데이터 시각화(Matplotlib)
- 데이터 시각화를 어떤 목적으로 해야할지를 이해하고 데이터를 시각화하는 방법을 학습
목적
- 데이터 시각화를 통해 얻을 수 있는 것은 무엇일까?
1) 데이터 시각화가 중요한 이유
- 바다 오염의 주범은 빨대다?
- 요즘은 카페에서 종이빨대를 사용
- 이는 바다거북이가 코에 빨대가 박혀 고통스러워하는 영상이 확산되며 환경오염에 대한 인식을 개선하기 위해 여러 환경단체 및 기관에서 노력한 결과
- 그러나, 바다 오염의 주범인 바다쓰레기를 줄이기 위해서 시작한 빨대 사용금지가 얼마나 효과가 있을까?
- 데이터 분석가로서 실제 바다 오염을 줄이는 프로젝트를 맡게되었다고 가정
- 실제 데이터를 살펴보면, 전세계 바다 쓰레기의 0.03%가 플라스틱(빨대)로 인한 것이고, 가장 많이 문제가 되고 있는 것은 46%를 차지하는 어망(어업도구)라는 것을 알 수 있음
- 실제 바다 쓰레기의 약 50% 어업활동으로 인해 발생했다는 사실을 바탕으로 어떤 의사결정을 할 수 있을까?
- 효율/효과 측면
- 어업 활동에서 발생하는 바다 쓰레기를 줄이는 방안을 모색해야 한다고 분석결과를 전달할 수 있음
- 종이 빨대를 만드는 예산을 어업활동에서 쓰레기가 발생하지 않도록 개선시키는 것에 활용하는 것도 제안할 수 있음
- 효율/효과 측면
- 즉, 어디에 집중을 하고 어떤 전략을 수립해야할지 방향을 제시하는 역할을 데이터를 통해 전달하는 것이 데이터 분석의 역할이며, 분석된 결과에 따라 다양한 의사결정이 이루어질 수 있음
- 의사 결정을 더욱 쉽게 할 수 있도록 데이터를 잘 전달해야 함
- 데이터 시각화는 이러한 의사결정을 잘할 수 있게 도와줄 수 있음
- 예를 들어, 정말로 (예산부족으로) 빨대를 줄이기 위해 노력하는 활동에 투입되는 예산을 어업활동에서 발생하는 쓰레기를 줄이는 것에 사용할 수 밖에 없는 경우에, 그것의 효과와 영향이 크다는 것을 인식시키고 설득시킬 때 데이터 시각화는 매우 중요한 요소가 됨
- 전체 바다쓰레기의 100% 중 0,03%와 46%의 비중과 투입되는 예산대비 얻게될 기대효과에 대해 시각화된 자료와 함께 분석결과를 전달할 수 있다면, 여러분의 분석은 큰 설득력을 갖추게 될 것
2) 데이터 시각화의 목적
(1) 패턴 발견 및 이해
- 데이터 시각화는 데이터 내의 숨겨진 패턴을 발견하고, 이해하는 데 도움을 줍니다. 그래프나 차트를 통해 데이터의 특징을 시각적으로 파악할 수 있음
사례
- 시간에 따른 매출 추이 분석
- 시간(월, 분기, 연도 등)에 따른 매출 추이를 선 그래프로 시각화하면, 매출의 계절적 변동이나 특정 시기의 매출 증감 패턴을 쉽게 파악할 수 있음
- 이를 통해 특정 시기에 매출이 감소하는 이유나 증가하는 이유를 이해할 수 있음
- 지역별 매출 비교 분석
- 지도를 이용하여 지역별 매출을 시각화하면, 각 지역의 매출 패턴을 파악할 수 있음
- 지역 간의 매출 차이나 특정 지역에서의 매출 높은 이유를 이해할 수 있음
- 제품 카테고리별 매출 분석
- 막대 그래프나 원형 차트를 사용하여 제품 카테고리별 매출을 시각화하면, 어떤 카테고리가 가장 많은 매출을 올리는지 파악할 수 있음
- 이를 통해 인기 있는 제품 카테고리를 파악하거나, 특정 카테고리의 성장세를 이해할 수 있음
- 고객 구매 패턴 분석
- 히스토그램이나 상자 그림(Box Plot)을 사용하여 고객의 구매 패턴을 시각화하면, 평균 구매액, 최고/최저 구매액, 이상치 데이터 등을 파악할 수 있음
- 이를 통해 고객들의 구매 습관이나 행동을 이해할 수 있음
(2) 의사 결정 지원
- 시각화는 복잡한 데이터를 이해하고 결정을 내리는 데 도움을 제공
- 시각화를 통해 정보를 명확하게 전달하여 의사 결정 과정을 지원
사례
- 마케팅 캠페인 효과 분석
- 시간에 따른 매출 또는 고객 유입량의 변화를 추적하는 선 그래프를 사용하여, 마케팅 캠페인을 실행한 시점 이후의 변화를 확인할 수 있음
- 이를 통해 마케팅 캠페인이 실제로 기업의 매출 또는 고객 유입에 어떤 영향을 미치는지를 시각적으로 확인할 수 있음
- 캠페인 채널별 효과 비교
- 막대 그래프나 원형 차트를 사용하여 각 마케팅 캠페인 채널(소셜미디어, 이메일, 광고 등)별로 매출이나 고객 획득량을 비교할 수 있음
- 이를 통해 어떤 채널이 가장 효과적인지 판단하고, 자원을 최적으로 분배할 수 있음
- 고객 반응 분석
- 히스토그램이나 상자 그림을 사용하여 특정 마케팅 캠페인에 참여한 고객들의 반응을 분석할 수 있음
- 고객들의 평균 구매액 증가, 반응 시간의 변화 등을 시각화하여 캠페인의 효과를 좀 더 깊이 있게 이해할 수 있음
- A/B 테스트 결과 시각화
- A/B 테스트 결과를 바탕으로 한 그래프를 통해, 다른 버전의 마케팅 캠페인이나 웹페이지 등의 변화가 어떻게 고객 행동에 영향을 미치는지 확인할 수 있음
- 이를 통해 어떤 디자인 또는 콘텐츠가 더 효과적인지를 시각적으로 확인할 수 있음
(3) 효과적인 커뮤니케이션
- 시각화는 데이터 분석 결과를 다른 사람들과 공유하거나 설명할 때 유용
- 데이터를 시각적으로 보여주면 이해하기 쉽고 기억하기 쉬운 형태로 전달할 수 있음
사례
- 보고서와 프레젠테이션
- 다양한 차트, 그래프, 히트맵 등을 사용하여 데이터 분석 결과를 시각적으로 나타내면 보고서나 프레젠테이션을 더 효과적으로 구성할 수 있음
- 이를 통해 빠르고 명확하게 데이터의 핵심 내용을 전달할 수 있음
- 의사 결정자와의 논의
- 데이터 시각화를 통해 의사 결정자들과의 논의를 용이하게 할 수 있음
- 시각적인 그래프나 차트를 보여주면 의사 결정자들이 데이터를 더 쉽게 이해하고 빠르게 의사 결정을 할 수 있음
- 다양한 대중에게의 정보 전달
- 쉽게 이해할 수 있는 그래픽을 사용하여 데이터 분석 결과를 블로그, 보고서, 뉴스레터 등을 통해 다양한 대중에게 전달할 수 있음
- 이를 통해 보다 많은 사람들에게 데이터에 대한 인사이트를 제공할 수 있음
- 소셜미디어 및 인터넷 활용
- 효과적인 데이터 시각화는 소셜미디어 상에서 데이터 기반의 이야기를 공유하는 데 유용
- 인포그래픽, 그래픽 이미지 등을 활용하여 복잡한 데이터를 간결하게 전달하여 더 많은 관심을 끌 수 있음
- 간결하고 효과적인 커뮤니케이션
- A시각화를 통해 데이터의 핵심을 간결하게 전달할 수 있으며, 이를 통해 복잡한 정보를 시각적으로 이해하기 쉽게 만들어 줌
- 이는 전문가와 비전문가 모두가 쉽게 이해하고 의사 소통을 할 수 있게 도움
Matplotlib 알아보기
- Matplotlib
- 데이터 시각화 라이브러리 중 하나
- 다양한 종류의 그래프를 생성하기 위한 도구를 제공
- 2D 그래픽을 생성하는 데 주로 사용
- 선 그래프, 막대 그래프, 히스토그램, 산점도, 파이 차트 등 다양한 시각화 방식을 지원
- 그래프를 색상, 스타일, 레이블, 축 범위 등을 조절하여 원하는 형태로 시각화할 수 있음
그래프 도구 살펴보기
matplotlib.pyplot- plot() 함수
- 2차원 데이터를 시각화하기 위해 사용
- plot() 함수
import matplotlib.pyplot as plt
# 데이터 생성
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# 선 그래프 그리기
plt.plot(x, y)
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Example Plot')
plt.show()데이터셋 불러오기
- Seaborn이라는 라이브러리에서 불러올 수 있는 내장 데이터셋을 가지고 실습 진행
- iris 데이터셋: 붓꽃의 꽃잎과 꽃받침의 길이와 너비를 포함한 데이터셋
- tips 데이터셋: 음식점에서의 팁과 관련된 정보를 담고 있는 데이터셋
- titanic 데이터셋: 타이타닉 호 승객들의 정보를 포함한 데이터셋
- flights 데이터셋: 연도별 항공편 정보를 담고 있는 데이터셋
- planets 데이터셋: 외계 행성 발견에 대한 정보를 담고 있는 데이터셋
import seaborn as sns
# 'tips' 데이터셋 불러오기
tips_data = sns.load_dataset('tips')
# 데이터셋 확인
print(tips_data.head())그래프 그리기: 도구
- 그래프를 그리기 위해서 필요한 도구(축, 범례, 스타일, 텍스트) 배우기
Matplotlib.pyplot 에서 plot() 를 활용하는 법
pandas의plot()메서드는DataFrame객체에서 데이터를 시각화하는데 사용- 예를 들어, 선 그래프를 그리기 위해서는
plot()메서드를 호출하고x와y인수에 각각 x축과 y축에 해당하는 열을 지정
- 예를 들어, 선 그래프를 그리기 위해서는
import pandas as pd
import matplotlib.pyplot as plt
# 샘플 데이터프레임 생성
data = {
'A': [1, 2, 3, 4, 5],
'B': [5, 4, 3, 2, 1]
}
df = pd.DataFrame(data)
# 선 그래프 그리기
df.plot(x='A', y='B')
plt.show()스타일 설정하기
plot()메서드를 호출할 때 다양한 스타일 옵션을 사용하여 그래프의 스타일을 설정할 수 있음color,linestyle,marker등의 파라미터를 사용하여 선의 색상, 스타일, 마커 변경 가능
ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o')
plt.show()-
Color(색상)
- 색상은 문자열로 지정할 수 있음
- 'blue', 'green', 'red', 'cyan', 'magenta', 'yellow', 'black', 'white'와 같은 기본 색상 이름 또는 RGB 값을 직접 지정 가능
-
Linestyle(선 스타일)
- 선의 스타일은
'-'(실선),'--'(대시선),':'(점선),'-.'(점-대시선) 등으로 지정할 수 있음
- 선의 스타일은
-
Marker(마커)
- 마커는 데이터 포인트를 나타내는 기호
'o'(원),'^'(삼각형),'s'(사각형),'+'(플러스),'x'(엑스) 등 다양한 기호로 지정할 수 있음
-
matplotlib 공식 문저
범례 추가
legend()메서드를 사용하여 그래프의 범례를 추가
#1 label
ax = df.plot(x='A', y='B', color='green', linestyle='--', marker='o', label='Data Series')
#2 legend
ax.legend(['Data Series'])
#1번 또는 2번 방법으로 범례를 추가할 수 있습니다.
plt.show()축, 제목 입력
set_xlabel(),set_ylabel(),set_title()메서드를 사용하여 x축과 y축의 레이블 및 그래프 제목을 추가
ax.set_xlabel('X-axis Label')
ax.set_ylabel('Y-axis Label')
ax.set_title('Title of the Plot')
plt.show()텍스트 추가
text()메서드를 사용하여 그래프에 특정 위치에 텍스트를 추가
ax.text(3, 3, 'Some Text', fontsize=12)
plt.show()한꺼번에 설정하는 방법
plot()함수에color,linestyle,marker,label등의 파라미터로 스타일과 범례를 적용xlabel(),ylabel(),title(),legend(),text()함수들을 사용하여 각각의 설정을 추가plot()함수 자체에는 범례, 제목, 텍스트를 직접적으로 입력하는 기능 없음
import matplotlib.pyplot as plt
# 데이터 생성
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# 그래프 그리기
plt.plot(x, y, color='green', linestyle='--', marker='o', label='Data Series')
# 추가 설정
plt.xlabel('X-axis Label')
plt.ylabel('Y-axis Label')
plt.title('Title of the Plot')
plt.legend()
plt.text(3, 8, 'Some Text', fontsize=12) # 특정 좌표에 텍스트 추가
# 그래프 출력
plt.show()그래프 크게 만들기
plt.figure()함수를 사용하여 Figure 객체를 생성하고, 이후에figsize매개변수를 이용하여 원하는 크기로 설정할 수 있음figsize는 그래프의 가로와 세로 크기를 인치 단위로 설정
import matplotlib.pyplot as plt
# Figure 객체 생성 및 사이즈 설정
plt.figure(figsize=(8, 6)) # 가로 8인치, 세로 6인치
# 데이터 생성
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
# 그래프 그리기
plt.plot(x, y)
# 그래프 출력
plt.show()그래프 그리기: 차트
- 그래프 직접 그려보기
그래프 자료 유형
| 그래프 유형 | 자료 유형 | 특징 |
|---|---|---|
| Line Plot | 연속형 데이터 | 데이터의 변화 및 추이를 시각화 |
| Bar Plot | 범주형 데이터 | 카테고리 별 값의 크기를 시각적으로 비교 |
| Histogram | 연속형 데이터 | 데이터 분포, 빈도, 패턴 등을 이해 |
| Pie Chart | 범주형 데이터의 비율 | 범주별 상대적 비율을 부채꼴 모양으로 시각화 |
| Box Plot | 연속형 데이터의 분포 | 중앙값, 사분위수, 최소값, 최대값, 이상치 확인 |
| Scatter Plot | 두 변수 간 관계 | 변수 간의 관계, 군집, 이상치 등 확인 |
1) Line
- Line Plot(선 그래프)
- 데이터 간의 연속적인 관계를 시각화하는 데에 적합
- 주로 시간의 흐름에 따른 데이터의 변화를 보여줌
- 자료 유형
- 연속적인 데이터의 추이를 보여줄 때 사용
- 활용
- 시간에 따른 데이터의 변화, 추세를 보여줄 때 효과적
import pandas as pd
import matplotlib.pyplot as plt
# 데이터프레임 생성
data = {'날짜': ['2023-01-01', '2023-01-02', '2023-01-03'],
'값': [10, 15, 8]}
df = pd.DataFrame(data)
# '날짜'를 날짜 형식으로 변환
df['날짜'] = pd.to_datetime(df['날짜'])
# 선 그래프 작성
plt.plot(df['날짜'], df['값'])
plt.xlabel('날짜')
plt.ylabel('값')
plt.title('선 그래프 예시')
plt.show()
2) Bar vs. Histogram
- Bar Plot(막대그래프)
- 범주형 데이터를 나타냄
- 각각의 막대로 값의 크기를 비교하는 데에 사용
- 자료 유형
- 범주형 데이터 간의 비교를 나타낼 때 주로 사용
- 활용
- 카테고리 별로 값의 크기나 빈도를 시각적으로 비교할 때 유용
# 데이터프레임 생성
data = {'도시': ['서울', '부산', '대구', '인천'],
'인구': [990, 350, 250, 290]}
df = pd.DataFrame(data)
# 막대 그래프 작성
plt.bar(df['도시'], df['인구'])
plt.xlabel('도시')
plt.ylabel('인구')
plt.title('막대 그래프 예시')
plt.show()
- Histogram(히스토그램)
- 연속된 데이터의 분포를 보여줌
- 주로 데이터의 빈도를 시각화하여 해당 데이터의 분포를 이해하는 데 사용
- 자료 유형
- 연속형 데이터의 분포를 보여줄 때 사용
- 활용
- 데이터의 빈도나 분포, 패턴을 이해하고자 할 때 유용
import matplotlib.pyplot as plt
import numpy as np
# 데이터 생성 (랜덤 데이터)
data = np.random.randn(1000)
# 히스토그램 그리기
plt.hist(data, bins=30)
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('Histogram')
plt.show()
- Bar vs Histogram 그래프 비교
- 데이터를 시각화하는 목적이 다름
- 막대 그래프는 주로 범주형 데이터의 값을 비교하는데 사용
- 히스토그램은 연속적인 데이터의 분포를 시각화하는 데 사용
- 데이터를 시각화하는 목적이 다름
| 구분 | 막대 그래프 | 히스토그램 |
|---|---|---|
| 데이터 유형 | 범주형 데이터 비교 | 연속적 데이터 분포 |
| 막대 형태 | 수직 or 수평 막대 (크기) | 막대가 붙어있는 형태 (빈도) |
| 시각화 유형 | 해당 범주의 크기를 나타냄 | X축은 데이터 값의 범위를, |
| Y축은 해당 범위에서의 빈도를 나타냄 | ||
| 예시 | 팀별 판매량, 국가별 GDP 등을 비교 | 시험 점수 분포, 온도 변화 등 |
| 연속적인 데이터의 분포 |
3) Pie
- Pie Chart(원 그래프)
- 전체에서 각 부분의 비율을 보여줌
- 주로 카테고리별 비율을 비교할 때 사용
- 자료 유형
- 범주형 데이터의 상대적 비율을 시각화하는 데 사용
- 활용
- 전체에 대한 각 범주의 비율을 보여줄 때 유용
- 주로 비율을 비교하는 데 사용
import matplotlib.pyplot as plt
# 데이터 생성
sizes = [30, 20, 25, 15, 10]
labels = ['A', 'B', 'C', 'D', 'E']
# 원 그래프 그리기
plt.pie(sizes, labels=labels, autopct='%1.1f%%')
plt.title('Pie Chart')
plt.show()
4) Box plot
- Box Plot(박스 플롯)
- 데이터의 분포와 이상치를 시각적으로 보여줌
- 중앙값, 사분위수, 최솟값, 최댓값 등의 정보를 제공하여 데이터의 통계적 특성을 파악하는 데 사용
- 자료 유형
- 연속형 데이터의 분포와 이상치를 시각화하는 데 주로 사용
- 활용
- 데이터의 중앙값, 사분위수(25%, 50%, 75% 위치의 값), 최소값, 최대값, 이상치를 한눈에 파악할 수 있음
import matplotlib.pyplot as plt
import numpy as np
# 데이터 생성
np.random.seed(10)
data = [np.random.normal(0, std, 100) for std in range(1, 4)]
# 박스 플롯 그리기
plt.boxplot(data)
plt.xlabel('Data')
plt.ylabel('Value')
plt.title('Box Plot')
plt.show()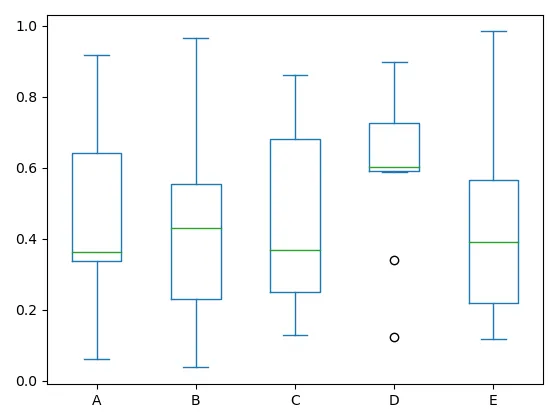
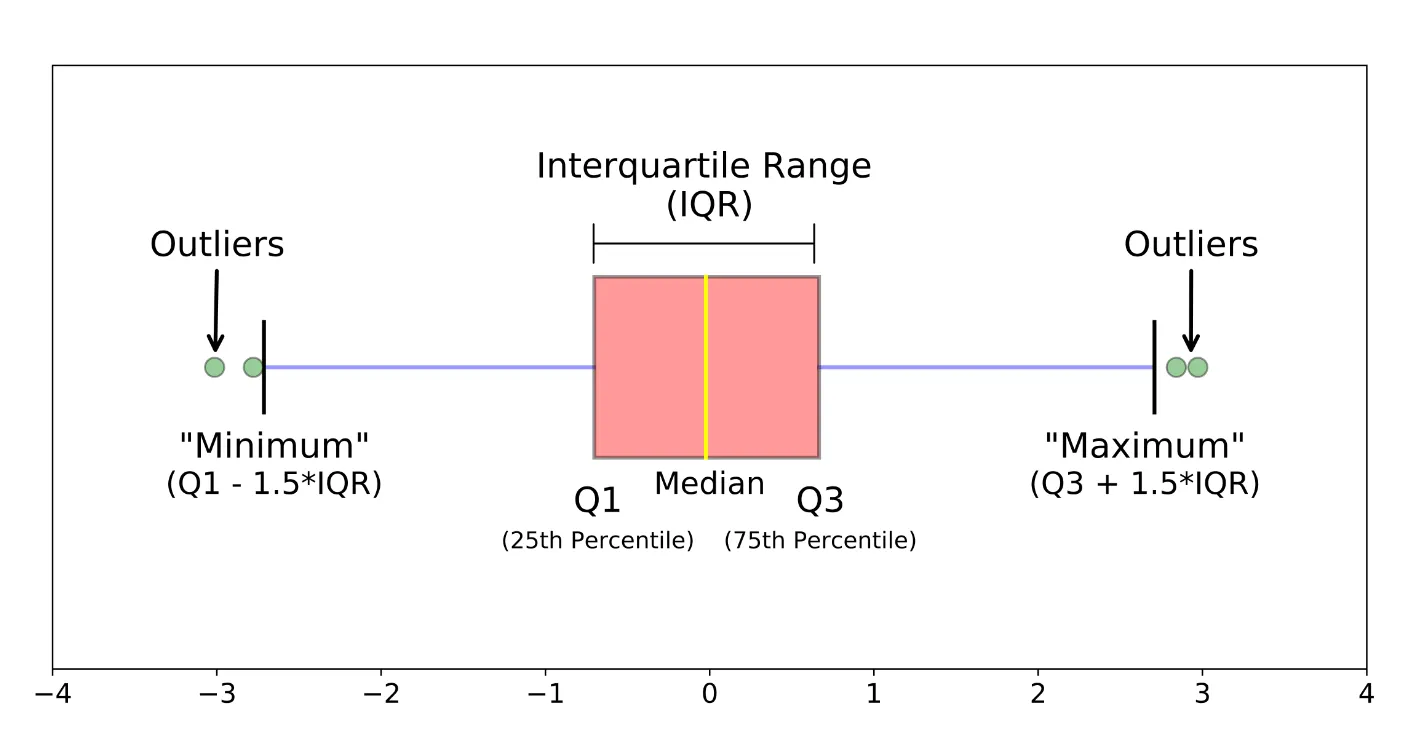
구성 요소
- 상자(Box)
- 데이터의 중앙값과 사분위수(25%와 75%)를 나타냄
- 상자의 아래쪽 끝은 25%의 값(1사분위수), 상자의 윗쪽 끝은 75%의 값(3사분위수)
- 상자의 중앙에 위치한 선은 중앙값
- 데이터의 중앙값과 사분위수(25%와 75%)를 나타냄
- 수염(Whisker)
- 상자의 위 아래로 연장되는 선
- 수염의 끝은 최솟값과 최댓값
- 일반적으로 1.5배의 사분위 범위로 계산
- 이 범위를 넘어가는 값은 이상치(outlier)로 간주
- 상자의 위 아래로 연장되는 선
- 이상치(Outliers)
- 수염 부분을 벗어나는 개별 데이터 포인트
- 일반적인 범위를 벗어나는 값들을 의미
- 박스 플롯에서 독립적으로 표시
용어 설명
- 중앙값
- 데이터를 크기 순서대로 나열했을 때, 정확히 중간에 위치한 값입니다. 중앙값은 데이터의 중심 경향을 나타내는 하나의 지표로서 사용됩니다.
- 만약 데이터가 홀수 개라면, 중앙값은 데이터를 작은 것부터 나열했을 때 정확히 가운데에 위치한 값입니다. 예를 들어, {3, 6, 7, 12, 14}에서 중앙값은 7입니다.
- 하지만 데이터가 짝수 개일 경우에는 중앙에 위치한 두 값의 평균이 중앙값이 됩니다. 예를 들어, {3, 6, 7, 12, 14, 16}에서 중앙값은 (7 + 12) / 2 = 9.5입니다.
- 중앙값은 데이터의 이상치에 대해 덜 민감하며, 데이터의 대표값을 파악하는 데에 사용됩니다.
- 사분위수
- 사분위수(quartiles)는 데이터를 4등분한 지점을 말합니다. 이것은 데이터를 크기 순서대로 정렬했을 때, 25%, 50%, 75%에 해당하는 위치의 값을 가리킵니다.
- 1사분위수(First Quartile, Q1): 데이터의 하위 25%에 해당하는 값을 말합니다. 즉, 데이터를 작은 값부터 정렬했을 때 약 25% 지점에 위치한 값입니다.
- 2사분위수(Second Quartile, Q2): 데이터의 중앙값(median)에 해당합니다. 데이터를 정렬했을 때 중간에 위치한 값으로, 50%의 위치에 해당합니다.
- 3사분위수(Third Quartile, Q3): 데이터의 상위 25%에 해당하는 값을 말합니다. 데이터를 큰 값부터 정렬했을 때 약 75% 지점에 위치한 값입니다.
- 사분위수는 데이터의 분포를 더 자세히 이해하고 데이터 집합의 특성을 파악하는 데에 유용합니다. 이를 통해 데이터의 하위 25%, 중간 50%, 상위 25%의 값들을 나누어 살펴볼 수 있습니다. 이상치를 감지하거나 데이터의 분포를 확인하는 데에 활용됩니다.
- 이상치
- 이상치(outlier)란 일반적인 데이터 집합의 패턴에서 크게 벗어나는 값을 가진 데이터 포인트를 말합니다. 이상치는 다른 데이터들과 비교했을 때 극단적으로 크거나 작은 값을 갖는 경우를 의미합니다.
- 주어진 데이터 집합에서 일반적인 범위를 벗어나는 이상치는 종종 실수, 실험 오류, 데이터 수집 과정에서 발생한 문제 등으로 인해 나타날 수 있습니다. 이상치는 통계 분석이나 데이터 시각화 과정에서 주의를 기울여야 하는 부분입니다. 데이터의 정확성을 해치거나 모델의 성능을 왜곡시킬 수 있기 때문에 이상치를 식별하고 처리하는 것이 중요합니다.
- 일반적으로 이상치는 상자 수염 그림(Box Plot)이나 히스토그램(Histogram) 등을 사용하여 시각적으로 확인될 수 있습니다. 또한, 통계적 방법이나 도메인 지식을 활용하여 이상치를 탐지하고 처리하는 방법도 있습니다.
- 상자의 아래쪽 끝은 25%의 값(1사분위수), 상자의 윗쪽 끝은 75%의 값(3사분위수)을 나타냅니다.
- 중앙에 위치한 선은 중앙값을, 수염의 끝은 최솟값과 최댓값을 나타냅니다.
- 박스 플롯에서 이상치(outlier)로 간주되는 값들이 점으로 표시되어 있습니다.
활용
- 데이터의 분포와 중앙값, 이상치를 한눈에 파악
- 다수의 그룹 또는 범주 간의 데이터 분포를 비교
- 통계적으로 중요한 데이터의 특성을 시각적으로 표현
예시
- A라는 회사가 제품을 배송하는 업체라고 가정
- 이때 배송데이터를 활용하여, 제품별 배송시간의 특이점을 파악하고자 할 때:
- 배송 데이터를 Box plot을 통해 시각화
- 제품 특성을 기준으로 각 제품의 배송시간을 Box plot으로 표현
- Box plot을 통해 제품과 배송시간의 분포와 중앙값, 이상치 등을 파악
- 어떤 제품이 평균배송시간에 벗어나는 이상치 및 변동성이 존재하는지 파악
- 배송 데이터를 Box plot을 통해 시각화
- box plot의 정보를 토대로 배송 프로세스를 개선하거나, 특정 제품의 배송 시간을 최적화하는 데에 활용할 수 있음
- 예를 들어, 배송 시간이 긴 제품의 이상치가 발견된다면 해당 제품의 배송 프로세스를 개선하여 고객 만족도를 높일 수 있음
→ Box plot을 통해 데이터의 분포와 특성을 시각적으로 파악함으로써, 비즈니스에서 품질 향상, 프로세스 개선, 결정 지원 등에 활용 가능
5) Scatter
- Scatter Plot(산점도)
- 두 변수 간의 관계를 점으로 표시하여 보여주는 그래프
- 두 변수 간의 상관 관계를 보여주고,
각 점이 데이터 포인트를 나타내며, 그 점들이 어떻게 분포되어 있는지 시각적으로 확인
- 자료 유형
- 두 변수 간의 관계 및 상관관계를 보여줄 때 사용
- 활용
- 변수 간의 관계, 군집, 이상치를 확인하고자 할 때 유용
import matplotlib.pyplot as plt
# 데이터 생성
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# 산점도 그리기
plt.scatter(x, y)
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Scatter Plot')
plt.show()
상관관계
-
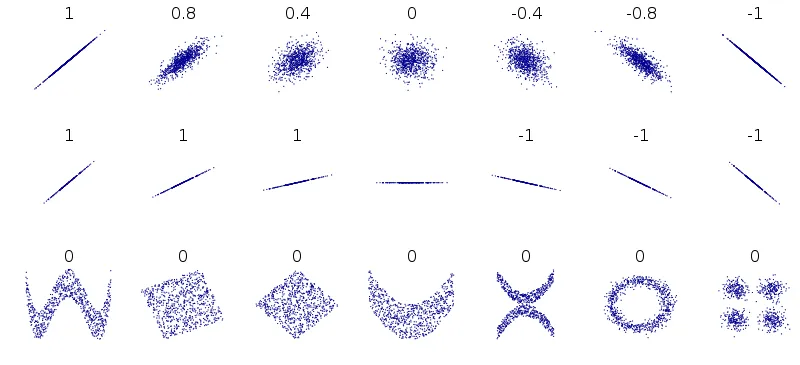
상관관계 확인하기
- 양의 상관관계
- 산점도에서 점들이 오른쪽 위 방향으로 일직선으로 분포되어 있을 때
- 즉, 하나의 변수가 증가할 때 다른 변수도 증가하는 경향
- 음의 상관관계
- 산점도에서 점들이 왼쪽 위 방향으로 일직선으로 분포되어 있을 때
- 하나의 변수가 증가할 때 다른 변수는 감소하는 경향
- 무상관 관계
- 산점도에서 점들이 어떤 방향으로도 일직선으로 분포하지 않고 무작위로 퍼져 있을 때
- 즉, 두 변수 간에는 상관관계가 거의 없는 것
- 양의 상관관계
-
상관관계의 강도 확인하기
- 점들의 모임
- 점들이 더 밀집된 곳은 상관관계가 높다는 것을 나타낼 수 있음
- 점들의 방향성
- 일직선에 가까운 분포일수록 상관관계가 강할 가능성이 높음
- 상관계수 계산
- 피어슨 상관계수와 같은 통계적 방법을 사용하여 상관관계의 정도를 수치적으로 계산할 수 있음
- 점들의 모임
피어슨 상관계수(Pearson correlation coefficient)
- 두 변수 간의 선형적인 관계를 측정하기 위한 통계적인 방법 중 하나
- 주로 연속형 변수들 간의 상관관계를 평가하는 데 사용
- 특징
- 범위
- -1에서 1 사이의 값
- 양의 상관관계
- 1에 가까울수록 강한 양의 선형관계
- 음의 상관관계
- -1에 가까울수록 강한 음의 선형관계
- 무상관 관계
- 0에 가까울수록 선형관계가 거의 없거나 약한 관계
- 범위
- 공분산을 각 변수의 표준편차로 나누어 정규화한 값으로, 두 변수 간의 선형적 관계 정도를 측정
- 값이 1에 가까울수록 두 변수 사이에 강한 선형적 관계가 있음을 의미하며, 값이 0에 가까울수록 두 변수 사이에 선형적인 관계가 거의 없거나 매우 약한 관계를 나타냄
- 주로 선형적인 관계를 가진 두 변수 간의 상관성을 평가하는 데 사용되며, 변수 간의 비선형적 관계는 잘 표현하지 못할 수 있음
- 이상치가 있는 경우에도 영향을 받을 수 있음
💡 피어슨 상관계수는,
r이 -1.0과 -0.7 사이이면, 강한 음적 선형관계,
r이 -0.7과 -0.3 사이이면, 뚜렷한 음적 선형관계,
r이 -0.3과 -0.1 사이이면, 약한 음적 선형관계,
r이 -0.1과 +0.1 사이이면, 거의 무시될 수 있는 선형관계,
r이 +0.1과 +0.3 사이이면, 약한 양적 선형관계,
r이 +0.3과 +0.7 사이이면, 뚜렷한 양적 선형관계,
r이 +0.7과 +1.0 사이이면, 강한 양적 선형관계
로 해석하곤 합니다.
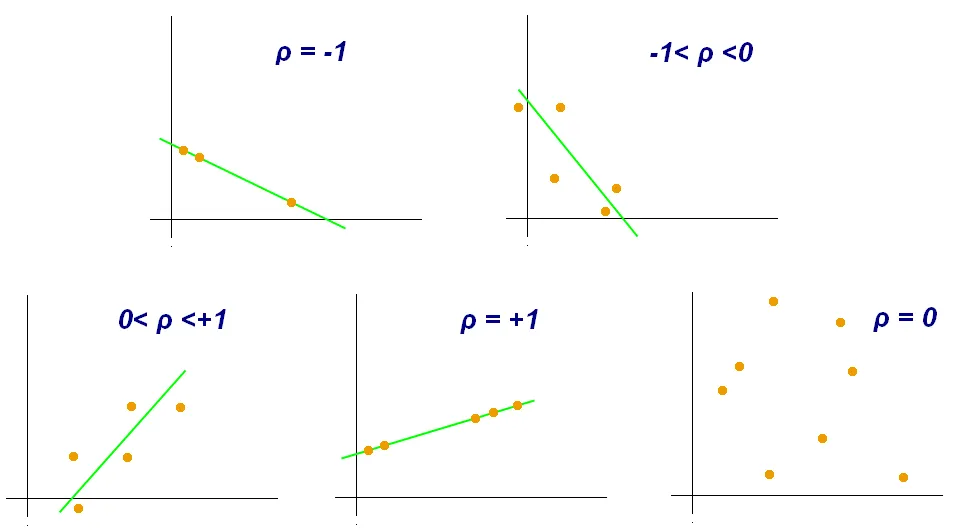
예시
-
매출과 광고 비용 간의 상관분석
- 최근 신제품 출시를 고려하고 있는 A회사가 있다고 가정 → 마케팅 예산을 산정하기 위해, 이전 판매 데이터와 마케팅 비용 간의 관계를 알고자 함
- A회사의 특정기간의 판매 데이터와 마케팅 비용 데이터를 활용하여 상관분석
- 상관관계수가 약 0.85로 매우 높은 양의 상관관계를 확인
→ 즉, 마케팅 비용이 증가할수록 매출도 상승하는 경향이 있음
- 상관관계수가 약 0.85로 매우 높은 양의 상관관계를 확인
- 위 분석내용을 기반으로 다음과 같은 판단 가능
- 새 제품 출시 시 마케팅 예산을 늘릴 경우, 매출 증가가 어느정도 상관성이 존재한다라고 판단하여 마케팅 예산을 투입해 매출 상승을 기대
(단, 상관관계가 인과관계를 의미하지는 않는다는 점 유의)
- 새 제품 출시 시 마케팅 예산을 늘릴 경우, 매출 증가가 어느정도 상관성이 존재한다라고 판단하여 마케팅 예산을 투입해 매출 상승을 기대
-
이처럼, 상관분석은 비즈니스에서 전략적인 의사 결정에 중요한 도움을 주는 도구로 활용될 수 있음
용어 설명
- 표준편차(standard deviation)
- 데이터의 분산 정도를 나타내는 측정 지표 중 하나
- 데이터가 평균으로부터 얼마나 퍼져 있는지를 보여줌
- 즉, 데이터 포인트가 평균에서 얼마나 멀리 떨어져 있는지를 평균적으로 측정하는 값
- 표준편차가 작을수록 데이터 포인트들이 평균 주변에 모여있는 것이고, 표준편차가 클수록 데이터 포인트들이 평균에서 멀리 퍼져있다고 해석할 수 있음
- 데이터의 흩어진 정도를 알려주는 지표로, 통계적 분석에서 널리 사용
- 공분산(covariance)
- 두 변수 간의 관계를 나타내는 통계적 측정 지표
- 두 변수의 변화 패턴이 함께 일어나는 정도를 측정하는데 사용
- 공분산이 양수인 경우, 변수X와Y는 함께 증가 또는 감소하는 경향
- 공분산이 음수인 경우에는 하나의 변수가 증가할 때 다른 변수는 감소하는 경향
- 하지만 공분산의 값 자체만으로는 두 변수 간의 관계의 강도나 방향을 명확하게 알려주지 않으므로 표준화된 지표인 상관계수(correlation coefficient)를 사용하여 두 변수 간의 관계를 더 명확하게 파악해야 함
- 정규화(normalization)
- 데이터의 스케일(scale)을 조정하여 특정 범위나 규격에 맞추는 과정
- 데이터 스케일 조정
- 데이터의 값이 서로 다른 범위에 있을 때, 일부 알고리즘에서는 이를 고려하여 데이터를 처리
- 정규화를 통해 데이터를 특정 범위로 조정함으로써, 알고리즘이 데이터를 더 잘 처리할 수 있도록 도움
- 이상치 영향 완화
- 이상치가 있는 데이터는 전체적인 분포를 왜곡시킬 수 있으므로 이를 완화하기 위해 데이터를 정규화하여 이상치의 영향을 줄임
- 알고리즘의 수렴성 향상
- 몇몇 머신 러닝 알고리즘은 데이터가 정규화되어 있을 때 수렴하는 속도가 빨라질 수 있음
- 특히 경사 하강법 등의 최적화 기법에서 이점

숙제
flights 데이터셋을 활용해 그래프 그리기
import seaborn as sns
import matplotlib.pyplot as plt
# Seaborn의 내장 데이터셋 'flights' 불러오기
flights_data = sns.load_dataset('flights')- 연도별 총 승객 수
- 연도별 평균 승객 수
- 승객 수 분포
- 연도별 승객 수와 월간 승객 수
- 월별 승객 수 분포
tips 데이터셋을 활용해 그래프 그리기
import seaborn as sns
import matplotlib.pyplot as plt
# Seaborn의 내장 데이터셋 'tips' 불러오기
tips_data = sns.load_dataset('tips')- 요일별 팁 금액의 평균
- 제목: Average Tips by Day
- X축: Day of the Week
- Y축: Average Tip Amount
- 요일별 총 팁 금액
- 제목: Total Tips by Day
- X축: Day of the Week
- Y축: Total Tip Amount
- 식사 금액 분포
- 제목: Distribution of Total Bill
- X축: Total Bill Amount
- Y축: Frequency
- 식사 금액과 팁 금액의 관계
- 제목: Tip Amount vs Total Bill
- X축: Total Bill Amount
- Y축: Tip Amount
- 요일별 식사 금액 분포
- 제목: Total Bill Distribution by Day
- X축: Day of the Week
- Y축: Total Bill Amount
데이터 홀로서기
- "데이터 분석가" 혼자서도 잘할 수 있어요!
데이터 분석가로 홀로서기
- 강의에는 없는 내용은 어떻게 학습할까?
1) 모르는 함수가 나온 경우
- 많은 연습과 구글링!
- 하루 10분 pandas 써 보기
- 10분 pandas는 pandas에서 주로 활용되는 함수 등을 쉽게 사용가능하도록 설명한 문서
- 10분 pandas에 소개됙 코드를 맹목적으로 받아쓰기 하듯 적어보기
- 코딩도 하나의 언어라서 단순히 암기하는 것이 아니라 자주 사용해야 함
- 구글링은 나의 멘토
- 구글 신은 모든 것을 알고 있다
- 모르는 함수나 함수가 기억나지 않는 상황에 처했을 때, 구글에 물어보는 것을 습관화하기 → 스스로 검색해보고 배워가는 습관
- 하루 10분 pandas 써 보기
2) 데이터 전처리/시각화 과정에서 가져야 할 방향성
전처리와 시각화하기 전에,
내가 무엇을 위해 데이터를 확인할 것인가 메모하는 습관!
- 몰입해서 python코드를 작성하다 보면, 코드 로직에만 몰두하게 되면서 정작 "무엇을 얻고자 했었지?"라는 의문이 생길 수 있음
- 더군다나 양이 많고 복잡한 데이터를 다루면 더욱 어려워짐
- 내가 무엇을 해결하기 위해 전처리를 하고, 어떤 인사이트를 얻기 위해 시각화를 할지 사전에 고민하고 메모해 두는 습관 들이기
3) 다양한 시각화 라이브러리 & Tools
- Pandas 라이브러리
| 라이브러리 | 설명 |
|---|---|
| Matplotlib | 파이썬의 기본 시각화 라이브러리로, 다양한 종류의 그래프를 생성할 수 있습니다. 막대 그래프, 선 그래프, 산점도, 히스토그램 등을 지원하며, 다양한 커스터마이징 기능을 제공합니다. |
또한, Pandas는 Matplotlib을 내장하고 있어 DataFrame에서 바로 시각화를 할 수 있는 기능을 제공합니다. DataFrame.plot()을 사용하여 간단한 선 그래프, 막대 그래프, 산점도 등을 생성할 수 있습니다. | |
| Seaborn | Matplotlib을 기반으로 만들어진 통계 데이터 시각화를 위한 라이브러리입니다. 히트맵, 카운트 플롯, 상자 그림, violin plot과 같은 통계적 그래프 생성에 특화되어 있으며, 사용하기 쉬운 API를 제공합니다. |
| Plotly | 인터랙티브한 그래프를 만들기 위한 라이브러리로, 웹 기반의 대화형 시각화를 제공합니다. 사용자의 상호작용에 따라 데이터를 동적으로 조정할 수 있는 장점을 가지고 있습니다. |
- 데이터 시각화 툴
| 특징/도구 | Tableau | Google Data Studio | Amazon QuickSight |
|---|---|---|---|
| 사용자 인터페이스 | 직관적이고 사용자 친화적 | 사용하기 쉽고 간단한 UI | 직관적이고 쉽게 사용 가능 |
| 연동 가능한 데이터 소스 | 다양한 데이터 소스와 연동 가능 | 다양한 데이터 소스와의 연동 가능 | AWS 데이터와의 연동 가능 |
| 시각화 기능 | 다양한 시각화 및 차트 옵션 제공 | 다양한 시각화 기능 제공 | 다양한 시각화 옵션 제공 |
| 대시보드 공유/협업 | 공유 및 협업 기능 지원 | 공유 및 협업 기능 제공 | 협업 및 공유 기능 지원 |
| 클라우드 기반 | 데스크톱 및 클라우드 기능 제공 | 구글 클라우드 기반 | AWS 클라우드 기반 |
| 확장성 | 확장성이 좋음 | 구글 서비스와 연동하여 확장 가능 | AWS 생태계 내에서 확장 가능 |
-
- 사용자가 데이터를 시각적으로 탐색하고 이해하기 쉽도록 도와주는 시각화 도구
- 대화형 대시보드 및 시각화를 생성하고, 다양한 데이터 소스와 연결하여 분석 및 시각화를 제공
- 특징
- 직관적인 UI, 다양한 시각화 옵션, 대규모 데이터 처리, 대시보드 공유 및 협업 기능, 실시간 분석 등
-
- 구글의 무료 데이터 시각화 도구
- 다양한 데이터 원본을 연결하고 시각화하여 사용자 정의 대시보드를 생성할 수 있음
- 특징
- 간단한 사용법, 다양한 데이터 소스와의 연동, 실시간 데이터 업데이트, 사용자 지정 가능한 대시보드 및 보고서 생성 등
-
- AWS에서 제공하는 비즈니스 인텔리전스 및 시각화 도구
- 빠른 시간 내에 대화형 시각화를 생성하고 AWS 데이터와 연결하여 분석을 수행
- 특징
- 빠른 대시보드 구축, 스마트 기능을 활용한 데이터 분석, 클라우드 기반의 시스템으로 확장 가능한 기능 등
내가 생각하는 데이터 분석가 정의하기
- 내가 되고 싶은 데이터 분석가는?
1) 데이터 분석가란?
- Python , SQL 스킬은 매우 쉽고, 반복하다보면 어느새 잘해진 내 모습을 발견하게 됩니다. 즉, 스킬은 배우면 되고 반복학습하면 늘기 마련입니다.
- 그러나 여러분이 정말 하고 싶은 데이터 분석은 방향성에 따라 매우 다르고 그것을 위한 스킬 또한 다르다 라는 것을 말씀드리고 싶습니다.
- e.g. 비즈니스 분석가: 현업에서는 python을 다루지 않는 경우가 대부분. 스킬보다 비즈니스 현상에 대한 이해와 인사이트가 더욱 중요함.
데이터 사이언티스트: python 스킬은 필수. AI에 대한 기본 지식이 필요함(논문을 읽고 해석하며 실제업무에 반영할 수 있는 능력 필요)
- e.g. 비즈니스 분석가: 현업에서는 python을 다루지 않는 경우가 대부분. 스킬보다 비즈니스 현상에 대한 이해와 인사이트가 더욱 중요함.
2) 내가 되고 싶은 데이터 분석가
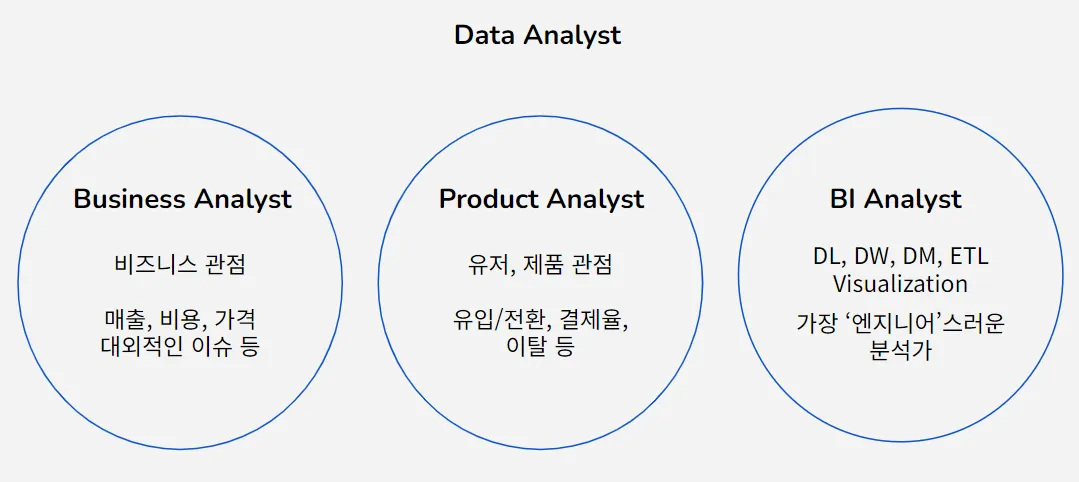
- BA, PA, BI, DS, DA, …
- 비즈니스 분석가(BA)
- 주로 비즈니스 문제를 이해하고 해결하기 위해 데이터를 분석
- 비즈니스 프로세스 및 요구 사항을 파악하고, 데이터 기반으로 의사 결정을 지원
- 주로 업무 프로세스 개선, 비즈니스 모델 분석, 요구 사항 관리 등을 수행
- 프로덕트 분석가(PA)
- 제품이나 서비스의 성과를 평가하고 개선하기 위해 데이터를 분석
- 사용자 행동 및 제품 성능과 관련된 데이터를 분석하여 제품 개선에 기여
- 주로 제품 경험과 사용자 행동에 대한 분석을 수행하며, A/B 테스트, 사용자 경로 분석 등을 담당
e.g. 커널 분석
- 데이터 분석가(DA)
- 주로 정형 데이터(표 형태로 정제되어 있는 데이터)를 분석하여 기업의 의사 결정을 지원
- 데이터베이스, 스프레드시트 등에서 데이터를 추출하고, 데이터를 정제하여 보고서 및 시각화를 생성
- 주로 기술적인 기술이 필요하며, SQL, Excel, 데이터 시각화 등을 활용하여 업무를 수행
- BI 분석가(BI)
- 기업의 비즈니스 인텔리전스 플랫폼과 도구를 사용하여 데이터를 시각화하고 보고서를 작성
- 주로 기업 내부 데이터를 시각화하고, 이를 통해 의사 결정에 필요한 정보를 제공
- BI 도구 (Tableau, Power BI 등)를 사용하여 대시보드를 구축하고, 데이터 시각화 및 보고서 작성을 담당
- 데이터 사이언티스트(DS)
- 주로 데이터를 활용하여 예측, 패턴 발견, 복잡한 분석을 수행하여 비즈니스 문제를 해결
- 통계, 머신러닝, 딥러닝 등의 기술과 알고리즘을 사용하여 데이터를 분석하고 모델을 구축
- 데이터 수집, 전처리, 모델링, 평가 및 해석을 포함한 end-to-end 데이터 분석 작업을 수행
- 비즈니스 분석가(BA)
숙제
- 실제 공공데이터를 활용해서 데이터를 전처리하고 시각화하여, 인사이트를 발굴해보기
공공데이터: 서울시 코로나 일일 확진 현황
- 서울시 코로나 일일 확진 현황 데이터를 활용해서 데이터를 시각화하고 시각화한 자료를 해석하여 인사이트를 도출해보기
공공데이터: 전국 아파트 부동산 분양가
- 전국 아파트 부동산 분양가 데이터를 활용해서 데이터를 시각화하고 시각화한 자료를 해석하여 인사이트를 도출해보기
참고: pandas , matplotlib 공식문서

2 B R 0 2 B