1.5기는 필수가 아니라고 했으나.. 1기 백엔드 파트장님의 피드백을 받을 수 있는 기회는 언제든지 잡고 싶어서 ㅎㅎ
1. VM과 컨테이너의 차이가 무엇인가요? (Docker, Python VirtualEnv 는 어디에 속하나요?)
Virtual Machine (가상 머신, VM)
가상머신은 하드웨어 시스템에 소프트웨어로 논리적으로 만들어낸 컴퓨터다. 하나의 물리 자원(컴퓨터)에 하나의 환경(OS)만 있는 것을 효율화하고자 가상화층을 만들고 그 위에 OS를 새로 설치하는 기법이다. 이렇게 하면 하나의 물리적 호스트 머신에 여러 개의 virtual 게스트 머신을 돌릴 수 있다
작동 방식
각 가상머신은 다른 가상머신과는 분리된 각자의 OS와 기능을 갖는다.
가상머신은 물리적 머신의 OS 위에 어플리케이션 윈도우의 프로세스로 실행한다.
용도
- 다른 운영환경을 필요로 하는 소프트웨어를 실행시키기 위해
- 어플리케이션을 안전한 환경에서 테스트하기 위해
- 서버 가상화: 자원을 최대 활용
- 실제 호스트 환경에서 실행하기에는 위험이 큰 경우
장점
- 관리/유지보수가 쉽다
- 하나의 물리적 머신에 여러 개의 OS 환경을 사용할 수 있다
- 물리적 공간, 시간, 그리고 관리 장점
- 오래된 어플리케이션 또한 실행 가능하다: 굳이 새로운 OS로 이전할 필요 없음
- 문제 발생시 복구 용이
단점
- 하나의 물리적 머신에 여러 개의 가상머신을 돌리면 안정적이지 못할 수 있다
- 가상머신은 물리적 컴퓨터를 사용하는 것보다 덜 효율적이고 느리다
가상머신 종류 (1) 프로세스 가상 머신
Process virtual machine: 프로세스 가상머신
하나의 호스트 머신에 하나의 프로세스를 실행한다
- platform-independent programming environment
- 하드웨어/OS의 정보를 마스킹해 호스트머신과 독립적인 프로그래밍 환경을 구성한다
- (ex) Java Virtual Machine (JVM): OS와 무관하게 자바 어플리케이션을 실행하도록
가상머신 종류 (2) 시스템 가상머신
System virtual machine: 시스템 가상머신
- 물리적 머신을 대체하기 위해 완전히 가상화됨
- 호스트 컴퓨터의 물리적 자원을 여러 가상머신에 걸쳐 나누는 것을 가능케 지원함
- 각 가강머신은 OS를 각자 복제하여 사용
- 하이퍼바이저 또는 OS 위에 작동
하이퍼바이저
Hypervisor, virtual machine monitor (VMM): 가상머신을 만들고 실행시키는 소프트웨어
- 하나의 호스트 컴퓨터가 여러 게스트 가상머신을 실행시킬 수 있도록 컴퓨터의 자원(메모리, 프로세싱 등)을 공유한다
- 장점:
- 속도: 하이퍼바이저로 매우 빠르게 가상머신을 만들 수 있다
- 효율성: 여러 가상머신을 실행하는 하이퍼바이저는 하나의 물리적 서버를 가격과 자원 면에서 더 효율적으로 사용할 수 있다
- 유연성: 하이퍼바이저는 OS와 하드웨어를 분리시키기 때문에 OS와 그의 어플리케이션이 다양한 하드웨어 위에서 실행될 수 있도록 한다
- 휴대성: 하이퍼바이저로 여러 OS가 하나의 물리적 서버에 독립적으로 존재하기 때문에 가상머신을 이전하거나 플랫폼을 이전하기에 용이하다
- 작동 방식
- 컴퓨터의 하드웨어로부터 소프트웨어를 추출/추상화하여 가상머신을 만든다
- 물리적 자원과 가상 자원 간 요청을 바꾸는 역할을 한다
추상화하다: 복잡한 특성은 백그라운드에 숨기고, 필요한 것들만 보이도록 하는 과정이다
가상화 종류 (1) 하드웨어 가상화
하드웨어/서버 가상화
하드웨어 가상화의 경우에는 컴퓨터와 OS가 가상화되어 하나의 메인 물리적 서버로 통합된다. 하이퍼바이저는 가상머신을 관리하기 위해 물리적 서버의 디스크공간과 CPU와 직접 소통한다.
하드웨어 가상화를 통해 하드웨어 자원을 더 효율적으로 사용하고, 하나의 물리적 머신이 동시에 여러 OS를 실행시킬 수 있다.
가상화 종류 (2) 소프트웨어 가상화
소프트웨어 가상화는 하나의 물리적 호스트 머신에 하나 이상의 게스트 OS가 돌아갈 수 있는 컴퓨터 시스템을 만든다
(예) 안드로이드 OS는 마이크로소프트 윈도우 OS를 사용하는 호스트 머신에 실행될 수 있다.
가상화 종류 (3) 스토리지 가상화
여러 물리적 스토리지 장치가 하나의 스토리지 장치처럼 쓰이게끔 스토리지를 가상화할 수 있다.
장점: 퍼포먼스 및 속도 최적화, 로드 밸런싱, 싼 가격, 복구
가상화 종류 (4) 네트워크 가상화
여러 서브네트워크를 합쳐서 하나의 소프트웨어 기반 가상네트우워크 자원을 만들면 하나의 물리적 네트워크로 사용할 수 있다.
- 사용 가능 대역폭을 여러 독립적 채널로 나눠 각각 서버 및 장치에 실시간으로 배치할 수 있다
- increased reliability, network speed, security, better monitoring of data usage
가상화 종류 (5) 데스크탑 가상화
데스크탑 가상화는 데스크탑 환경을 물리적 장치와 분리하여 데스크탑을 원격 서버에 저장한다. 이 과정을 통해 사용자는 어느 곳에서나 자신의 데스크탑에 접속할 수 있다
- easy accessibility, better data security, cost savings on software licenses, easy management
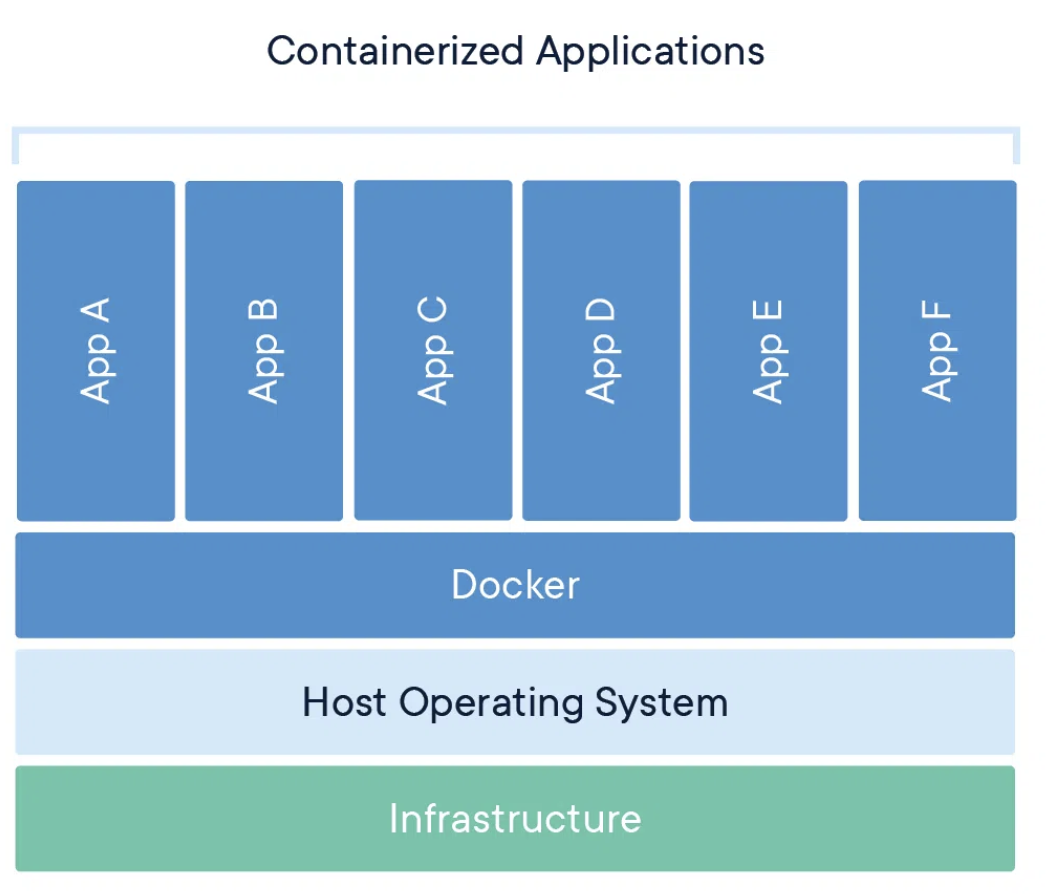
Container
컨테이너는 소프트웨어의 표준단위로, 어플리케이션이 컴퓨팅환경에서 쉽게 실행될 수 있도록 그 코드와 의존성을 패키징한다.
도커 컨테이너 이미지는 가볍고, 독립적이며, 실행 가능한 소프트웨어 패키지다.
작동 방식
컨테이너 이미지는 런타임에 컨테이너가 되어
장점
Container vs. Hypervisor
컨테이너와 하이퍼바이저 모두 애플리케이션 최적화에 기여하지만, 기여하는 방식이 다르다
Hypervisor:
- VM을 사용하여 OS가 하드웨어와는 독립적으로 실행된다
- 가상 컴퓨팅, 스토리지 및 메모리 자원을 공유한다
- 하나의 서버 위에 여러 OS를 실행시킬 수 있다
Containers:
- 어플리케이션이 OS와는 독립적으로 실행된다
- 컨테이너 엔진이 있는 이상 모든 OS에 실행될 수 있다
- 하나의 컨테이너가 애플리케이션을 실행시키는데 필요한 모든 것을 갖기 때문에 휴대성이 매우 높다
결론
- 하이퍼바이저는 가상머신을 만들고 실행시키는데 쓰인다
- 컨테이너는 앱과 그 서비스를 패키징한다
Virtual Machine vs. Container
가상머신은 하드웨어를 가상화하여 컴퓨터를 만드는 반면에, 컨테이너는 하나의 앱과 그의 의존성을 패키징할 뿐이다.
가상머신은 하이퍼바이저에 의해 주로 관리되지만, 컨테이너 시스템은 호스트에서 공유되는 OS 서비스를 사용하여 가상메모리 하드웨어로 애플리케이션을 고립시킨다.
VM
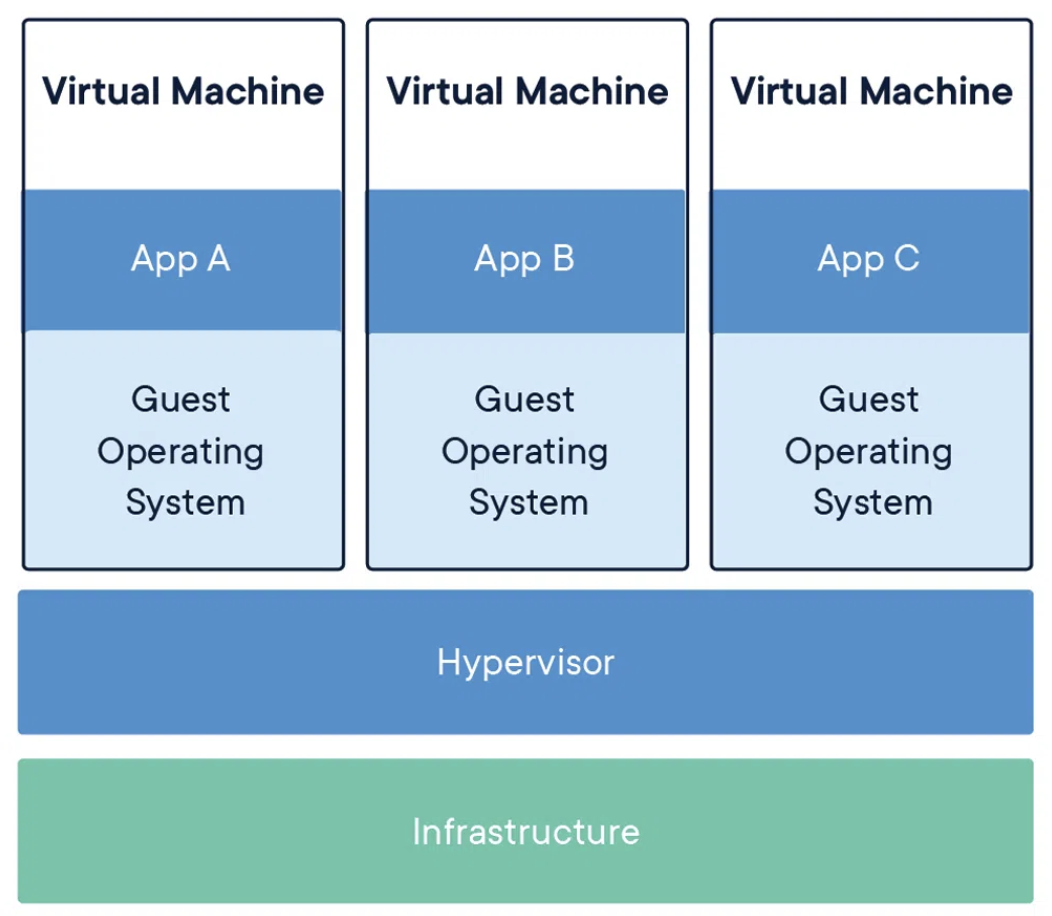
- larger
- slower to boot
- logically isolated from one another
- separate OS kernel
- benefits of a completely separate operating system
- best for running multiple apps together
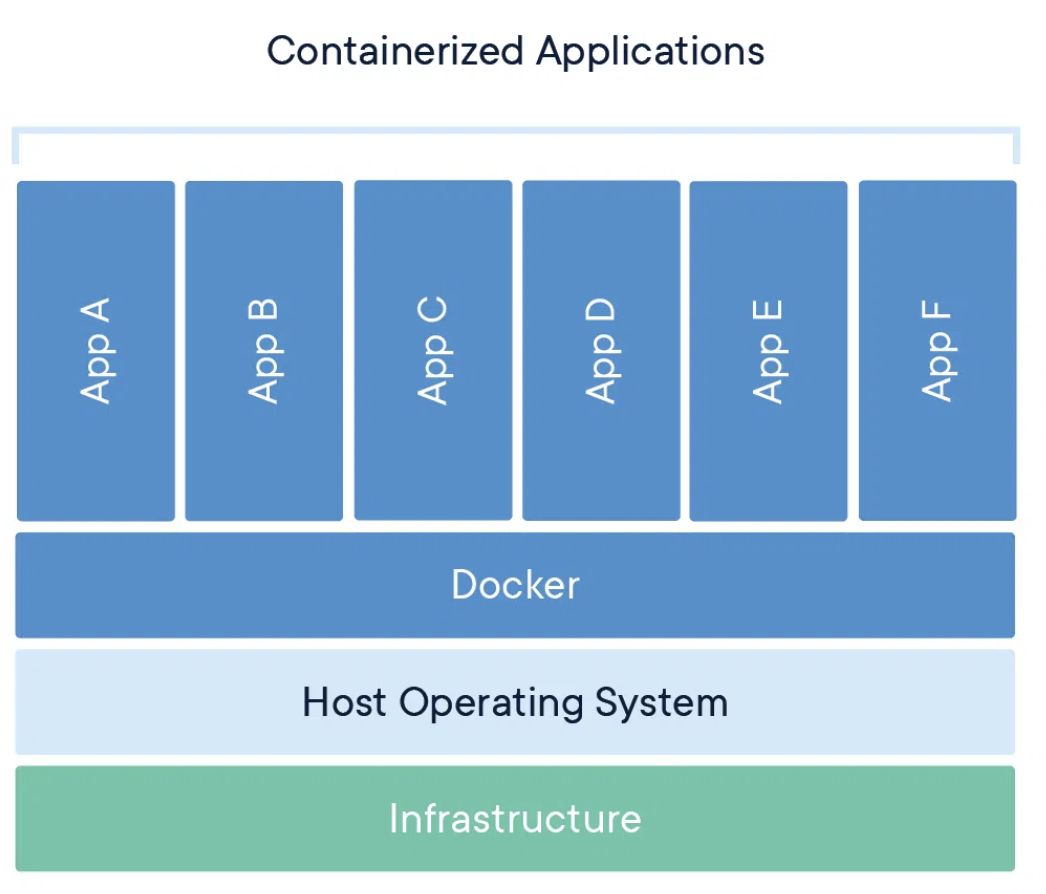
Container
- less overhead compared to VM
- 컨테이너는 application, binaries, libraries, dependencies만 포함한다
- boot faster
- maximize server resources
- delivering applications easier
2. 토큰 기반 인증과 세션 기반 인증을 비교해주세요. 본인이라면 어떤 방식을 사용할 것 같나요?
토큰 및 세션 기반 인증은 서버가 인증된 유저로부터의 요청을 받도록 하는 방법이다. 세션 기반 인증은 주로 웹 애플리케이션에 사용되는 반면에, 서버 간 연결에서는 토큰 기반 인증이 선호된다.
토큰 기반 인증
토큰
- 함부로 변경할 수 없는 허가 파일
- 서버가 비밀키를 사용해 생성하여 사용자에게 보내면, 사용자가 로컬 스토리지에 저장한다
작동 과정
- 사용자가 서버에 로그인 요청을 보낸다
- 서버가 로그인을 허가하고 사용자에게 토큰을 전송한다
- 사용자가 토큰을 포함한 새 요청을 보낸다
- 서버가 토큰이 유효한지 확인하고, 유효한 경우에 사용자에게 요청한 페이지를 전송한다
장점
- 사용자가 자격증명 횟수를 줄이고 싶을 때
- 서버간 연결은 자격증명이 어려워서 토큰 사용이 적합하다
- 토큰을 사용하는 서버는 세션ID를 확인할 필요 없으니 더 좋은 성능을 낼 수 있다
단점
- 인증 정보가 클라이언트에 저장되어 있어 세션에서는 가능한 보안 작업이 어렵다
- 공격자가 유효한 토큰을 가로채면 서버 데이터베이스에 무제한의 접근이 가능할 수도 있다
세션 기반 인증
세션
- JSON 포맷 등의 작은 파일
- 사용자의 정보(아이디, 로그인 시간, 로그인 만료시간 등)를 저장한다
- 서버에서 생성되고 저장된다
- 서버가 사용자의 요청을 기록한다
- 사용자는 매 요청에 보낼 쿠키로 쓰일 세션의 정보를 받는다
- 서버는 이 쿠키를 인식해 사용자의 요청을 허용한다
과정
- 사용자가 서버에 로그인 요청을 보낸다
- 서버가 로그인 요청을 인증한다 > 데이터베이스에 세션을 보낸다 > 사용자에게 세션ID를 담은 쿠키를 보낸다
- 사용자가 쿠키를 포함한 새 요청을 보낸다
- 서버는 데이터베이스에 쿠키의 ID가 있는지 확인하고, 확인되는 경우에는 요청된 페이지를 전송한다
장점
- 세션이 서버에 저장되기 때문에 서버관리자가 세션을 관리할 수 있다
- 계정이 해킹된 경우에 세션ID를 처리하면 보안 문제 해결 가능
단점
- 서버가 세션ID 존재 여부를 확인해야 하기 때문에 scalability 문제가 존재한다
- 쿠키가 cross-site request forgery 공격에 노출될 수 있다
- 이를 이용해 공격자는 사용자를 악성웹사이트로 보낼 수 있다
- Man-in-the middle 공격에 취약하다
토큰 vs. 세션 기반 인증
| 기준 | 세션 인증 | 토큰 인증 | |
|---|---|---|---|
| 1 | 인증정보가 저장되는 곳 | 서버 | 사용자 |
| 2 | 요청 허가를 받기 위해 사용자가 서버에 보내는 것 | 쿠키 | 토큰 |
| 3 | 서버가 사용자의 요청을 허가하는 방법 | 사용자가 쿠키와 보낸 ID로 데이터베이스에서 유효한 세션인지 확인 | 사용자의 토큰을 해독하여 확인한다 |
| 4 | 서버관리자가 보안 작업을 처리할 수 있나 | 가능. 세션이 서버에 저장돼서 | 불가능. 토큰이 클라이언트에 저장됨 |
| 5 | 어느 공격에 취약한가 | man-in-the-middle, cross-site request forgery | man-in-the-middle, token steal, breaches of secret key |
| 6 | 적합한 용도 | 사용자-서버 연결 | 서버간 연결 |
3. 동기와 비동기, 블로킹과 논블로킹의 차이에 대해 설명해주세요. 또한, 각각을 사용한 예시 또한 설명해주세요.
동기와 비동기
동기와 비동기는 호출되는 함수의 작업 완료 여부를 신경쓰는지에 의해 결정된다
동기는 함수 A가 함수 B를 호출한 뒤, 함수 B의 리턴값을 계속 확인한다.
비동기는 함수 A가 함수 B를 호출할 때 콜백 함수를 함께 전달해서, 함수 B의 작업이 완료되면 함께 보낸 콜백 함수를 실행하기 때문에 작업 완료 여부를 계속 확인할 필요는 없다
동기 (Synchronous transmission)
- 데이터가 블록/프레임 단위로 전송된다
- 직렬적으로 작업을 처리한다
- 요청이 들어오면 순차적으로 작업을 수행하고, 해당 작업이 수행 중이면 다음 작업은 대기한다
- 한 번에 많은 요청이 들어오고, 동시에 많은 요청을 처리해야 하는 서버와는 맞지 않다
- (예) 채팅방, 전화, 화상전화
비동기 (Asynchronous transmission)
- 이전 요청에 의한 작업이 끝나지 않았어도 계속해서 요청을 받는다
- 작업이 끝났다는 이벤트가 오면 이후 요청을 처리한다
- 네트워크 관리에 최적화된 모델이다
- (예) 이메일, 포럼
블로킹과 논블로킹
함수 A가 함수 B를 호출했을 때 제어권을 어떻게 처리하느냐의 문제다
제어권: 자신의 코드를 실행할 권리
블로킹 (Blocking)
블로킹은 함수 A가 함수 B를 호출하면 A가 B에게 제어권을 넘겨준다.
- 함수 A가 함수 B를 호출하면서 B에게 제어권을 넘긴다
- 제어권을 넘겨받은 B는 함수를 실행한다. A는 B에게 제어권을 넘겨줬기 때문에 함수 실행이 정지된다
- 함수 B는 실행이 끝나면 자신을 호출한 A에게 제어권을 돌려준다
논블로킹 (Non-blocking)
함수 A가 함수 B를 호출해도 제어권은 A가 갖고 있는다
- 함수 A가 함수 B를 호출하면 함수 B가 실행되어도 함수 A가 제어권을 가진다
- 함수 A가 제어권을 계속 가져서 함수 B가 실행되는 동안에도 A는 자신의 코드를 계속 실행한다
Implementations
동기-블로킹 (Sync-blocking)
동기라서 함수 A는 함수 B의 리턴값을 필요로 한다
그래서 제어권을 함수 B에게 넘겨주고, 함수 B가 실행완료하여 리턴값과 제어권을 돌려줄 때까지 기다린다 (blocking)
동기-논블로킹 (Sync-Nonblocking)
함수 A는 함수 B를 호출할 때 제어권을 주지 않고 자신의 코드를 계속 실행함 (논블로킹)
그런데 함수 B의 리턴값이 필요하기 때문에 중간중간 함수 B에게 함수 실행을 완료했는지 물어봄 (동기)
비동기-논블로킹 (Async-Nonblocking)
함수 A가 함수 B를 호출할 때 제어권을 주지 않고 자신의 코드를 계속 실행함 (논블로킹)
함수 B를 호출할 때 콜백 함수를 함께 줘서 함수 B는 자신의 작업이 끝나면 콜백함수를 실행함 (비동기)
비동기-블로킹 (Async-blocking)
함수 A는 함수 B의 리턴값에 신경쓰지 않고 콜백함수를 보냄 (비동기)
함수 A는 함수 B의 작업에 관심이 없지만 제어권을 넘기기 때문에 (블로킹) 자신과 관련없는 함수 B의 작업이 끝날 때까지 기다려야 함
4. ORM이 무엇인가요? 단점은 없을까요?
Object Relational Mapping (ORM): 객체-관계 맵핑
객체와 관계형 데이터베이스의 데이터를 자동으로 매핑한다. 객체지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용해서 객체 모델과 관계형 모델 간에 불일치가 존재한다. ORM을 통해 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결한다
데이터베이스 데이터 <-- 맵핑 --> Object 필드
ORM의 장점
- 객체지향적인 코드로 더 직관적이다
- ORM으로는 SQL쿼리가 아닌 메서드로 데이터를 조작할 수 있다
- 선언문/할당/종료 등 부수적인 코드가 많이 줄어든다
- 코드의 가독성 증가
- 재사용 및 유지보수가 편리하다
- 객체들이 독립적으로 작성되고, 해당 객체들을 재활용할 수 있다
- DBMS에 대한 종속성이 줄어든다
- 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하기 때문에 RDBMS의 데이터 구조와 객체지향 모델 간의 가격을 좁힐 수 있다
ORM의 단점
- 완벽한 ORM으로만 서비스를 구현하기 어렵다
- 프로젝트의 복잡성이 증가하면 구현하기 더 어려워진다
- 잘못 구현된 경우에는 속도 저하 가능성
- 프로시저가 많은 시스템은 ORM의 객체지향적인 장점을 활용하기 어렵다
Java Persistence API (JPA)
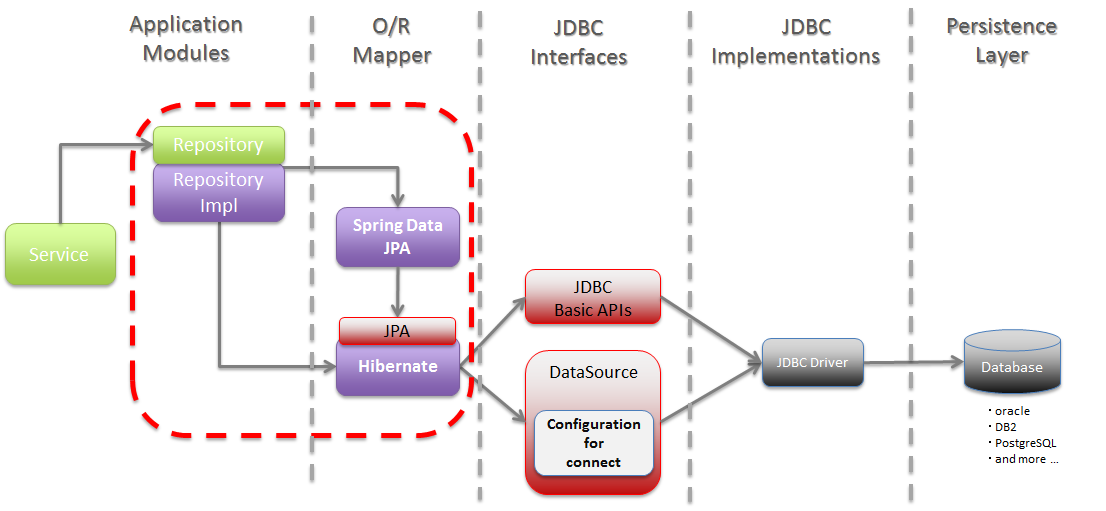
- 자바 ORM 기술에 대한 표준 명세
- Java에서 제공하는 API
- 자바 어플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스
- 라이브러리는 아님
- 자바 클래스와 DB테이블을 맵핑한다
- SQL을 맵핑하지는 않는다
5. RDB와 NoSQL의 차이가 무엇인가요? 왜 각자 그런 형태를 선택했을까요?
Database는 컴퓨터 시스템에 전자 방식으로 저장된 구조화된 정보 또는 데이터의 체계적인 집합을 의미한다.
DBMS (Database Management System)는 사용자와 데이터베이스 사이에서 사용자의 요구에 따라 정보를 생성해주고 데이터베이스를 관리해주는 소프트웨어다.
SQL (Structured Query Language)는 RDBMS의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어로, RDBMS에서 자료의 검색과 관리, 디비 스키마 생성과 수정, 데이터베이스 객체 접근 조정 관리를 위해 고안되었다.
Relational Database
관계형 데이터베이스로, 각 엔티티가 테이블이고, 각 테이블이 관계를 맺어 집합체가 된다. 관계는 외래키로 표현한다.
RDB 장점
- 정해진 스키마에 따라 데이터를 저장해서 명확한 데이터 구조를 보장한다
- 각 데이터를 중복없이 한번만 저장한다
RDB 단점
- 테이블간 관계를 맺고 있어
NoSQL (Not only SQL)
관계형 데이터베이스가 아닌 다른 형태의 데이터저장 기술. 테이블 간 관계를 정의하지 않고, 일반적으로 테이블간 join도 불가능하다
RDBMS의 단점인 성능을 향상시키기 위해서는 Scale-up이 필요한데, 이를 위해서는 비용을 많이 들여 장비를 업그레이드해야 한다. 하지만 데이터 일관성을 보장한다는 장점이 있다.
빅데이터의 등장으로 인해 데이터와 트래픽이 기하급수적으로 증가함에 따라 비용이 큰 Scale-up이 필요한 RDBMS와 그의 데이터 일관성을 포기하고, 여러 대의 데이터에 분산하여 저장하는 Scale-out을 목표로 등장한게 NoSQL이다.
NoSQL은 다양한 형태의 저장 기술을 지원하고, RDBMS 스키마에 맞춰 데이터를 관리해야 한다는 한계를 극복하며, 수평성 확장성을 보장한다.
CAP
분산형 구조는 일관성(Consistency), 가용성(Availability), 분산 허용(Partitioning Tolerance) 3가지 특징을 가지고 있는데, 이 중 2가지만 만족할 수 있다고 한다
- 일관성(Consistency): 분산된 노드 중 어느 노드로 접근하더라도 데이터 값이 같다
- 가용성(Availability): 클러스터링된 노드 중 하나 이상의 노드가 실패라도 정상적으로 요청 처리가 되는 기능을 제공한다
- 분산 허용(Partition Tolerance): 클러스터링 노드 간에 통신하는 네트워크가 장애가 나더라도 정상적으로 서비스를 수행한다. 노드 간 물리적으로 전혀 다른 네트워크 공간에 위치도 가능하다.
일반적으로 NoSQL은 가용성과 분산허용을 만족하는 것과 일관성과 분산허용을 만족하는 것으로 나뉜다.
- C+P형: 대용량 분산파일시스템으로 성능이 보장된다
- A+P형: 비동기식 서비스, SNS 서비스
NoSQL 특징
- UPDATE/DELETE를 잘 사용하지 않는다
- Insert으로 대체
- 강한 consistency를 요구하지 않는다
- 노드의 추가/삭제 및 데이터 분산에 유연하다
- 모델링이 유연하다
- 쿼리가 유연하다
NoSQL 장점
- 스키마가 없어서 유연하고 자유로운 데이터 구조
- 데이터 분산이 용이하다
- scale-up & scale-out 가능하다
NoSQL 단점
- 데이터 중복 발생할 수 있다
- 데이터 무결성과 정합성이 보장되지 않는다
- 중복된 데이터가 변경되면 수정을 모든 컬렉션에서 수행해야 한다
- 스키마가 없어서 명확한 데이터구조를 보장할 수 없다
6. DB의 인덱스의 개념에 대해 설명해주세요.
7. DB의 트랜잭션과, ACID 원칙에 대해 설명하고, Lock에 대해 설명해주세요.
Transaction: 데이터베이스의 상태를 변화시키기 위해 수행하는 작업의 단위
ACID 원칙
Atomicity
원자성: 트랜잭션이 데이터베이스에 모두 반영되거나, 전혀 반영되지 않아야 한다.
트랜잭션 도중에 서버가 다운되는 등에 사건이 발생하면 트랜잭션은 전혀 반영되지 않은 상태여야 한다.
DBMS는 이전에 커밋된 상태를 임시 영역에 따로 저장하고, 현재 수행하고 있는 트랜잭션에 의해 변경된 내역을 유지한다. 현재 수행하고 있는 트랜잭션에서 오류가 발생하면 현재 변경 내역을 날리고, 임시 영역에 저장했던 상태로 롤백한다.
Rollback segment: 이전 데이터를 임시로 저장하는 영역
데이터베이스 테이블: 현재 수행하고 있는 트랜잭션에 의해 새롭게 변경되는 내역
트랜잭션의 원자성은 롤백 세그먼트에 의해 보장된다
트랜잭션의 길이가 길 때는 오류가 발생해서 처음부터 작업을 수행하는 것을 방지하기 위해 확실한 부분에 대해서는 롤백이 되지 않도록 중간 저장 지점인 save point를 지정할 수 있다.
이러한 과정을 UNDO 연산이라 부른다. UNDO 연산은 트랜잭션이 정상적으로 종료될 수 없게 되면 트랜잭션이 변경한 페이지들을 원상 복구시킨다.
DBMS는 두 개의 버퍼 관리 정책 중 골라 UNDO를 수행할 수 있는데, STEAL 정책으로 수정된 페이즈를 언제든지 디스크에 쓸 수도 있고, ¬STEAL를 통해 수정된 페이즈들을 최소한 트랜잭션 종료 시점까지는 버퍼에 유지할 수도 있다. 거의 모든 DBMS는 STEAL 정책을 채택해 사용하고, 이는 필연적으로 UNDO 로깅과 복구 작업을 수반한다. ¬Steal 정책은 매우 큰 크기의 메모리 버퍼를 필요로 한다는 단점이 있다.
Consistency (일관성)
일관성: 트랜잭션이 진행되는 동안에 데이터베이스가 변경되더라도 처음에 참조한 데이터베이스로 트랜잭션을 수행한다. 업데이트된 데이터베이스는 사용하지 않는다.
그래서 사용자는 일관성있는 데이터를 볼 수 있다.
DBMS는 트랜잭션 전 후에 데이터 모델의 모든 제약 조건을 만족 시켜 일관성을 보장한다.
Isolation
둘 이상의 트랜잭션이 동시에 실행되고 있는 경우, 각각 다른 트랜잭션의 연산에 끼어들 수 없다. 이 트랜잭션이 완료될 때까지 다른 트랜잭션은 이 트랜잭션의 결과를 참조할 수 없다.
병행 처리(concurrent processing)의 경우에 공통된 데이터의 조작 때문에 데이터가 혼란스러워질 수 있어서 독립성 보장이 필수적이다. Lock과 Unlock을 통해 데이터의 고립성을 보장한다.
- 트랜잭션에서 데이터를 읽을 때에는 여러 트랜잭션이 읽을 수는 있지만 쓸 수는 없는
shared_lock을 사용한다. - 트랜잭션에서 데이터를 쓸 때는 다른 트랜잭션이 읽을 수도 쓸 수도 없게 하는
exclusive_lock을 사용한다. - 트랜잭션의 읽기/쓰기 작업이 끝나면 unlock을 통해 다른 트랜잭션이 lock을 할 수 있도록 데이터에 대한 잠금을 푼다
Lock을 사용하면 데드락이 발생할 수도 있어서 2PL 프로토콜(2 Phase Locking Protocol)을 통해 여러 트랜잭션이 공유하고 있는 데이터에 동시 접근할 수 없도록 한다.
2PL 프로토콜(2 Phase Locking Protocol)
2PL 프로토콜은 두 개의 상태 (growing phase와 shrinking phase)가 가능하다.
- Growing phase에서는 read_lock, write_lock이 일어난다
- Shrinking phase에서는 unlock이 일어난다
이 때 2PL 프로토콜은 growing phase와 shrinking phase가 섞이면 안된다고 정의한다. Lock이 다 일어난 후에 unlock이 모두 수행되어야 한다.
Durability
지속성: 트랜잭션이 성공적으로 완료됐을 경우, 결과는 영구적으로 반영되어야 한다
트랜잭션이 성공적으로 수행되었다면, 런타임 오류나 시스템 오류가 발생하더라도 해당 기록은 영구적이여야 한다.
8. 동시성과 병렬성의 차이가 무엇인가요? 멀티코어 프로그래밍 관점에서 설명해주세요.
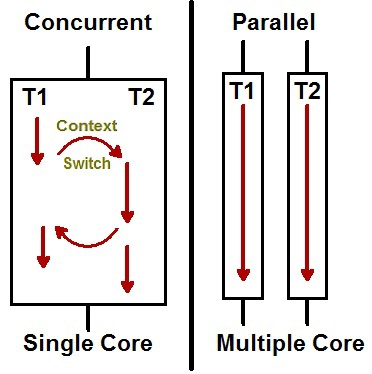
| 동시성 | 병렬성 |
|---|---|
| 동시에 실행되는 것 같이 보이는 것 | 실제로 동시에 여러 작업이 처리되는 것 |
| 싱글 코어에서 멀티스레드를 동작시킨다 | 멀티코어에서 멀티스레드를 동작시킨다 |
| 논리적인 개념 | 물리적인 개념 |
9. 테스트 코드란 무엇이고, Unit Test와 Integration Test에 대해서 설명해주세요.
테스트 코드
내가 작성한 코드가 목적에 맞게, 여러 상황에서도 잘 수행되는지 확인하는 과정이다
테스트 코드의 존재 이유
- 디버깅 비용 절감
- 코드 변경에 대한 불안감 해소
- 문서화가 용이하다
- 좋은 코드는 테스트하기 쉽다
Unit Test
유닛 테스트는 도메인 모델과 비즈니스 로직을 테스트한다
작은 단위의 코드 및 알고리즘 테스트
Integration test
integration test는 코드의 주요 흐름을 통합적으로 테스트하며, 주요 외부 의존성에 대해서 테스트한다
테스트 코드는 어떻게 작성해야 할까
1. 테스트코드는 DRY보다는 DAMP하게 작성하라
DRY: Don't repeat yourself
DAMP: Descriptive and Meaningful Phrases
의미있고 설명적인 구문을 사용하라
2. 테스트는 구현이 아닌 결과를 검증하라
3. 읽기 좋은 테스트를 작성하라
10. CI/CD란 무엇인가요?
CI/CD는 앱개발 단계에 자동화를 도입하여 자주 어플리케이션을 내놓는 방식이다.

Continuous Integration
Continuous integration는 개발자를 위한 자동화 과정으로, 새 코드가 정기적으로 빌딩, 테스팅, 그리고 머지됨을 뜻한다.
개발 단계에서 충돌 가능성이 존재하는 여러 브랜치를 갖는 앱에 유용하다
CI 과정
- push to the code repository
- static analysis: 코드를 실행시키기 전에 버그, 포맷팅, 스타일링 등을 확인한다
- pre-deployment testing
- packaging & deployment to test environment
- post-deployment testing
Continuous Delivery/Deployment
Continuous delivery: 코드가 자동으로 버그 테스팅 되어 레포지토리에 업로드된다.
Continuous deployment: 코드가 레포지토리에서 프로덕션으로 자동 release 된다
11. TCP와 UDP의 차이에 대해 설명해주세요.
TCP와 UDP는 7계층 중 전송 계층에서 사용되는 프로토콜이다. 프로세스간의 전송기술을 다룬다.

Transmission Control Protocol
- 연결형 서비스: 연결할 때는 3-way handshake, 해제할 때는 4-way handshake
- connection-oriented
- stream-oriented
- 가상회선 방식으로 패킷을 교환한다
- 전송 순서가 보장된다
- 수신 여부를 확인한다
- 1:1 통신
- 신뢰성이 높다
- 속도는 느리다
- 혼잡도 제어 가능
TCP 헤더
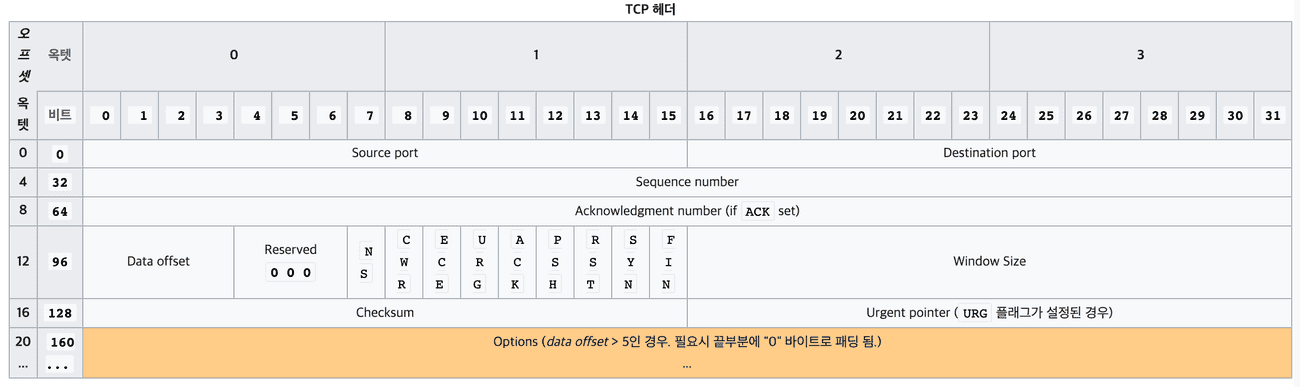
TCP 헤더는 목적지 정보, sequence number, acknowledgement number, control fields 등의 정보를 포함한다
3-way handshake
- 클라이언트가 연결하고 싶다는 SYN플래그를 보낸다
- 서버가 SYN-ACK으로 클라이언트 요청에 응답한다
- 클라이언트가 ACK로 서버의 응답을 인정한다
4-way handshake
4-way handshake: TCP의 연결 세션을 종료하기 위해 수행되는 절차
- 클라이언트가 연결을 종료하겠다는 FIN플래그를 전송한다
- 서버는 일단 확인메시지를 보내고 자신의 통신이 끝날때까지 기다린다. TIME_WAIT 상태가 된다
- 서버가 통신이 끝나면 연결이 종료되었다고 클라이언트에게 FIN플래그를 전송한다
- 클라이언트는 수신 후 확인했다는 메시지를 보낸다
User Datagram Protocol
- 비연결형 서비스: connectionless
- 데이터그램으로 패킷을 교환한다
- 전송 순서가 바뀔 수 있다 (보장되지 않는다)
- 수신 여부를 확인하지 않는다
- 1:1 or 1:N or N:N 통신
- 신뢰성은 낮다
- 속도는 빠르다
데이터그램

데이터그램: 사용자가 전달하고자하는 데이터를 네트워크로 전송하기 위해 통신 정보 등을 담은 헤더를 씌운 독립적인 패킷
UDP 동작과정
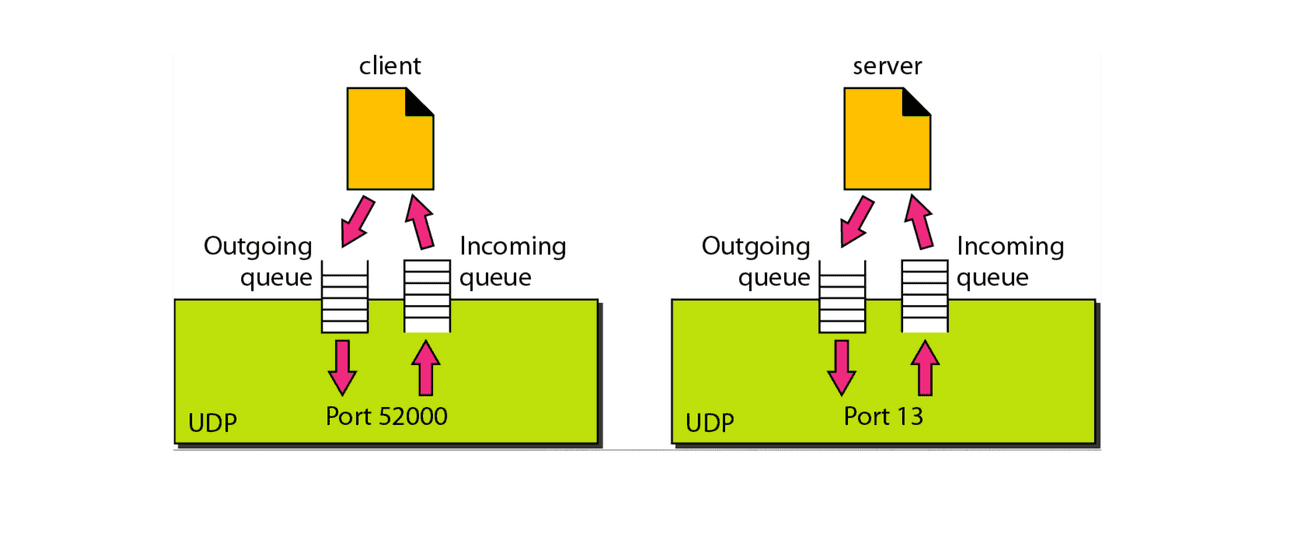
송신목적의 송신큐(Outgoing queue)와 수신목적의 수신큐(Incoming queue)가 존재한다
데이터 송신
- 프로세스에서 데이터를 외부로 전송하기 위해 송신 큐에 데이터를 밀어넣는다
- UDP는 프로세스에서 보낸 데이터를 하나씩 읽고 헤더를 붙여 3계층(IP)로 넘긴 후 송신 큐에서 제거한다
무작정 송신 큐에 많은 데이터를 넣으면 overflow가 발생할 수 있기 때문에 주로 이를 운영체제가 관리한다
데이터 수신
- 3계층(IP)에서 수신된 패킷이 있으면 이를 분석하여 통신하고자 하는 프로세스의 포트 번호와 연결을 시도한다
- 해당 포트 번호를 가진 프로세스가 있다면 패킷에서 통신 과정에 필요했던 헤더 정보를 벗겨내서 프로세스로 보낸다
결론
TCP는 연속성보다 신뢰성있는 전송이 중요할 때 사용된다.
UDP는 TCP보다 빠르고 네트워크 부하가 적지만, 신뢰성 있는 데이터 전송을 보장하지는 않아서 연속성이 중요한 서비스에 사용된다
12. www.naver.com 을 주소창에 입력했을 때, 네트워크 관점에서 발생하는 일을 최대한 자세하게 설명해주세요.
1. 브라우저의 URL 파싱
브라우저는 입력된 URL에서 필요한 모든 정보를 파악해야 한다.

- 프로토콜: 네트워크 상으로 통신할 때 어떤 프로토콜을 사용하여 해당 URL에 요청할 것인지 결정한다
- URL: 해당 웹사이트의 위치를 식별하기 위함
- 포트: 논리적인 접속 장소를 알려줌. 전송 계층에서 사용
이 경우에는 프로토콜과 포트를 제외하고 URL만 입력했지만, 나머지는 자동으로 구성된다. 브라우저에서 제공해주는 기능인데, 브라우저는 기본적으로 HTTP프로토콜을 사용해 접속을 시도하고, 사이트가 HTTPS프로토콜이 적용된 사이트면 리다이렉트 메시지를 보낸다. 이 요청을 통해 브라우저는 다시 해당 사이트에 HTTPS 프로토콜로 접속한다.
한 번이라도 HTTPS 프로토콜로 접속한 적이 있다면 HSTS(HTTP Strict Transport Security) 목록에 저장되며, 이후에 접속하게 되면 바로 HTTPS 프로토콜로 요청하게 된다.
포트는 명시적으로 선언하지 않아도 브라우저에서 설정된 기본값을 이용해 요청하고, HTTPS 프로토콜에 설정된 기본값은 443이다.
2. HSTS 목록 조회
해당 URL이 HSTS에 존재하면 HTTPS 프로토콜로 요청을 보내고, 존재하지 않으면 HTTP 프로토콜로 요청을 보낸다.
만약 해당 웹사이트가 HTTPS 프로토콜 연결만 허용하면 HTTP 프로토콜로 요청이 왔을 시 HTTP 응답 헤더에 Strict Transport Security라는 필드를 포함하여 응답하고, 이를 확인한 브라우저는 해당서버에 요청할 때 HTTPS 프로토콜만을 통해 통신하게 된다.
3. URL을 IP주소로 변환
브라우저는 캐시에 해당 URL이 존재하면 바로 접속하고, 존재하지 않으면 DNS 서버에 요청해 해당 URL을 IP주소로 변환한다.
브라우저가 로컬 DNS에서 확인하고, 있으면 반환, 없으면 Recursive Resolver에 보낸다.
브라우저가 Recursive Resolver에 도메인주소에 대한 쿼리를 전달하면, Resolver는 Root DNS에게 요청한다. Root DNS은 도메인 주소에 해당하는 TLD 네임서버로 응답하고, Recursive Resolver는 이 TLD 네임서버에 다시 요청을 보낸다. TLD 네임서버는 도메인주소에 해당하는 상세 네임서버로 응답하고, 이 상세 네임서버에 요청을 보내면 드디어 Resolver가 IP주소를 받는다.
4. 라우터를 통해 해당 서버의 게이트웨이까지 이동
Resolver는 웹브라우저에게 IP주소로 응답하고, 브라우저는 이 IP주소에 HTTP요청을 보낸다. 네트워크 장비인 라우터가 해당 주소까지의 경로를 라우팅하여 해당 주소에 요청을 전달한다
5. ARP를 통해 IP주소를 MAC주소로 변환
실질적인 통신을 위해서는 논리 주소인 IP주소를 물리 주소인 MAC주소로 변환해야 한다.
해당 네트워크 내에서 ARP를 브로드 캐스팅하고, 해당 IP주소를 갖고 있는 노드는 자신의 MAC주소로 응답한다.
6. 대상 서버와 TCP 소켓 연결
MAC주소를 통해 통신할 서버에 접근했으니 이제 실제로 통신하기 위해 3-way handshake을 통해 TCP 소켓 연결을 진행한다.
현재 요청이 HTTPS 요청이면 암호화 통신을 위한 TLS handshaking이 추가된다
7. HTTP(HTTPS) 프로토콜로 요청, 응답
해당 서버와 통신하기 위한 모든 과정이 완료되었으니 서버에게 웹페이지를 요청한다.
서버는 요청을 수락할 수 있는지 검사하고, 요청에 대한 응답을 생성하여 브라우저에 전달한다.
8. 브라우저에서 응답 해석
IP주소의 서버가 웹페이지를 보내면 브라우저가 이 페이지를 렌더링한다.
13. 네트워크 관련 공격 기법을 3가지 이상 조사해주세요. (ex. SQL Injection, XSS, CSRF, SSRF 등...)
SQL Injection
SQL injection은 흔한 웹해킹 기술로, 데이터베이스에 큰 영향을 끼칠 수 있다. 웹페이지 인풋으로 SQL문에 악성코드를 주입한다.
XSS (Cross-site scripting)
XSS(Cross Site Scripting): 사이트간 스크립팅이는 이름의 웹 취약점
- 웹사이트의 관리자가 아닌 악의적인 목적을 가진 제3자가 악성스크립트를 삽입해 의도하지 않은 명령어를 실행시키거나 세션 등을 탈취할 수 있는 취약점
- 대부분 자바스크립트 기반 공격이 이루어짐
- SQL Injection과 함께 웹취약점 중 가장 기초적인 취약점으로 알려짐
- 공격패턴이 다양하고 변화가 많아 완벽한 방어는 힘듬
위험성
- 쿠키 및 세션정보 탈취
- XSS에 취약한 웹게시판 등에 쿠키나 세션정보를 탈취하는 스크립트를 삽입해 해당 게시글을 열람하는 유저들의 쿠키 및 세션 정보를 탈취할 수 있음
- 공격자는 탈취한 정보를 바탕으로 인증을 회피하거나 특정 정보를 열람할 수 있는 권한을 가질 수 있음
- 악성프로그램 다운로드 유도
- XSS 자체는 악성프로그램을 다운로드 시킬수 없지만 스크립트를 통해 악성프로그램을 다운받는 사이트로 리다이렉트시켜 악성프로그램을 다운받도록 유도할 수 있음
- 의도하지 않은 페이지 노출: XSS를 이용해
<img>태그 등을 삽입해 원본페이지와는 전혀 관련없는 페이지를 노출시키거나, 페이지 자체에 수정을 가해 노출된 정보를 악의적으로 편집할 수 있음
공격 종류
- Reflected XSS: 공격자가 악성스크립트를 클라이언트에게 직접 전달하여 공격하는 방식
- URL에 스크립트를 포함시켜 공격하는 경우가 많음
- URL이 길면 클라이언트가 의구심을 가질 수 있어서 URL단축을 이용해 공격하기도 함
- 서버에서 스크립트를 저장하지 않기 때문에 서버에서 이루어지는 필터링을 피할 수 있는 공격
- Stored XSS: 공격자가 악성스크립트를 서버에 저장시킨 다음, 다음 클라이언트의 요청/응답 과정을 통해 공격하는 방식
- 스크립트를 서버에 저장하는 행위: 게시글 쓰기 등
- 보통 서버에서 필터링을 해서 공격을 우회하기 어렵지만, 한 번 성공하면 관리자가 눈치채기 어렵고 광범위한 피해를 줄 수 있음
- DOM Based XSS: 피해자의 브라우저가 html페이지를 분석해 DOM을 생성할때 악성 스크립트가 DOM의 일부로 구성되어 생성되는 공격
- 서버의 응답 내에는 악성 스크립트가 포함되지 않지만 브라우저의 응답페이지에 정상적인 스크립트가 실행되면서 악성스크립트가 추가되서 실행됨
XSS 방어 방법
- 입력값 검증: 데이터가 입력되기 전이나, 입력된 데이터를 서버에 전달하기 전에 프론트에서 검증하는 것
- 입력데이터의 길이 제한하기
- 지정된 문자 또는 형식으로 입력되었는지 확인
- 정해진 규칙을 벗어난 입력값들은 무효화시키기
- 출력값 검증
- 가장 흔히 쓰이는 대응 방식
- (예) 게시판에 올라온 글을 클릭하면 해당 글의 상세 내용을 조회하는 api를 호출하는데, 이 때 상세 내용에 HTML 또는 스크립트 구문이 들어가있다면 스크립트로 해석될 수 있어, 이런 여지가 있는 특수 문자들은 인코딩해서 보여줘야 함
- 보안 라이브러리와 브라우저 확장앱 사용
- Anti XSS 라이브러리: 서버단에서 개발자가 추가하는 것
- 사용자들이 각자 본인의 브라우저에서 악의적인 스크립트가 실행되지 않도록 방어하는 것이 중요
- Anti XSS 라이브러리: 서버단에서 개발자가 추가하는 것
- 웹 방화벽 사용: XSS 공격 및 각종 injection 공격에 대한 방어
- 쿠키 HttpOnly 옵션 활성화:
- 이 옵션을 활성화하지 않으면 스크립트를 통해 쿠키에 접근할 수 있어 세션 탈취에 취약해질 수 있음
- 활성화하면 악의적인 클라이언트가 쿠키에 저장된 정보에 접근하는 것을 차단함
- 이에 더불어 로컬 스토리지에 세션ID와 같은 민감한 정보를 저장하지 않는 것이 중요
CSRF랑 XSS는 어떤 차이가 있나요?
CSRF(Cross Site Request Forgery)
CSRF: 웹 어플리케이션 취약점 중 하나로 인터넷 사용자가 자신의 의지와는 무관하게 공격자가 의도한 행위를 특정 웹사이트에 요청하게 만드는 공격
- 해커는 희생자의 권한을 도용해 중요 기능을 실행할 수 있음
- 아래 조건이 만족되어야만 CSRF 공격이 이루어질 수 있음
- 위조 요청을 전송하는 서비스에 희생자가 로그인 상태
- 희생자가 해커가 만든 피싱 사이트에 접속
- 컴퓨터를 감염시키거나 서버를 해킹하지는 않음
CSRF 대응 방법
- Referer 체크: HTTP 헤더에 있는 Referer로 해당 요청이 요청된 페이지의 정보를 확인하는 방법
- 일반적인 경우 호스트와 Referer값이 일치함
- CAPTCHA 도입
- CSRF 토큰사용: 사용자 세션에 임의의 값을 저장하여 모든 요청마다 해당값을 포함하여 전송하도록 함
- 서버에서 요청을 받을 때마다 세션에 저장된 값과 요청으로 전송된 값이 일치하여 검증하여 방어하는 방법
CSRF vs. XSS
- 필요 조건
- CSRF) 로그인된 상태
- XSS) 로그인된 상태는 필요 없음
- 피해
- CSRF) 희생자 권한 내 가능한 행동만 사용 가능
- XSS) 악성 스크립트가 가능한 모든 범위
- 취약점
- CSRF) 유저가 악성 페이지 또는 링크를 클릭해야 함
- XSS) 취약점이 존재하면 됨
- 요청 방식
- CSRF) HTTP 요청만 보낼 수 있음
- XSS) 필요 데이터를 얻기 위해 HTTP 요청/응답을 보내고 수신할 수 있음
14. 클라우드 컴퓨팅이 무엇인가요? GCP, AWS, NCP 등은 어떤 차이가 있나요?
클라우드 컴퓨팅
클라우드 컴퓨팅은 컴퓨팅 리소스를 인터넷을 통해 서비스로 사용할 수 있는 주문형 서비스다. 클라우드 컴퓨팅 서비스 모델에는 3가지 유형이 존재한다
- Infrastructure as a Service: 컴퓨팅 및 스토리지 서비스를 제공한다
- Platform as a Service: 클라우드 앱을 빌드하는 개발 및 배포 환경을 제공한다
- Software as a Service: 앱을 서비스로 제공한다
클라우드 컴퓨팅 장점
- 유연성: 기업과 사용자가 인터넷만 연결되면 어디서나 클라우드 서비스에 액세스할 수 있다
- 효율성: 새로운 애플리케이션을 개발해서 빠르게 배포 가능
- 비용 효율성: 사용하는 컴퓨팅 리소스에 대해서만 비용을 지불한다
클라우드 컴퓨팅 용도
- 인프라 확장
- 재해 복구
- 데이터 스토리지
- 애플리케이션 개발
등
GCP, AWS, NCP의 비교
GCP: Google Cloud Platform
AWS: Amazon Web Services
NCP: Naver Cloud Platform
15. 캐시 메모리와, 캐시의 지역성에 대해 설명해주세요.
캐시 메모리
캐시 메모리: 속도가 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 범용 메모리
- CPU에서는 CPU 고어(고속)와 메모리(CPU에 비해 저속) 사이에서 속도차에 따른 병목현상 완화
메인 메모리에서 자주 사용하는 프로그램과 데이터를 저장해둬 속도를 빠르게 함 - CPU가 어떤 데이터를 원하는지 예측해야 함
- CPU의 속도에 버금갈 만큼 메모리 계층에서 가장 속도가 빠름
- 용량이 적고 비쌈
캐시 메모리 장점
- 애플리케이션 성능 개선
메모리는 디스크보다 속도가 빨라서 인 메모리 캐시에서 데이터를 읽는 속도가 매우 빠름
빠른 데이터 액세스는 애플리케이션의 전반적인 성능 개선 - 데이터베이스 비용 절감
단일 캐시 인스턴스는 수많은 데이터베이스 인스턴스를 대체할 수 있음 > 총 비용 절감 - 백엔드의 로드 감소
캐싱은 읽기 로드의 상당 부분을 백엔드 데이터베이스에서 인 메모리 계층으로 리디렉션함
데이터베이스의 로드를 줄임: 로드 시 성능 저하되거나 작업 급증 시 작동이 중단되지 않도록 보호
캐시 메모리 단점
모든 데이터를 캐싱하지 않는 이유
1. 메모리 특성상 데이터 소실 위험
2. 메모리 사용은 비쌈: 방대한 양의 데이터를 모두 메모리에 적재하는 것은 비용 너무 큼
캐싱하기 좋은 데이터
- 자주 바뀌지 않는 데이터
- 자주 사용되는 데이터
- 자주 같은 결과를 반환하는 데이터
- 오래 걸리는 연산의 결과
캐시의 지역성
캐시의 지역성, Cache Locality: 데이터에 대한 접근이 시간적/공간적으로 가깝게 발생하는 것
- 캐시의 적중률을 극대화하여 캐시가 효율적으로 동작하도록
- 공간 지역성, Spatial locality: 최근에 사용했던 데이터와 인접한 데이터가 참조될 가능성이 높다
배열, 페이지 접근 등 - 시간 지역성, Temporal locality: 최근에 사용했던 데이터가 재참조될 가능성이 높다
loop 등
캐시의 지역성 예시
이차원 배열을 가로/세로로 탐색했을 때의 성능 차이
이차원 배열을 반복문으로 탐색하는 전제 하에:
가로로 탐색하면 연속적인 공간을 참조함 > 공간 지역성의 이점 활용 > 성능이 더 좋음
세로로 탐색하면 불연속적 공간을 참조함 > 공간 지역성 X > 성능이 덜 좋음
참고
https://www.redhat.com/ko/topics/virtualization/what-is-a-virtual-machine
https://www.vmware.com/topics/glossary/content/hypervisor.html
https://www.vmware.com/topics/glossary/content/virtual-machine.html#:~:text=A%20Virtual%20Machine%20(VM)%20is,a%20physical%20%E2%80%9Chost%E2%80%9D%20machine.
https://www.docker.com/resources/what-container/
https://developers.redhat.com/blog/2017/09/06/continuous-integration-a-typical-process?cicd=32h281b&extIdCarryOver=true&sc_cid=701f2000001OH7EAAW
https://www.redhat.com/en/topics/devops/what-is-ci-cd
https://www.geeksforgeeks.org/session-vs-token-based-authentication/
https://80000coding.oopy.io/ed22f6e8-89ea-4164-a86e-a6b92a1f54b4
https://gmlwjd9405.github.io/2019/02/01/orm.html
https://seamless.tistory.com/42
https://tech.inflab.com/20230404-test-code/
https://www.geeksforgeeks.org/tcp-3-way-handshake-process/
https://wormwlrm.github.io/2021/09/23/Overview-of-TCP-and-UDP.html
https://velog.io/@becooq81/DNS%EC%99%80-DNS-%EB%A0%88%EC%BD%94%EB%93%9C
https://cloud.google.com/learn/what-is-cloud-computing?hl=ko
https://velog.io/@becooq81/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-%EC%BA%90%EC%8B%9C-%EB%A9%94%EB%AA%A8%EB%A6%AC

와우... 내용이 방대하네요!! 잘 읽고 갑니다.