백엔드 프로젝트를 스프링 웹플럭스로 구현하기로 한 김에..
1. Spring Webflux란?
탄생배경
- 적은 스레드로 동시처리를 제어할 논블로킹 웹스택의 필요성
- Servlet으로 논블로킹 I/O를 구현하면 동기처리(
Filter,Servlet) 또는 블로킹(getParameter,getPart) 등을 사용하기 어려움 - 논블로킹 전반에 걸쳐 사용할 공통 API가 필요함
- Servlet으로 논블로킹 I/O를 구현하면 동기처리(
- 함수형 프로그래밍
- Java 8에서 람다 선언의 등장 >> 함수형 API
- 비동기 로직을 선언적으로
웹스택이란? OS, 프로그래밍 언어, 데이터베이스 소프트웨어, 웹 서버 등을 포함하는, 웹 개발에 쓰이는 소프트웨어의 집합
Servlet이란?
- 자바를 허용하는 웹/앱 서버에서 런하는 자바 프로그램
- 웹서버로부터 받아온 요청을 처리하고 응답을 만들어 전송하는 데 쓰임
- 웹서버와 데이터베이스의 중간다리
Reactive?
Reactive: 변화에 대한 반응을 중심으로 짜여진 프로그래밍 모델
- (예) I/O 이벤트에 반응하는 네트워크 컴포넌트, 마우스 이벤트에 반응하는 UI 컨트롤러 등
- Non-blocking은 즉 reactive다
- 블록되지 않고 작업이 끝났다는(또는 데이터가 사용 가능해졌다는) 알림에 응답하는 방식이기 때문
Non-blocking back pressure
Back pressure: 트래픽 통신 과부하에 대한 피드백 매커니즘
- 동기 명령형 코드) 블로킹 콜이 곧 back pressure다
- caller가 기다리도록 강제한다
- 논블로킹 코드) 생산자가 목적지를 과부하시키지 않도록 이벤트 rate을 제어하는 것이 중요
Reactive API
Spring Webflux는 리액티브 라이브러리 Reactor를 채택한다
Reactor
- Reactive Streams library
- 즉,
Reactor의 모든 기능이 non-blocking back pressure을 지원함
- 즉,
- 데이터 시퀀스 처리를 위해
Mono,FluxAPI 타입을 제공한다 WebFlux API는Reactor에 대한 의존성이 필수적임Reactive Streams을 통해 다른 reactive 라이브러리와도 상호운용적Publisher를 받아 내부적으로Reactortype으로 적용해서 처리하고,Flux/Mono를 리턴함
Servers
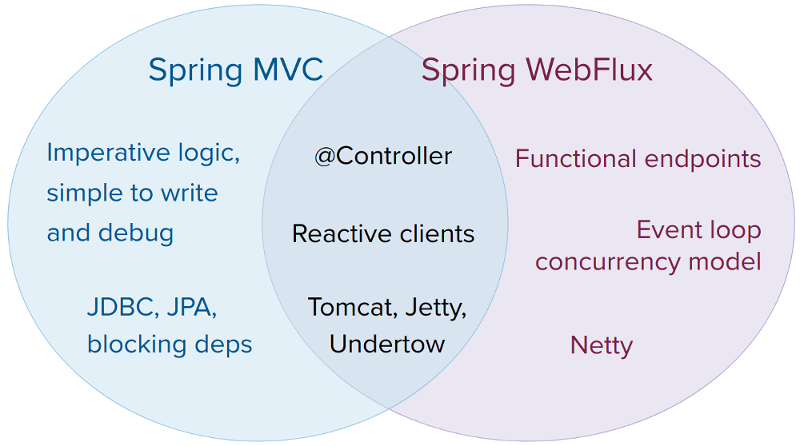
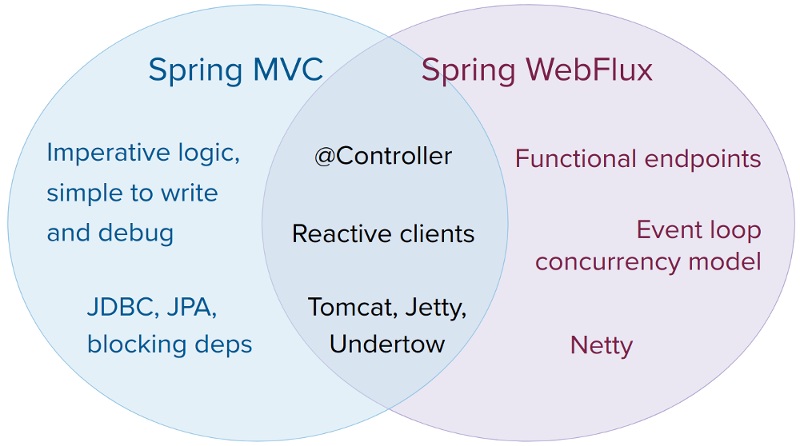
2. Spring Webflux vs. Spring MVC
[이미지 출처]
{kind=link}
Spring MVC와 WebFlux는 함께 사용해도 됨
- Spring MVC 애플리케이션이 이미 잘 돌아가면 걍 그거 쓰자
- 논블로킹 웹스택이 필요하면 Spring Webflux
- 경량, 함수형 웹 프레임워크가 필요하면 Spring Webflux
...
결국 경우에 따라 고려하면 됨
3. [배민스토어] 우리만의 자유로운 WebFlux Practices
WebFlux 도입 배경
- 계층 경계의 모호함
- 코드 간 interconnectivity
- legacy API의 존재
- 앞으로 늘어날 연동 플랫폼 및 응답 시간 고려
- 저장소 구조(Redis+DynamoDB): 모두 논블로킹 API 제공
- WebFlux의 성능 장점
시행착오: zip()
zip(): 주어진 입력 소스를 병합하는 메서드
문제: 본사(seller)와 지점(shop)이 1:N으로 구성될 때, 본사에 연결된 모든 지점의 정보를 가져온 뒤, 본사 정보와 지점 정보를 조합해 사용자에게 보여준다
과정:
fun getSeller(sellerId: String): Mono<Seller> = sellerRepository.findById(sellerId)
fun getShops(shopIds: Collection<String>): Flux<Shop> = shopRepository.findAllByIds(shopIds)getSeller- 본사 정보를 가져오는 함수
- 본사는 한개이니
Mono - 반환형:
Mono
getShops- 지점 정보를 가져오는 함수
- 지점 정보는 여러개니
Flux - 반환형:
Flux
본사 정보(i.e., 삼성스토어)와 지점 정보(i.e., 송파점)을 합치고자 한다
getShops(shopIds)
.zipWith(getSeller(sellerId))
.map { (shop, seller) -> "${seller.name} ${shop.name}" }위처럼 코드를 작성하면 지점이 딱 한 개만 나오는 버그가 발생한다
왜냐?
zip() 연산자에 3개의 Publisher를 넘기면, 각 Publisher가 한개씩은 값을 내보내야 zip() 연산자도 한 묶음의 값을 내보내기 때문에 여러 값을 내보내는 Publisher와 하나의 값을 내보내는 Publisher를 zip하면 한개의 값만 받게 된다
배민 WebFlux 관례
1. 파이프라인은 변수 말고 함수로 분리
파이프라인을 구성할 때 Flux, Mono를 반환하는 일련의 로직을 함수로 분리하자
val seller = sellerRepository.findById(sellerId)
val shops = shopRepository.findAllByIds(shopIds)
Mono.zip(
seller,
shops.collectList(),
)보다는.. 아래 코드처럼!
fun getSeller(sellerId: String): Mono<Seller> = sellerRepository.findById(sellerId)
fun getShops(shopIds: Collection<String>): Flux<Shop> = shopRepository.findAllByIds(shopIds)
Mono.zip(
getSeller(sellerId),
getShops(shopIds).collectList(),
)왜냐?
- 의미가 분명한 변수 작명이 어려움
- 특히 타입을 변수명에 포함하면 안티 패턴
- 파이프라인 안에서 사용되는 타입 특성상 함수 그대로 보이는 것이 직관적임
하지만 Mono, Flux를 캐싱해서 파이프라인 하나에서 여러 번 구독하여 사용하는 경우 (cache() 등을 통해)에는 변수를 추천
2. zipWhen()을 활용하자
flatMap을 통해 여러 값을 조합하면 중첩 flatMap이 생길 가능성이 높기 때문에 Mono.zipWhen()을 활용하자
shopRepository.findById(shopId)
.zipWhen { shop -> sellerRepository.findById(shop.sellerId) }
.map { (shop, seller) -> mapper.toDto(shop, seller)
}3. 값이 없을 때는 defaultIfEmpty()
Flux, Mono에 값이 없을 때 switchIfEmpty()보다
shopRepository.findById(shopId)
.map { shop -> shop.name }
.switchIfEmpty("알 수 없는 지점".toMono())defaultIfEmpty()가 더 간결하다
shopRepository.findById(shopId)
.map { shop -> shop.name }
.defaultIfEmpty("알 수 없는 지점")안정성을 위한 관례
1. 값의 처리에는 flatMap()을 지양하자
하나의 이벤트로 여러 처리를 실행할 때 flatMap()을 사용하면, 서로 의존할 필요 없는 로직끼리 의존하게 되는 문제가 생긴다.
fun saveToDB(event: ProductEvent): Mono<ProductEvent> =
productDBRepository.save(toEntity(event))
.thenReturn(event)
fun saveToCache(event: ProductEvent): Mono<ProductEvent> =
productCacheRepository.save(toCacheObject(event))
.thenReturn(event)
fun process(event: ProductEvent): Mono<Void> =
saveToDB(event)
.flatMap { saveToCache(event) }
.then()위처럼 작성한 코드는 누군가 리턴값을 지운다면 함수간 의존성 때문에 어느 로직은 절대 실행되지 않는 경우가 생길 수가 있음.
- 순차적인 실행을 위해
then() - 순서가 중요하지 않은 병렬 실행을 위해
and()
saveToDB(event).then(saveToCache(event))
saveToDB(event).and(saveToCache(event))디버그
1. 로그는 파이프라인 안에
fun getSeller(sellerId: String): Mono<Seller> =
sellerRepository.findById(sellerId)
.doFirst { log.debug("셀러 조회 발생: {}", sellerId) }References
- https://techblog.woowahan.com/12903/
- https://www.techtarget.com/whatis/definition/Web-stack#:~:text=A%20web%20stack%20is%20the,a%20type%20of%20solution%20stack.
- https://www.geeksforgeeks.org/introduction-java-servlets/
- https://blog.knoldus.com/spring-reactor-backpressure/#:~:text=Backpressure%20is%20the%20ability%20of,data%20flow%20from%20the%20Publisher.
