데이터 전처리(Pandas)
목표
- Python의 Pandas 라이브러리를 활용해 데이터를 전처리하는 과정 학습
데이터 전처리
- 내가 데이터를 보기 위해 하는 모든 활동 == 데이터 전터리
- Excel에서 컬럼 가공하고 조건 걸고 하는 행동이 데이터 전처리
- Excel → 개발자가 아닌 사람에게 가장 중요한 데이터 툴
- Excel에서 컬럼 가공하고 조건 걸고 하는 행동이 데이터 전처리
- 데이터 전처리를 엑셀 말고 Python을 활용해보기
데이터 전처리를 해야 하는 이유
-
실제 데이터는 원하는 형태로 구축되어 있지 않음
- 우리가 생각하는 데이터: 깔끔, 정석
- 실제 데이터: 디지털 쓰레기…😭
-
결국 데이터를 하나하나 가공해서 활용해야 함
-
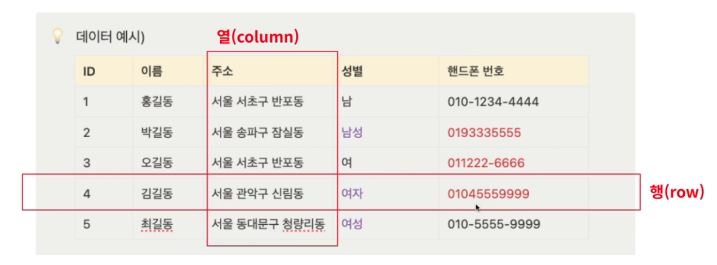
데이터 예시
| ID | 이름 | 주소 | 성별 | 핸드폰 번호 |
|---|---|---|---|---|
| 1 | 홍길동 | 서울 서초구 반포동 | 남 | 010-1234-4444 |
| 2 | 박길동 | 서울 송파구 잠실동 | 남성 | 0193335555 |
| 3 | 오길동 | 서울 서초구 반포동 | 여 | 011222-6666 |
| 4 | 김길동 | 서울 관악구 신림동 | 여자 | 01045559999 |
| 5 | 최길동 | 서울 동대문구 청량리동 | 여성 | 010-5555-9999 |
→ 성별 남, 여로 구분해야하는데 남성, 여자, 여성 등 불규칙한 경우가 존재함
→ 핸드폰 번호를 확인할 때 ‘-’ 기호가 불규칙하게 존재함
- 데이터 분류
- 정형 데이터
- excel이나 표 형태로 나타내는 데이터
- 열과 행이 명확하게 존재하는 경향
- 비정형 데이터
- 이미지, 목소리, 오디오 등 다양한 형식
- 정형 데이터
데이터 전처리는 어떻게 해야 할까?
- 데이터 전달의 목적성
- 꼭 방향성을 가지고 해야 함
- 데이터를 통해 무엇을 확인할 것인가?
- 어떤 의사결정을 위해 필요한가?
- 데이터를 통해 무엇을 얻고자 하는가?
- 목적을 달성하기 위해 데이터 전처리가 필요
- 꼭 방향성을 가지고 해야 함
- 데이터 전달의 효과성
데이터셋 불러오기
- Seaborn이라는 라이브러리에서 불러올 수 있는 내장데이터셋을 가지고 실습을 진행
- iris 데이터셋: 붓꽃의 꽃잎과 꽃받침의 길이와 너비를 포함한 데이터셋
- tips 데이터셋: 음식점에서의 팁과 관련된 정보를 담고 있는 데이터셋
- titanic 데이터셋: 타이타닉 호 승객들의 정보를 포함한 데이터셋
- flights 데이터셋: 연도별 항공편 정보를 담고 있는 데이터셋
- planets 데이터셋: 외계 행성 발견에 대한 정보를 담고 있는 데이터셋
import seaborn as sns
# 'tips' 데이터셋 불러오기
tips_data = sns.load_dataset('tips')
# 데이터셋 확인
print(tips_data.head())데이터 다루기 Excel vs. Pandas
-
자동화와 프로그래밍 기능
- Pandas는 다양한 라이브러리를 사용하여 데이터를 불러오고, 변환하며, 분석 → 이를 통해 반복적이고 복잡한 작업을 자동화 할 수 있음
- 엑셀은 시각적 사용자 인터페이스를 통해 데이터를 다루는 스프레드시트 프로그램 → 작업은 주로 수동으로 수행되며, 고급 기능을 프로그래밍적으로 확장하기가 어려움
-
대용량 데이터 처리
- Pandas는 대용량 데이터를 처리하는 데 유용합니다. 메모리 내에서 데이터를 처리하거나, 큰 데이터 세트를 조각으로 나누어 처리할 수 있는 기능을 제공
- 엑셀은 상대적으로 작은 크기의 데이터셋을 다루는 데 적합 → 매우 큰 데이터를 처리할 경우에는 처리 속도가 느려질 수 있고, 파일 크기 제한 등의 제약이 있을 수 있음
-
복잡한 데이터 처리 및 분석
- Pandas는 데이터 분석 및 처리를 위한 다양한 도구와 라이브러리를 활용 가능하며, 데이터를 다양한 방식으로 조작하고 분석할 수 있음 → 복잡한 데이터 작업, 통계 분석, 머신러닝 모델 구축 등이 가능
- 셀은 기본적인 수식과 함수를 통해 데이터를 처리하고 시각화할 수 있지만, 복잡한 데이터 조작이나 분석에는 제약이 있을 수 있음
-
확장성과 유연성
- PPython은 다양한 데이터 포맷을 처리할 수 있는 라이브러리를 지원하며, 데이터베이스와 연동하여 작업할 수 있는 등 매우 유연
- 엑셀은 주로 특정 데이터 형식의 파일 (.xlsx, .csv 등)을 다루는 데에 제한되어 있음
-
버전 관리 및 자동화
- Python 코드는 버전 관리 시스템(Git 등)을 사용하여 변경 내역을 관리하고, 코드 자체에 주석을 추가하거나 문서화할 수 있어 작업 히스토리를 추적하기 용이
- 엑셀은 사용자가 직접 수정하기 때문에 변경 사항을 추적하거나 문서화하기 어려움
💡 엑셀이 엄청나게 좋은 툴이라는 사실은 변함 없음! 그러나, Pandas만의 장점이 존재함
- Pandas은 대규모 데이터셋 및 복잡한 작업을 처리하는 데 효과적이며, 자동화와 프로그래밍 기능을 통해 더 많은 유연성과 확장성을 제공합니다.
- 반면에 엑셀은 상대적으로 작은 규모의 데이터나 간단한 작업에 유용하며, 비전문가가 쉽게 사용할 수 있는 직관적인 인터페이스를 제공합니다.
Pandas란?
- Python에서 데이터를 조작하고 쉽게 분석할 수 있게 도와주는 라이브러리
Pandas 활용 장점
- 대용량 데이터 처리 가능
- Pandas는 데이터를 메모리에 로드하고, 다양한 연산을 빠른 처리가 가능하며 대용량 데이터를 처리하는데 최적화되어 있음
- 데이터 조작 기능
- 데이터 정렬, 필터링, 집계, 결측값 처리 등 데이터를 쉽게 가공할 수 있음
- 데이터 시각화 기능 제공
- Matplotlib, Seaborn , … , etc
- 데이터를 구조화하여 분석할 수 있음
- DataFrame이라는 자료형을 제공하여 데이터를 표 형태로 나타내어 분석이 가능
Pandas 구조
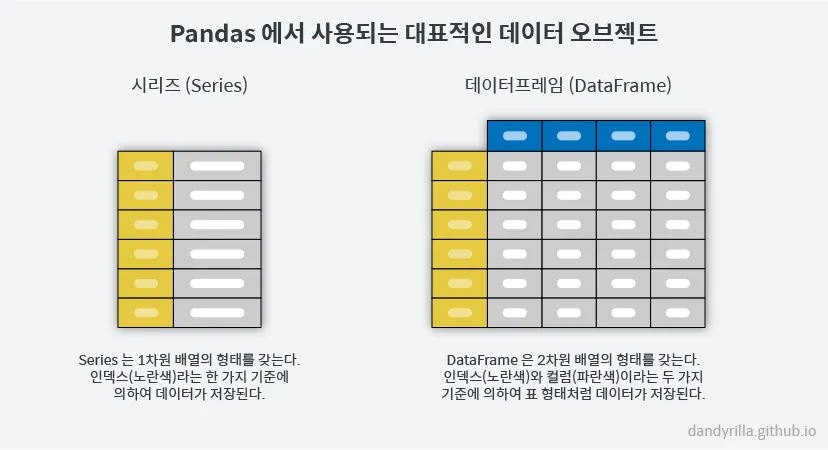
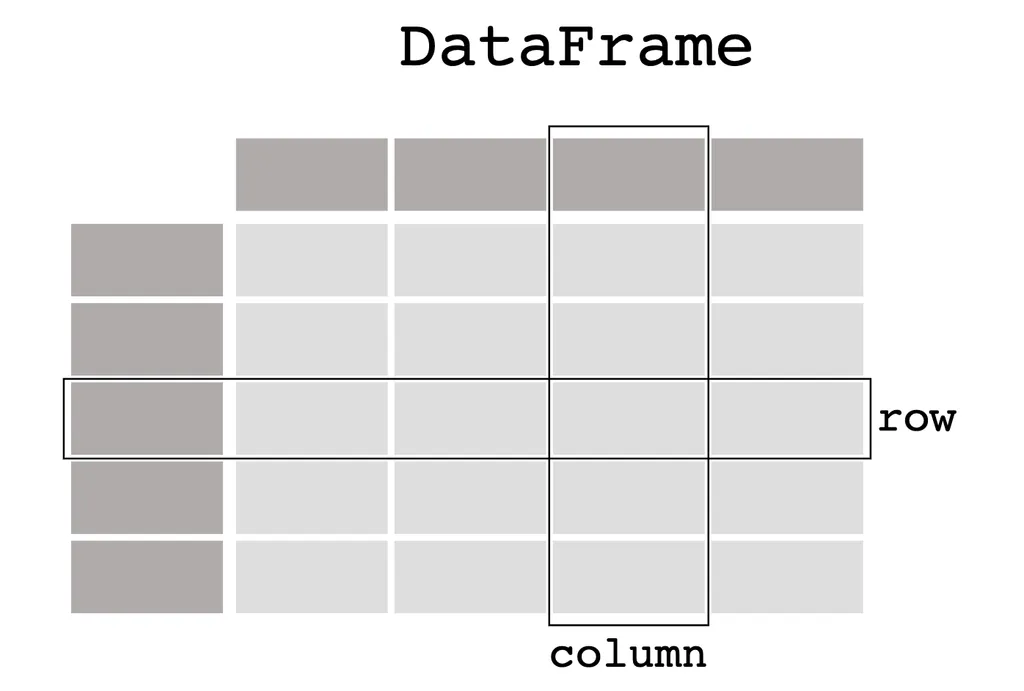
- DataFrame
- 표 형태
- index
- 각 아이템을 특정할 수 있는 고유의 값
- 엑셀에서는 좌측 열순서로 생각하면 됨
- columns
- 하나의 속성을 가진 데이터 집합
- Series
- 하나의 속성을 가진 데이터 집합
- DataFrame 표에서 열 1줄이라고 생각하면 쉬움
- value + index

2 B R 0 2 B