Python이란
Python은 인터프리터 프로그래밍 언어로, 직관적이고 쉬운 문법과 다양하고 풍부한 라이브러리들을 바탕으로 한 강력한 생태계를 가지고 있어 프로그래밍 교육, 데이터 분석 및 빅데이터, 백엔드, 프론트엔드, 웹 스크래핑 등 다양한 분야에서 사용된다. 2020년대 이후로는 인공지능 분야에서도 사용되고 있다.
설치 방법
컴퓨터에 직접 설치할 수 있고, Conda를 통해 설치하는 방법이 있고, Google Colab에서 바로 사용할 수 있다.
직접 설치
Windows에서 설치
https://www.python.org/downloads/windows/ 에 접속해서 Python 3.12.7 버전을 설치한다. Python 3.13 에서는 아직 Pytorch혹은 Tensorflow를 설치할 수 없기에 가급적이면 3.12.7 버전을 이용하자. Windows installer (64-bit) 버전을 다운로드 받자.
macOS에서 설치
기본적으로 Python 3.9 이하 버전이 설치되어있다. 최신버전은
https://www.python.org/downloads/macos/ 에 접속해서 Python 3.11.9 혹은 3.12.7 버전을 설치한다. 여기서 3.12 버전은 인텔맥에서는 Pytorch 2.2.2까지 설치할 수 있는데, Pytorch 2.4.0버전부터 Python 3.12를 지원한다. 따라서 인텔맥에서 Pytorch를 사용하고 싶다면 Python 3.11.9 버전을 설치하는게 좋다. 또한 Python 3.12 버전에서는 Tensorflow의 Metal 플러그인을 설치할수 없다.
또한 macOS에서는 Homebrew를 통해서도 Python을 설치할 수 있다. Homebrew의 설치에 대해서는 https://brew.sh 를 참조하자.
- Intel CPU 기반의 Mac - Python 3.11.9 버전 설치
- Apple Silicon 기반의 Mac - Python 3.12.7 버전 설치
Homebrew를 이용한 설치방법
$ brew update
# Apple Silicon 기반의 Mac
$ brew install python@3.12
# Intel CPU 기반의 Mac
$ brew install python@3.11Linux에서 설치
macOS와 마찬가지로 기본적으로 Python이 설치되어있다. 다만 리눅스 배포판에 따라 기본적으로 설치된 Python 버전이 다르다. Linux에서 설치하는 방법은 https://wiki.python.org/moin/BeginnersGuide/Download 를 참조하자.
Conda를 이용한 설치
Anaconda와 Miniconda가 있다.
Anaconda 는 과학 연구 및 머신러닝 분야에 적합한 Python 및 R 언어의 패키지 의존성 관리 및 배포를 편리하게 해주는 패키지 관리자다.
파이썬 버전 관리가 용이하기 때문에 Conda를 설치하는것을 권장한다.
Anaconda의 경량화 버전인 Miniconda도 존재하며 Anaconda와는 달리 구동에 필요한 최소한의 것만 제공되기 때문에 Anaconda보다 훨씬 가볍지만 필요한 패키지는 사용자 스스로 찾아서 설치해야한다.
https://www.anaconda.com/download 에 접속해서 Skip Registration을 누르고 Anaconda 혹은 Miniconda를 다운로드 받고 설치하자.
Google Colab에서 바로 사용
Google Colaboratory는 설치가 필요없고 완전히 클라우드에서 실행되는 무료 Jupyter 노트북 환경이다. Colab을 사용하면 브라우저를 통해 무료로 코드를 작성 및 실행하고, 분석을 저장 및 공유하며 강력한 컴퓨팅 리소스를 이용할 수 있다.
Colab은 구글 계정이 필요하므로 만약 구글 계정이 없다면 미리 만들어놓자.
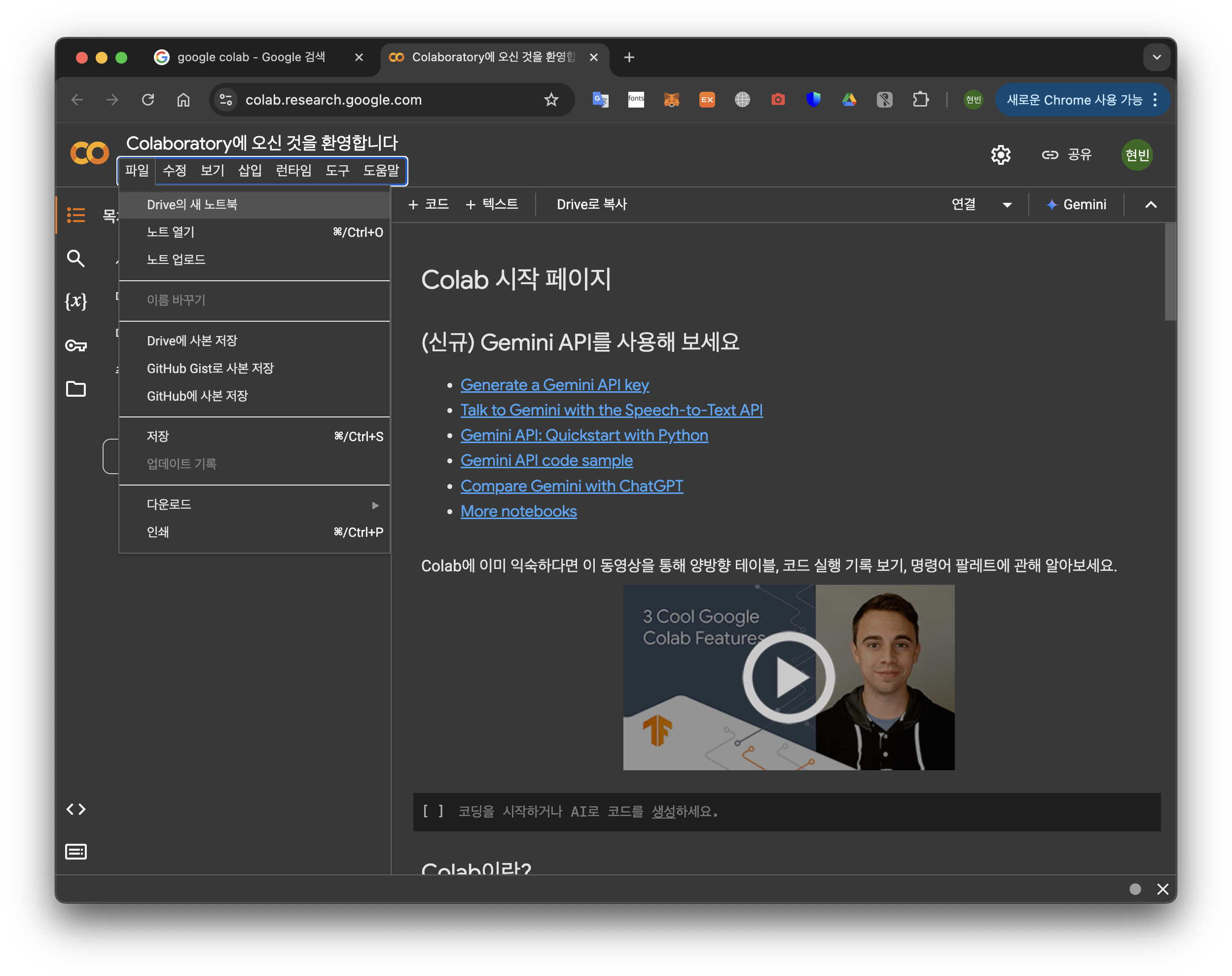
- 파일->Drive의 새 노트북 순서대로 누른다.
-
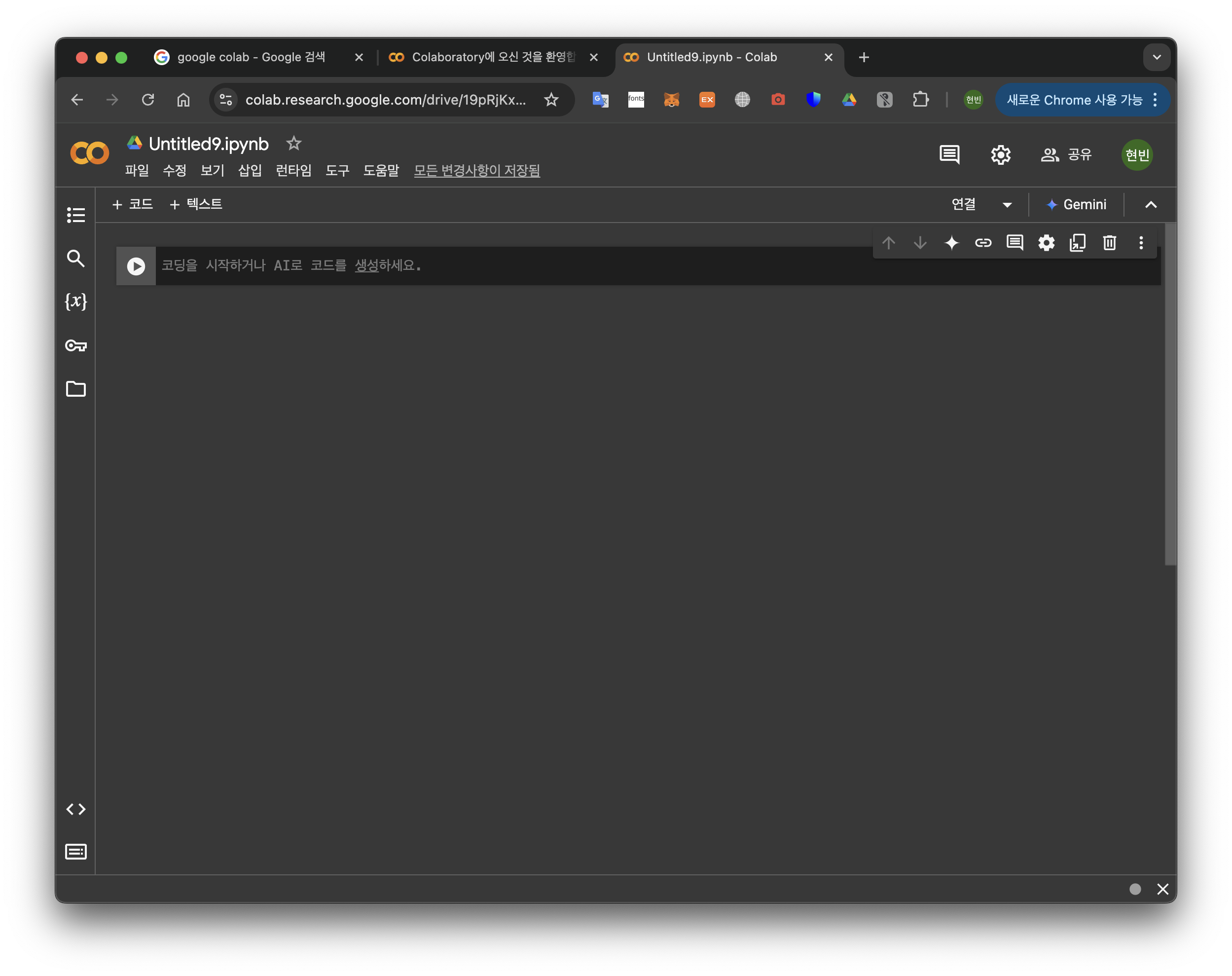
아래의 그림과 같이 나오는 코드 작성 공간을 Shell이라고 한다.

-
여기서 +코드를 누르면 Shell이 추가된다. 이때 Shell에 코드를 작성하고 Shift+Enter(macOS에서는 command/control+Enter)키를 눌러서 실행한다.
-
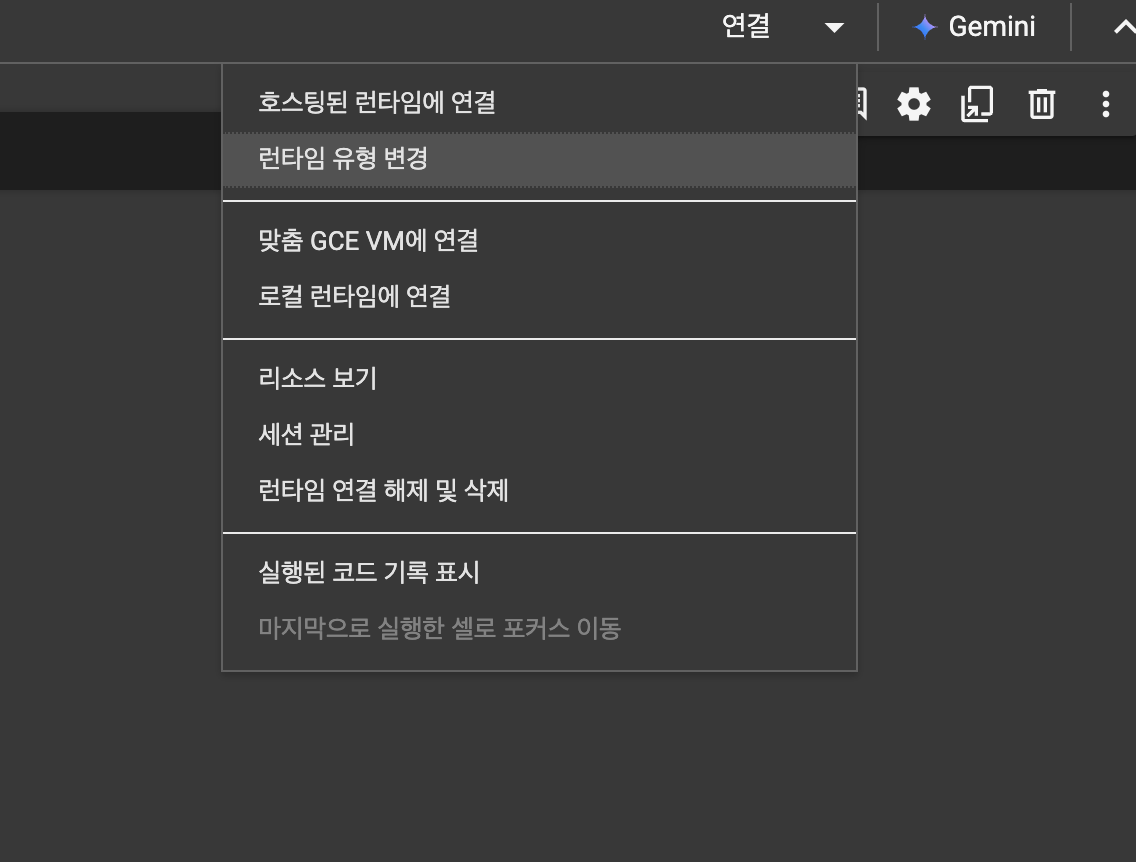
딥러닝에서는 GPU를 사용한다. CPU를 통해서도 실습할수 있지만 엄청나게 느리므로 GPU를 사용해서 실습하자.
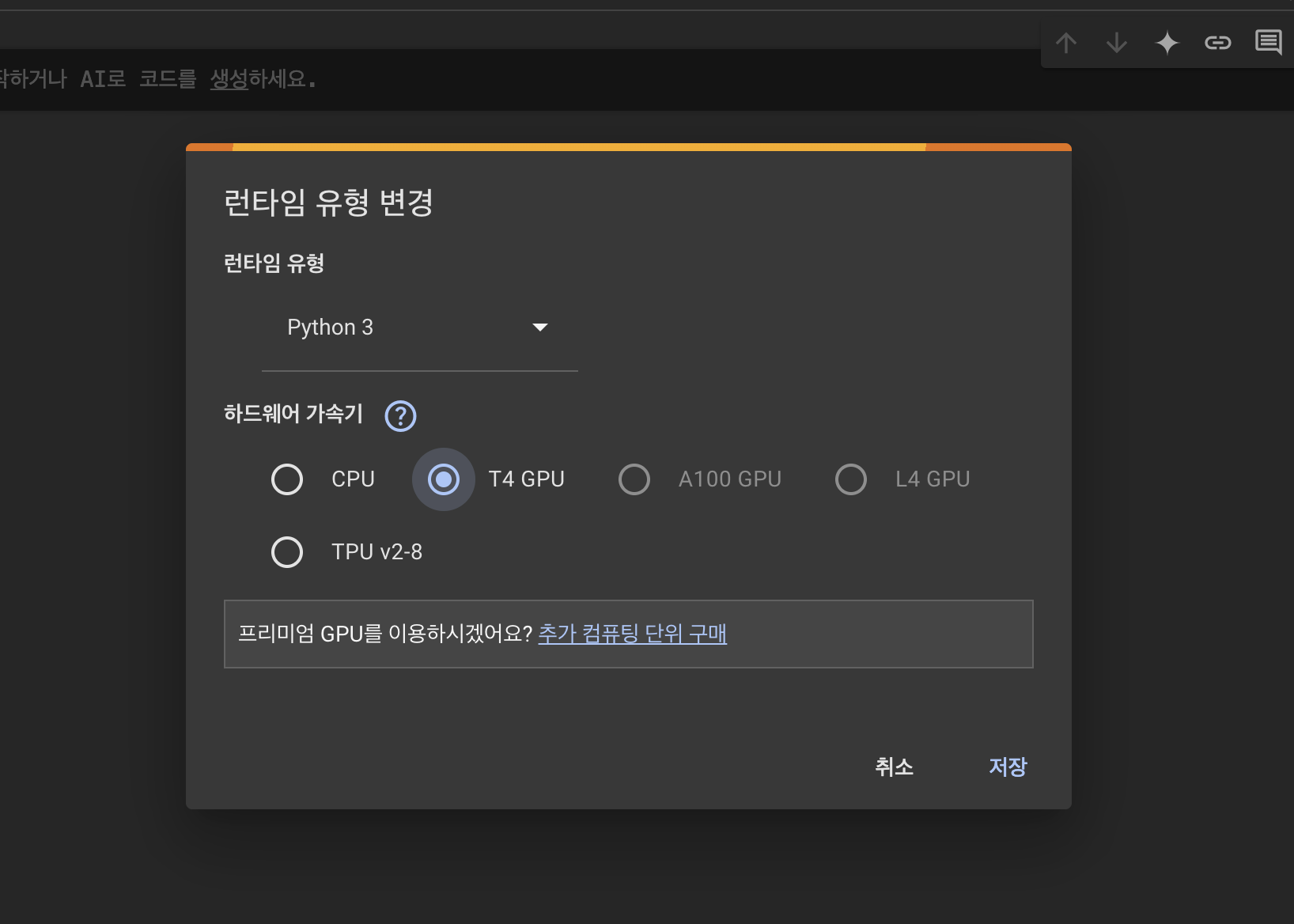
필수 라이브러리 설치
Tensorflow
Tensorflow는 구글이 2015년에 공개한 Machine Learning 오픈소스 라이브러리이다. Machine Learning과 Deep Learning을 직관적이고 손쉽게 할수 있도록 설계되었다.
$ pip install tensorflowimport tensorflow as tf
tf.__version__'2.18.0'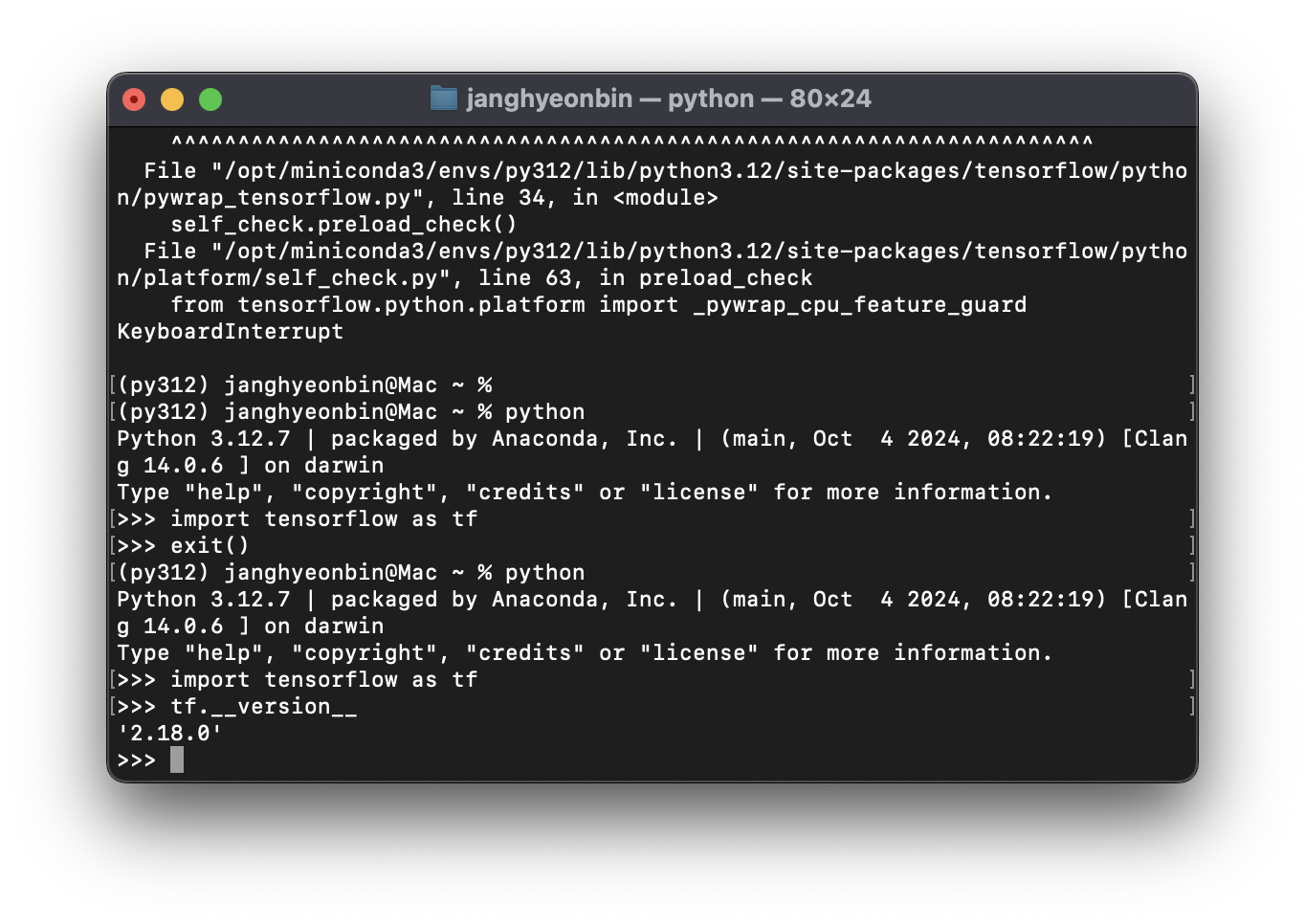
Keras
Keras는 Deep Learning Framework인 Tensorflow에 대한 추상화된 API를 제공한다. 백엔드로 Tensorflow를 사용하며, 좀더 쉽게 Deep Learning을 사용할 수 있게 해준다.
# keras 3.x
$ pip install keras
# keras 2.x
$ pip install tf-keras# keras 3.x
import keras
keras.__version__'3.6.0'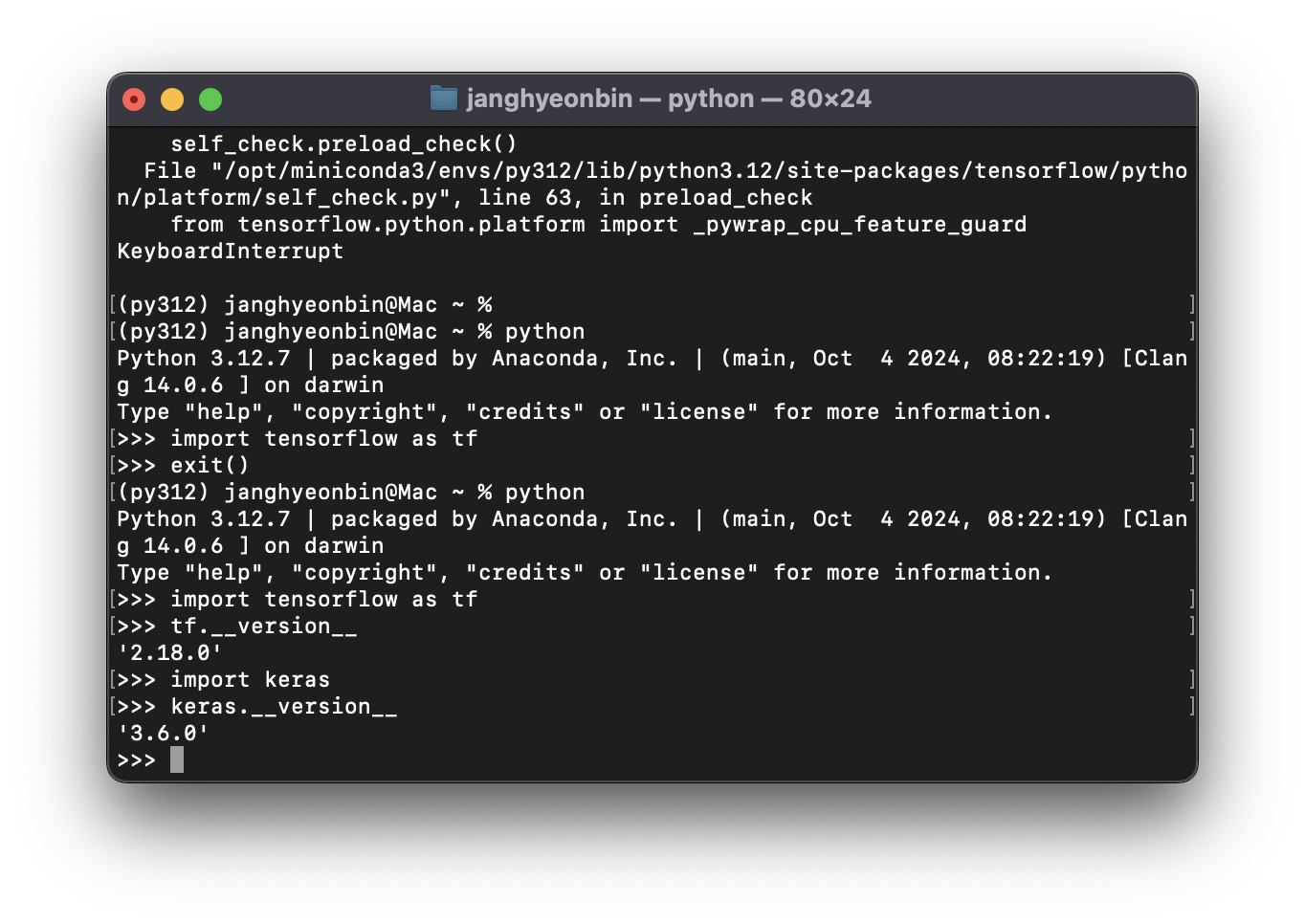
# keras 2.x (legacy)
import tf_keras
tf_keras.__version__'2.18.0'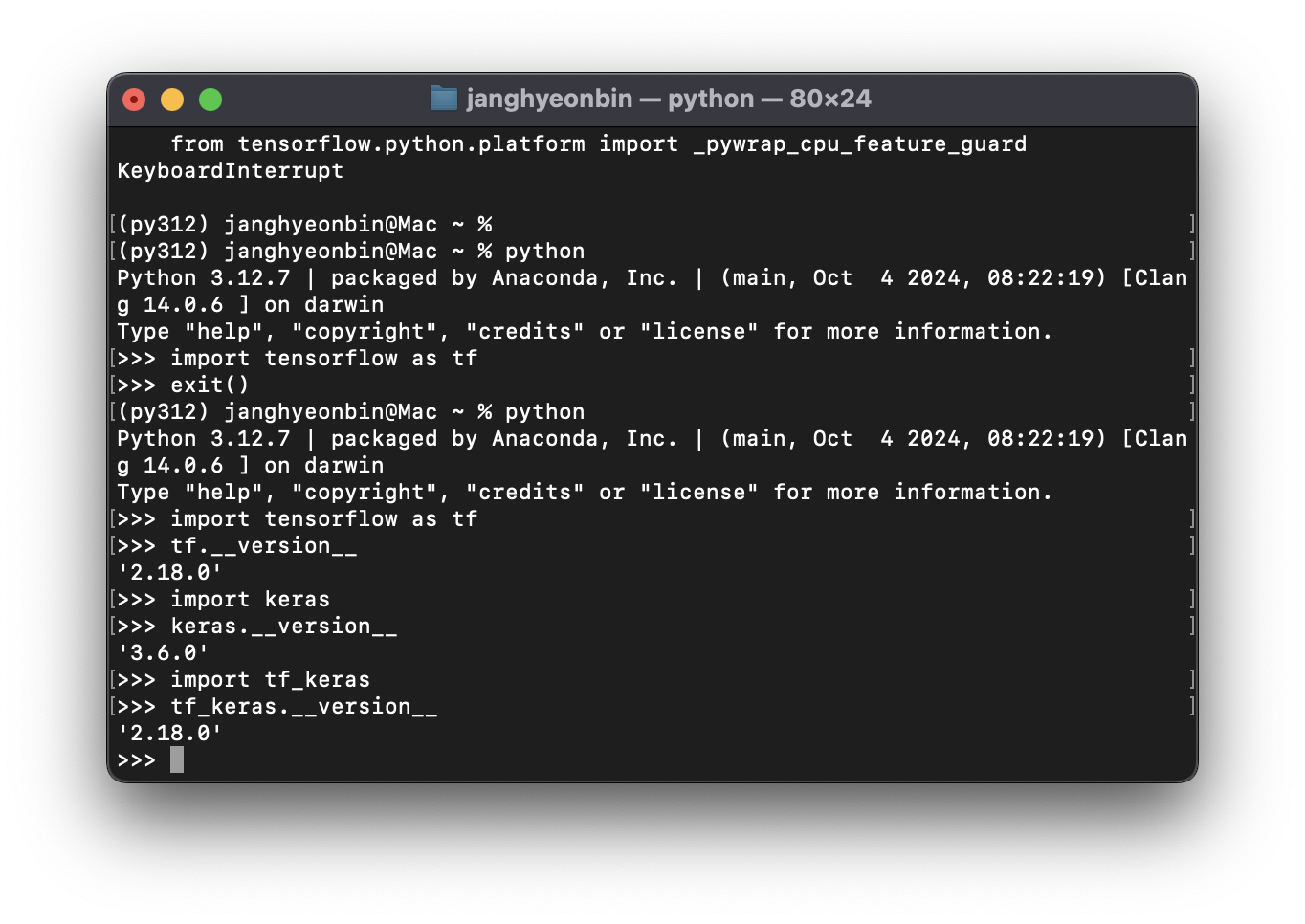
Gensim
Gensim은 머신 러닝을 사용하여 토픽 모델링과 자연어 처리 등을 수행할 수 있게 해주는 오픈 소스 라이브러리다.
$ pip install gensimimport gensim
gensim.__version__'4.3.3'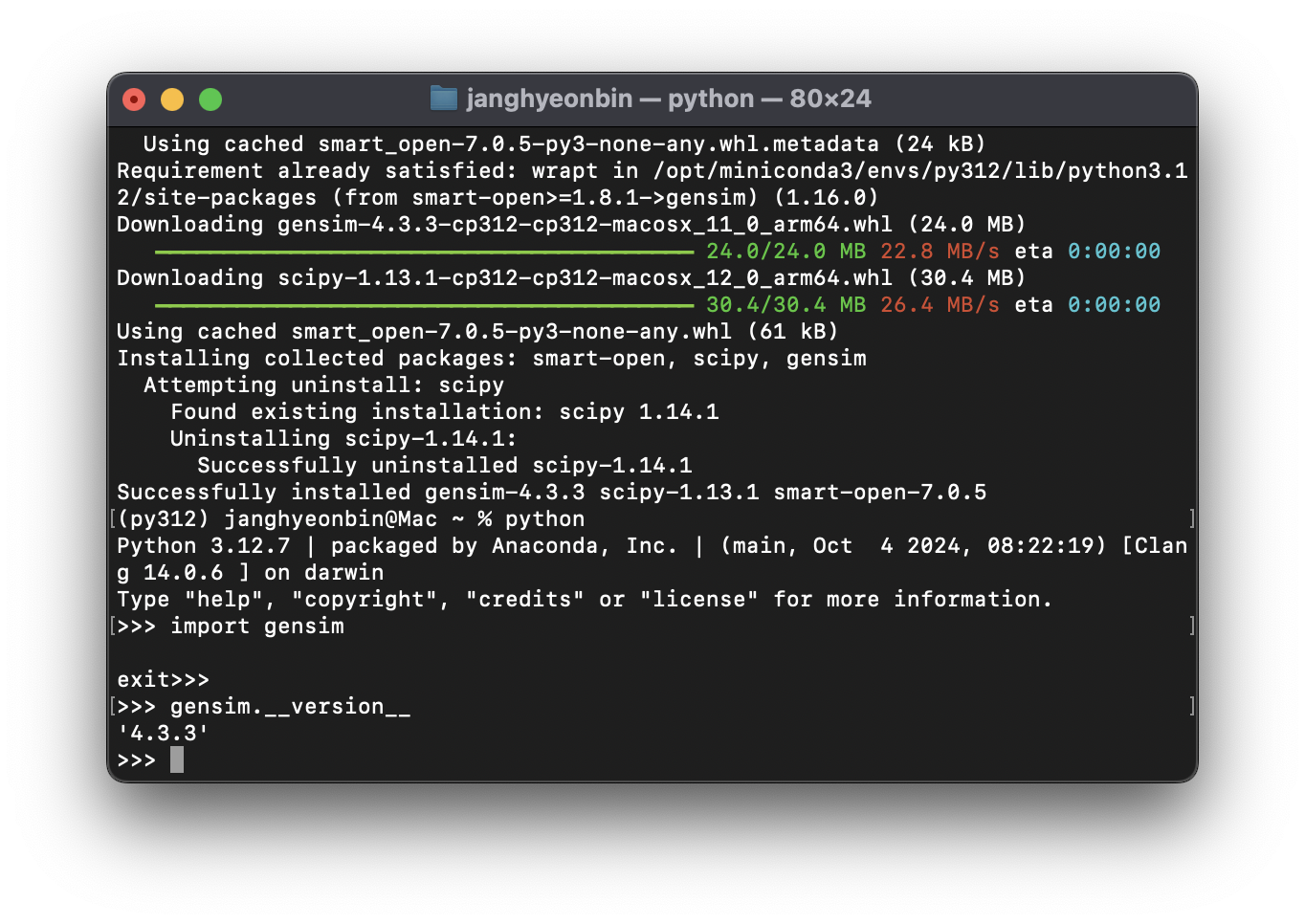
Scikit-learn
Python의 Machine Learning Library로 나이브 베이즈 분류, 서포트 벡터 머신 등 다양한 머신 러닝 모듈을 불러올수 있다.
$ pip install scikit-learnimport sklearn
sklearn.__version__'1.5.2'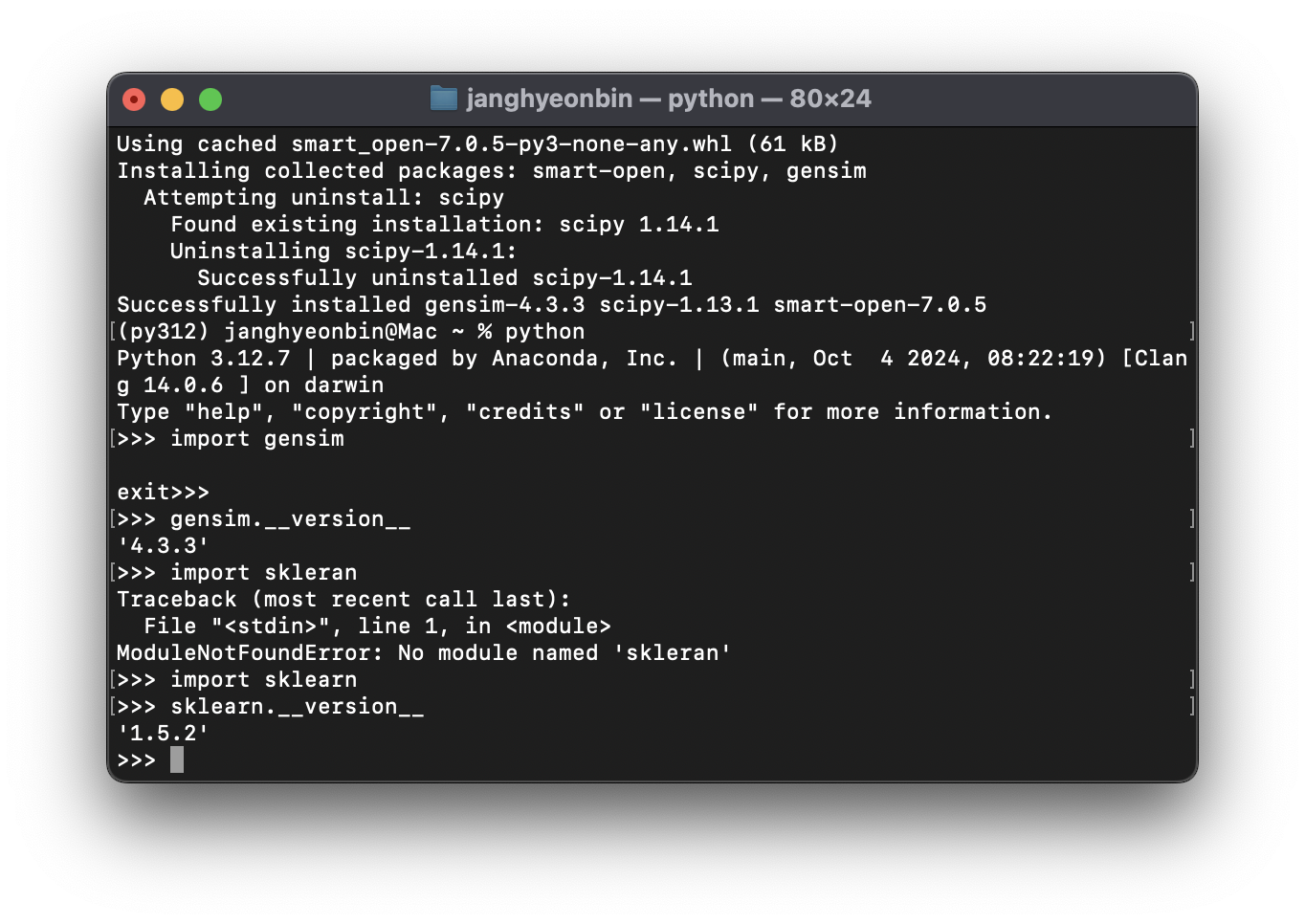
Jupyter
Jupyter Notebook은 웹에서 코드를 작성하고 실행할 수 있는 오픈소스 웹 애플리케이션이다. Anaconda 혹은 Miniconda를 설치하면 기본적으로 설치된다. 만약 Python을 직접 설치 했다면 pip를 통해 설치할수 있다.
$ pip install jupyter$ jupyter notebookNLTK
자연어 처리를 위한 파이썬 라이브러리
$ pip install nltkimport nltk
nltk.__version__'3.9.1'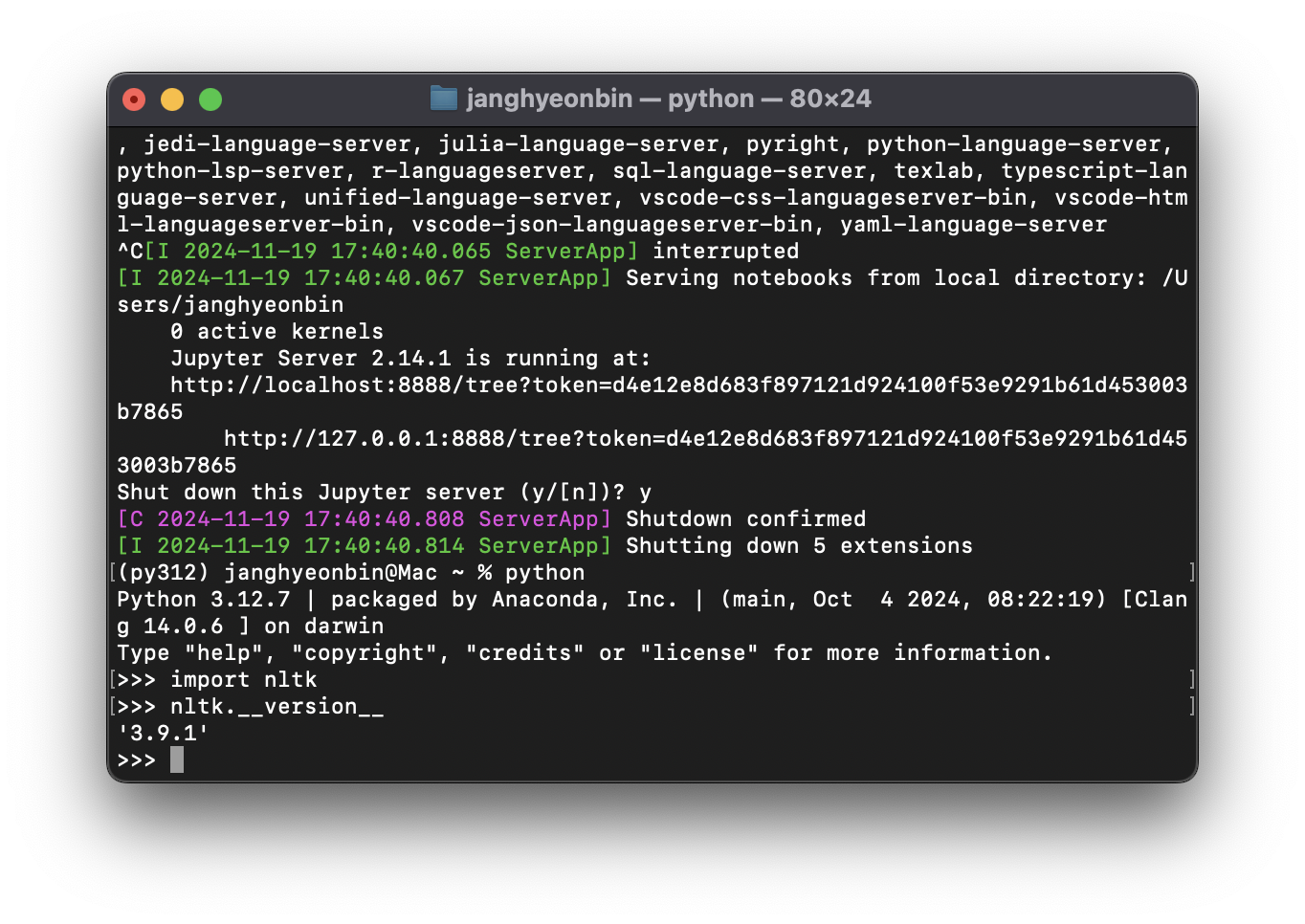
import nltk
nltk.download()
# 예시
nltk.download('treebank')KoNLPy
한국어 자연어 처리를 위한 형태소 분석기 패키지
$ pip install konlpyimport konlpy
konlpy.__version__'0.6.0'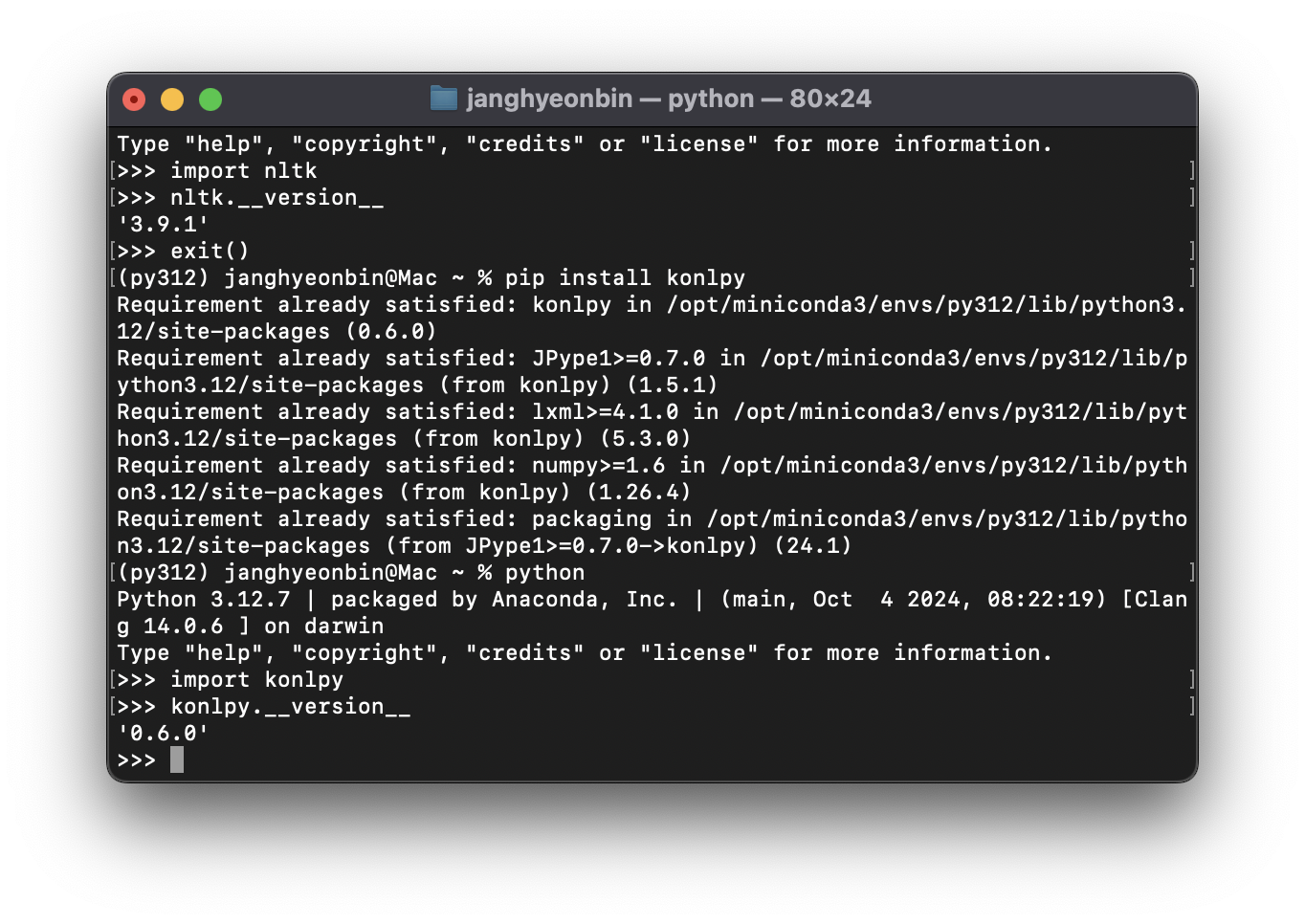
pandas
파이썬 데이터 처리를 위한 필수 라이브러리
$ pip install pandas
판다스는 import pandas as pd라 적는게 관례이다.
import pandas as pd
pandas.__version__'2.2.2'Series
시리즈 클래스는 1차원 배열의 values에 각 값에 대응 하는 index를 부여할수 있는 구조이다.
sr=pd.Series([17000, 18000, 1000, 5000],
index=["피자", "치킨", "콜라", "맥주"])
print('시리즈 출력: ')
print('-'*15)
print(sr)시리즈 출력:
---------------
피자 17000
치킨 18000
콜라 1000
맥주 5000
dtype: int64
print('시리즈의 값: {}'.format(sr.values))
print('시리즈의 인덱스: {}'.format(sr.index))시리즈의 값: [17000 18000 1000 5000]
시리즈의 인덱스: Index(['피자', '치킨', '콜라', '맥주'], dtype='object')DataFrame
데이터프레임은 2차원 리스트를 매개변수로 전달한다. 행방향 index와 열방향 column이 있다.
values=[[1,2,3],[4,5,6],[7,8,9]]
index=['one', 'two', 'three']
columns=['A','B','C']
df=pd.DataFrame(values, index=index, columns=columns)
print('데이터프레임 출력: ')
print('-'*18)
print(df)데이터프레임 출력:
------------------
A B C
one 1 2 3
two 4 5 6
three 7 8 9
print('데이터프레임의 인덱스: {}'.format(df.index))
print('데이터프레임의 컬럼: {}'.format(df.columns))
print('데이터프레임의 값: ')
print('-'*18)
print(df.values)데이터프레임의 인덱스: Index(['one', 'two', 'three'], dtype='object')
데이터프레임의 컬럼: Index(['A', 'B', 'C'], dtype='object')
데이터프레임의 값:
------------------
[[1 2 3]
[4 5 6]
[7 8 9]]데이터프레임은 List, Series, dict, Numpy의 nparrays, 그외 데이터프레임으로부터 생성할수 있다.
data=[
['1000', 'Steve', 90.72],
['1001', 'James', 78.09],
['1002', 'Doyeon', 98.43],
['1003', 'Jane', 64.19],
['1004', 'Pilwoong', 81.30],
['1005', 'Tony', 99.14],
]
df=pd.DataFrame(data)
print(df) 0 1 2
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14
df=pd.DataFrame(data, columns=['학번', '이름', '점수'])
print(df) 학번 이름 점수
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14
data={
'학번':['1000', '1001', '1002', '1003', '1004', '1005'],
'이름':['Steve', 'James', 'Doyeon', 'Jane', 'Pilwoong', 'Tony'],
'점수':[90.72,78.09,98.43,64.19,81.30,99.14]
}
df=pd.DataFrame(data)
print(df) 학번 이름 점수
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14
DataFrame 조회
print(df.head(3)) 학번 이름 점수
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
print(df.tail(3)) 학번 이름 점수
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14
print(df['학번'])0 1000
1 1001
2 1002
3 1003
4 1004
5 1005
Name: 학번, dtype: object
외부데이터 읽기
Pandas는 CSV, Text, Excel, SQL, HTML, JSON등 다양한 데이터 파일을 읽고 DataFrame을 생성할 수 있다.
pandas.read_csv
df=pd.read_csv('example.csv')
print(df) student id name score
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14print(df.index)RangeIndex(start=0, stop=6, step=1)Numpy
Numpy는 수치 데이터를 다루는 파이썬 패키지이다. Numpy의 핵심이라고 불리는 다차원 행렬 자료구조인 ndarray를 통해 벡터 및 행렬을 사용하는 선형 대수 계산에서 주로 사용된다. Numpy는 편의성뿐만 아니라, 속도면에서도 순수 파이썬에 비해 압도적으로 빠르다는 장점이 있다.
$ pip install numpyimport numpy as np # np라는 명칭으로 임포트하는게 관례
np.__version__'1.26.4'np.array()
Numpy의 핵심은 ndarray다. np.array()는 리스트, 튜플, 배열로부터 ndarray를 생성한다.
vec=np.array([1,2,3,4,5])
print(vec)[1 2 3 4 5]# 2차원 배열
mat=np.array([[10,20,30],[60,70,80]])
print(mat)[[10 20 30]
[60 70 80]]print('vec의 타입:',type(vec))
print('mat의 타입:',type(mat))vec의 타입: <class 'numpy.ndarray'>
mat의 타입: <class 'numpy.ndarray'>np.zeros(): 배열의 모든 원소에 0 삽입.
zero_mat=np.zeros((2,3))
print(zero_mat)[[0. 0. 0.]
[0. 0. 0.]]np.ones(): 배열의 모든 원소에 1삽입.
one_mat=np.ones((2,3))
print(one_mat)[[1. 1. 1.]
[1. 1. 1.]]np.full(): 배열에 사용자가 지정한 값을 삽입.
same_value_mat=np.full((2,2),7)
print(same_value_mat)[[7 7]
[7 7]]np.eye: 대각선으로는 1이고 나머지는 0인 2차원 배열 생성
eye_mat=np.eye(3)
print(eye_mat)[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]np.random.random(): 임의의 값을 가지는 배열 생성
random_mat=np.random.random((2,2))
print(random_mat)np.arange(): 0부터 n-1까지의 값을 가지는 배열 생성
range_vec=np.arange(10)
print(range_vec)[0 1 2 3 4 5 6 7 8 9]n=2
range_n_step_vec=np.arange(1,10,n)
print(range_n_step_vec)[1 3 5 7 9]np.reshape(): 내부 데이터는 변경하지 않으면서 배열의 구조를 바꿈.
reshape_mat=np.array(np.arange(30)).reshape((5,6))
print(reshape_mat)[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]]- slicing: ndarray를 통해 만든 다차원 배열은 Python의 자료구조인 List처럼 Slicing 기능을 지원한다. 슬라이싱 기능을 사용하여 특정 행이나 열들의 원스들에 접근할수 있다.
mat=np.array([[1, 2, 3], [4, 5, 6]])
print(mat)[[1 2 3]
[4 5 6]]slicing_mat=mat[0, :]
print(slicing_mat)[1 2 3]slicing_mat=mat[:, 1]
print(slicing_mat)[2 5]- integer indexing: 슬라이싱은 배열로부터 부분 배열을 추출할 수 있지만, 연속적이지 않은 원소로 배열을 만들 경우에는 슬라이싱이 불가. 이럴때 인덱스를 사용하여 배열을 구성 가능. 인덱싱은 원하는 위치의 원소들을 뽑을수 있음.
mat=np.array([[1, 2], [4, 5], [7, 8]])
print(mat)[[1 2]
[4 5]
[7 8]]print(mat[1, 0])4indexing_mat=mat[[2, 1], [0, 1]]
print(indexing_mat)[7 5]- numpy 연산: Numpy는 배열간 연산을 손쉽게 수행할 수 있다. 사칙연산에 연산자 +, -, *, /를 사용할 수 있으며
np.add(),np.subtract(),np.multiply(),np.divide()를 사용할수도 있다.
x=np.array([1,2,3])
y=np.array([4,5,6])result=x+y
print(result)[5 7 9]result=x-y
print(result)[-3 -3 -3]result=result*x
print(result)[-3 -6 -9]result=result/x
print(result)[-3. -3. -3.]numpy에서 벡터오 행렬곱 또는 행렬곱을 위해서는 dot()을 사용해야 함
mat1=np.array([[1,2],[3,4]])
mat2=np.array([[5,6],[7,8]])
mat3=np.dot(mat1, mat2)
print(mat3)[[19 22]
[43 50]]matplotlib
데이터를 chart 혹은 plot 으로 시각화 하는 패키지.
$ pip install matplotlibimport matplotlib as mpl
mpl.__version__'3.9.2'import matplotlib.pyplot as pltplot(): 라인 플롯을 그리는 기능을 수행.
plt.title('test')
plt.plot([1,2,3,4],[2,4,8,6])
plt.show()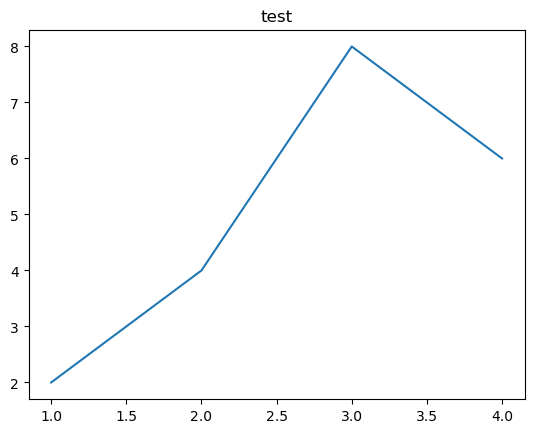
plt.title('test')
plt.plot([1,2,3,4],[2,4,8,6])
plt.xlabel('hours')
plt.ylabel('score')
plt.show()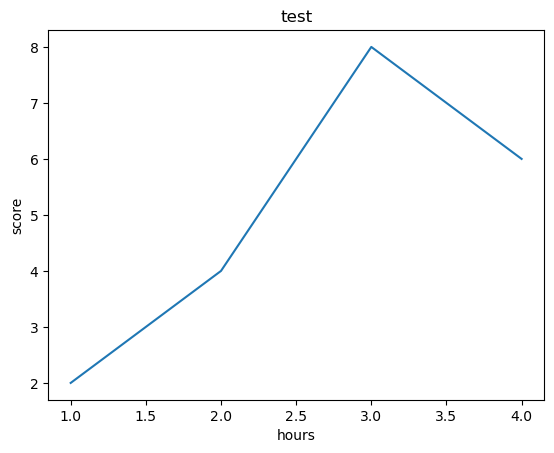
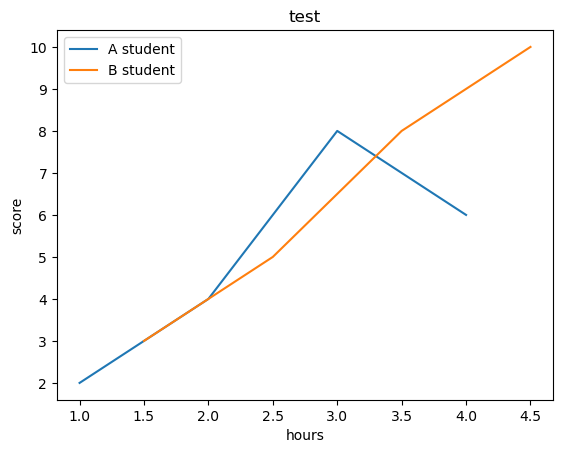
plt.title('test')
plt.plot([1,2,3,4],[2,4,8,6])
plt.plot([1.5,2.5,3.5,4.5], [3,5,8,10])
plt.xlabel('hours')
plt.ylabel('score')
plt.legend(['A student', 'B student'])
plt.show()