TL;DR
이커머스 시스템에서 주문이 발생하면 재고 차감과 포인트 차감이 동시에 일어납니다. 여러 사용자가 동시에 주문을 요청할 때 데이터 정합성을 보장하기 위해 비관적 락을 적용했지만, 예상치 못한 문제가 발생했습니다.
이 문제를 분석하고 해결한 과정을 정리했습니다.
1. 배경: 동시성 제어가 필요한 이유
동시성 문제의 예시
- 재고가 1개 남았는데 10명이 동시에 주문한다면?
- 포인트가 100원 남았는데 여러 주문에서 동시에 차감한다면?
동시성 제어 없이는 재고를 초과한 주문이나 마이너스 포인트가 발생할 수 있습니다.
비관적 락을 선택한 이유
주문 시스템에서 사용할 수 있는 동시성 제어 방식은 크게 두 가지입니다.
낙관적 락(Optimistic Lock)
- 충돌이 드물 것이라 가정하고 자유롭게 작업
- 커밋 시점에 충돌 검사 후 문제가 있으면 롤백
- 충돌 시 재시도 비용 발생
비관적 락(Pessimistic Lock)
- 충돌이 발생할 것이라 가정하고 미리 락을 획득
- 다른 트랜잭션의 접근을 원천 차단
- 성능은 낮지만 데이터 정합성 보장
주문 시스템에서는 비관적 락을 선택했습니다.
선택 이유:
1. 재고와 포인트는 데이터 정합성이 매우 중요한 데이터
2. 잘못된 데이터로 인한 비즈니스 손해가 심각할 수 있음
3. 성능 문제는 재고와 포인트를 상품/유저와 분리하여 완화
2. 문제 발견: 동시성 테스트 실패
테스트 시나리오
10포인트를 가진 사용자가 4원짜리 상품(재고 10개)을 10번 동시에 주문합니다.
예상 결과
- 2건 성공 / 8건 실패 (포인트 부족)
- 총 8원 차감
- 최종 상태: 재고 8개, 남은 포인트 2원
실제 결과
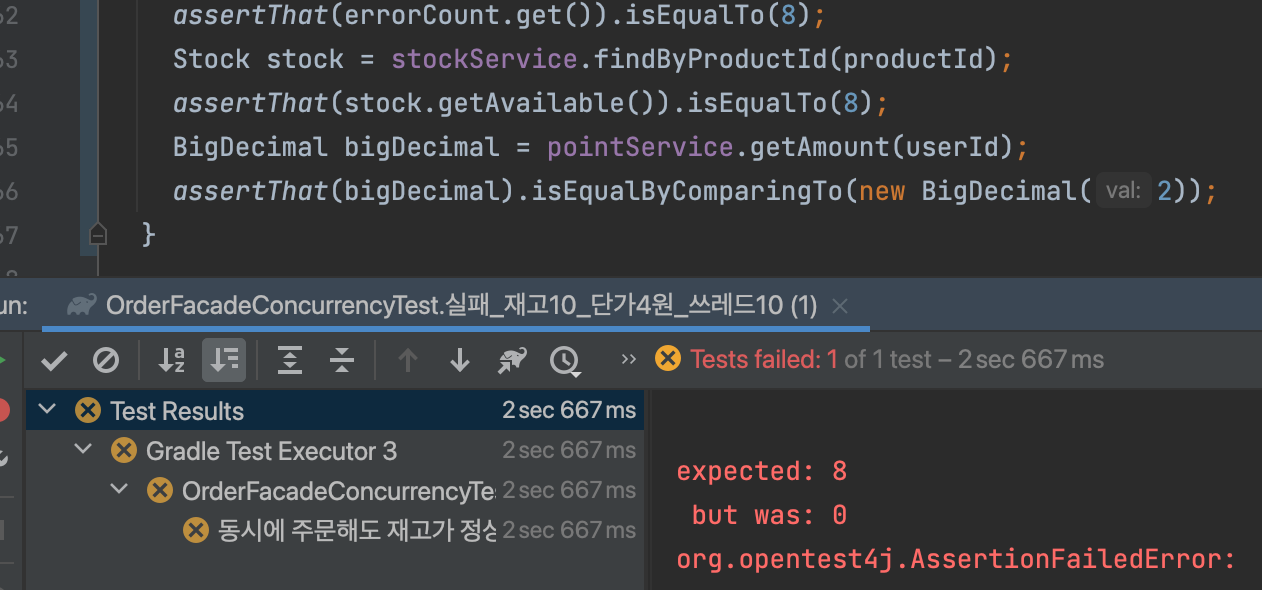
실패 건수: 0
남은 재고: 0개
남은 포인트: 2원모든 주문이 성공했습니다. 재고는 정상적으로 차감되었지만, 포인트는 10건 모두 정상 실행되었는데도 오류가 발생하지 않았습니다.
로그를 확인한 결과:
- 포인트 조회 시
10 → 6업데이트 후에도 계속 10포인트로 조회됨 - 이후 어느 순간부터
6 → 2로만 조회되어 오류 없이 완료
쿼리문에 비관적 락은 제대로 동작하고 있지만 조회 포인트가 업데이트 되지 않고 있었습니다.
원인 분석 1: MySQL의 동시성 제어
문제를 이해하기 위해 먼저 사용하고 있는 MySQL의 동작 방식을 알아봤습니다.
Repeatable Read와 MVCC
MySQL InnoDB의 기본 격리 수준은 Repeatable Read이며, MVCC(Multi-Version Concurrency Control)로 동시성을 제어합니다.
MVCC의 핵심 개념:
- 각 레코드를 여러 버전으로 관리 (undo log 활용)
- 트랜잭션마다 읽는 데이터의 "스냅샷 버전"이 다를 수 있음
- 동시 접근 시에도 블로킹 없이 각자의 버전을 읽음
SELECT FOR UPDATE의 특별한 동작
여기서 중요한 포인트가 있습니다.
SELECT FOR UPDATE는 MVCC 스냅샷을 무시하고 항상 최신 커밋된 데이터에 락을 겁니다.
즉, Repeatable Read 격리 수준이더라도 SELECT FOR UPDATE, UPDATE, DELETE 같은 쓰기 락 작업은 마치 Read Committed처럼 동작합니다.
그렇다면 SELECT FOR UPDATE도 최신 데이터를 조회해야 정상인데, 왜 오래된 데이터가 조회되었을까요?
원인 분석 2: User findById가 문제였다
의심스러운 코드 발견
Optional<User> user = userRepository.findById(command.userId());포인트를 조회하는 곳에서 User.getPoint()를 직접 호출하는 곳은 없었습니다. 유일하게 Point와 연관되는 곳은 주문 생성 전 해당 객체들의 존재 여부를 확인하기 위해 조회되던 userRepository.findById 밖에 없었습니다.
User 객체가 실제로 필요한 곳이 없어, 해당 구문을 주석 처리하고 테스트를 실행했습니다.
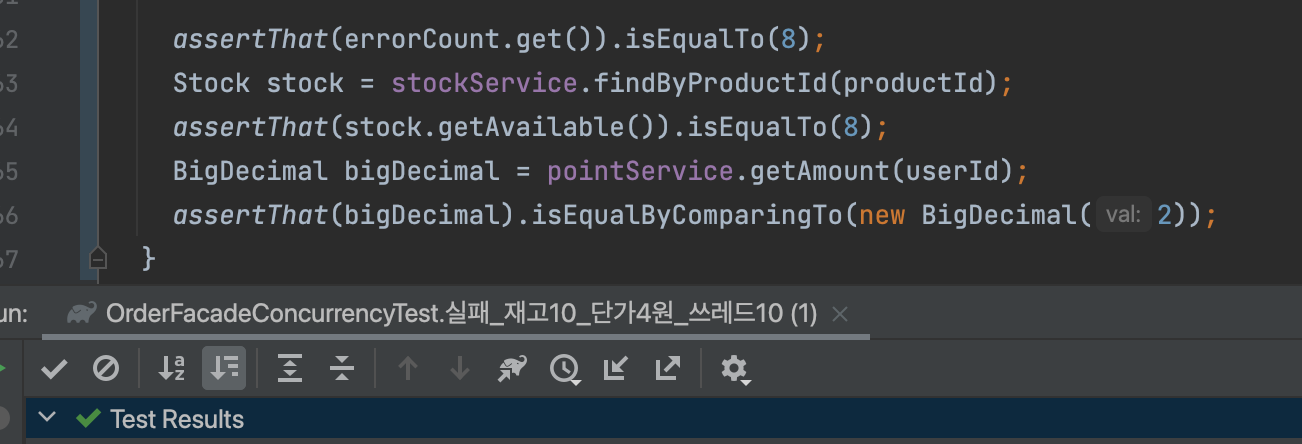
테스트가 성공했습니다!
userRepository.findById로 조회된 user를 사용하지 않고 조회 여부만으로 테스트의 결과가 달라지고 있었습니다. 조회만으로 1차 캐시가 생성되고, 이후 Point 조회 시 SELECT FOR UPDATE 값보다 1차 캐시의 값이 우선적으로 리턴되고 있는 상황이었습니다.
원인 분석 3: JPA 1차 캐시의 함정
JPA 1차 캐시와 SELECT FOR UPDATE의 충돌
JPA의 영속성 컨텍스트는 엔티티를 조회하면 1차 캐시에 저장합니다. 그리고 동일 트랜잭션 내에서 같은 엔티티를 다시 조회하면 DB를 거치지 않고 1차 캐시의 값을 반환합니다.
여기서 핵심은 "DB를 거치지 않는다"는 점입니다.
MySQL과 JPA는 서로 다른 레벨에서 동작한다
앞서 설명한 MySQL의 MVCC와 SELECT FOR UPDATE는 데이터베이스 레벨의 이야기입니다. 반면 JPA 1차 캐시는 애플리케이션 레벨의 이야기입니다.
문제의 핵심:
1. 🔄 userRepository.findById() 호출 → User 엔티티가 1차 캐시에 저장됨
2. 🚫 이후 SELECT FOR UPDATE로 Point를 조회하려 해도 → DB 쿼리가 아예 실행되지 않음
3. ⚠️ DB에서 최신 버전을 읽을 기회 자체가 없어짐
4. ❌ 결과: 1차 캐시에 있는 "오래된 값"이 그대로 반환됨
즉, MySQL의 SELECT FOR UPDATE가 아무리 최신 데이터를 가져오려 해도, JPA가 DB 조회 자체를 차단하기 때문에 무용지물이 되는 상황입니다.
주석 처리한 코드가 왜 문제를 해결했을까?
// Optional<User> user = userRepository.findById(command.userId()); // 주석 처리이 한 줄을 주석 처리했더니 테스트가 통과했습니다. 그 이유는:
- 주석 처리 전:
findById()로 User를 조회 → Point도 함께 1차 캐시에 저장 → 이후SELECT FOR UPDATE가 DB에 가지 않음 - 주석 처리 후: User 조회를 하지 않음 → Point가 1차 캐시에 없음 →
SELECT FOR UPDATE가 실제로 DB에서 최신 데이터를 가져옴
결국 불필요한 User 조회가 1차 캐시를 오염시켜, 비관적 락의 동작을 무력화시킨 것입니다.
원인 분석 4: 왜 Point까지 1차 캐시에 들어갔을까?
새로운 의문점
여기서 의문이 생깁니다. userRepository.findById()로 User만 조회했는데, 왜 Point까지 1차 캐시에 저장되었을까요?
User와 Point는 @OneToOne 관계로 연결되어 있고, fetch=LAZY로 설정되어 있습니다. LAZY 로딩이라면 Point는 실제로 사용되는 시점에만 조회되어야 합니다. 즉, user.getPoint()를 명시적으로 호출하지 않는 한 Point는 1차 캐시에 들어가지 않아야 정상입니다.
그런데 실제로는 Point도 함께 조회되어 1차 캐시에 저장되고 있었습니다. 왜 그럴까요?
LAZY로 설정했는데 EAGER로 동작하는 이유 확인
의심이 든 부분을 검증하기 위해 테스트 코드를 작성했습니다. findById(User) 시, Point 객체가 LAZY/EAGER 중 어떤 방식으로 조회되었는지 확인하는 테스트입니다.
테스트 결과: LAZY 설정이 무시되고 있었다
- SQL 로그를 확인하니 User 조회 시 Point조회도 함께 실행됨
- assert 검증으로 EAGER 조회가 일어남을 확인
- 디버그로 실행 시, User 객체 안의 Point가 Proxy가 아닌 실제 데이터를 가진 객체로 조회
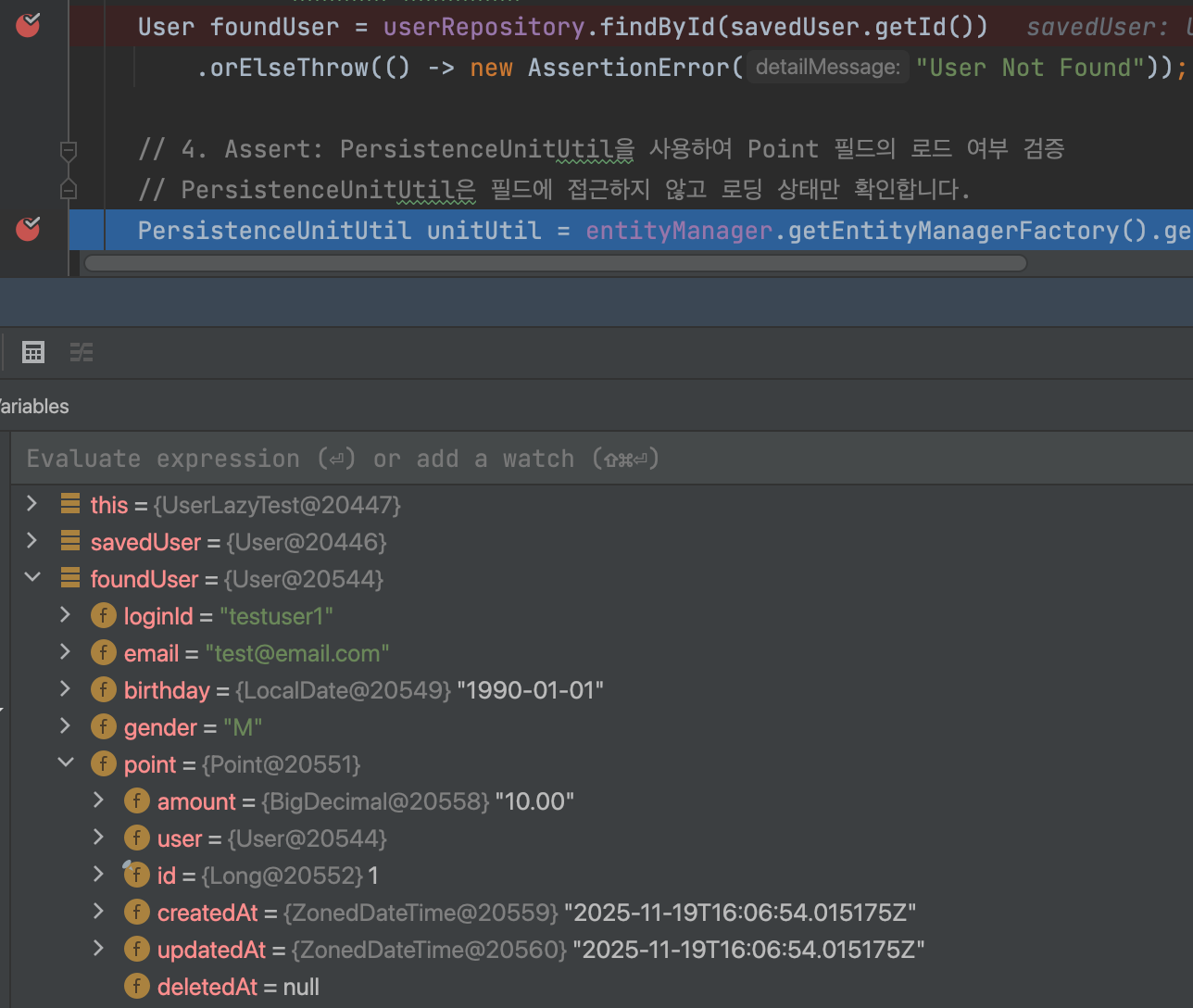
분명 fetch=LAZY로 설정했는데, Hibernate가 이를 무시하고 EAGER로 동작하고 있었습니다.
@OneToOne 양방향 관계의 숨겨진 동작
@OneToOne 관계에서 LAZY 로딩을 명시하더라도, Hibernate는 EAGER 로딩을 강제하는 경우가 많습니다.
왜 이런 일이 발생할까?
프록시 생성의 난제: @OneToOne 관계에서 LAZY 로딩을 구현하려면 프록시(Proxy) 객체를 사용해야 합니다. 하지만 @OneToOne은 특별한 문제가 있습니다.
예를 들어, User를 조회할 때 Hibernate는 "이 User에게 연관된 Point가 있는가?"를 알아야 프록시를 만들지 null을 반환할지 결정할 수 있습니다. 하지만 이를 알려면 어차피 Point 테이블을 조회해야 합니다.
결과적으로:
- Point가 있는지 확인하려면 → Point 테이블을 조회해야 함
- 어차피 조회할 거면 → 그냥 데이터까지 가져오자
- Hibernate의 선택 → LAZY를 무시하고 EAGER로 동작
특히 양방향 관계에서, 그리고 연관 필드가 Not-Null인 경우 이런 현상이 자주 발생합니다.
문제의 연쇄 작용 전체 그림
이제 모든 퍼즐이 맞춰졌습니다:
- 📝
userRepository.findById()호출 - 🔄
@OneToOne양방향 관계 + Hibernate의 내부 최적화 → Point도 함께 EAGER 로딩 - 💾 User와 Point 모두 1차 캐시에 저장됨
- 🔒 이후
SELECT FOR UPDATE로 Point를 조회하려 시도 - 🚫 JPA가 1차 캐시를 먼저 확인 → DB 쿼리가 실행되지 않음
- ⏰ 1차 캐시의 "오래된 Point 값"이 반환됨
- ❌ 비관적 락이 무력화되어 동시성 제어 실패
해결 방법 시도와 최종 결정
시도한 해결 방안들
@OneToOne(mappedBy = "user", cascade = CascadeType.ALL, fetch = FetchType.LAZY, optional = true)에서optional제거- Point에서 User를 참조하는 쪽도
FetchType.LAZY를 명시적으로 지정 (방어적 코딩)
결과: 두 방법 모두 실패 ❌
최종 해결: 양방향 관계 제거
현재 상태에서 가장 수정이 적은 방법들로도 해결되지 않아, 양방향 관계를 단방향으로 변경하기로 결정했습니다.
포인트를 유저 안에 넣을지, 유저와 포인트를 분리할지 설계 시점에서 정확하게 결정하지 못한 것이 근본 원인이었습니다. 중간에 방향을 바꾸려다 보니 불완전한 구조가 되었고, 이것이 예상치 못한 버그로 이어졌습니다.
최종 결정: User와 Point를 명확하게 분리하는 단방향 관계로 재설계
회고와 배운 점
- JPA 1차 캐시의 우선순위:
SELECT FOR UPDATE보다 1차 캐시가 먼저 동작한다는 것을 경험으로 배웠습니다 - @OneToOne 양방향 관계의 함정: LAZY로 설정해도 Hibernate가 EAGER로 동작할 수 있다는 것을 알게 되었습니다
- 트랜잭션 격리 수준: MySQL의 Repeatable Read와 MVCC에 대한 이해도가 높아졌습니다
- 관계 설정의 중요성: 양방향 관계가 정말 필요한지, 단방향으로도 충분하지 않은지 신중하게 고려해야 합니다
발생한 문제를 해결하면서, Repeatable Read에 대해 알아보고, 각 DB별 기본 트랜잭션 격리에 대해서 학습하니 각 특성에 대해 더 잘 이해할 수 있었습니다.
