
소프트웨어학 복수전공을 하면서, 개발에 대한 지식이 너무 부족하다고 생각했다. 그래서 부스트캠프에서 백엔드 스터디를 시작하였다. 대학원생도 결론적으로는 모델 서빙을 할 줄 알아야 한다고 생각하기에 개발 공부가 나에게 필수적이라는 생각이 들었다.
http, server, client, 등 기본적인 지식을 인프런에서 2주간 수강하였다. 솔직히 말하자면 2주간 들은 내용으로 당장 서버를 만들고 API를 구성할 수 있는 정도로 많은 것을 알게 되진 않았다. 하지만, Spring, FastAPI 등을 배우는데 앞서 기본을 다진 과정이라고 생각하고 열심히 인강을 듣고 공부했다.
👍 인프런 강의
여러 인강이 있지만, 부캠 멘토님이 추천해주신 강의를 들었다.
(전) 우아한 형제들 기술이사셨던 김영한 님의 "모든 개발자를 위한 HTTP 웹 기본 지식" 강의를 들었다. 정말 깔끔하게 정리된 강의 자료와 짧게 구성된 강의는 집중해서 듣기 좋았다.
HTTP, 통신, 캐시, 쿠키, 웹 기본지식에 대한 공부가 필요하신 분들에게 정말 추천하는 강의다.
📖 공부 내용 정리
콘텐츠를 배포하면 안되기에, 공부내용을 간단하게 목차 형식으로만 남기자면,
🔽 섹션 1. 인터넷 네트워크
인터넷 통신
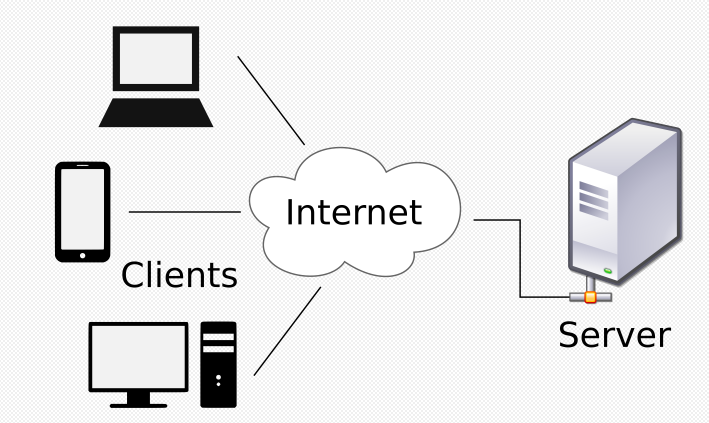
- 서버(server) : 서비스를 제공하는 컴퓨터(service provider)
- 다수의 클라이언트에게 서비스를 제공하기 때문에 고사양의 하드웨어를 갖춘 컴퓨터이지만, 하드웨어의 사양으로 서버와 클라이언트를 구분하는 것은 절대 아니며, 사양의 관계없이 서비스를 제공하는 소프트웨어가 실행되는 컴퓨터를 서버라고 한다. - 클라이언트(client) : 서비스를 사용하는 컴퓨터(service user)
- 서버와 이어진 모든 기기(컴퓨터의 경우 WIFI / 모바일은 모바일 네트워크)와 단말기에서 이용하는 웹에 접근하는 SW이며, 주로 서버에 요청을 보내고 응답을 받는 역할을 한다. - 서비스(Service)
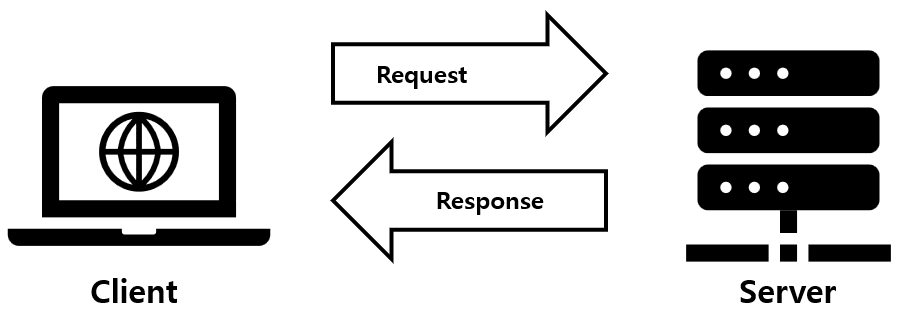
- 위에서 본 것 처럼 서버는 클라이언트로부터 요청을 받아 응답을 내려주고 클라이언트는 서버에 데이터를 요청하고 응답을 받는다. 재화와 서비스의 개념에서 가져와 서비스라고 일컫는다.
- 서비스의 종류에 따라 파일 서버/메일 서버/어플리케이션 서버 등으로 나눠진다.
IP(인터넷 프로토콜)

- IP 프로토콜의 한계:
1) 비연결성 : 패킷을 받을 대상이 없거나 서비스 불능이어도 패킨 전송
2) 비신뢰성 : 패킷이 순서대로 안 오거나, 패킷이 사라져도 알 수 없음
3) 프로그램 구분 : 같은 IP를 사용하는 서버에 통신하는 애플리케이션이 둘 이상,,,구분 불가..
TCP, UDP

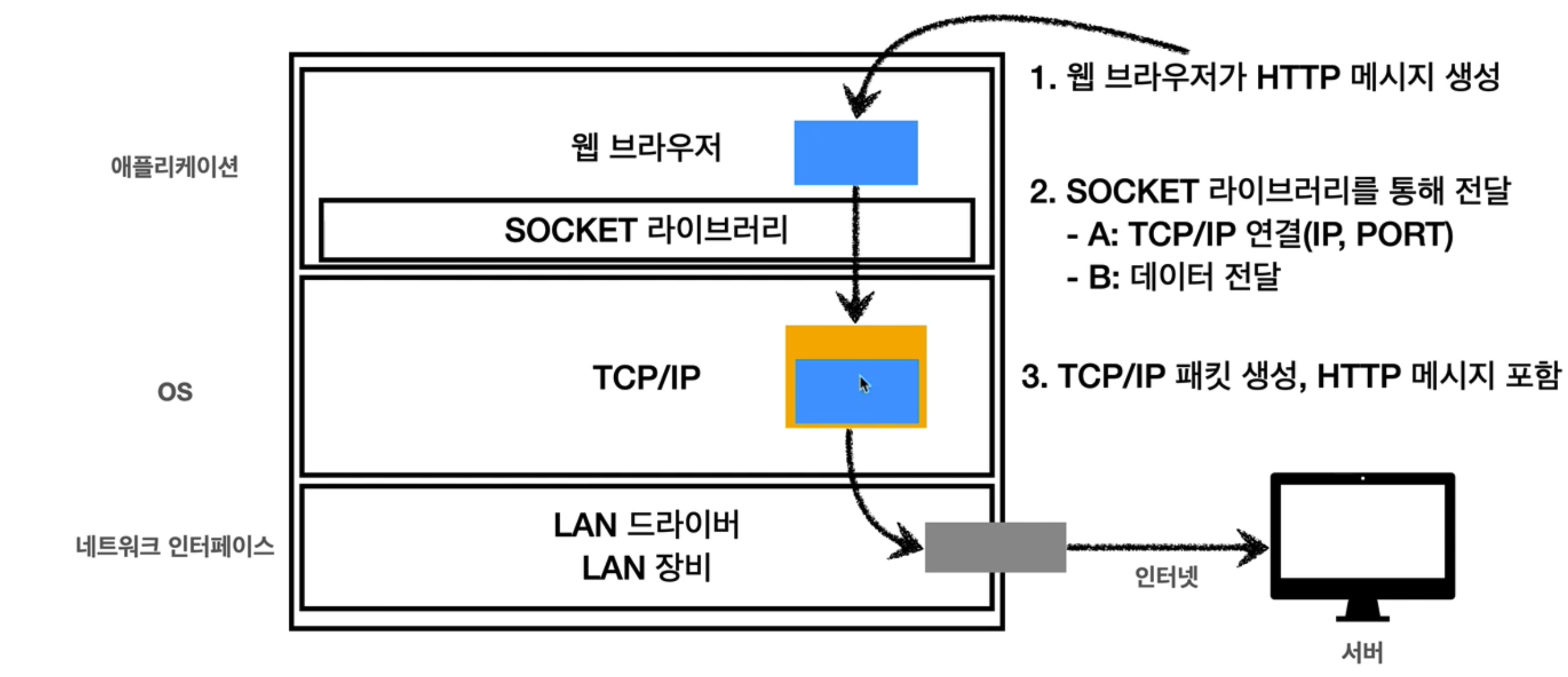
전송데이터를 TCP세그먼트로 싸고, 그걸 IP패킷으로 싸고 거기에 Ethernet frame을 싸서 LAN 카드를 통해 서버에 전송하는 것이다.
-TCP : 3 way handshake, 패킷 순서 보장, 데이터 전달 보장 => 대부분 TCP 사용 중
-UDP : 기능이 거의 없음, 속도는 TCP보다 빠르지만, 패킷 순서 보장하지 않고, 데이터 전달도 보장하지 못함. 거의 IP 같음...
PORT
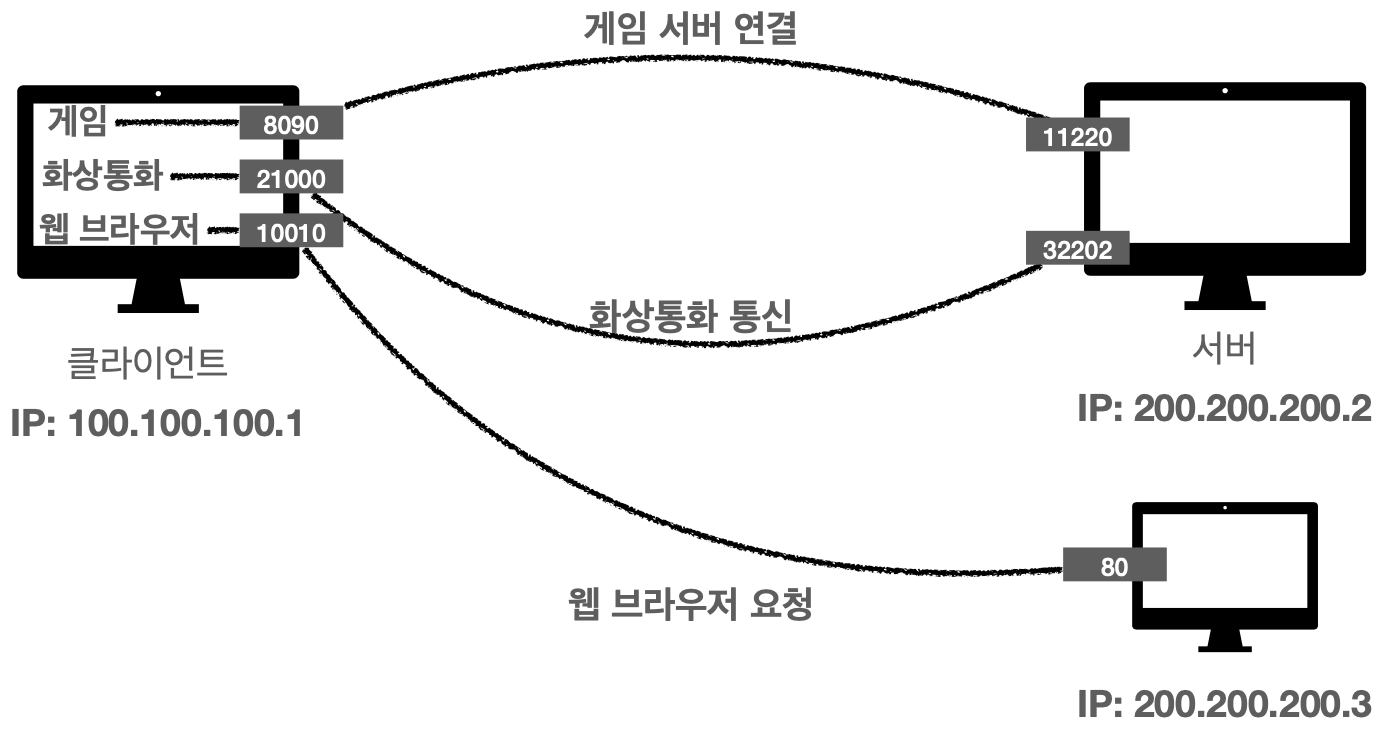
- HTTP = 80
- HTTPS = 443
- 0~65535 = 할당 가능
- 0~1023 = 잘 알려진 포트로서 사용하지 않는게 좋음
DNS

🔽 섹션 2. URI와 웹 브라우저 요청 흐름
URI
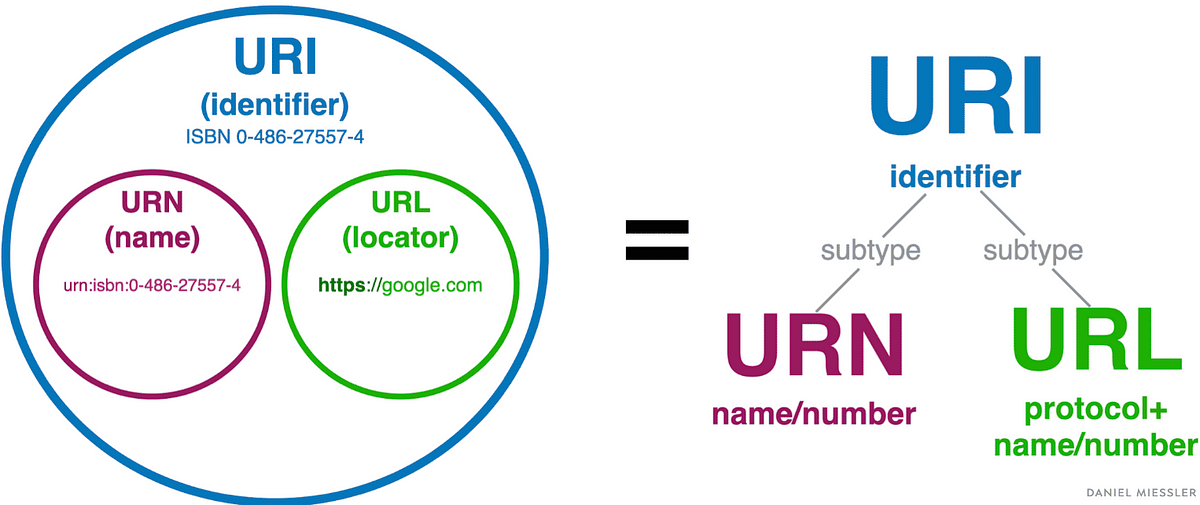
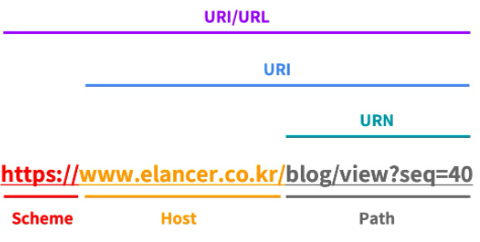
웹 브라우저 요청 흐름
🔽 섹션 3. HTTP 기본
모든 것이 HTTP
HTTP = HyperText Transfer Protocol
지금은 Http 시대!
HTTP 메시지에 모든 것을 전송!
클라이언트 서버 구조
Stateful, Stateless
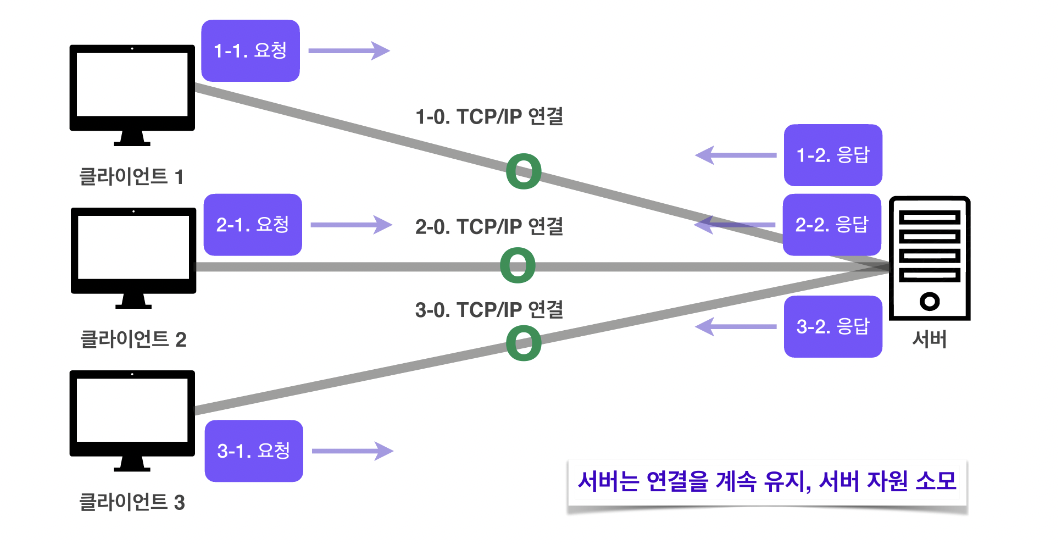
- stateful (상태 유지) : 항상 같은 서버가 유지됨
- stateless (무상태 프로토콜) : 아무서버나 호출해도 됨. 서버가 클라이언트의 상태를 보존하지 않음. => 서버 확장성 높음!
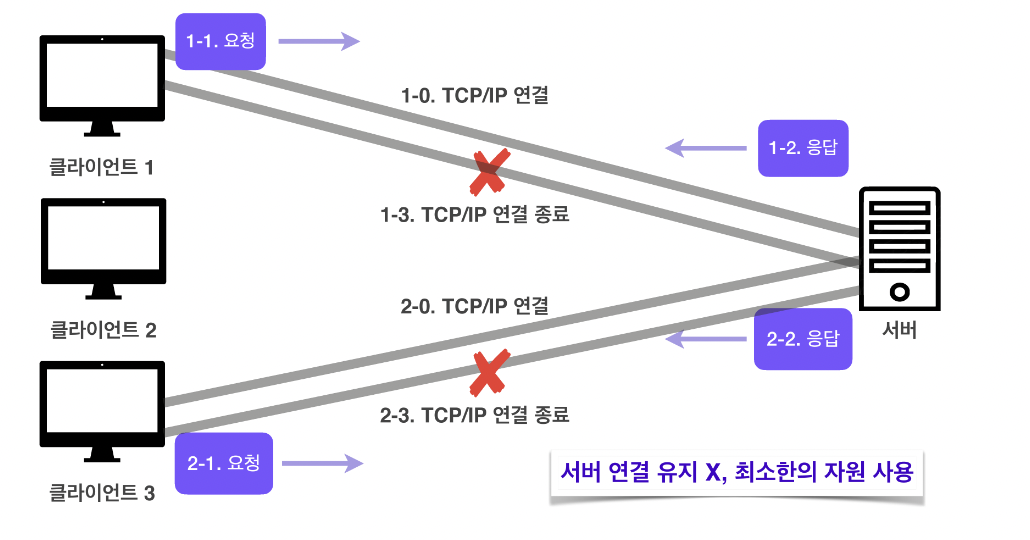
비 연결성(connectionless)
Http는 기본이 연결을 유지하지 않는 모델!!
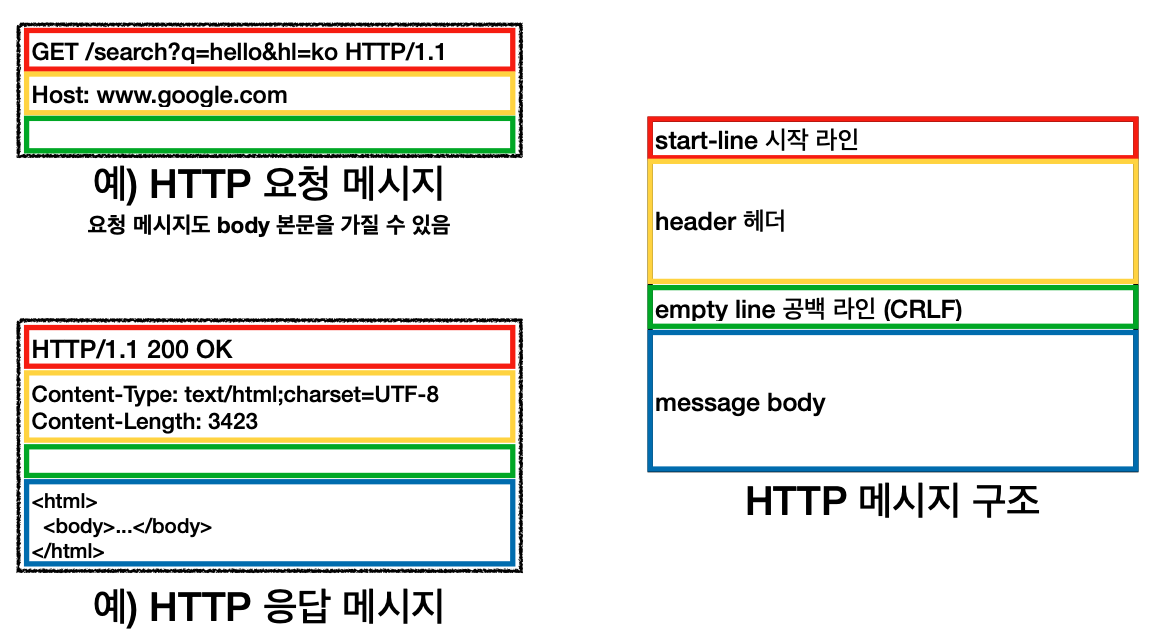
HTTP 메시지
🔽 섹션 4. HTTP 메서드
HTTP API를 만들어보자
가장 중요한 것은 리소스 식별!!
리소스와 해당 리소스를 대상으로 하는 행위를 분리해서 URI를 구성해야한다.
- 리소스 : 회원
- 행위 : 조회, 등록, 삭제, 변경
HTTP 메서드 - GET, POST, PUT, PATCH, DELETE
- GET : 리소스 조회
- POST : 요청 데이터 처리, 주로 등록에 사용
- PUT : 리소스를 대체, 해당 리소스가 없으면 생성
- PATCH : 리소스 부분 변경
- DELETE : 리소스 삭제
(+) 기타 메서드
• HEAD : GET과 동일하지만 메시지 부분을 제외하고, 상태 줄과 헤더만 반환
• OPTIONS : 대상 리소스에 대한 통신 가능 옵션(메서드)을 설명(주로 CORS에서 사용)
• CONNECT : 대상 리소스로 식별되는 서버에 대한 터널을 설정
• TRACE : 대상 리소스에 대한 경로를 따라 메시지 루프백 테스트를 수행
GET 과 POST 의 차이점
-
사용목적
: GET은 서버의 리소스에서 데이터를 요청할 때, POST는 서버의 리소스를 새로 생성하거나 업데이트할 때 사용 (DB로 따지면 GET은 SELECT 에 가깝고, POST는 Create 에 가깝다고 보면 된다.) -
요청에 body 유무
: GET 은 URL 파라미터에 요청하는 데이터를 담아 보내기 때문에 HTTP 메시지에 body가 없음. POST 는 body 에 데이터를 담아 보내기 때문에 당연히 HTTP 메시지에 body가 존재. -
멱등성 (idempotent)
: GET 요청은 멱등이며, POST는 멱등이 아니다.
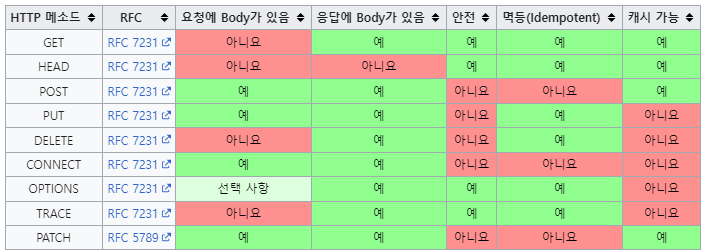
HTTP 메서드의 속성
1) 안전 (Safe Method) : 호출해도 리소스를 변경하지 않음
2) 멱등 (Idempotent Methods) : 한번 호출하든 100번 호출하든 결과가 같음
3) 캐시가능 (Cacheable Methods) : 응답 결과 리소스를 캐시해서 사용해도 됨
🔽 섹션 5. HTTP 메서드 활용
클라이언트에서 서버로 데이터 전송
데이터 전달 방식은 크게 2가지로 볼 수 있는데,
1) 쿼리 파라미터를 통한 데이터 전송
ex) GET
2) 메시지 바디를 통한 데이터 전송
ex) POST, PUT, PATCH

HTTP API 설계 예시
• HTTP API - 컬렉션
- POST 기반 등록
- 예) 회원 관리 API 제공
• HTTP API - 스토어
- PUT 기반 등록
- 예) 정적 컨텐츠 관리, 원격 파일 관리
• HTML FORM 사용
- 웹 페이지 회원 관리
- GET, POST만 지원
🔽 섹션 6. HTTP 상태코드
HTTP 상태코드 소개

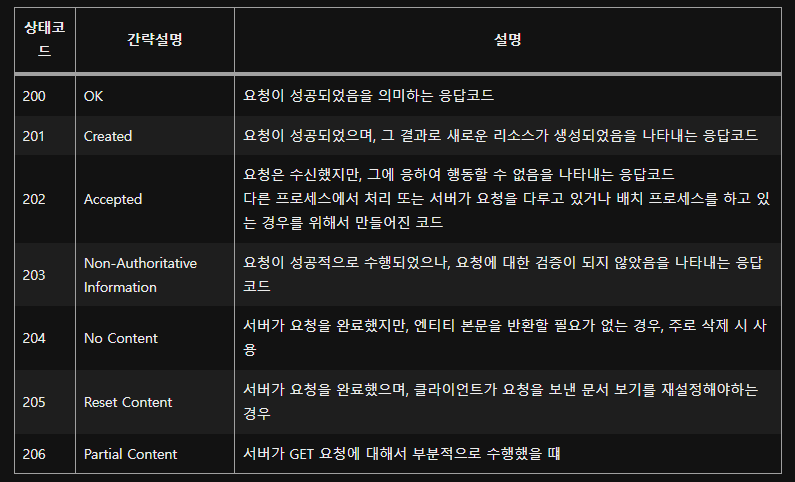
2xx - 성공
3xx - 리다이렉션
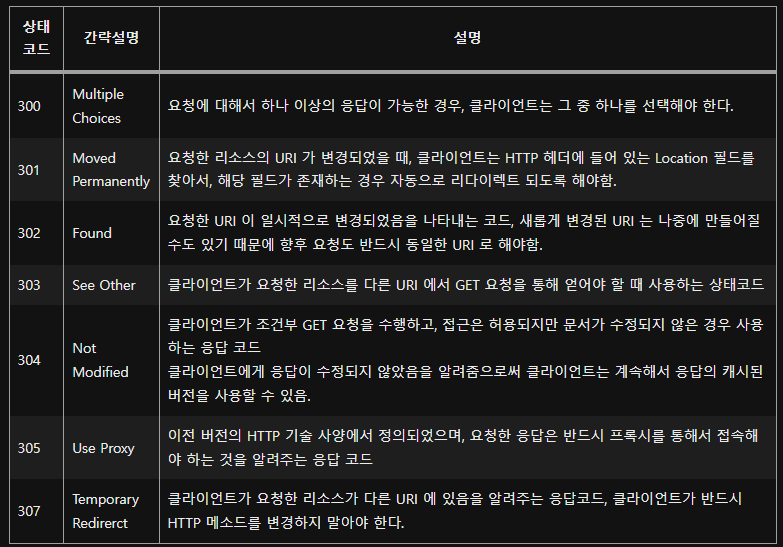
4xx - 클라이언트 오류
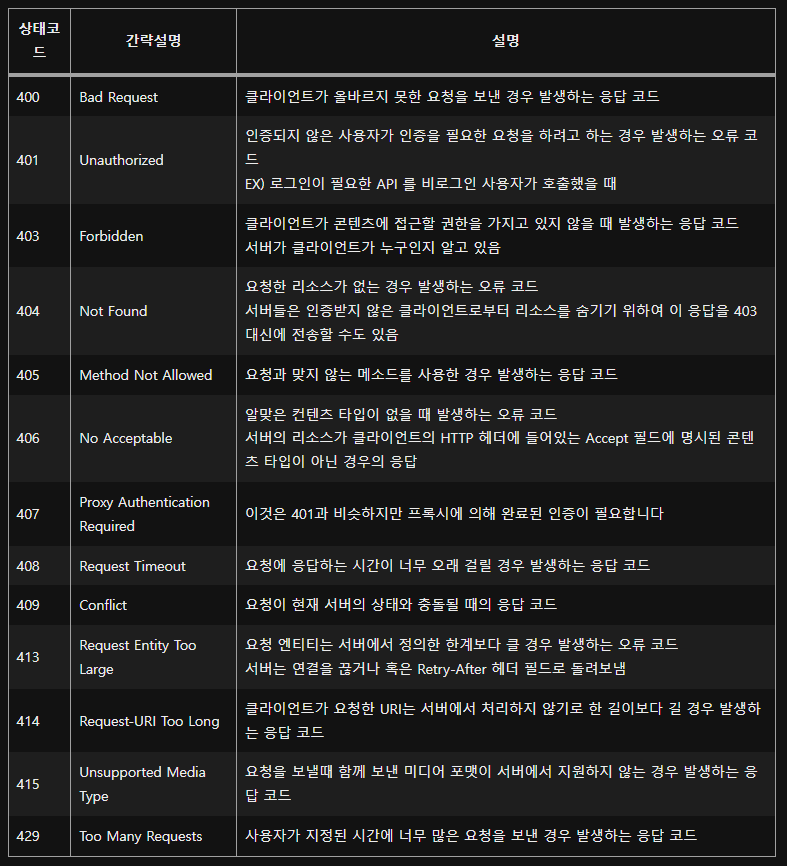
5xx - 서버 오류

🔽 섹션 7. HTTP 헤더1 - 일반 헤더
HTTP 헤더 개요
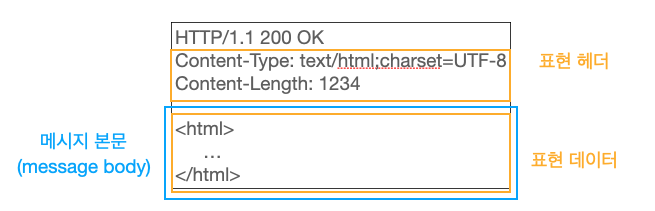
표현
엔티티(Entity) -> 표현(Representation) 으로 명칭이 바뀌었다
Representation = representation Metadata + Representation Data
표현 = 표현 메타데이터 + 표현 데이터
추후에 REST API속 REST가 Representation 을 의미함.
콘텐츠 협상
• Accept: 클라이언트가 선호하는 미디어 타입 전달
• Accept-Charset: 클라이언트가 선호하는 문자 인코딩
• Accept-Encoding: 클라이언트가 선호하는 압축 인코딩
• Accept-Language: 클라이언트가 선호하는 자연 언어
협상 헤더는 요청시에만 사용
전송 방식
- 단순 전송
- 압축 전송
- 분할 전송
- 범위 전송
일반 정보
- From: 유저 에이전트의 이메일 정보
- Referer: 이전 웹 페이지 주소
- User-Agent: 유저 에이전트 애플리케이션 정보
- Server: 요청을 처리하는 오리진 서버의 소프트웨어 정보
- Date: 메시지가 생성된 날짜
특별한 정보
• Host: 요청한 호스트 정보(도메인)
• Location: 페이지 리다이렉션
• Allow: 허용 가능한 HTTP 메서드
• Retry-After: 유저 에이전트가 다음 요청을 하기까지 기다려야 하는 시간
인증
1) Authorization: 클라이언트 인증 정보를 서버에 전달
2) WWW-Authenticate: 리소스 접근시 필요한 인증 방법 정의
쿠키
- Set-Cookie: 서버에서 클라이언트로 쿠키 전달(응답)
- Cookie: 클라이언트가 서버에서 받은 쿠키를 저장하고, HTTP 요청시 서버로 전달
ex) 로그인 상황에서 쿠키를 사용하지 않으면, 모든 요청에 사용자 정보를 포함해서 로그인 정보를 알려줘야함(http는 stateless 이기에,,) ... 그 대안으로,, 쿠키가 필요함...
❗쿠키 정보는 항상 서버에 전송됨
• 네트워크 트래픽 추가 유발
• 최소한의 정보만 사용(세션 id, 인증 토큰)
• 서버에 전송하지 않고, 웹 브라우저 내부에 데이터를 저장하고 싶으면 웹 스토리지 (localStorage, sessionStorage) 참고
❗ 주의 : 보안에 민감한 데이터는 저장하면 안됨(주민번호, 신용카드 번호 등등)
🔽 섹션 8. HTTP 헤더2 - 캐시와 조건부 요청
캐시 기본 동작
<캐시가 없을 때>
• 데이터가 변경되지 않아도 계속 네트워크를 통해서 데이터를 다운로드 받아야 한다.
• 인터넷 네트워크는 매우 느리고 비싸다.
• 브라우저 로딩 속도가 느리다.
• 느린 사용자 경험
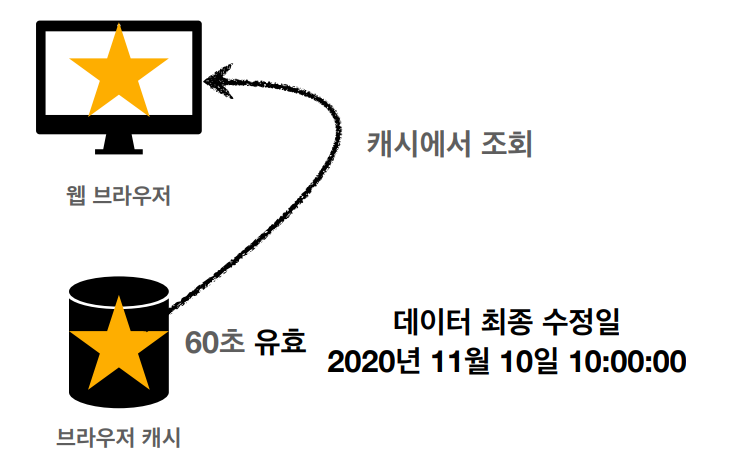
<캐시 적용>
• 캐시 덕분에 캐시 가능 시간동안 네트워크를 사용하지 않아도 된다.
• 비싼 네트워크 사용량을 줄일 수 있다.
• 브라우저 로딩 속도가 매우 빠르다.
• 빠른 사용자 경험
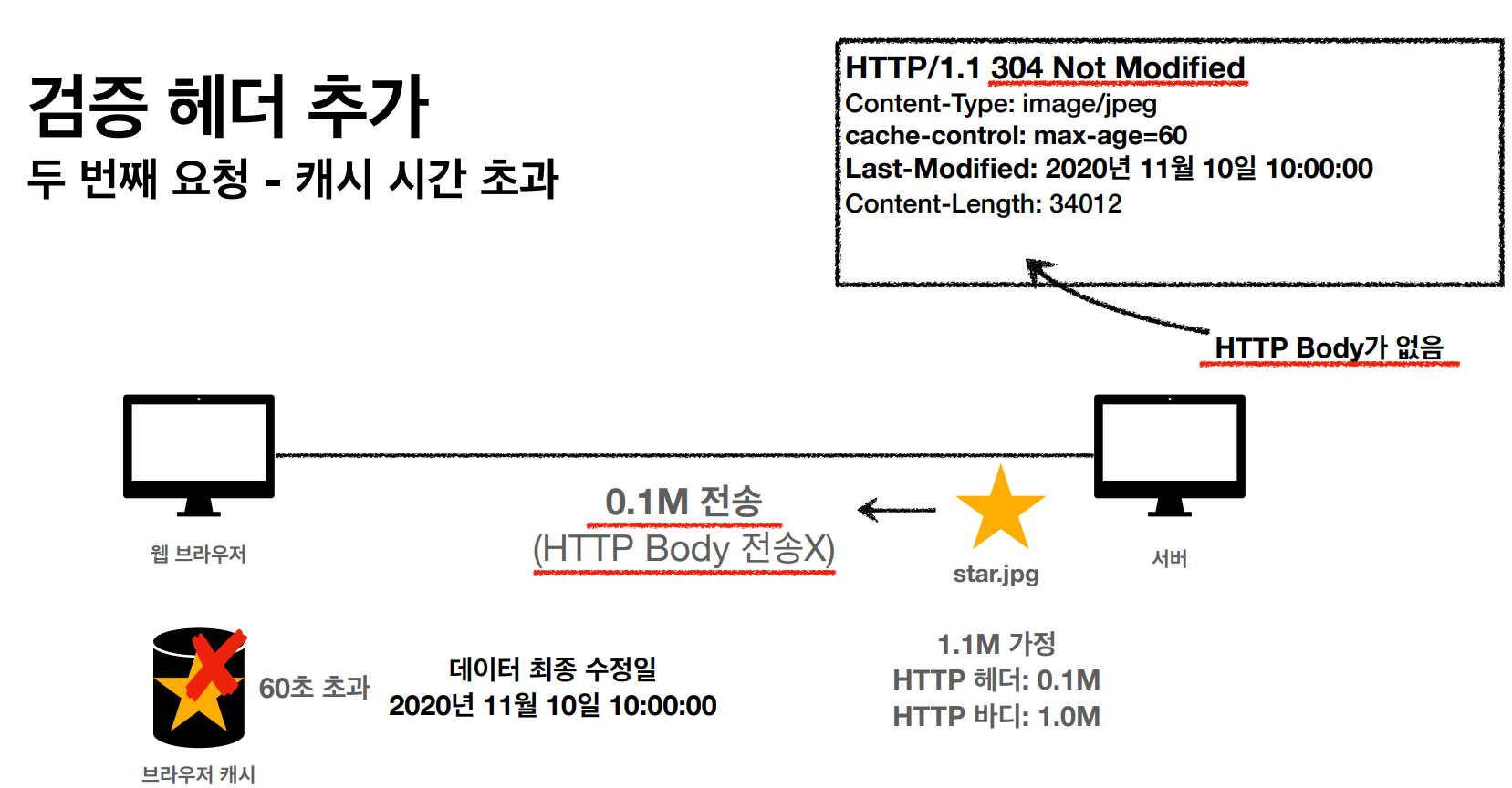
<캐시 시간 초과>
• 캐시 유효 시간이 초과하면, 서버를 통해 데이터를 다시 조회하고, 캐시를 갱신한다.
• 이때 다시 네트워크 다운로드가 발생한다
🤔 검증 헤더 와 조건부 요청
1) 검증 헤더
- 캐시 데이터와 서버 데이터가 같은지 검증하는 데이터
- Last-Modified , ETag
2) 조건부 요청 헤더
- 검증 헤더로 조건에 따른 분기
- If-Modified-Since: Last-Modified 사용
- If-None-Match: ETag 사용
- 조건이 만족하면 200 OK
- 조건이 만족하지 않으면 304 Not Modified
- 진짜 단순하게 ETag는 hash 값 기준으로, 서버에 보내서 같으면 유지, 다르면 다시 받기!
- 캐시 제어 로직을 서버에서 완전히 관리

캐시와 조건부 요청 헤더
• Cache-Control: 캐시 제어
• Pragma: 캐시 제어(하위 호환)
• Expires: 캐시 유효 기간(하위 호환)

프록시 캐시
원서버를 origin이라고 표현하자면, origin server는 리소스 자체가 있는 서버이다.
인터넷 망은 굉장히 복잡한데, 요청을 보내면 여러 서버를 거치게 된다. 미국에 있는 원 서버에서 리소스를 다운받으려먼 시간이 많이 든다. 그렇기에 프록시 캐시 서버(중간 단계 서버)에 리소스를 다운로드 받아두면 사용자는 원 서버 접근보다 빠르게 자료를 받을 수 있다.
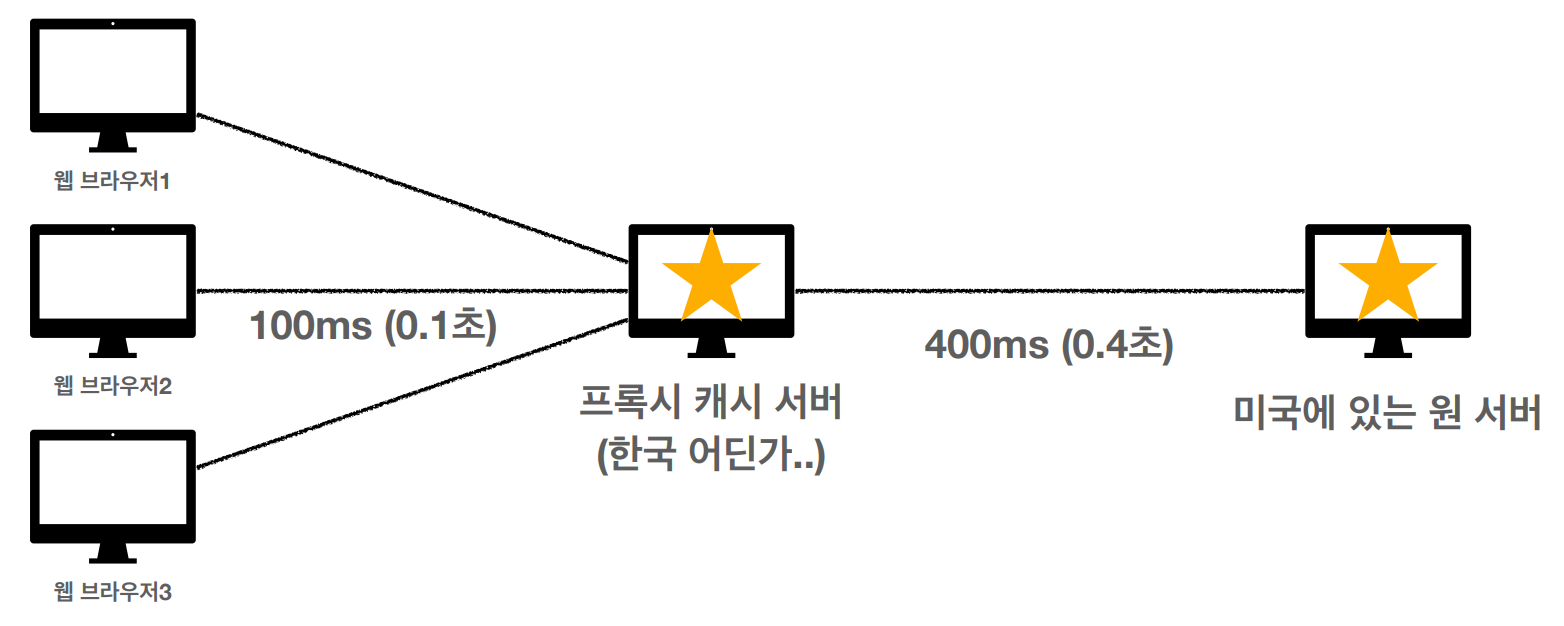
ex) 한국에서 미국 유튜브 영상 보면 다운로드 더 오래 걸림...
캐시 무효화
웹브라우저가 자동으로 cache 생성사는 경우가 있는데, 절대 cache 해서는 안되는 것은 꼭 처리해야함.
1) Cache-Control: no-cache
: 데이터는 캐시해도 되지만, 항상 원 서버에 검증하고 사용(이름에 주의!)
2) Cache-Control: no-store
: 데이터에 민감한 정보가 있으므로 저장하면 안됨
(메모리에서 사용하고 최대한 빨리 삭제)
3) Cache-Control: must-revalidate
: 캐시 만료후 최초 조회시 원 서버에 검증해야함
원 서버 접근 실패시 반드시 오류가 발생해야함 - 504(Gateway Timeout)
must-revalidate는 캐시 유효 시간이라면 캐시를 사용함
🔖 Reference
http 상태 코드 모음 정리 표
