

트랜스포머의 등장
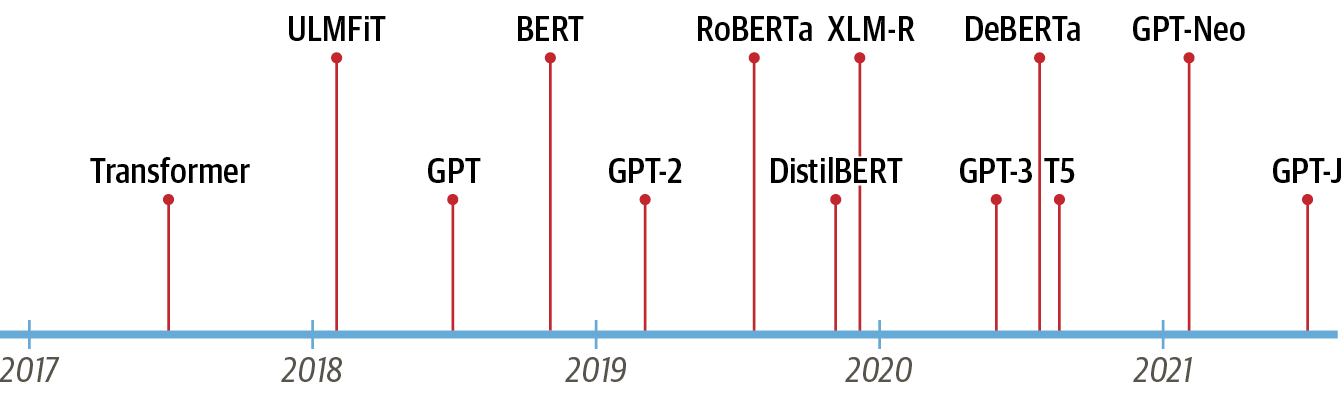
구글의 연구원들은 2017년 논문에서 시퀀스 모델링(sequene modeling)을 위한 새로운 신경망(neural network) 아키텍처를 제안했다.
트랜스포머라는 이름의 이 아키텍처는 기계 번역 작업의 품질과 훈련 비용 면에서 RNN을 크게 능가했으며, 효율적인 전이 학습(transfer learning) 방법인 ULMFiT가 매우 적은 양의 레이블링된 데이터로 최고 수준의 텍스트 분류 모델을 만들어냄을 입증했다.
이는 현재 가장 유명한 두 트랜스포머, GPT와 BERT의 촉매가 되었다.
이들은 트랜스포머 아키텍처와 비지도 학습(unsupervised learning)을 결합해 밑바닥부터 훈련할 필요를 없애고 거의 모든 NLP 벤치마크에서 큰 차이로 기록을 경신했다.
트랜스포머 모델을 이해하기 위해, 다음의 내용을 먼저 다루어보겠다.
- 인코더-디코더(encoder-decoder) 프레임워크
- 어텐션 메커니즘(attention mechanism)
- 전이 학습
인코더-디코더 프레임워크
트랜스포머가 등장하기 전, NLP에서는 LSTM과 같은 RNN 구조가 최선이었다.
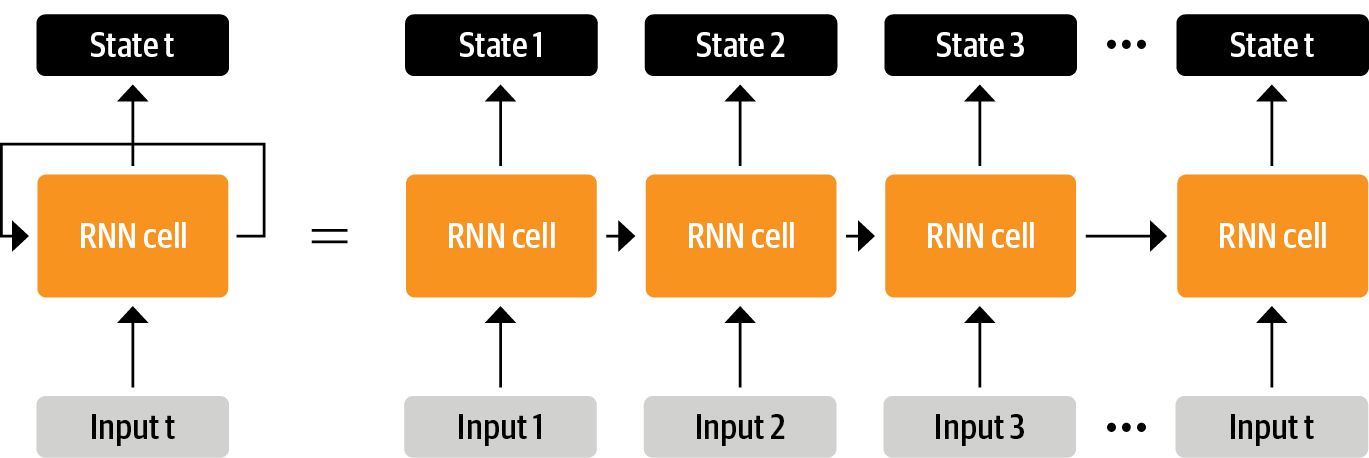
RNN은 입력을 받아 네트워크를 통과시킨 후 은닉 상태(hidden state)를 출력하고, 피드백 루프로 보내 자기 자신에게 다시 입력함으로써 출력한 정보의 일부를 다음 스텝에 사용한다. 이러한 구조는 NLP 작업, 음성 처리, 시계열 작업에 널리 사용되고 있다.
RNN은 단어 시퀀스를 한 언어에서 다른 언어로 매핑하는 기계 번역 시스템을 개발할 때 중요한 역할을 했으며, 이는 인코더-디코더(encoder-decoder) 또는 시퀀스-투-시퀀스(seq2seq) 구조로 처리하며 입력과 출력이 임의의 길이를 가진 시퀀스일 때 잘 맞는다.
인코더는 입력 시퀀스의 정보를 마지막 은닉 상태(last hidden state)라고도 부르는 수치 표현으로 인코딩하고, 이 상태가 디코더로 전달돼 출력 시퀀스가 생성된다.
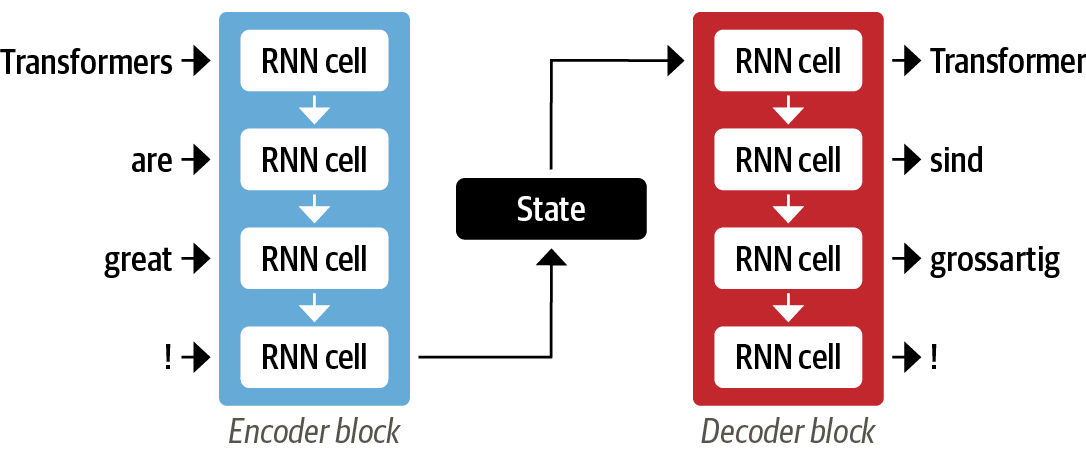
이러한 구조는 간결하지만, 인코더의 마지막 은닉 상태가 정보 병목(information bottleneck)이 된다는 약점이 있다. 디코더는 인코더의 마지막 은닉 상태만을 참조해 출력을 만들므로 전체 입력 시퀀스의 의미가 담겨야 하기 때문이다.
다행히 디코더가 인코더의 모든 은닉 상태에 접근해 이 병목을 제거하고, 이러한 메커니즘을 어텐션(attention) 이라고 한다.
어텐션 메커니즘
어텐션은 입력 시퀀스에서 은닉 상태를 만들지 않고 스텝마다 인코더에서 디코더가 참고할 은닉 상태(hidden state)를 출력한다는 주요 개념에 기초한다.
하지만 모든 상태를 동시에 사용하려면 디코더에 많은 입력이 발생하므로, 어떤 상태를 먼저 사용할지 우선순위를 정하는 메커니즘인 어텐션(attention)이 필요하다. 디코더는 모든 타임스텝마다 인코더의 각 상태에 다른 가중치, '어텐션'을 할당한다.
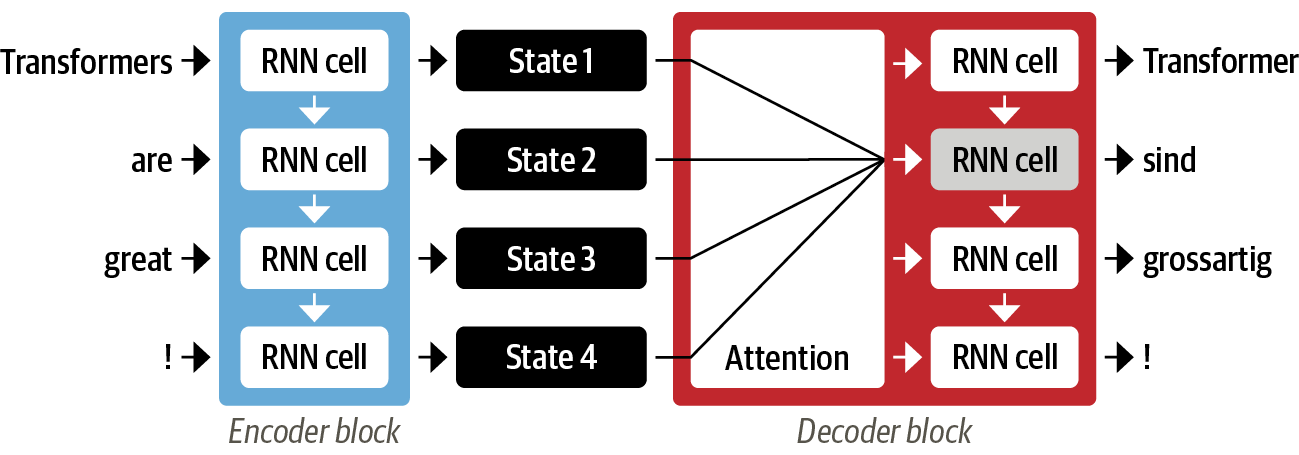
그러나 어텐션만으로는 순환 모델의 단점을 완벽히 해결할 수는 없다. 계산이 순차적으로 수행되며 입력 시퀀스 전체에 걸쳐 병렬화할 수 없기 때문이다.
이에 트랜스포머는 순환을 모두 없애고 셀프 어텐션(self-attention)을 사용해 모델링 패러다임을 바꿨다.
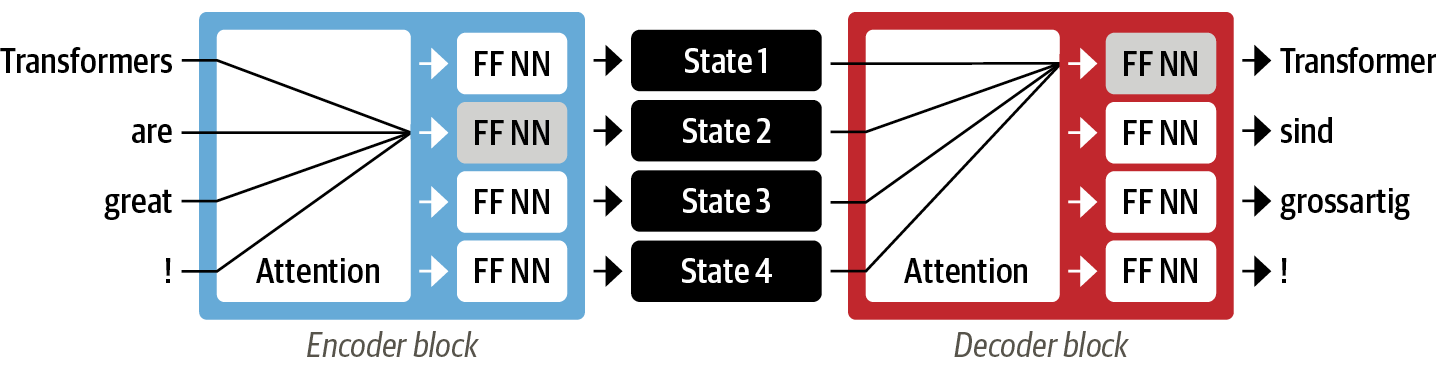
트랜스포머 논문에서는 대규모 말뭉치에서 번역 모델을 훈련했으나, 많은 실용적인 NLP 애플리케이션은 모델 훈련에 사용할 레이블링된 대규모 텍스트 데이터를 구하기 때문에 전이 학습을 필요로 하게 되었다.
NLP의 전이 학습
구조적으로 볼 때 모델은 바디(body)와 헤드(head)로 나뉜다.
바디의 가중치는 훈련하는 동안 원래 도메인에서 다양한 특성을 학습하고, 이 가중치를 사용해 새로운 작업을 위한 모델을 초기화한다. 전이 학습은 일반적으로 다양한 작업에서 적은 양의 레이블 데이터로 훨씬 효과적으로 훈련하는 높은 품질의 모델을 만든다.
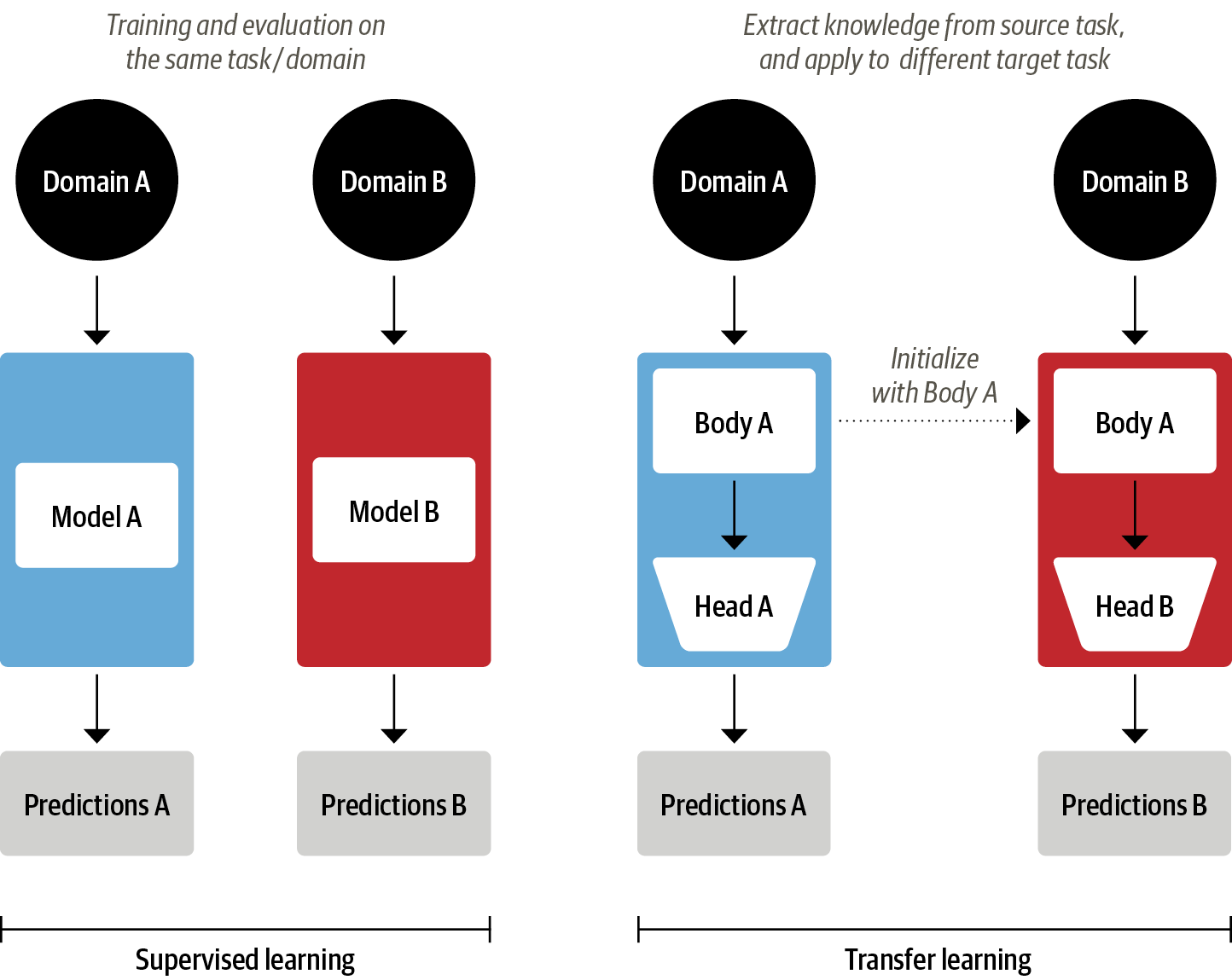
컴퓨터 비전과 달리, NLP에서는 전이 학습과 유사한 사전 훈련 과정이 무엇인지 수년간 특정하지 못했다.
그러다 2017년과 2018년, 몇몇 연구 단체가 NLP에서 전이 학습을 수행하는 새 방식을 제안했고,
그 뒤를 이어 범용적인 프레임워크 ULMFiT가 등장했다.
ULMFiT는 다양한 작업에 사전 훈련된 LSTM 모델을 적용하며, 세 개의 주요 단계로 구성된다.
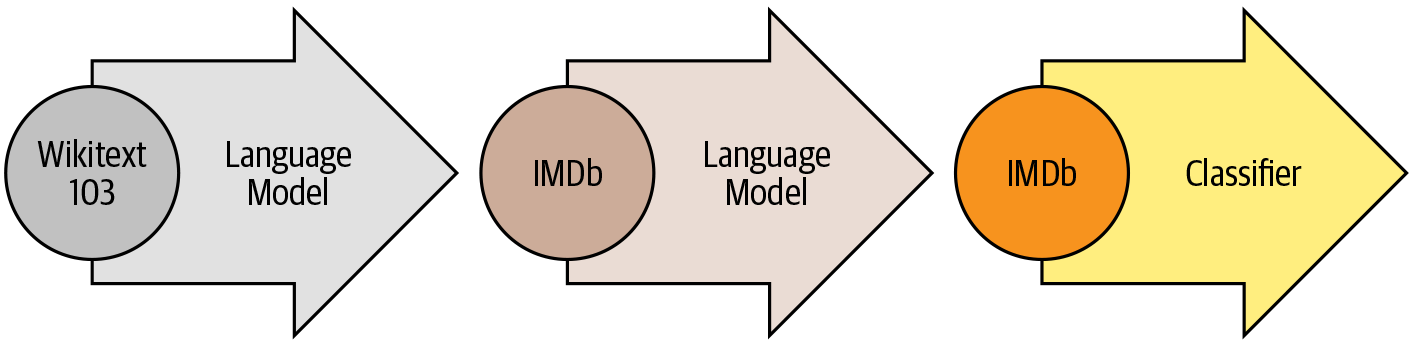
사전 훈련
- 이전 단어를 바탕으로 다음 단어를 예측하는 것으로, 언어 모델링(language modeling)이라 함.
- 레이블링된 데이터 필요 X; 위키피디아 같은 소스의 풍부한 데이터 활용
도메인 적응
- 언어 모델을 대규모 말뭉치에서 사전 훈련한 뒤, 도메인 내 말뭉치에 적응시킴.
- e.g. 위키피디아에서 훈련한 모델을 IMDb 영화 리뷰 말뭉치에 적응시키기
- 이제 모델은 타깃 말뭉치(IMDb 영화 리뷰)에 있는 다음 단어를 예측함.
미세 튜닝
- 언어 모델을 타깃 작업을 위한 분류층과 함께 미세 튜닝함.
- e.g. 영화 리뷰 감성 분류하기
2018년, 셀프 어텐션과 전이 학습의 결합으로 두 개의 트랜스포머 모델이 출시되었다.
GPT
- 트랜스포머 아키텍처의 디코더 부분만 사용
- ULMFiT 같은 언어 모델링(language modeling) 방법 사용
- BookCorpus 데이터셋(장르를 망라한 미출판 도서 7000권)으로 사전 훈련
BERT
- 트랜스포머 아키텍처의 인코더 부분만 사용
- 마스크드 언어 모델링(masked language modeling) 사용
- BookCorpus와 영어 위키피디아로 사전 훈련
🤗 허깅페이스 트랜스포머스
새로운 머신러닝 아키텍처를 새로운 작업에 적용하는 일은 일반적으로 다음 단계를 거친다.
1. 모델 아키텍처를 코드로 구현
2. (가능하다면) 서버로부터 사전 훈련된 가중치를 로드
3. 입력을 전처리하고 모델에 전달. 이후 해당 작업에 맞는 사후 처리 수행
4. 데이터로더(dataloader)를 구현하고 모델 훈련을 위해 손실 함수, 옵티마이저 정의
트랜스포머 애플리케이션
- 텍스트 분류 (text-classification)
- 개체명 인식 (ner)
- 질문 답변 (question-answering)
- 요약 (summarization)
- 번역 (translation)
- 텍스트 생성 (text-generation)
여기에서 실습해볼 수 있다.
🤗 허깅페이스 생태계
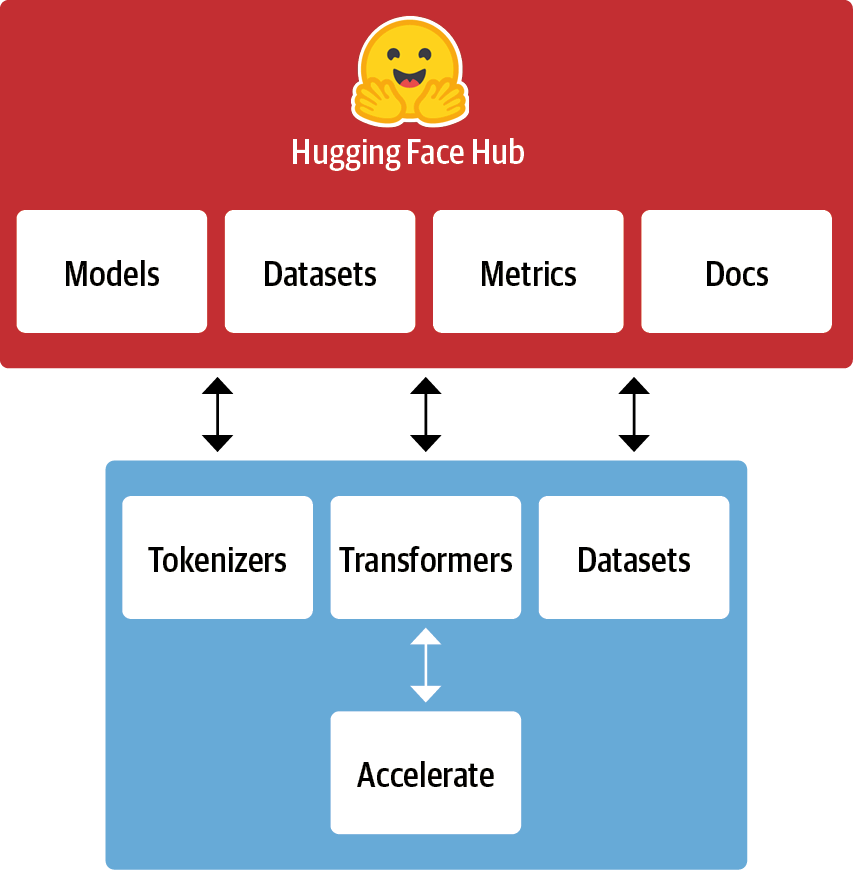
허깅페이스 생태계는 크게 라이브러리와 허브로 구성된다.
- 라이브러리: 코드 제공
- 허브: 사전 훈련된 모델 가중치, 데이터셋, 평가 지표를 위한 스크립트 등을 제공
Outro
참고 자료
- 트랜스포머를 활용한 자연어 처리 1장
- https://github.com/rickiepark/nlp-with-transformers
단어 정리
사전 훈련 (Pretraining)
- 대규모 데이터셋을 사용해 일반적인 패턴이나 지식을 미리 학습시키는 과정
- 예컨대 NLP 모델에서 텍스트 데이터를 이용해 언어의 기본 구조나 문법을 학습하는 단계
- 이후 특정한 작업을 위한 추가 학습(= 미세 튜닝)에 기초가 됨
미세 튜닝 (Fine Tuning)
- 사전 훈련된 모델을 특정 작업에 맞게 추가 학습시키는 과정
- 예컨대 사전 훈련된 언어 모델을 특정 분야(의학, 법률 등)의 텍스트로 추가 학습시킴으로써 해당 분야에서 더 정확하게 동작하도록 함
추상화 (Abstraction)
- 복잡한 시스템이나 개념을 더 단순하고 일반적인 형태로 표현하는 것
- NLP에서는 구체적인 데이터를 더 상위 개념으로 일반화하거나, 복잡한 구조를 단순화하여 다루기 쉽게 만드는 과정이 추상화임
파이프라인 (Pipeline)
- 여러 단계의 처리를 순차적으로 연결해 하나의 작업 흐름으로 만드는 것
- NLP에서는 텍스트 전처리, 모델 학습, 예측 등 다양한 단계가 순서대로 연결된 파이프라인을 통해 작업이 이루어짐
오버라이드 (Override)
- 객체 지향 프로그래밍(OOP)에서 자식 클래스가 부모 클래스의 메서드를 재정의하여 자신의 방식으로 동작하도록 하는 것
