
ElasticSearch는 뭘까?
루씬(Lucene)기반의 오픈소스 검색 엔진
루씬은 java 라이브러리 중 하나이나 나는 java를 공부하지 않아서 생략하겠다.
> 준 실시간 검색시스템
- 색인된 데이터가 빠르게 검색된다.
> 고가용성을 위한 클러스터 구성
한대이상의 노드로 클러스터를 구성하여 높은 수준의 안정성을 달성하고 부하 분산이 가능하게끔된다.
(대충 그려본 사진, 노드들은 각 데이터를 처리하는 단위(직원)이라고 가정)
그리고 그것들의 집합을 '클러스터' 라고한다.
항상 1대이상의 노드가 있어야 클러스터가 형성된다.
> 동적 스키마 생성
입력된 데이터들에 대해 미리 스키마를 정의하지 않아도 동적으로 스키마(schema) 생성이 가능하다.
> Rest API 기반의 인터페이스
Rest API 기반의 인터페이스를 제공하여 진입장벽이 낮다고 한다.(아닌거같다.)
그렇다면 '클러스터'는 정확히 뭘까?

- 컴퓨터 클러스터는 여러대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터의 집합
ElasticSearch 클러스터는?
ElasticSearch 여러대의 노드들이 각자의 역할을 바탕으로 하나의 시스템처럼 동작하게 되어있는 것.
그러므로 클러스터의 성능이 모자라면 노드를 늘려서 대응이 가능해질것이다. 다만 늘리기만 한다고 만병통치약처럼 성능이 무작정 늘어나는것은 아니다.
노드의 종류

간략한 종류들만 파악을 해보도록 하자.
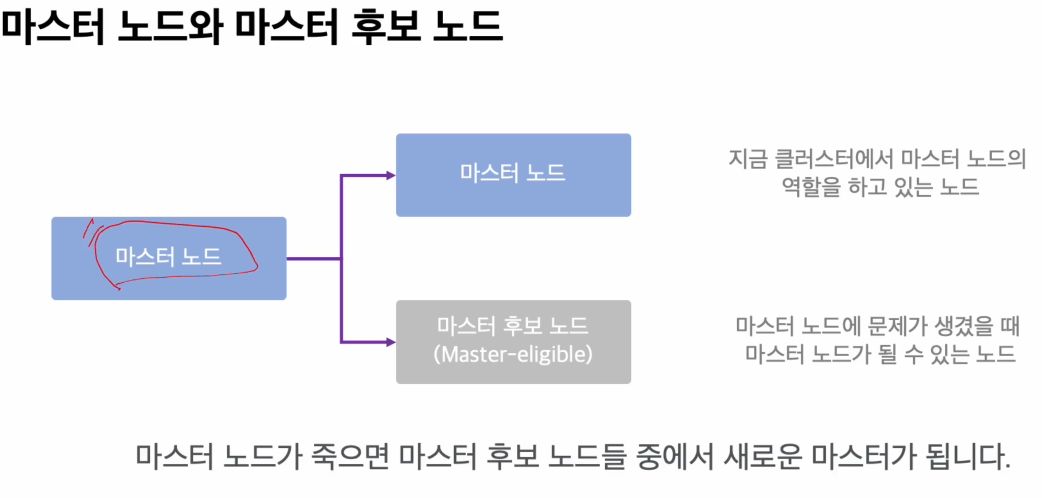
(직장에서 상사의 공백이 생기면 누군가가 승진을 하듯이.. 라고 이해해보자)
하나의 시스템처럼 움직이기 때문에 어떤 노드에 어떠한 요청을 한다고 하더라도 동일한 응답을 주게된다.
라는 신박한 개념도 가지고있다.
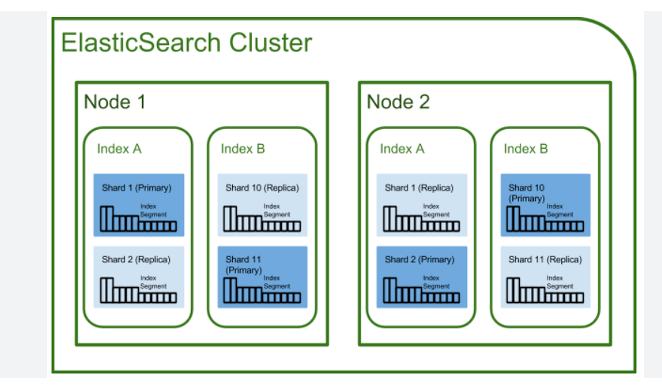
이렇게 하나의 클러스터(직장)안에 노드(직원)들이 여러명이 있는데. 그 중에서 어떠한 노드에게 어떠한 명령을 내려도 똑같이 응답을 하게된다.
카페에 가보자.
카페의 매니저인 점장 AA
커피만 만드는 직원 A
빵만 만드는 직원 B
커피랑 빵을 주문받는 직원 C
만약에 글을 읽는 누군가가 해당 카페에 가서 주문을 넣게된다면? 누구에게 주문을 하더라도 동일하게 커피는 나올것이다. 같은 클러스터(직장) 내에 있는 노드(직원) 이기 때문이다.
다만 내가 커피를 주문하려면 '직원C'에게 주문을 하게된다면
- 직원 C 가 A에게 커피를 요청
- 직원A가 직원C에게 커피를 전달
- 직원C가 고객(Req)에게 커피를 전달
식으로 간단하게 처리가 되지만 만약에 내가 커피를 만드는 Master노드 (직원AA)에게 주문을 한다면
- 마스터노드 AA가 직원 C에게 주문을 전달
- 직원 C가 A에게 커피를요청
- 직원 A가 C에게 커피를 전달
- 직원 C가 고객(Req)에게 커피를 전달
하는 것과 마찬가지고 불필요한 과정이 발생하므로 커피를 받는 시간은 늦어질 수있다.
이와 마찬가지로 우리는 요청을 보낼때 어떤 노드에 정확하게 주문할지에 대해서도 고민할 필요가 있다.
지금 작성한 이 글은 Elastic Search의 기본적인 개념이다. 추후에 상세한 개념들에 대해서 서술할 예정이다.
다음 글은 샤드와 INDEX에 대해서 게재할 예정이다.
나는 Elastic search를 이용하여 검색엔진을 만들 계획이다.
