
KNN 알고리즘
새로운 데이터가 주어졌을 때 기존 데이터 가운데 가장 가까운 K개 이웃(유사군 데이터)의 정보로 새로운 데이터를 예측하는 지도 학습 알고리즘이다.
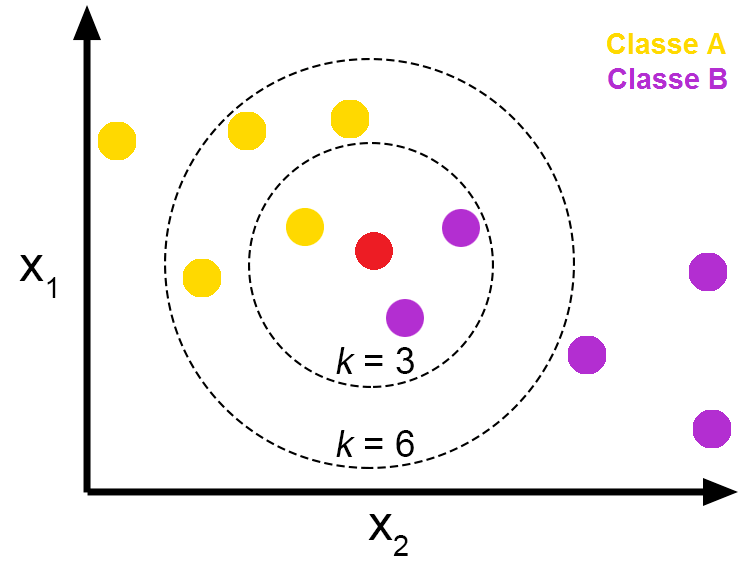
새로운 데이터가 주어졌을 때 (빨간 점) 이를 클래스 A로 분류할지, 클래스 B로 분류할지 생각해보자. k=3일때는, k가 3이라는 것은 가장 가까운 주변의 3개 데이터를 본 뒤, 3개의 주변 데이터가 더 많이 포함되어 있는 범주로 분류한다.
빨간 점 주변에 노란색 점(클래스 A) 1개와 보라색 점(클래스 B) 2개가 있다. 따라서 k=3 일 때는 해당 데이터가 클래스 B (보라색 점)으로 분류한다.
만약 k=6으로 한다면 어떠한가? 이제 원 안에 노란색 점 4개와 보라색 점 2개가 있게 되고 k=6일 때는 노란색 점으로 분류하게 된다.
KNN 은 K를 어떻게 정하냐에 따라 결과 값이 바뀐다. K가 너무 작아서도 안 되고, 너무 커서도 안 된다. K의 default 값은 5입니다. 가장 가까운 주변 5개 데이터를 기반으로 분류한다는 것입니다. 일반적으로 K는 홀수를 사용하는 것이 좋다. 짝수일 경우 동점이 되어 하나의 결과를 도출할 수 없기 때문이다.
KNN 은 경우 데이터와 데이터 사이의 거리를 구해야 한다. 거리를 구하는 방식은 보통 유클리드 거리 Eunclidean Distance 와 멘허튼 거리 Manhattan Distance 를 주로 쓴다.
유클리드 거리 :
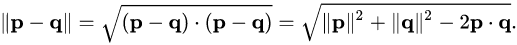
맨하튼 거리 :


새로운 것에 관심이 많고, 프로젝트 설계 및 최적화를 좋아합니다.