QUIC 프로토콜 개요
22년 6월에 표준화가 완료된 HTTP/3.0의 기반이 되는 프로토콜로 Google에서 완성한 기술이다.
본 문서에서는 HTTP/2.0에 어떤 한계가 있었으며 그것을 극복하기 위해서 QUIC 프로토콜이 나오게 된 그 배경에 집중할 계획입니다.
QUIC 프로토콜 어쩌다가 나왔나?
HTTP/2.0의 태생적 한계 (TCP의 한계와 유사)
HTTP/2.0은 이전에 비해 많은 부분이 향상되었습니다.
하지만 TCP 기반으로 동작하기 때문에 TCP가 가진 태생적 한계를 벗어날 수가 없습니다.
TCP는 연결수립이 느리다
TCP는 신뢰성, 안정성을 중요하게 생각하는 프로토콜입니다.
데이터를 보낼때 중간에 손실되지 않고 확실하고 안전하게 전달돼야합니다.
그것을 위해서 연결하는 과정이 필요한데, 이 과정이 느립니다.
TCP는 어떻게 신뢰성을 보장하는가?
TCP가 확실하게 데이터를 주고 받기 위해서 사용하는 것이 일련번호(sequence number)입니다.
TCP에서는 데이터를 보낼 때, 여러 개의 패킷으로 나누어보냅니다.
한번에 많은 데이터를 보내는 경우 대역폭을 많이 차지할 수 있기 때문입니다.
이때, 패킷은 sequence number가 포함합니다. 이것이 중간에 손실된 데이터가 있는지 검증하는 수단이 됩니다. 이를 바탕으로 중간에 손실된 데이터 유무를 확인할수 있고 그로인해 데이터 전송의 신뢰성이 보장되는 것입니다.
예를 들어서 여러분이 책을 읽는다고 가정합시다.
책은 1~100페이지 분량이고 장르는 추리소설입니다.
여기서 책은 데이터, 페이지는 패킷에 대응됩니다.
우리는 한 페이지씩 전달받아 읽을수 있습니다.
1~10페이지 까지는 순서대로 전달받아서 밀실사건의 개요를 이제 막 알게된 참입니다.
밀실에서 어떻게 사람을 해쳤을까, 왜 그랬을까 흥미진진해지는 참입니다.
그런데 다음으로 갑자기 80페이지를 받고, 거기서 사건의 범인을 바로 알게됩니다.
느닷없는 스포일러 공격을 당한 여러분은 이후에는 꼭 받은 페이지의 번호를 확인하게 됩니다.
스포일러를 막기 위해서 10페이지를 읽은 다음엔 11페이지만 받으려는 것입니다.
받은 페이지가 11페이지가 아니라 80페이지라면 읽어보지도 않고 '11페이지 줄래?' 하고 요청합니다.
이런 방식으로 일련번호를 확인하면 빠지는 데이터가 없이 (스포일러 없이) 안전한 전달이 가능합니다.TCP에 3-way-handshake는 왜 필요한가?
이렇게 sequence number를 사전에 확립하기 위해서 필요한 절차 = 3-way-handshake입니다.
TCP는 양방향 통신이기 때문에 클라이언트도, 서버도 데이터를 보낼 수 있습니다.
따라서 누가 보낸건지를 구분할 수 있는 수단이 있으면 좋을것 같습니다.
그 수단으로 각자의 sequence number가 좋을것 같습니다.
이때 맨처음에 생성하는 일련번호를 ISN(Initial Sequence Number)라고 합니다.
그리고 둘 다 서로의 초기 일련번호를 알 필요가 있습니다.
이것을 서로에게 알려주기 위해서 3-way-handshake가 필요한 것입니다.
여기까지 1-RTT가 소요됩니다.
(1-handShake)==========================================================
영희 -> 철수 : 철수야 내 ISN은 256란다.(SYN)
(2-handShake)==========================================================
영희 <- 철수 : 너의 ISN을 받았어. 256구나 알겠어(ACKnowledge)!
나는 257(256+1)을 받을 준비가 되었어(ACK)
영희 <- 철수 : 영희야 그리고 내 ISN은 567이야 (SYN)
(3-handShake)==========================================================
영희 -> 철수 : 너의 ISN을 받았어. 567이구나 알겠어(ACKnowledge)!
나는 568(567+1)을 받을 준비가 되었어(ACK)여기에 더해 보안을 신경 쓴 TLS handshake가 더해지면 어떻게될까요?
TLS handshake :
TLS는 보안 통신을 위해서 설계된 프로토콜입니다.
그리고 TLS handshake란 이 TLS를 이용해서 안전한 통신을 하기 위한 과정입니다.
간략하게 설명하면, 서버와 클라이언트가 서로 호환되는 암호화 알고리즘을 선택하고, 암호화에 사용될 난수와 서버의 인증서 그리고 키를 교환하는 과정입니다.
TLS핸드쉐이크까지 마무리 된 이후부터 본격적으로 클라이언트가 서버에게 원하는 요청을 시작할 수 있습니다.
여기서 포인트는 가장 진보된 버전이 1.3 버전에서는 2-way-handShake(1-RTT) 가 소요된다는 점입니다.
작은 결론 :
RTT는 쉽게 말해서 요청과 응답사이의 시간입니다.
RTT가 많아지면 안 좋은 이유를 이해하기 편하게하기 위해서 최악의 경우를 상정하겠습니다.
지구 반대편으로 요청을 하게되면 데이터는 지구를 한바퀴 돌아야합니다.
데이터 전달 속도는 빛의 속도이므로 RTT는 최소 133ms가 소요됩니다. (빛은 지구를 1초에 7바퀴 반 돔)
이것으로 인해 로딩 시간이 길어지면 사용자 경험이 안 좋아집니다.
따라서 사용자 경험 개선을 위해서 로딩시간을 줄이고 싶은데.
RTT시간을 줄일수는 없으므로(광속은 상수이기 때문에 ),
아예 RTT수 자체를 줄여야 한다는 쪽으로 사고가 이동한것 같습니다.
핵심은 TCP-Handshake가 진행된 다음에 TLS-Handshake 추가적으로 실행된다는 점입니다.
Handshake가 반복되면서 전체적인 RTT가 증가하게 됩니다.
이것이 TCP의 연결수립이 느린 이유입니다.
두 Handshake 패턴이 비슷한데? 한꺼번에 할수 있지 않을까요? 그러면 RTT수가 줄지 않을까요?
Q. 한꺼번에 할수 있겠다는 근거는 무엇일까요?
A. TCP-Handshake의 결과가 TLS-Handshake에서 필요하지 않기 때문입니다.
그래서 어떻게 해결했는가?
TCP-Handshake와 TLS-Handshake를 병합하는 QUIC 프로토콜을 개발하면서 해결했습니다.
왜 진작 TCP-Handshake와 TLS-Handshake를 병합하지 않았을까?
설계 구조와 호환성 그리고 라이브 서비스
TCP는 전송계층에서 동작하며 TLS는 애플리케이션 계층에서 동작합니다.
서로 다른 계층에서 상호작용을 최소화하도록 설계되었기 때문에 병합하기 위해서는 내부적으로 통합하는 프로토콜을 새로 만들어야 합니다.
그러지 않고 TCP 내부에서 통합하는 업데이트를 해버리면, 기존 TCP와 호환하던 네트워크 장비들과는 호환되지 않습니다.
해당 장비도 그에 맞는 업데이트를 한다면 가능합니다.
하지만 그러기 위해서는 기존의 네트워크 장비들의 운영체제를 업데이트 해야합니다.(TCP는 운영체제의 커널에 깊이 통합됐기 때문에).
이것은 전세계적인 단위의 인프라를 업데이트 해야하는 문제기 때문에 현실적으로 어렵습니다.
기존의 TCP로 잘 돌아가던 것들은 유지하기 위해서, 운영체제 업데이트 없이 해당 문제를 해결하려면은 애플리케이션 레벨에서의 프로토콜 구현하면 됩니다. 그렇게 만들어진게 QUIC 프로토콜입니다.
QUIC 프로토콜은 애플리케이션 계층상의 프로토콜이므로 전송계층으로 사용할 프로토콜이 필요합니다. 그럼 이때 TCP와 UDP 둘중에 무엇을 사용해야할까요? 앞서 말했듯이 TCP는 아닙니다.
왜냐하면 TCP를 사용하기 위해서는 이미 약속된 Handshake를 지워야하는 OS 업데이트가 필요합니다. 이렇게 네트워크 장비의 OS 업데이트를 시킬거면 QUIC을 따로 만들필요가 없겠죠?
UDP는 이미 약속된 Handshake가 없기 때문에 네트워크 장비의 OS 업데이트 없이 애플리케이션 레벨에서의 프로토콜로 TCP와 TLS의 기능(장점)을 구현하여 문제를 해결할수 있습니다.
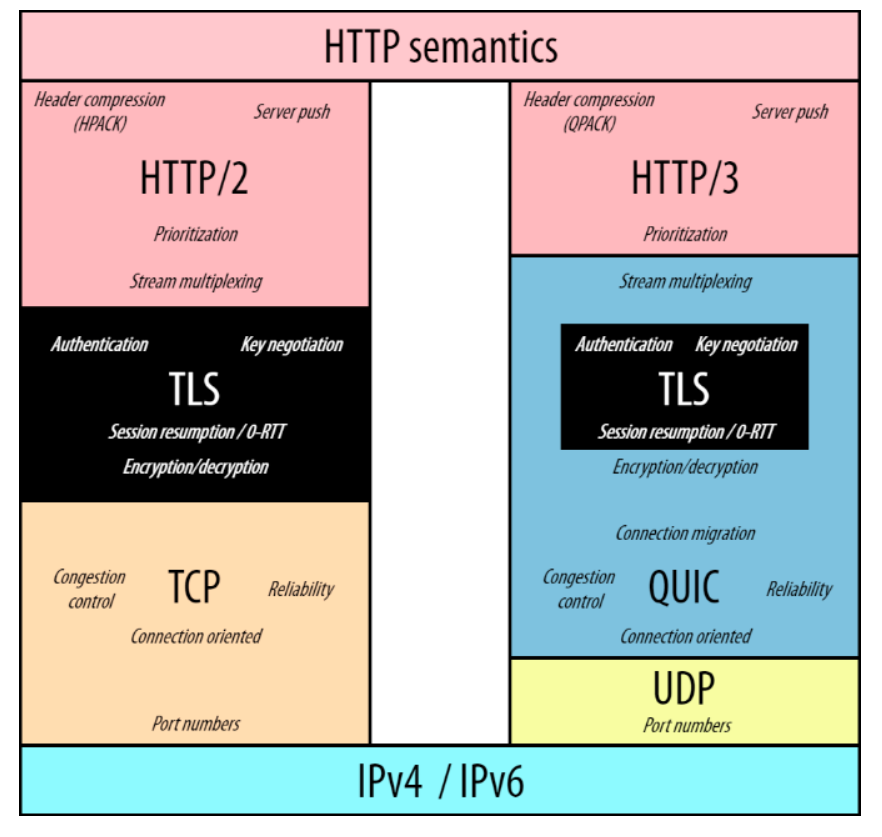
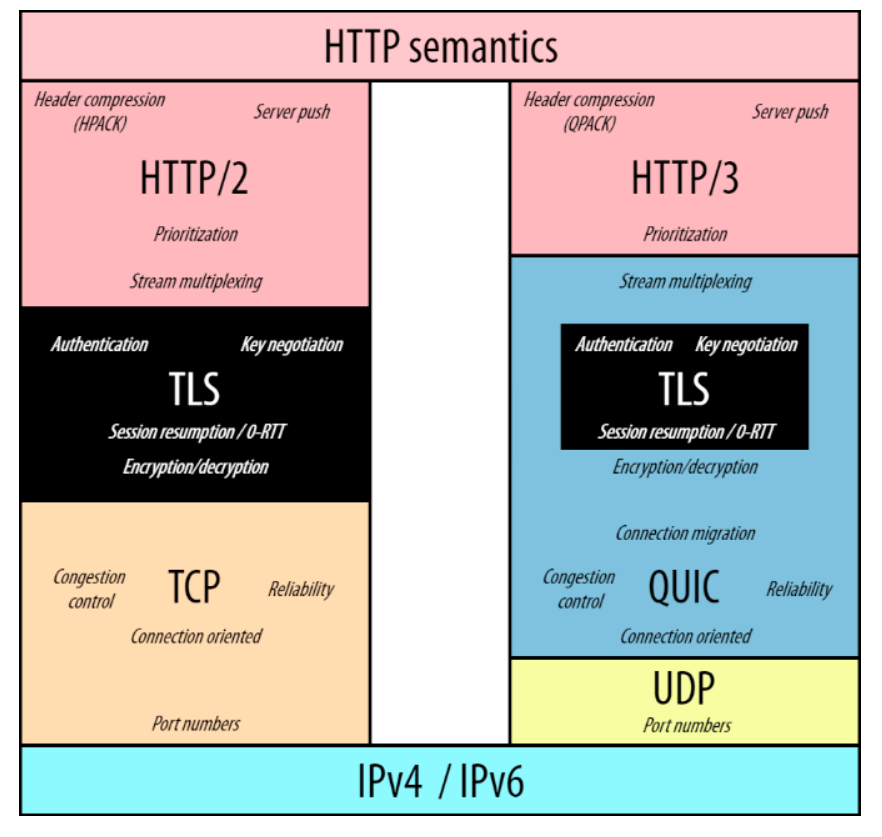
왼쪽 그림을 보면 기존의 TCP위에 TLS가 독립적으로 존재합니다.
하지만 오른쪽 그림의 QUIC에서는 TLS를 내장하고 있습니다.
TCP를 사용하면 연결을 수립할때 TCP다음 TLS에게 바톤이 넘어가면서 각 단계에서 RTT가 발생합니다.
그에 반면, QUIC를 사용하는 경우에는 TLS단계를 QUIC 단계에서 함께 처리할수 있습니다.
따라서, QUIC 단계 하나에서만 RTT가 발생한다고 해석할수 있습니다
QUIC의 장점
- 본문에서의 on Topic
- RTT수를 줄였다.
- 본문에서의 off Topic
- TCP 레벨의 Head-of-Line Blocking 문제 해결
- IP 주소가 변경되어도 연결을 유지할 수 있도록 설계됨
- 네트워크 전환이 발생해도 연결을 다시 설정할 필요가 없기 때문에
모바일 환경에서 더 안정적인 연결을 제공함 - 기존 TCP는 연결이 끊기면 다시 HandShake하면서 연결시작해야함.
오래 걸림…
- 네트워크 전환이 발생해도 연결을 다시 설정할 필요가 없기 때문에
QUIC의 단점
대표적으로 호환성 문제가 있다.
QUIC는 새로운 프로토콜이기 때문에 아직 지원하지 않는 클라이언트나 서버가 다수 존재할것이다.
따라서 이들과는 호환되지 않는다.
사용하는 곳(HTTP/3 지원 웹 사이트)
- 구글
- 유튜브
- 그외 대부분의 서비스
- 클라우드 플레어
- 클라우드 플레어를 사용하는 모든 웹 사이트에 기본적으로 적용됨.
- 그외 메이저 CDN
- 네이버 검색
- 토스 페이먼츠
- 나무위키
- 페이스북
- 인스타그램
- 넷플릭스
- ZOOM
레퍼런스: https://namu.wiki/w/HTTP/3
더 알아보기
0-RTT (제로-라운드 트립)
:BONUS: TCP레벨에서의 HOLB가 해결된 멀티플렉싱 :
TCP에서의 패킷 전송 흐름 :
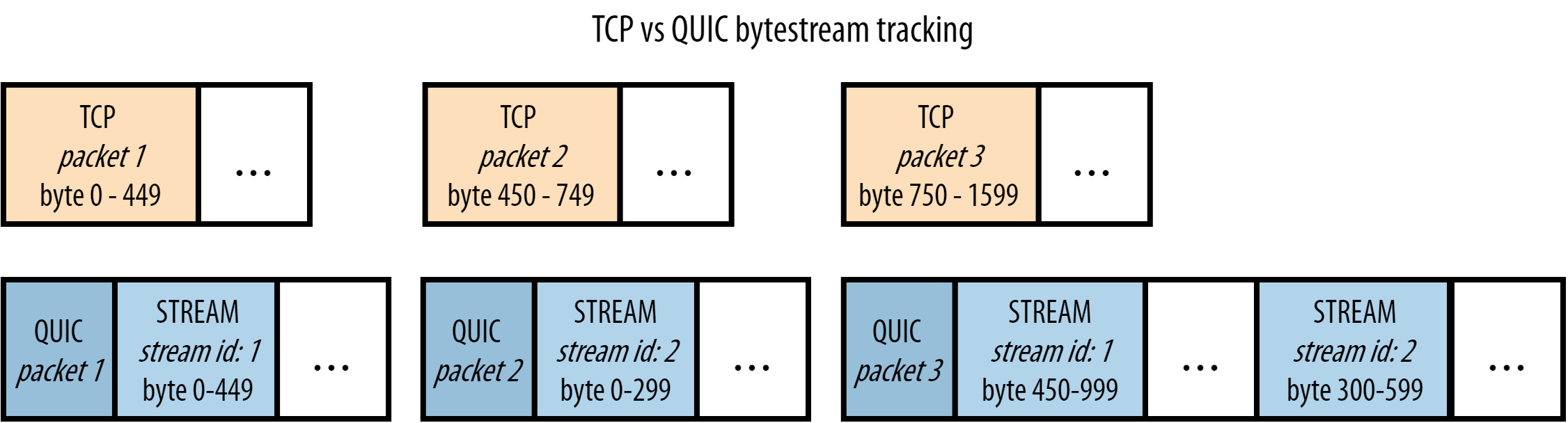
위쪽의 주황색은 TCP에서의 패킷 전송흐름입니다. 위에서 설명드렸다시피, TCP는 신뢰성을 중요하게 생각하는 프로토콜이기 때문에 각각의 패킷들이 순서에 맞게 도착하도록 해야합니다. 그것을 위해서 byte range가 주어져있습니다. 주황색 그림을 예로 들어 설명해보겠습니다.
packet1이 도착함 → packet1의 byte range 확인 후 이전 byte range와 연속적인지 비교 →
연속적임 → 기억 →
packet3이 도착함 → packet3의 byte range 확인 후 이전 byte range와 연속적인지 비교 →
연속적이지 않음 →
packet2 재전송 요청 → packet2 응답으로 올때까지 다른 packet들은 모두 대기
packet1과 packet3이 stream1에 속하는 데이터고
packet2가 stream2에 속하는 데이터라고 가정해보겠습니다.
그렇다면 packet2가 손실된 것은 packet1과 packet3의 데이터와는 큰 상관이 없음에도
불구하고 packet3는 그냥 기다린것이 됩니다.
QUIC에서의 패킷 전송 흐름 :
그런데 QUIC은 이런 문제를 각각의 패킷에 stream id를 부여함으로써 해결합니다.
여기에선 각각의 패킷마다 그 안에 stream id를 가지고 있습니다. 이게 핵심입니다.
1번 패킷이 먼저 도착하고 그 다음에 3번 패킷이 도착했다고 가정하겠습니다.
다시 말해서 packet 2에 손실이 생긴 것입니다.
만약 TCP였다면 곧 바로 packet2를 재전송 요청했을 것입니다.
하지만, QUIC에서는 패킷이 도착한다? 그러면 stream id를 먼저 확인합니다.
그런 다음, 이전 stream id에서 가지고 있던 byte range를 확인합니다.
아래는 또 다른 예시를 더 자세하게 풀어쓴 내용입니다.
packet 1이 도착했다.stream id를 확인하니 1번 stream이다.
해당 스트림에 대한 byte range를 기억한다.
packet 3이 도착했다.stream id를 확인해보니 1번 stream이다.
그러면 이전에 받은 stream1의 byte range를 확인한다.
확인해보니 0-449다. 지금 받아온 byte range는 450-999다.
byte range 사이의 어떤 gap도 존재하지 않는다. 정상이라고 처리한다.
packet 4를 받았다.stream id를 확인해보니 2번 stream이다.
그러면 이전에 stream id 2번의 byte range를 확인한다.
어, 그런데 해당 데이터가 존재하지 않는다.
지금 받아온 byte range는 300-599인데, 0-299라는 gap이 존재한다.
stream id 2 번에 대한 이전 패킷을 다시 요청해야겠다.
stream 2번에 해당하는 이전 패킷을 요청한다.
다시 손실된 패킷을 받아오는 동안, packet 4번의 데이터는 보관된다.
그리고 나머지 상관없는 stream1의 패킷에는 지연이 발생하지 않는다.
오로지 Stream 2번과 관련된 패킷에만 지연이 생긴다.
이런 원리를 통해서 http3에서는 TCP 차원에서 발생하던 HOLB의 문제를 해결했습니다.
모든 패킷들에 대해서 순서를 지키도록 하는 것은 아니고, 각 스트림에 대해서는 순서를 지키도록 하면서 QUIC은 신뢰성을 보장하고 있습니다.
요약:
- 스트림 = 개별 파일
- 2.0에서는 멀티플렉싱으로 하나의 tcp에서 여러 파일을 받을수 있게됨.
- 이전에는 파일마다 연결이 필요 했음.
- 좋긴한데 stream1에서 패킷 손실이 발생하면 다른 streamK의 패킷들도 지연되는 문제가 있었음. (TCP레벨에서의 Head Of Line Blocking 문제)
- 3.0에서는 이 마저도 해결함.
- 각각의 streamK들은 패킷 손실이 발생해도 서로 독립적으로 지연됨.
:BONUS: TCP와 UDP를 대화 타입에 비유
TCP => 우리 어디까지 이야기했더라? 반응 주고 받으며 계속 확인하는 사람.
- 대화의 질은 좋지만 대화하는데 에너지가 많이 들어감, 특히 여러명이 말걸때.
- 확인하는 과정이 곧 추가적인 비용이고 따라서 비용이 큰 방법.
UDP => 자기 할 말만 계속 하는사람.
- 대화는 아니지만 말하는 사람은 편하게 자기하고 싶은 이야기 말할수 있음.
- 사용 체력 대비 많은 말을 할수 있음.
- 상대방 반응 확인할 시간 아껴서 빠름.
- 기본적으로 단방향 통신이지만, 애플리케이션 레벨에서 송수신 잘 처리하면 양방향 통신도 가능하다.
- 사용 분야: (realTimeService) 통화, 온라인 게임, 스트리밍 서비스
- 이유 예시) 통화를 TCP로 했을때
- ㄱ: 너 나 좋아해?
- ㄴ: ...(TCP 느려서 아무것도 못 들어서 침묵중)
- ㄱ: 왜 말이 없어? 나 싫어해?
- ㄴ: 응! (ㄱ: 너 나 좋아해?가 이제 도착하고 그에대한 대답)
- 실시간 소통이 안될경우 대화가 꼬여서 대참사가 발생할수 있다.
✨레퍼런스


성지순례왔습니다.