특정 태그나 속성을 찾고자 할 때 사용합니다. | - name: 찾으려는 태그의 이름 또는 리스트 (예: 'p' 또는 ['div', 'span']). |
- attrs: 특정 속성을 가진 태그를 찾기 위한 속성 딕셔너리 (예: {'class': 'example-class'}). |
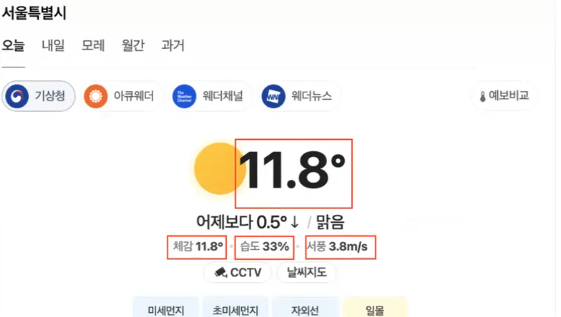
- 형태를 알고 싶으면 copy>copy selectors해서 코드 안에 넣어주면 됨
- 체감 온도:
#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(1) > dd
- 체감 온도:
예시
soup.select_one메서드로 원하는 데이터 찾기select_one메서드는 CSS 선택자를 사용하여 특정 조건을 만족하는 첫 번째 HTML 요소를 찾는 데 유용함
soup.select_one('CSS 선택자')- CSS 선택자
- HTML 요소를 선택하기 위해 CSS 스타일의 선택자를 사용
- 예:
div.classname
pan#idname
a[href="link"]
…
- 예:
- HTML 요소를 선택하기 위해 CSS 스타일의 선택자를 사용
→ 위에서 찾은 체감 온도의 경우 아래와 같이 쓰면 됨:
soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(1) > dd')추가 내용
★ 1번과 2번 코드 차이 이해하기
- 1번
element = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(1) > dd')
print(element)
print(element.text)실행 결과:
<dd class="desc">11.8°</dd>
'11.8°'- 2번
feel_temp = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(1) > dd').get_text()
print(feel_temp)실행 결과:
'11.8°'실습
03. bs4를 통해 HTML 파싱
url = "https://search.naver.com/search.naver?query=서울날씨"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')03-1. CSS Selector로 추출
feel_temp = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(1) > dd').get_text()
humidity = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(2) > dd').get_text()
wind = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(3) > dd').get_text()
print("체감온도:\t", feel_temp)
print("습도:\t", humidity)
print("서풍:\t", wind)네이버에서 "서울날씨" 정보 가져오기
requests을 사용하여 네이버 날씨 페이지에 접속해 HTML 응답 가져오기BeautifulSoup및select_one을 사용하여 체감온도, 습도, 서풍 정보를 추출
url = "https://search.naver.com/search.naver?query=서울날씨"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
feel_temp = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(1) > dd').get_text()
humidity = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(2) > dd').get_text()
wind = soup.select_one('#main_pack > section.sc_new.cs_weather_new._cs_weather > div > div:nth-child(1) > div.content_wrap > div.open > div:nth-child(1) > div > div.weather_info > div > div._today > div.temperature_info > dl > div:nth-child(3) > dd').get_text()
print("체감온도:", feel_temp)
print("습도:", humidity)
print("서풍:", wind)selector 파라미터 이용
.select_one(selector)- CSS 셀렉터로 일치하는 첫 번째 요소를 반환
.select_all(selector)- CSS 셀렉터로 일치하는 모든 요소를 반환
(전체에서 모두 가져옴)
- CSS 셀렉터로 일치하는 모든 요소를 반환
HTML Tag 이용: name, attrs 파라미터 ★
- HTML 구조를 파악한 다음 사용하면 매우 효과적
.find(name, attrs)- 지정된 조건과 일치하는 첫 번째 태그를 찾고 반환
- HTML 클래스가 어떤 구조로 되어 있는지 파악해야 활용할 수 있음!
- 지정된 조건과 일치하는 첫 번째 태그를 찾고 반환
today = soup.find('div', {'class': '_today'})
today실행 결과:
<div class="_today"> <div class="weather_graphic"> <div class="weather_main"> <i class="wt_icon ico_wt6"><span class="blind">구름많음</span></i> </div> <div class="temperature_text"> <strong><span class="blind">현재 온도</span>14.9<span class="celsius">°</span></strong> </div> </div> <div class="temperature_info"> <p class="summary">어제보다 <span class="temperature up">1.6° <span class="blind">높아요</span> </span> <span class="weather before_slash">구름많음</span> </p> <dl class="summary_list"> <div class="sort"> <dt class="term">체감</dt> <dd class="desc">14.9°</dd> </div> <div class="sort"> <dt class="term">습도</dt> <dd class="desc">61%</dd> </div> <div class="sort"> <dt class="term">서풍</dt> <dd class="desc">1.1m/s</dd> </div> </dl> </div> </div>print(today.text)실행 결과:
구름많음 현재 온도14.9° 어제보다 1.6° 높아요 구름많음 체감 14.9° 습도 61% 서풍 1.1m/s
→ 이 텍스트를 가지고 split해서 활용해도 되지만 더 섬세하게 하고 싶다면 .findall(class)을 쓰자
summaries = today.find('dl', {'class': 'summary_list'}).find_all('dd')
summaries실행 결과:
[<dd class="desc">14.9°</dd>,
<dd class="desc">61%</dd>,
<dd class="desc">1.1m/s</dd>]→ 하나였던 걸 나눠서 리스트 형식으로 만들어 줌
feel_temp = summaries[0].get_text()
humidity = summaries[1].get_text()
wind = summaries[2].get_text()
print("체감온도:\t", feel_temp)
print("습도:\t", humidity)
print("서풍:\t", wind)실행 결과:
체감온도: 14.9°
습도: 61%
서풍: 1.1m/s
추가: for문으로도 가능
summaries_ver2 = today.find('dl', {'class': 'summary_list'}).find_all('div')
metrics = []
for element in summaries_ver2:
metrics.append(element.find('dd'))
metrics실행 결과:
[<dd class="desc">14.9°</dd>,
<dd class="desc">61%</dd>,
<dd class="desc">1.1m/s</dd>]for element in metrics:
print(element.text)실행 결과:
14.9°
61%
1.1m/s
실습
03-2. HTML Tag로 추출
today = soup.find('div', {'class': '_today'})
summaries = today.find('dl', {'class': 'summary_list'}).find_all('dd')
feel_temp = summaries[0].get_text()
humidity = summaries[1].get_text()
wind = summaries[2].get_text()
print("체감온도:\t", feel_temp)
print("습도:\t", humidity)
print("서풍:\t", wind)★ web scraping은 예술 쪽과도 관련이 있다고 함! → 웹사이트 개발자가 이 데이터를 어떻게 넣었냐? 어떤 클래스에 넣었냐? 이거에 따라서 작업이 쉬울 수도 있고 반대로 본인들만 알 수 있게끔 지어가지고 그럴 때는 고생을 좀 해야 함
★ Selector로 하면 엄청 명확하게(specific하게) 복사가 되어서 포멧이 엄청 길어짐 → 웹사이트 개발자가 특정 클래스 이름을 변경하기라도 하면 바로 코드 마비됨 → 이걸 어느 정도 방지하려고 포멧을 조금이라도 이제 미리 파악을 해서 find로 쓰는 걸 권장하는 workaround가 있음
수집한 데이터를 CSV 파일로 저장
- 수집한 데이터를 CSV 파일로 저장하여 활용할 수 있음
import pandas as pd
# 데이터 준비
data = [{'temperature': feel_temp, 'humidity': humidity, 'wind': wind}]
# DataFrame 생성 및 CSV 파일로 저장
df = pd.DataFrame(data)
df.to_csv('weather_webscraping.csv', index=False)
print("날씨 정보가 CSV 파일로 저장되었습니다.")- 방식 1: Direct
- working directory(현재 작업하고 있는 공간)에 기본적으로 저장됨
- 작업하고 있는 공간 내에서 특정 경로를 원한다면 data/...로 설정: 폴더를 추가해서 거기 저장함
- 방식 2: Relative
- relative space에 full path를 넣어도 됨:
C:\Users\Pigeon\Desktop
- relative space에 full path를 넣어도 됨:
Web Scraping 장단점
장점
- 데이터 수집 자동화
- 대량의 데이터를 자동으로 수집할 수 있어 시간과 노력을 절약할 수 있음
- 다양한 데이터 확보 가능
- 웹 페이지에서 다양한 형태의 데이터(텍스트 등)를 가져올 수 있음
- 비정형 데이터(e.g. 뉴스 기사 등)도 가져올 수 있음!
- 웹 페이지에서 다양한 형태의 데이터(텍스트 등)를 가져올 수 있음
- 빠른 데이터 수집
- 특정 웹사이트에서 데이터를 실시간으로 빠르게 수집할 수 있음
단점
- 법적/윤리적 문제
- 일부 웹사이트는 크롤링을 금지하며, 무단 크롤링은 법적 문제를 야기할 수 있음
- 웹 구조 변경에 취약
- 웹페이지 구조가 변경되면 크롤링 코드가 작동하지 않을 수 있음
- HTML 클래스의 이름에 의존하기 때문(selector, find 모두)에 안정도나 안정성이 떨어짐
- 웹페이지 구조가 변경되면 크롤링 코드가 작동하지 않을 수 있음
- 서버 부하 유발
- 지나친 크롤링은 대상 웹사이트에 과부하를 줄 수 있으며, IP 차단 등의 조치를 당할 수 있음
- 크롤링은 어떻게 보면 인간이 하는 행동(검색하고 이것저것 누르기 등)을 따라하는 행동인데 그게 너무 많이 지속되고 너무 빠른 요청을 계속 많이 하면 일종의 디도스 공격이 될 수 있기 때문에 크롤링을 한다면 너무 자주는 안 하는 걸 추천(1초마다는 X. 하루에 한 번, 1시간에 한 번 정도만 스케줄링)
- 지나친 크롤링은 대상 웹사이트에 과부하를 줄 수 있으며, IP 차단 등의 조치를 당할 수 있음
- 데이터 품질 문제
- 비구조적이고 일관되지 않은 데이터로 인해 추가적인 전처리가 필요할 수 있음
- 웹 개발자들이 웹사이트 구조를 바꾼다거나, 태그 위치를 옮긴다거나, 단위를 바꾼다거나 할 때 공지가 뜨는 게 아니라 바뀐 걸 인지하지 못하고 코드가 돌아가면 데이터의 퀄리티 이슈가 발생할 수 있음
- 비구조적이고 일관되지 않은 데이터로 인해 추가적인 전처리가 필요할 수 있음
★ Term 주는 것도 가능함: 일정 시간마다 데이터를 수집하도록 하고 싶은 경우 time을 import한 뒤 활용하면 됨
import time
# 아래 코드 형식만 참고(실제론 안 돌아감)
for i in range(100):
response = requests.get(url)
time.sleep(1)
soup = BeautifulSoup(response.text, 'html.parser')★ 프로그램적으로 하고 싶은 경우 API Rate limiting 같은 패키지를 써서 조정 가능
→ 구글에 'request limit control' 검색해보기
번외: Time.sleep으로 과부화 줄이기
- 미세먼지 현황 파악
import time
import requests
from bs4 import BeautifulSoup
import pandas as pd
for i in range(3): # 3번 돌리기
url = "https://search.naver.com/search.naver?query=미세먼지"
if response.status_code == 200: # Code 200 일때만 수행
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('div', {'class': 'tb_scroll'}).find('table')
# Extract headers
headers = [th.get_text() for th in table.find('thead').findAll('th')]
# Extract rows
rows = []
for tr in table.find('tbody').find_all('tr'):
cells = tr.find_all(['th', 'td'])
row = [cell.get_text().strip() for cell in cells]
rows.append(row)
# Create DataFrame
df = pd.DataFrame(rows, columns=headers)
print(df)
time.sleep(5) # 5초마다 휴식 객체 지향 프로그래밍 Object Oriented Programming (OOP)
- 현실 개념을 코드로 모델링 가능
- 클래스와 객체를 사용하여 현실의 개념과 행동을 코드로 표현
- 코드 재사용성과 유지보수성 향상
- 한 번 작성한 클래스를 여러 객체에 재사용할 수 있으며, 유지보수가 쉬움
- 복잡한 문제 해결에 유리
- 코드의 모듈화로 문제를 작은 단위로 나눌 수 있어 시스템을 보다 쉽게 관리할 수 있음
- 캡슐화, 상속, 다형성 지원
- 데이터 보호, 재사용성 증가, 유연한 동작 가능
🡆 OOP는 데이터를 관리하고 재사용 가능한 코드를 작성하는 데 중요한 역할 → 데이터 수집 파이프라인을 구축할 때도 OOP 개념을 활용하면 더 견고하고 확장 가능한 코드를 만들 수 있음
🡆 production에 옯기거나 배포를 하고 싶으면 작성한 코드를 정리해 주어야 함 → 어떻게 정리할 것인가?에 대한 개념 중 하나가 바로 OOP
🡆 여러 가지 현실 개념들(e.g. 함수 등)을 사용해 코드를 표현 → 우리가 쓴 함수 등을 여러 군데에서 쓰고 싶음 → e.g. 철수라는 사람이 자기가 쓰는 프로그래밍 여러 가지 개발 코드에서 우리가 짠 웹크롤링 코드를 쓰고 싶다고 요청하면 우리는 작성한 웹크롤링 코드를 객체로 만들어서 드리면 됨: 코드 재사용성
e.g. 본인의 코드를 목적에 맞게 작은 단위로 나눠서 모듈화를 해서(보통 함수로 따로 조그맣게 모듈화) 넘겨줄 수도 있음
예시: 학생(Student)이라는 객체 만들어보기
- 학생을 처음 정의(
__init__)할때 name (이름)과 age (나이)를 설정해야 함- OOP에는 클래스와 객체가 있음
- class는 '개념'이라고 생각하면 됨
__init__은 필수인 변수를 설정: 학생이라는 개념을 만들 때 이름이랑 나이는 꼭 들어가야 되는 것이라고 컴퓨터에게 알려주는 것- class 안에 우리가 이 객체(예시에서는 학생)가 할 수 있는 것들을 함수로 표현
- OOP에는 클래스와 객체가 있음
- 학생은 인사(
introduce)를 할 수 있음 - 학생을
print할 때는 학생 정보가 출력됨- 누군가 학생들 자체를 출력하고 싶을 수 있으니
__str__로print(Student(name, age))했을 때 출력될 학생에 대한 정보를 만들어 줌
- 누군가 학생들 자체를 출력하고 싶을 수 있으니
# 클래스 정의
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def introduce(self):
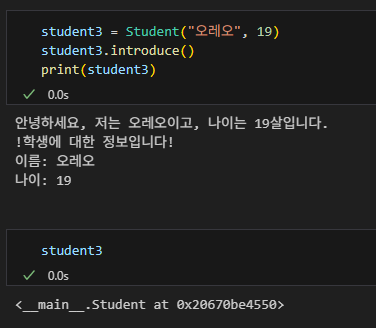
print(f"안녕하세요, 저는 {self.name}이고, 나이는 {self.age}살입니다.")
def __str__(self):
return f"!학생에 대한 정보입니다!\n이름: {self.name}\n나이: {self.age}"
# 객체1, 홍길동 생성
student1 = Student("홍길동", 20)
student1.introduce()
print(student1)
# 객체2, 이영희 생성
student2 = Student("이영희", 22)
student2.introduce()
print(student2)🡆 학생이라는 개념을 만들어 주고 각각 함수 같은 걸 추가해가지고 이 학생(객체)이 할 수 있는 행동을 정의해 주는 것!
🡆 학생 클래스를 정리를 해 주면 이 다음부터 이와 관련된 사람을 계속 인스턴스를 만들 수 있어요. 이걸 이제 객체라고 합니다! → 클래스를 통해서 객체를 만듦
🡆 student1이라는 변수를 만들 때 student1 안에 Student() 클래스의 파라미터를 두 개 넣어서(이름: 홍길동, 나이: 20) 정의
추가: self
- 자기 자신한테 뭔가 설정을 해줘야 해서 꼭 들어가야 함 → 초기 값 설정
self.name: 자기 자신한테 name 설정- "나는 name이 있어야 함"
def introduce(self):: 자기 자신에게 설정했던 name, age를 불러와서 쓰겠다는 것
기타 QnA
- 금융투자협회에서 종목가격 크롤링 등 하는 경우 많음
- 실시간 주가 확인을 위한 것(완전 실시간은 아닌데 그래도 업데이트를 계속 받을 수 있음)
- '주식 데이터 크롤링' 구글링해보세요
- wikidocs: 종목의 가격 데이터 크롤링
- github: 국내 주식 데이터 수집
- https://freesis.kofia.or.kr
-
크롤링만 가지고 회사 차린 경우도 있음: ScrapingBee
-
기업들은 크롤링을 좋아하지 않아서 api를 쓰라고 주는 경우도 있음
- 찾고자 하는 데이터 소스(api)가 없을 때 크롤링을 사용
Web Scrapting 하다가 자바스크립트 만나면?
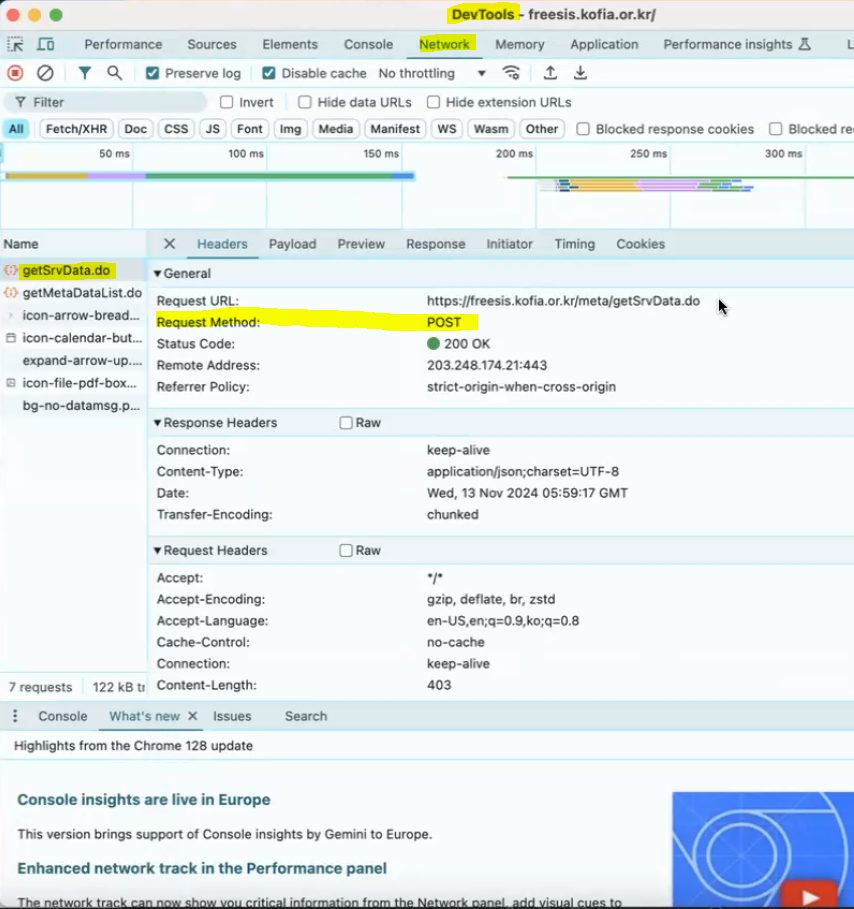
request.post- 홈페이지에서 이것저것 누르는 데 HTML이 똑같으면 자바스크립트로 처리되고 있는 것:
동적 웹사이트 →request.post를 사용해야 함
- 홈페이지에서 이것저것 누르는 데 HTML이 똑같으면 자바스크립트로 처리되고 있는 것:
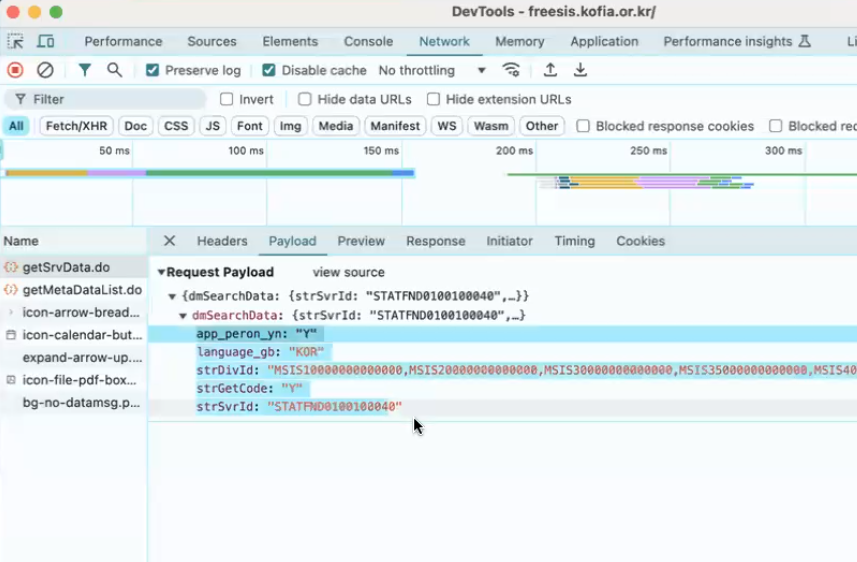
- request method가 post인 경우 parameter추가해서 처리
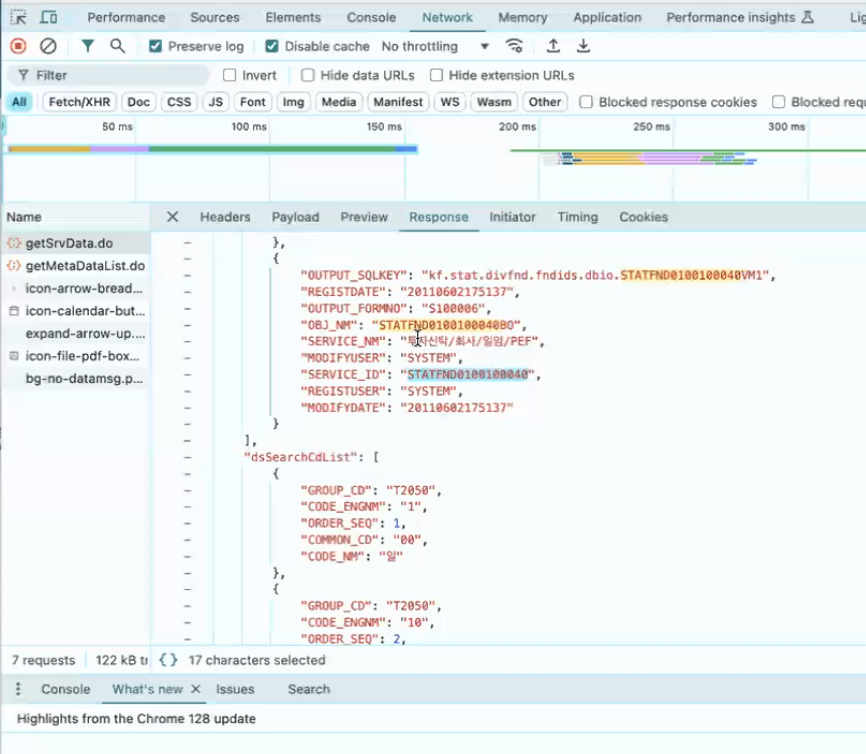
- 개발자 모드 > network에서 어떤 게 post를 던지는지 파악해야 함
과제
- 네이버 경제 > 증권 뉴스에 보이는 뉴스 제목을 출력해주세요!
- 가이드를 따라 OpenWeather API에서 API KEY를 발급해 주세요.
