02 OpenAI Chat API 기초
들어가며
랭체인과 랭그래프로 구현하는 RAG·AI 에이전트 실전 입문을 읽고 요약한 글입니다.
2장에서는 다음의 개념을 주로 다룹니다.
- OpenAI의 Chat 모델
- Chat Completions API
- 개념
- 주요 Parameter
- Function calling
- Token, Tokenizer
OpenAI의 Chat 모델
GPT-4o,GPT-4o-mini등의 명칭은 실제로는 모델 패밀리를 가리킨다.- API 사용 시 모델 패밀리(예:
gpt-4o) 혹은 정확한 모델 스냅숏(예:gpt-4o-2024-08-06)을 지정할 수 있다. - 모델 패밀리마다 최대 입력 토큰 수, 최대 출력 토큰 수, 요금 정책이 다르다.
Chat Completions API
개념
ChatGPT UI를 사용할 때와 마찬가지로, '입력 텍스트를 제공해 응답 텍스트를 얻는' 방식으로 동작한다.
다음은 Chat Completions API로의 요청 예시이다.
{
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "안녕하세요! 저는 이한서라고 합니다."},
{"role": "assistant", "content": "안녕하세요, 이한서님! 만나서 반갑습니다. 오늘은 어떤 이야기를 나눠볼까요?"},
{"role": "user", "content": "제 이름을 기억하세요?"}
]
}- Chat Completions API의 요청 파라미터에는 최소한
model,messages가 포함된다. - Chat Completions API 자체는 State를 저장하지 않아, 과거 대화 이력을 고려해 응답할 수 없다. 따라서 대화 이력을 고려해 응답하고 싶다면
messages에 과거의 모든 대화를 포함해야 한다.
호출 및 응답 예시
# 호출 예시
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "안녕하세요! 저는 이한서라고 합니다."},
{"role": "assistant", "content": "안녕하세요, 이한서님! 만나서 반갑습니다. 오늘은 어떤 이야기를 나눠볼까요?"},
{"role": "user", "content": "제 이름을 기억하세요?"}
]
)
print(response.to_json(indent=2))# 응답 예시
{
"id": "chatcmpl-BxGXp8zdZyJxkI4CgOBEtfQwb6m4o",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "네, 이한서님! 당신의 이름을 기억하고 있습니다. 어떤 도움이 필요하신가요?",
"refusal": null,
"role": "assistant",
"annotations": []
}
}
],
"created": 1753464649,
"model": "gpt-4o-mini-2024-07-18",
"object": "chat.completion",
"service_tier": "default",
"system_fingerprint": "fp_197a02a720",
"usage": {
"completion_tokens": 23,
"prompt_tokens": 66,
"total_tokens": 89,
"completion_tokens_details": {
"accepted_prediction_tokens": 0,
"audio_tokens": 0,
"reasoning_tokens": 0,
"rejected_prediction_tokens": 0
},
"prompt_tokens_details": {
"audio_tokens": 0,
"cached_tokens": 0
}
}
}주요 Parameter
| 파라미터명 | 개요 | 기본값 |
|---|---|---|
temperature | 0~2 사이의 값으로, 클수록 출력이 무작위해지고, 작을수록 결정적이고 예측 가능해짐. | 1 |
n | 한 번의 요청에 대해 생성할 답변 수 (예시: 3으로 설정하면 3개의 서로 다른 응답을 받을 수 있음.) | 1 |
stop | 답변 생성을 중단할 문자열(또는 문자열 배열). 이 문자열이 등장하면 해당 지점에서 생성이 멈춤. (예시: stop=["\n\n", "###"]) | null (중단 없음) |
max_tokens | 생성할 최대 토큰 수(답변의 길이 제한). 이 값을 넘어가면 답변 생성이 중단됨. 입력 토큰을 포함하지 않으며, 답변 자체의 길이만 제한함. | max_model_tokens |
log_probs | 답변의 각 토큰에 대한 로그 확률을 반환할지 여부. | false |
더 많은 파라미터는 문서를 참고하자.
Function calling
- 개발자가 미리 정의해 둔 외부 함수나 코드를 호출하고 그 결과를 바탕으로 더 정확하고 유용한 답변을 생성하게 하는 기능이다.
- 사용 가능한 함수를 LLM에게 알려주고, LLM에게 '함수를 사용하고 싶다'는 판단을 하게 하는 기능이다.
(LLM이 함수를 실행하는 것이 아니라, LLM은 '함수를 사용하고 싶다'는 응답만 반환한다.) - 아래는 질문(
서울 날씨는 어때?)에 대해 적절한 함수(get_weather)를 반환하는 예제이다.
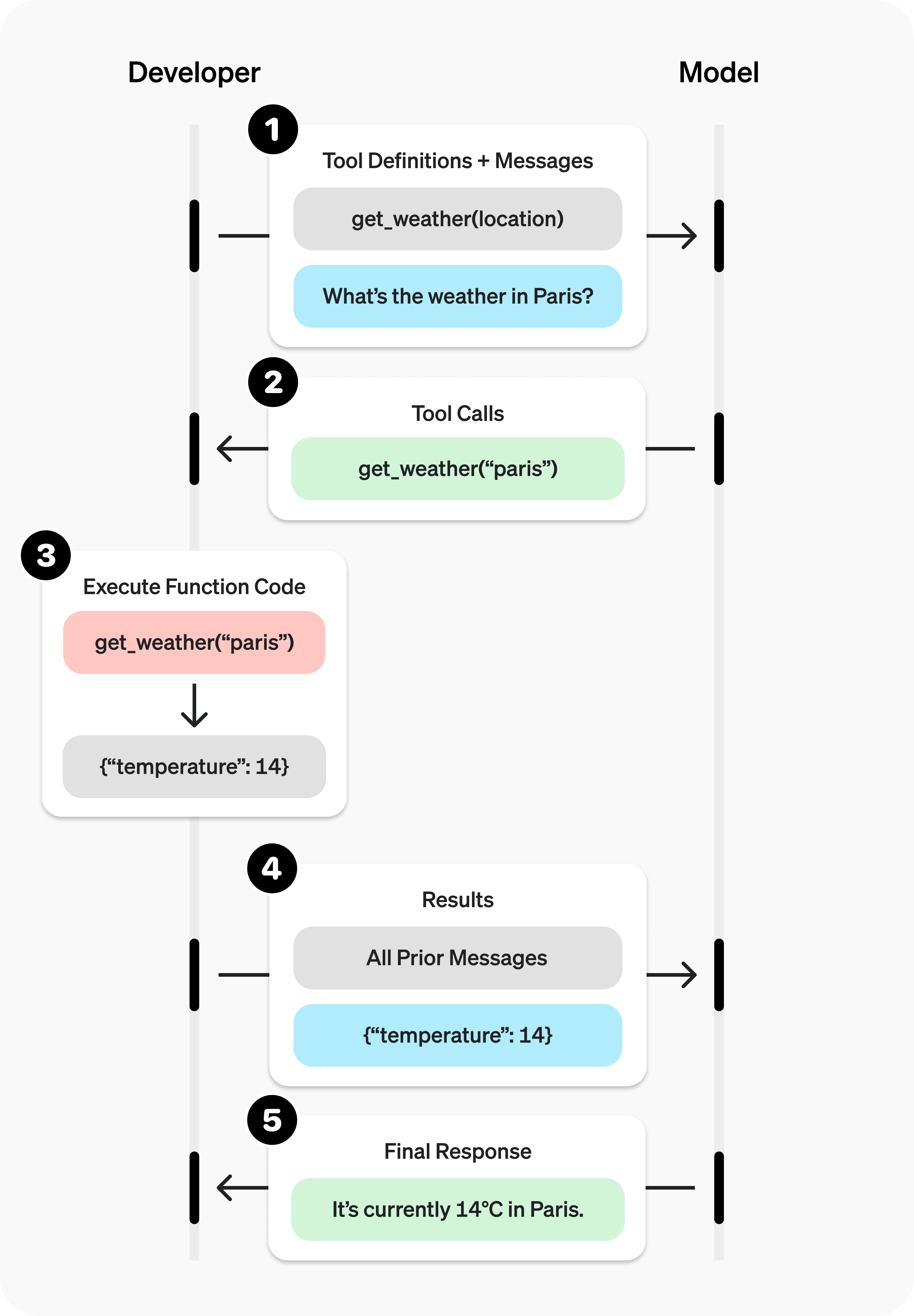
import openai
import json
# get_weather: 입력한 지역의 날씨를 알려주는 (예시용 더미) 함수 정의
def get_weather(location, unit="celsius"):
if "seoul" in location.lower():
return json.dumps({"location": "Seoul", "temperature": "26", "unit": unit})
return json.dumps({"location": location, "temperature": "unknown"})
client = openai.OpenAI() # OpenAI Client 초기화
def run_conversation():
messages = [{"role": "user", "content": "서울의 현재 날씨는?"}]
# function calling에 사용할 함수 목록 정의
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "도시 이름 (예: Seoul)"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"]
},
},
}
]
# Chat Completions API 호출
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools,
tool_choice="auto" # 모델이 지정된 함수를 사용해야 한다고 판단하면 함수명과 인수를 반환
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
if tool_calls: # 모델이 함수 호출 요청
messages.append(response_message)
for tool_call in tool_calls:
function_args = json.loads(tool_call.function.arguments)
function_response = get_weather(
location=function_args.get("location"),
unit=function_args.get("unit", "celsius"),
)
messages.append({ # 함수 실행 결과 메시지 추가
"tool_call_id": tool_call.id,
"role": "tool",
"name": "get_weather",
"content": function_response,
})
# 함수 실행 결과 반영 반복 요청
second_response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
)
return second_response.choices[0].message.content
# 실행 예시
final_answer = run_conversation()
print(final_answer) # 출력: 서울의 현재 날씨는 섭씨 26도입니다.JSON 모드
JSON 형태의 출력을 얻기 위해선 Chat Completions API의 'JSON 모드'를 사용할 수 있다.
이를 위해선
- 프롬프트에 'JSON'이라는 문자열을 포함시키고
response_format파라미터에{"type": "json_object"}를 지정한다.
# JSON 모드 호출 예시
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": '인물 목록을 다음 JSON 형식으로 출력해주세요.\n{"people": ["aaa", "bbb"]}',
},
{
"role": "user",
"content": "제가 좋아하는 노래는 정승환의 '비가 온다', 브리즈의 '뭐라할까!' 입니다. 으하하~",
},
],
response_format={"type": "json_object"},
)
print(response.choices[0].message.content)출력 결과는 다음과 같다.

요금
- 모델별 요금은 docs/models에서 확인할 수 있다.
- 실제로 발생한 요금은 usage에서 확인할 수 있다.
cf. Batch API
- GPT-4o나 GPT-4o-mini를 이용하기 위해 Chat Completions API 대신 Batch API를 사용할 수도 있다.
- Batch API는 비동기적으로 출력이 생성된다.
- 즉시 응답을 얻을 수 없는 대신, Chat Completions API의 절반 가격으로 이용할 수 있다.
Token, Tokenizer
LLM은 텍스트를 '토큰'이라는 단위로 분할해 처리하며, 분할 기준은 토크나이저마다 다르다.
예시) tiktoken: ChatGPT -> Chat, GPT
토큰 수 확인
OpenAI 플랫폼의 Tokenzier 또는 Python 패키지 tiktoken을 사용해 토큰 수를 확인할 수 있다.
한국어의 토큰 수에 대해
- 같은 의미의 텍스트라도 영어를 사용했을 때에 비해 한국어를 사용했을 때 더 많은 토큰을 사용하는 경향이 있다.
- 따라서 토큰 수를 줄일 목적으로는 한국어보다 영어를 사용하는 것이 바람직하다.
- 예시: 한국어와 영어의 토큰 수 비교 (
gpt-4o)
"LLM을 사용해 멋진 것을 만들기는 쉽지만, 프로덕션에서 사용할 수 있는 것을 만들기는 매우 어렵다." -> 28 tokens
"It's easy to make something cool with LLMs, but very hard to make something production-ready with them." -> 23 tokens
AI Safety 일짱이 되겠다.