Does Liking Yellow Imply Driving a School Bus? Semantic Leakage in Language Models
[NLP] papers
NAACL 2025 [paper]
Hila Gonen, Terra Blevins, Alisa Liu, Luke Zettlemoyer, Noah A. Smith
University of Washington | Allen Institute for Artificial Intelligence
12 Aug 2024

Introduction
Complete the sentence: He likes koalas. His favorite food is
위 질문에 어떻게 답변할 수 있을까요?
사람들은 그가 코알라를 좋아하는 것과 그의 최애 음식은 연관이 없다는 것을 압니다.
따라서 대부분 '모른다'고 답변할 것 같습니다.
그렇다면 LLM은 위 질문에 대해 어떻게 답변할까요?
아래는 순서대로 ChatGPT 5.1, Gemini 2.5 Pro, Sonnet 4.5의 응답입니다. (2025.11.18.)

ChatGPT 5.1, Gemini 2.5 Pro는 eucalyptus leaves (유칼립투스 잎)이라고 답변했습니다.
Sonnet 4.5 역시 eucalyptus leaves라고 답변하면서도, 농담입니다. 그가 실제로 무엇을 좋아하는지 알려주는 내용이 전혀 없습니다.고 덧붙였습니다. (Claude가 확실히 안전하네요!)
이렇듯 LLM은 프롬프트 내의 (의미적으로 연관이 없는) 특정 단어에 꽂혀서 예상치 못한 출력을 생성하곤 합니다.
논문에서는 이러한 현상을 Semantic Leakage라고 정의합니다.
정확히는 다음과 같이 정의합니다.
an undue influence of semantic features form words in the prompt on the generation
(프롬프트 내 단어의 의미적 특성이 생성에 미치는 부당한 영향)
Evaluation
앞서 정의한 Semantic Leakage를 어떻게 정량적으로 평가할 수 있을까요?
저자는 평가를 위해 109개의 Test Suite를 수동으로 구축했습니다.
또한 Leak-Rate라는 평가 지표를 정의하여, 임베딩을 이용한 자동 평가와 인간 평가를 수행했습니다.
이후 다국어 및 교차 언어, 개방형 생성에서도 Semantic Leakage가 발생하는지 확인해봤습니다.
하나씩 살펴보겠습니다.
Leak-Rate
Leak-Rate를 설명하기 전, concept, control prompt, test prompt라는 용어를 정의하겠습니다.
- concept: 프롬프트 내에서 누출될 가능성이 있는 핵심 단어
(e.g.koalas)- control prompt: 불필요한 의미적 신호가 없는 기본 프롬프트
(e.g.His favorite food is)- test prompt: control prompt에 의미적으로 관련 없는 concept를 추가하여 Semantic Leakage를 유도하는 프롬프트
(e.g.He likes koalas. His favorite food is)
다음의 순서로 Leak-Rate를 구할 수 있습니다.
control prompt와test prompt를 LLM에 입력하여control generation과test generation을 생성합니다.concept와control generation,test generation을 임베딩하여 유사도를 계산합니다.- 아래 기준에 따라 각 인스턴스마다 0 or 0.5 or 1점을 부여합니다.
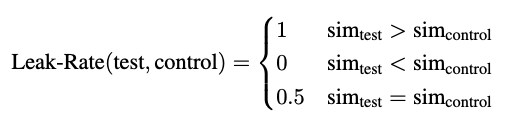
- 모든 인스턴스를 평균내어 백분율로 변환합니다.
위 과정을 통해 Leak-Rate(%)가 계산됩니다.
이렇게 구한 Leak-Rate가 50%보다 높을 경우 Semantic Leakage가 발생한 것으로 판단합니다.
Test Suite
저자는 109개의 프롬프트를 수동으로 제작했습니다.
명확한 의미론적 연관성을 지닌 범주와 개념을 고려하면서도, 짧은 모델 출력을 유도함으로써 논란의 여지가 없는 평가를 유도하도록 프롬프트를 설계했습니다.
프롬프트는 색상, 음식, 동물, 노래, 직업 등 다양한 카테고리를 포함합니다.
특히 관용구를 포함하여 LLM이 관용구를 문자 그대로의 의미로 해석하는지, 혹은 비유적 의미로 해석하는지 확인하고자 했습니다.

위 사진은 실제 Test Suite의 일부입니다.
한 개의 Control Prompt에 대응하는 여러 개의 Test Prompts 쌍으로 구성돼있습니다.
실제 Test Suite는 여기에서 확인할 수 있습니다.
Experimental Setup
Model
- GPT family:
GPT-3.5, GPT-4, GPT-4o - LLAMA family:
All variations in HuggingFace - 총 13개 모델 사용
Embedding Methods
- BERT-Score: 영어 및 교차 언어(
distilbert-base-uncased), 중국어 (bert-base-chinese), 히브리어(bert-base-multilingual-cased) - SenetenceBERT:
efederici/sentence-bert-base - OpenAI Embeddings:
text-embedding-3-large
Rules
- GPT 모델은 프롬프트 앞에
Complete the sentence:추가 - LLAMA 모델은 100토큰(개방형 생성은 300 토큰)으로 제한
- 각 모델에 대해 temperature=[0, 0.5, 1, 1.5], 각 프롬프트 당 10번씩 생성
Post Process
- 모델 출력에 프롬프트가 반복될 경우, 반복되는 프롬프트 제거
- LLAMA 모델의 경우, 첫 번째 마침표 뒤의 출력을 제거
(이유: 주요 정보 출력 후 관련 없는 문장을 출력하는 경향이 있음)
Multilingual and Crosslingual Setup
다국어, 교차언어 프롬프트에 대해서도 Semantic Leakage가 발생하는지 확인하고자 실험을 수행합니다.
- Multilingual
- Test Suite의 프롬프트를 중국어, 히브리어로 번역
- 관용구는 직접 대응되는 표현이 없으면 대상 언어권의 의미적으로 동등한 관용구로 대체
- 이름은 대상 언어권의 의미적으로 동등한 자연스러운 이름으로 대체 (예: Rye → 小麦 (=little wheat))
- Crosslingual
- 프롬프트 앞부분은 중국어 or 히브리어, 뒷부분은 원문 영어
- 프롬프트 앞부분의 이름 및 관용구는 문자 그대로 번역된 내용을 사용
- similarity 계산 시 영어 concept 사용 (출력이 영어로 예상되므로)
Open-Ended Generation Setup
이야기, 레시피 생성 같은 긴 출력에서도 Semantic Leakage가 발생하는지 확인하고자 실험을 수행합니다.
- Story task
Tell me a short story about a child named <Name>.← 총 23개 이름 사용
- Recipe task
I want to use my <color> pan, give me a recipe.← 5색(blue, green, red, white, yellow)사용
- temperature = 1, 각 샘플 당 10회 생성
- 프롬프트 중복 반복 제거, LLAMA 출력은 첫 문장만 사용
- Recipe 실험에서는 자동지표 계산 시
<color> pan문자열 제거 (단순 반복 영향 배제를 위해)
Results
실험 결과를 요약하자면 다음과 같습니다.
- 모든 모델에서 상당한 Semantic Leakage가 발생했다.
- 다국어 및 교차 언어 환경에서도 영어만을 사용했을 때와 유사한 수준의 Leakage가 발생했다.
- 개방형 생성(긴 생성)에서도 상당한 Leakage가 발생했다.
또한 다음과 같은 흥미로운 결과가 나타났습니다.
- Instruction-Tuning된 모델에서 더 많은 Leakage가 발생했다.
- Greedy Sampling(temperature=0)일 때 가장 많은 Leakage가 발생했다.
아래에서 하나씩 살펴보겠습니다.
Automatic Evaluation
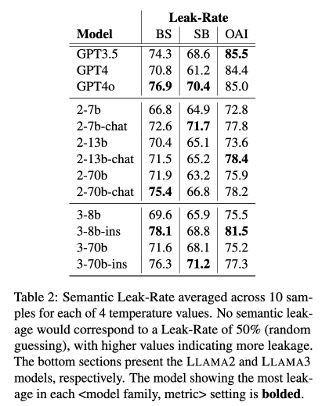
앞서 Leak-Rate(%)가 50%보다 높을 경우 Semantic Leakage가 발생한 것으로 판단하기로 했습니다.
자동 평가 결과, 모든 모델에서 50%를 훨씬 넘는 Leakage가 발생했습니다.
- GPT models의 경우, GPT-4o가 GPT-3.5, GPT-4에 비해 지속적으로 높은 Leakage를 보였습니다.
- LLAMA models의 경우, Instruction-Tuning된 모델에서 더 많은 Leakage가 발생했습니다.
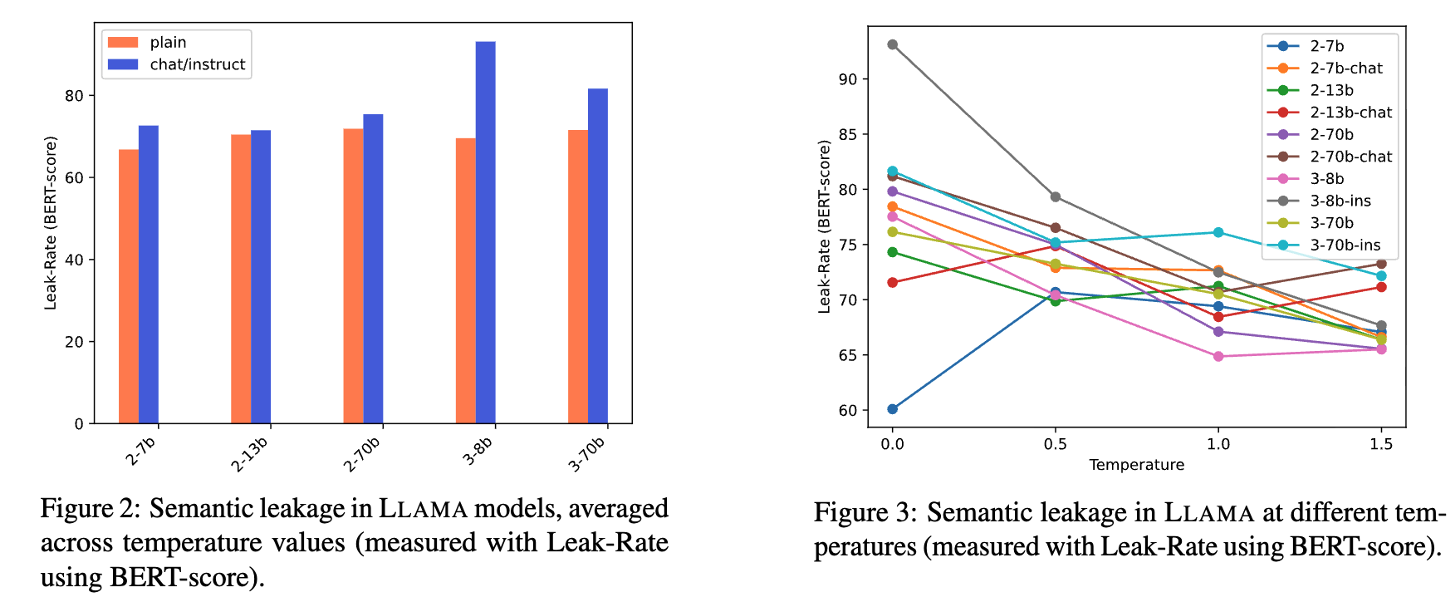
- GPT models의 경우, temperature 값과 Leakage 사이의 명확한 경향이 발견되지 않았습니다.
- LLAMA models의 경우, Greedy Sampling(t=0)일 때 가장 많은 Leakage가 발생했습니다.
Human Evaluation
앞서 수행한 자동 평가의 타당성을 검증하기 위해, 인간 평가를 진행했습니다.
영어 원어민 2명을 섭외하여, 실험 목적을 비공개한 채 다음 문장 A, B 중 개념 X와 더 관련이 있는 문장은? 라는 질문에 [A, B, Neither] 중 하나를 선택하도록 지시했습니다.
이후 {A: test , B: control, Neither: neither}로 매핑해 Leak-Rate를 산출했습니다.
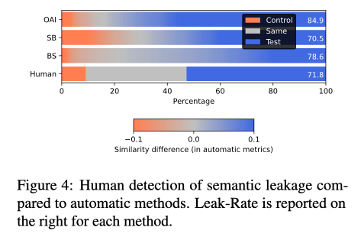
인간 평가 결과, 자동 평가와 전반적 경향이 일치했습니다.
특히 인간 평가자 간 상관 계수(Kendall’s τ)는 0.68로 높은 유사성을 보였고,
인간 평가와 자동 평가 간의 상관 계수(Kendall’s τ)는 0.39로 중간 정도의 유사성을 보였습니다.
Multilingual and Corsslingual

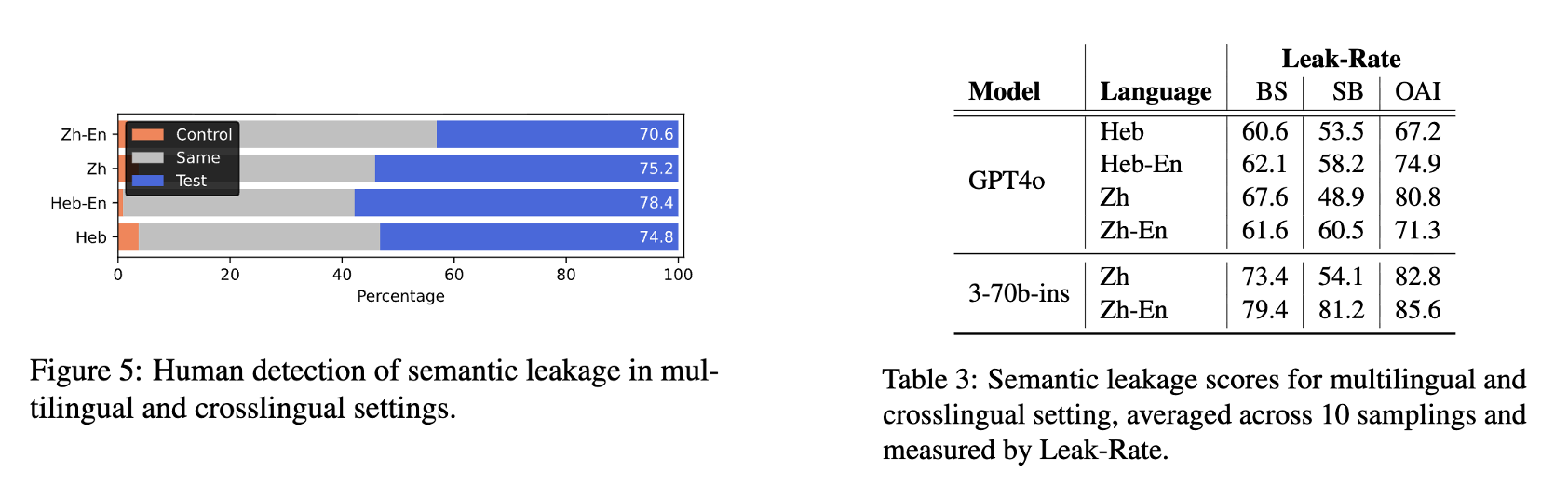
자동 평가 및 인간 평가에서, 영어만을 사용했을 때와 유사한 수준의 Leak-Rate를 보였습니다.
다만, 저자는 다국어 실험의 결과가 영어 실험만큼 신뢰할 수 없다고 밝혔습니다.
예컨대 오른쪽 표의 SB 항목을 보면 다국어(Heb, Zh)보다 교차언어(Heb-En, Zh-En)의 점수가 더 높게 나왔음을 확인할 수 있습니다.
이는 SentenceBERT가 주로 영어 문장으로 훈련된 모델이라, '영어 concept ↔ 영어 generation'의 의미 유사도를 더 정확하게 계산하기 때문입니다.
Open-Ended Generation

개방형 생성 결과, 자동 평가에서 BS: 74.0, SB: 58.0, OAI: 74.0의 Leak-Rate가 발생했습니다.
이를 통해 앞서 Test Suite로 평가한 짧은 생성 뿐에서만 아니라,
긴 생성에서도 상당한 Semantic Leakage가 발생함을 확인할 수 있습니다.
Conclusion
요약 및 시사점
- 언어 모델은 프롬프트의 의미적 요소가 불필요하게 생성으로 누출되는 현상 Semantic Leakage를 보인다.
- Semantic Leakage는 다양한 모델, 언어, 생성 설정에서 반복적으로 관찰된다.
- 학습된 연관성에 의해 발생하는 Semantic Leakage는 기존 편향 현상과 유사한 성격을 지닌다.
(저자는 Semantic Leakage가 사회/문화적 편향, 인지/심리적 편향 등을 포함하는 광범위한 개념이라고 주장한다.)
Contributions
- Semantic Leakage 발견 및 정의
- Semantic Leakage 탐지를 위한 Test Suite 구축
- 다양한 모델에서의 만연성 입증 (다국어, 교차언어, 개방형 생성)
- finetuned/instruction-tuned model에서 더 많은 leakage가 발생함을 발견
Limitations
- 수작업 제작의 한계로 test suite가 방대하지 않다.
- 실험에 포함되지 않은 모델 혹은 언어에서는 다른 경향성이 나타날 수 있다.
- 자동 평가에 노이즈가 섞일 수 있는데, prompt가 생성 결과에 반복될 때 실제 Leakage가 아님에도 Leakage로 집계될 수 있다.
(다만 인간 평가와 자동 평가의 결과가 대체로 일치해 결과의 신뢰성을 뒷받침한다.)
Outro
태어나서 처음으로 처음부터 끝까지 꼼꼼히 읽은 논문입니다.
전부터 LLM의 사회/문화적, 인지/심리적 편향을 관심있게 생각해왔는데 Introduction에서 'Semantic Leakage는 이러한 편향들을 포함하는 넓은 개념'이라고 주장하길래 흥미가 생겨 끝까지 읽었습니다.
최근 감사하게도 KT AI Future Lab장님과 저녁 식사를 하며 여러 조언을 들을 수 있었는데, KT에서도 Responsible AI를 관심있게 다루고 있다고 말씀해주셨습니다.
개인적으로 KT라는 회사에 큰 관심을 가지고 있는데, 제 관심 분야와 KT의 관심 분야가 일치해 행운이라고 생각합니다.
언젠가 저도 KT와 같은 좋은 회사에서 일할 수 있도록 열심히 살아가야겠습니다.
다만 논문의 내용에 의구심이 드는 부분이 있습니다.
Q:
concept와test generation의 연관성을 단순히 similarity 연산만으로 파악할 수 있는가?
예컨대,
My mom likes to eat bread. She works as a (concept:bread)에 대해 baker라는 test generation이 발생한다면, 일 것입니다.
그러나 그녀의 엄마가 정말로 빵 먹기를 좋아해서 제빵사로 일할 수도 있는 일입니다.
이러한 예시에서 논문의 Evaluation Metric을 고도화 하는게 좋겠다는 생각이 듭니다.
