
'TCP/IP 쉽게 더 쉽게' 라는 책을 중심으로 학습 정리한 포스팅입니다. 잘못된 내용이 있다면 언제든 지적해주시면 감사하겠습니다.🙇🏻♀️
라우팅과 인터넷 계층
개요
IP 주소: 수신자의 정보를 표현한다는 점에서는 전화번호 또는 우편번호와 비슷하지만 전화번호, 우편번호 처럼 지역 정보를 포함하지 않고 네트워크 단위로 할당된다.
IP 주소는 지리적인 위치 정보가 포함되어 있지 않으므로 데이터가 전달된 수신지를 찾기 위해서는 라우터를 이용한다. 이 때 라우터는 네트워크간의 연결 정보를 관리한다.
인터넷 계층의 역할
인터넷 계층은 네트워크 인터페이스 계층과 협력해 데이터를 전달하는 역할을 한다. 하드웨어에 해당 하는 부분은 네트워크 인터페이스 계층이 담당하고 인터넷 계층은 IP 주소를 가지고 데이터를 전달할 수 있는 체계를 제공한다.
- 라우터(router): 네트워크와 네트워크를 연결하는 역할.
- 라우팅(routing): 라우터는 데이터를 목적지까지 전달하기 위해 다음 네트워크의 경로를 찾고 그 경로에 있는 라우터에게 데이터 전달을 위임하는데 라우터가 최종 목적지에 대한 경로를 찾게 되는 과정을 라우팅이라고 한다.
IP 주소를 사람이 알아보기 쉬운 도메인명과 연결해주는 DNS가 있다.
IP 주소의 고갈을 방지하기 위한 대안
- private address 와 public address 를 구분하는 기법
- IPv6 도입 (IPv4보다 주소 체계가 확장된 버전)
IPv4와 IPv6
IPv4 (Internet Protocol Version 4)
IPv4는 컴퓨터의 주소를 지정할 때 사용되는 인터넷 계층의 프로토콜. 네트워크에 연결된 컴퓨터를 식별하기 위해 32비트의 IP 주소가 사용된다. 단, 32비트 문자열은 사람이 알아보기 어렵기 때문에 32비트를 8비트씩 4개단위로 끊고 10진수로 변환해 표기한다.
-
IPv4 헤더
위의 IPv4 헤더에서 TTL(Time To Live)는 생존기간을 나타내는 것으로 생존기간을 초과한 패킷은 소멸된다. 이는 수신지로 지정된 컴퓨터가 실제로 존재하지 않거나 통신 경로를 찾지 못해 패킷이 제대로 전달되지 못하는 상황들로 인해 네트워크가 혼잡될 수 있는 상황을 막기 위해 사용된다.
-
MTU (Maximum Transmission Unit)
한번에 전송할 수 있는 데이터 크기. 통신 경로에 따라 해당 값이 변경된다. 경로 상태가 좋지 않으면 MTU 값이 줄어드는데 라우터는 MTU 값에 따라 패킷을 분할해서 전송한다. 다만 라우터의 작업 부하가 높아지거나 분할된 패킷 중의 일부가 유실되면 복원이 어려워진다. 이에 라우터가 데이터를 송신하기 전에 통신 경로 전체의 MTU를 살펴본 후 처음부터 MTU보다 작은 크기의 패킷을 만들도록 설정하기도 한다.
-
Identification, IP Flags, Fragment Offset
데이터를 분할하고 복원하기 위해서 IPv4에 Identification, IP Flags, Fragment Offset 필드가 있다.
Identification은 같은 데이터인지 식별하기 위한 16비트의 값
IP Flags는 분할 허가 플래그와 이후 남은 분할 부분이 더 있는지 위한 표시하기 위한 플래그
Fragment Offset은 원래 데이터에서의 위치 값을 표현하는 13비트의 숫자 값을 의미한다.

IPv6
IPv4의 32비트 주소가 고갈된 상황에 이르자 128비트 주소로 만든 IPv6이 보급되고 있다.
- IPv6 헤더
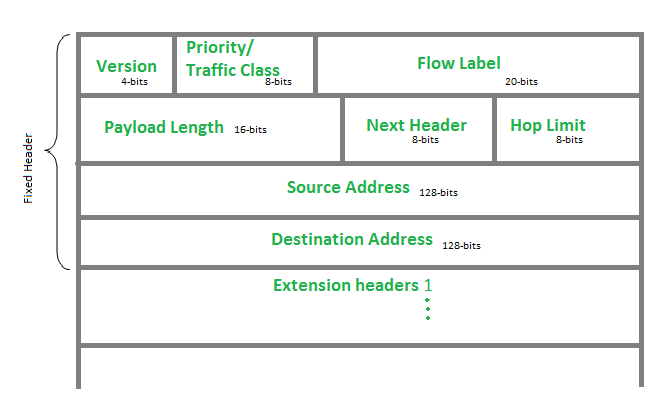 Version (4-bits): Indicates version of Internet Protocol which contains bit sequence 0110 = 6을 나타낸다.
Version (4-bits): Indicates version of Internet Protocol which contains bit sequence 0110 = 6을 나타낸다.
Traffic Class (8-bits): IPv4의 서비스 필드와 비슷하며 패킷의 우선 순위를 결정한다. 패킷의 우선순위는 아래의 그림과 같다.

Payload Length (16-bits): 패킷의 페이로드에 포함되어 있는 정보의 양을 의미한다 → 데이터 부분의 길이를 의미.
Hop Limit (8-bits): 홉 리미트는 IPv4의 TTL과 같다. 생존기간을 나타낸다.
(그 밖의 헤더 항목에 대해서는 https://www.geeksforgeeks.org/internet-protocol-version-6-ipv6-header/ 참고.)
IPv4와 IPv6는 서로 호환이 되지 않아서 두 가지를 병행할 수 있도록 위한 듀얼 스택(dual stack), 터널링(tunneling)과 같은 기술이 있다.
IP 주소
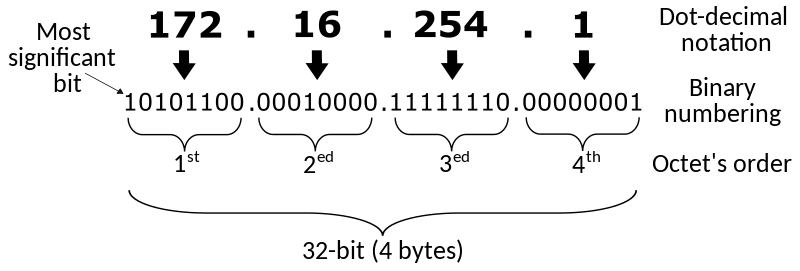
(이미지 출처: 위키백과 - IP주소)
IP 주소는 네트워크 부와 호스트 부로 나누어진다. 여기에서 호스트는 네트워크에 연결된 컴퓨터나 네트워크 장비를 의미한다.
라우터는 IP 주소의 네트워크 부의 정보를 보고 송신할 목적지의 네트워크를 판단한다.
IP주소에서 네트워크 부와 호스트 부를 정하여 결정해 둔 것이 있는데 이를 어드레스 클래스 (Address Class)라고 부른다.
- Address Class

Private IP Address
프라이빗 IP 주소는 가정이나 사내에서 사용하는 주소이다. 인터넷에 연결해도 외부에서 접근할 수 없기 때문에 NAT(Network Address Translation)와 같은 주소 변환 기술을 사용해서 퍼블릭 IP주소로 변환해줘야 한다.
프라이빗 IP 주소로 사용 가능한 범위는 아래와 같다.
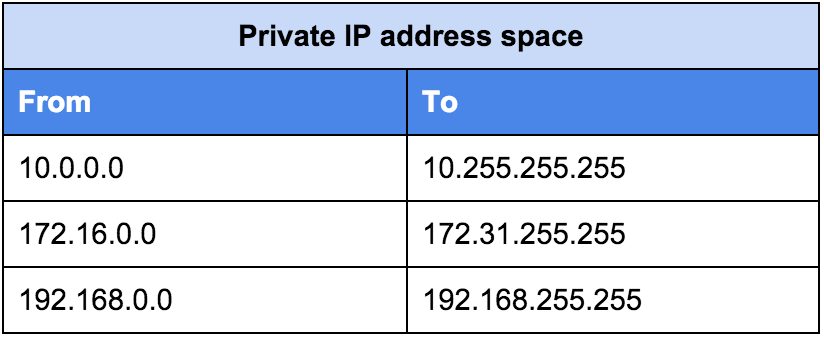
(이미지 출처: https://www.homenethowto.com/ports-and-nat/public-and-private-ip-addresses/)
Public IP Address
퍼블릭 IP 주소는 인터넷 안에서 중복이 되면 안 되기 때문에(만약 중복되어 있다면 데이터를 어디로 보내야 할지 알 수 없다)
ICANN(Internet Corporation for Assigned Names and Numbers)이나 KRNIC(Korea Network Information Center)와 같은 단체(인터넷 레지스트리)가 관리하고 있다.
퍼블릭 IP는 인터넷 레지스트리를 통해 인터넷 서비스 제공자들에게 할당되고 기업이나 가정은 인터넷 서비스가 제공자가 확보한 IP 주소들을 빌려서 쓴다.
서브넷 마스크
우리가 클래스 A(어드레스 클래스에서)의 네트워크를 가지고 있다고 가정한다면, 우리는 약 1600만개의 호스트 어드레스를 가지고 있다는 의미가 된다. 우리는 이 큰 네트워크를 관리해야 하고 네트워크 보안을 신경써야 한다. 이를 위해 큰 네트워크를 작은 네트워크로 나누는 서브네팅(subnetting)이 필요하다.
전체 32비트 중 네트워크 부를 제외한 호스트 부 부분만 서브네팅을 위해 자유롭게 할당하여 사용할 수 있다. 예를 들어 우리가 C클래스 네트워크를 가지고 있고 4개의 서브넷으로 나눈다고 하면 호스트 파트에서 2비트를 선택하면 된다.
서브넷 마스크를 2비트 길이만큼 더 늘려 26비트로 만들면 4개의 서브 네트워크를 만들 수 있다.
라우팅(Routing)
인터넷에서 데이터가 목적지까지 전달되기 위해서 라우터가 자신과 연결된 다른 라우터를 찾아가면서 최종 목적지까지의 경로를 찾는 과정을 라우팅이라고 한다.
라우팅 프로토콜
데이터가 전송될 경로를 찾기 위해 연결 정보를 교환하는데 이 때 라우팅 프로토콜(Routing Protocol)을 사용한다. 대표적인 라우팅 프로토콜로는 BGP, OSPF, RIP 등이 있다.
자율시스템(AS, Autonomous System)
인터넷 서비스 제공자가 사용하는 규모가 큰 네트워크에서는 몇 개의 네트워크를 하나로 묶어서 자율시스템이라는 단위로 관리한다. 네트워크의 경로를 하나하나 찾아다니며 이동하는 것보다 AS 접속 경로 단위로 이동하면 멀리 있는 컴퓨터와도 더 빠른 속도로 통신할 수 있다.
라우터
라우터는 네트워크 간의 패킷을 전달한다.
라우팅 테이블
라우터는 내부에 저장하고 있는 라우팅 테이블이라는 정보를 활용해서 라우팅을 한다. 라우팅 테이블에는 목적지 호스트가 속한 네트워크 정보와 그 네트워크로 도달하기 위해 경유해야 하는 라우터의 정보가 들어 있다.
정적 라우팅과 동적 라우팅
라우팅 테이블을 만드는 방법은 두가지가 있다.
- 정적 라우팅: 네트워크 관리자가 직접 라우팅 테이블을 설정하는 방식
- 동적 라우팅: 라우팅 프로토콜을 사용해 자동적으로 경로 정보를 수집한 후 라우팅 테이블을 설정하는 방식
대부분 동적 라우팅을 사용한다.
라우팅 테이블에 목적지의 정보가 없다면 해당 라우터보다 더 많은 정보를 가지고 있는 기본 라우터 혹은 디폴트(default) 라우터에게 물어보게 된다. 디폴트 라우터 정보는 각 라우터마다 정적으로 설정되어 있다.
동적 라우팅 알고리즘
라우팅 프로토콜에는 경로를 찾는 방식에 따라 크게 거리 벡터형과 링크 상태형의 두가지가 많이 사용된다. 이들 위에 자율 시스템 AS 간의 통신에서 사용되는 경로 벡터형도 있다.
- 거리 벡터형: RIP(Routing Information Protocol) 프로토콜이 사용하는 방식으로 목적지까지의 거리를 살펴보고 짧은 경로를 선택하는 방식이다. 이 때 거리는 경유하는 라우터의 수를 의미하는 hop의 수로 센다. 구성이 간단한 LAN 네트워크에 적합하다.
- 링크 상태형: OSPF(Open Shortest Path First) 프로토콜이 사용하는 방식으로 네트워크의 통신 상태의 정보를 맵(map)으로 관리하며 상태가 가장 좋은 경로를 선택하는 방식이다. 복잡하고 변화가 잦은 네트워크 구성에 적합하다.
AS에서 사용되는 프로토콜
- OSPF: AS 안에서 주로 사용한다. 다만 링크 상태형은 네트워크 규모가 커지면 맵 정보를 처리하는 부하가 커질 수 있어 네트워크를 몇 개의 영역(area)으로 분할한 후 각 영역별로 맵을 따로 만드는 방식을 사용한다.
- BGP(Border Gateway Protocol): AS간에 사용한다. 경로 벡터형은 경로의 거리와 경로 도중에 경유하는 AS 정보도 포함해서 경로 정보를 만든다.
ICMP(Internet Control Message Protocol)
ICMP 프로토콜은 데이터 전송 중에 문제가 생길 경우 장애 상황을 통보하기 위해 사용된다.
ICMP패킷은 IP헤더에 타입이나 코드와 같은 ICMP 메시지를 덧붙인 형태이다.

타입과 코드에 따라서 의미하는 뜻이 달라지게 되는데 아래의 표는 그 일부를 발췌한 것이다.
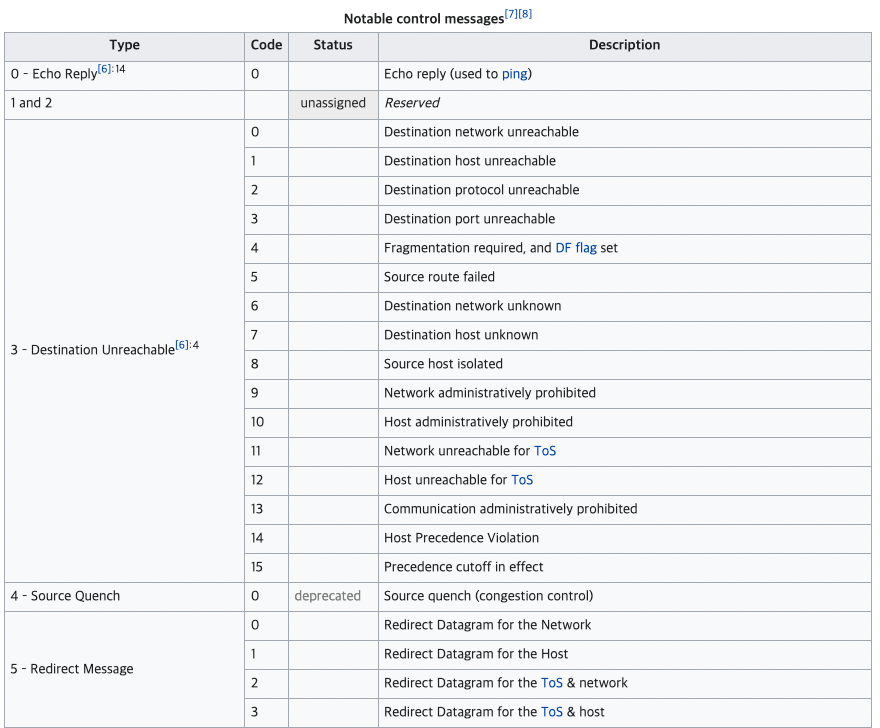
(이미지 출처: https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol)
여러 메시지 중에 타입 10번과 타입 9번 메시지를 사용하면 네트워크에 속한 라우터의 IP 주소를 알 수 있다.
패킷의 TTL이 경과하게 되면 패킷이 소멸되면서 라우터가 패킷을 보낸 송신측으로 타입 11번 메시지를 보내게 된다.
NAT(Network Address Translation)
private IP 주소가 인터넷에 연결된 서버와의 통신을 하기 위해서는 네트워크 어드레스 변환(NAT)이 필요하다. NAT 기술은 private IP 주소와 public IP 주소 변환 외에도 IPv4와 IPv6 간의 변환에도 사용된다.
NAT의 포트번호 충돌을 막기 위해 네트워크 어드레스 포트 변환(NAPT, Network Address Port Translation) 방식이 만들어졌다. NAPT는 IP 주소뿐만 아니라 포트 번호도 함께 변환한다. 내부 네트워크에서 private IP를 사용하는 여러 호스트가 같은 포트 번호를 사용하고 있다면 외부와 통신할 때 포트 번호가 충돌 나지 않도록 변환해서 요청을 보낸 호스트를 구분할 수 있도록 한다.
외부에서 들어오는 요청을 받아야 하는 경우에는 아래와 같은 방법을 사용할 수 있다.
- 메시지의 자동 확인
- 포트 포워딩(Port Forwarding): LAN안에 웹 서버나 FTP 서버를 운영하면서 외부로 서비스를 공개할 때 라우터의 특정 포트 번호로 통신이 들어오면 내부의 특정 서버에 전달되도록 설정하는 방법.
도메인명
컴퓨터를 구분하는 식별자로는 IP 주소와 호스트명이 있는데 이들 정보를 관리하기 위해 DNS(Domain Name System)와 도메인명이라는 것이 생겨났다.
http://www.sample.co.kr 이라는 주소가 있다고 했을 때
호스트명은 www, 도메인명은 sample.co.kr에 해당 한다. 이 둘을 합치면 IP주소가 된다.
도메인명을 조금 더 세부적으로 나눠보자면 아래와 같다.
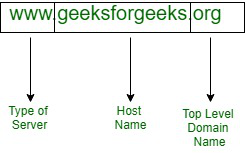
도메인명에 대응하는 IP 주소가 알고 싶다면 DNS 캐시 서버(caching server)에 물어보면 된다. 우리는 터미널에서 nslookup 명령으로 도메인명으로 IP 주소를 알아내거나 IP 주소로 도메인명을 알아낼 수 있다.
계층 구조
도메인에는 계층구조가 있는데 이를 마침표로 구분해 표현한다.
www.sample.co.kr에서 가장 뒤에 나오는 ‘kr’ 같은 도메인이 상위 도메인에 해당하는데 최상위 도메인 또는 탑 레벨 (top level domain)이라고 불린다. 탑 레벨 도메인의 하위 도메인은 2단계 도메인 또는 서브 도메인이라고 부른다.
DNS 또한 계층 구조가 있는데 각 DNS 서버는 도메인 계층 중 일부 영역을 담당하고 그 영역에 속한 도메인명을 관리한다. 도메인명 데이터를 직접 관리하는 DNS 서버를 DNS 콘텐츠 서버라고 부른다.
사용하고 싶은 도메인이 있다면 등록기관에 신청해야만 인터넷에서 사용할 수 있다. 신청한 도메인 명은 DNS 서버에 등록되는데 DNS 서버에 등록되는 정보를 리소스 레코드(Resource Record)라고 하고 리소스 레코드가 등록된 파일을 zone file 이라고 한다.
DHCP (Dynamic Host Configuration Protocol)
IP 주소를 할당하고 중복되지 않게 관리하는 것이 DHCP이다. DHCP를 사용하면 호스트가 네트워크에 연결될 때 IP 주소와 서브넷 마스크 등의 정보가 자동으로 설정된다.
가정용 초고속 인터넷 라우터는 DHCP 서버 기능을 가지고 있어서 컴퓨터를 연결하면 private IP 주소를 할당한다. 공공 장소의 와이파이 역시 DHCP로 IP 주소를 할당하는 방식을 사용한다.
IP 주소를 할당 할 때 신규 호스트는 네트워크의 모든 호스트에게 브로드캐스트 방식으로 DHCP 발견 메시지를 보내고 이 메시지를 받은 DHCP 서버가 사용 가능한 IP주소를 알려주는 방식으로 자동 할당이 이루어진다.
참고
geeksforgeeks.org/internet-protocol-version-6-ipv6-header/
https://ko.wikipedia.org/wiki/IP_주소
https://www.geeksforgeeks.org/introduction-of-classful-ip-addressing/
https://www.geeksforgeeks.org/internet-control-message-protocol-icmp/?ref=gcse
https://www.geeksforgeeks.org/difference-between-domain-name-and-url/?ref=gcse
