NumPy란?
: 넘파이라고 읽으며 Numerical Python을 의미함.
오픈소스 라이브러리이며 n차원의 배열 객체인 ndarray를 효율적으로 작동하는 방법과 함께 제공됨.
배열의 속성
배열은 일반적으로 유형 및 크기가 동일한 항목의 고정 크기 컨테이너이다.
배열의 차원과 항목 수는 해당 모양으로 정의되며, 배열의 모양은 음이 아닌 정수의 tuple이다.
Numpy에서는, 차원을 ‘축, Axis’ 이라고 한다. 다음은 2차원의 배열이다.
[[0., 0., 0.,]
[1., 1., 1.,]]
이 배열에는 2개의 축이있으며 2x3의 모양을 가지고 있다.N차원 배열(N Dimension Array, ndarray)
NumPy의 ndarray클래스는 행렬과 벡터를 모두 나타내는 데 사용된다.
Numpy 배열은, 파이썬의 리스트와 유사하지만 다음과 같은 특징을 가진다.
- 동일한 데이터 타입 :
NumPy 배열은 모든 요소가 동일한 데이터 타입을 가진다. 이는 메모리 구조를 간소화하고 데이터 처리 속도를 높이는 데 도움이 된다. - 다차원 배열 :
NumPy 배열은 다차원 배열을 지원한다. 1차원 : 벡터, 2차원 : 행렬, 3차원 : 텐서 등으로 표현함. - 고속 연산 :
내부적으로 C언어로 구성되어 있으며 벡터 및 행렬 연산등 수치 계산에 최적화 되어있다.
⭐ NumPy 배열의 내부 구성
NumPy 배열의 내부는 다음과 같이 구성된다.
- 데이터 버퍼 (Data Buffer) :
NumPy 배열은 메모리에 일련의 연속된 데이터로 저장된다. 이 데이터는 C언어와 유사한 방식으로 저장된다.
ndarray 클래스는 데이터를 저장하기 위한 버퍼를 가리키는 포인터를 포함한다. - 데이터 타입 (Data Type) :
NumPy 배열은 고정된 데이터 타입을 가지며, 모든 요소는 동일한 데이터 타입을 가져야 한다.
이러한 데이터 타입은 ndarray 객체의 dtype 속성을 통해 지정된다. 예를 들어, 정수 배열, 부동 소수점 배열, 복소수 배열 등을 생성할 수 있다. - 차원 (Dimension) :
NumPy 배열은 다차원 데이터를 처리할 수 있다. 따라서 배열은 1차원, 2차원, 3차원 등으로 정의될 수 있다.
ndarray 클래스는 배열의 차원을 나타내는 shape 속성을 포함한다. 예를 들어, 3x3 행렬은 (3, 3)의 shape를 가진다. - 스트라이드 (Stride) :
NumPy 배열은 차원 간의 간격을 나타내는 스트라이드를 가집니다. 스트라이드는 ndarray 객체의 strides 속성을 통해 지정됩니다.
예를 들어, 3x3 행렬의 스트라이드는 (24, 8)이 될 수 있습니다. 이는 행 간에는 24바이트씩, 열 간에는 8바이트씩 떨어져 있음을 의미한다. - 포인터 (Pointer) :
NumPy 배열은 메모리에 일련의 연속된 데이터로 저장된다. 이러한 데이터는 ndarray 객체의 데이터 버퍼를 가리키는 포인터를 통해 액세스된다.
기본 배열 만들기
np.array()
Numpy 배열을 만들기 위해, 해당 함수를 사용한다.
(파이썬의 리스트나 튜플 등의 시퀀스 데이터를 NumPy 배열로 변환한다.)
import numpy as np
a = np.array([1,2,3])
np.zeros(n)
n개의 요소가 0인 배열을 생성한다.
np.zeros(2)
array([0., 0.])np.ones(n)
n개의 요소가 1인 배열을 생성한다.
np.zeros(2)
array([0., 0.])np.empty(n)
n개의 요소가 무작위인 배열을 생성한다. 메모리 상태에 따라 달라짐
빠른 속도를 이용해 효율적인 메모리 활용을 위해 사용하는 듯 하다.
np.empty(2)
array([-1.67573603e+182 1.95661529e+024])np.linspace(x, y, z)
x번째 인자 ~ y번째 인자까지 범위 내에서 z번째 인자 갯수만큼 선형 간격(일정한 간격)을 가진 숫자들을 배열로 반환한다.
np.linspace(0, 10, num=5)
array([0., 2.5, 5., 7.5, 10.]) 말이 좀 복잡한데, 보면 array는 서로 2.5(동일한 간격, 선형 간격) 차이가 나는 숫자들이 num=5와 같은 5개가 반환된다.
* 더 쉽게 생각하자면, 1개의 케이크를 (x번째 인자부터, y번째 인자까지 먹을건데, z번째 만큼의 사람이 공평하게 나눌 수 있냐.) 같은 느낌이다.
np.random.rand(x, y)
0에서 1사이의 균등 분포로 난수를 생성하는데, x행/y열 의 모양을 가진 배열을 반환한다.
a = np.random.rand(2, 3)
>>> [[0.28936222 0.05805373 0.62299882]
[0.02382219 0.98781767 0.11934664]]np.random.randn(x, y)
표준 정규 분포로부터 난수를 생성한다.
a = np.random.randn(2, 3)
>>> [[-0.01954151 -0.22706278 -1.18352446]
[-1.54670661 0.55022597 -0.23290721]]데이터 유형 지정
기본적으로 결정되는 데이터 유형은 부동 소수점(np.float64)이지만, 원하는 데이터 유형을 명시할 수 있다.
x = np.ones(2, dtype=np.int64)
x = ([1, 1])
>>> 1이라는 요소 두개를 포함하는 배열을 만드는데, 데이터 유형을 dtype = int64(정수)로 정해주고 있다.배열 요소 추가, 제거 및 정렬
np.sort()
요소를 정렬하는 함수로, 오름차순으로 빠르게 정렬한다.
그러나 이는 원본을 변경하는 것이 아닌, 정렬된 배열을 복제하여 반환한다(원본 유지)
arr = np.array([2,1,5,3,7,4,6,8])
np.sort(arr)
arr = ([1, 2, 3, 4, 5, 6, 7, 8])- argsort, lexsort, searchsorted, paririon 등의 옵셔널한 선택지가 있으며
기능, 안정성 등 적재적소에 사용하면 좋을 듯 하다.
https://numpy.org/doc/stable/reference/generated/numpy.argsort.html#numpy.argsort
np.concatenate()
배열을 정렬하는 함수
a = np.array([1,2,3,4])
b = np.array([5,6,7,8])
np.concatenate((a,b))
>>> array([1,2,3,4,5,6,7,8)]
x = np.array([[1, 2], [3, 4]])
y = np.array([[5, 6]])
np.concatenate((x,y), axis=0)
>>> array( [[1, 2], [3, 4], [5,7]] )ndarray.ndium
배열의 축 또는 차원수를 알려줌.
ndarray.size
배열의 총 요소수를 알려줌
ndarray.shape
배열의 각 차원에 따라 저장된 요소 수를 나타내는 정수 튜플을 반환함.
array_example = np.array([[[0, 1, 2, 3],
[4, 5, 6, 7]],
[[0, 1, 2, 3],
[4, 5, 6, 7]],
[[0 ,1 ,2, 3],
[4, 5, 6, 7]]])
array_example.ndim >>> 3 (축의 개수가 3, 즉 3차원 배열이다)
array_example.size >>> 24 (총 24개의 요소가 있음을 의미한다)
array_example.shape >>> (3, 2, 4) 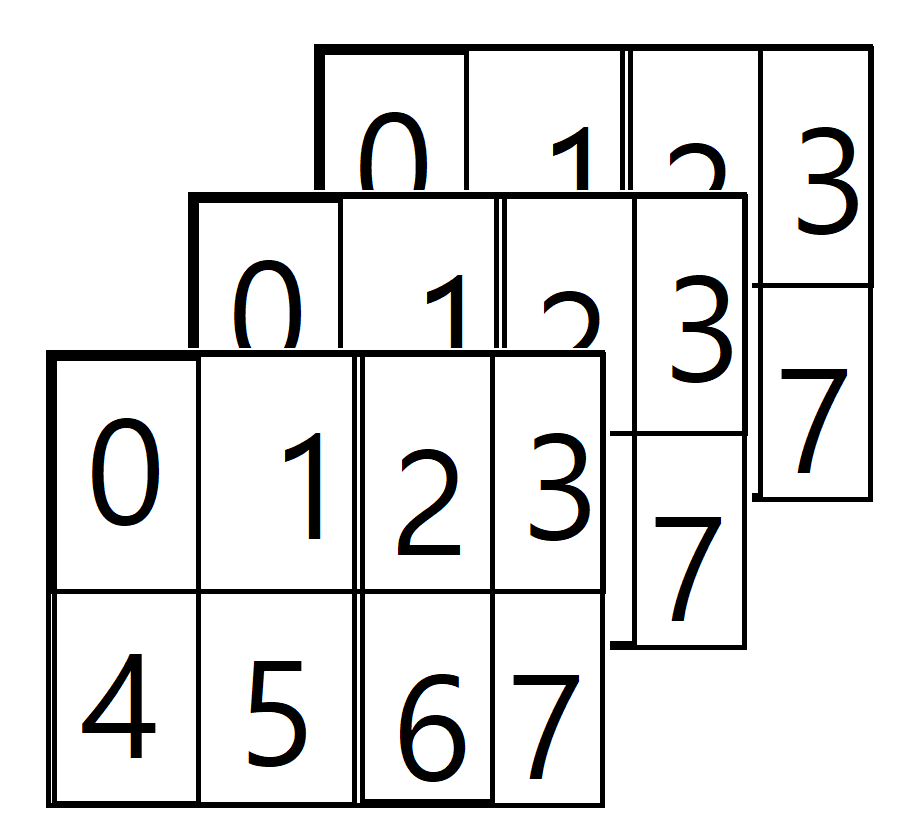
array_example.reshape()
배열을 재구성하는 함수
a = np.arange(6)
>>> a = [0 1 2 3 4 5]
b = a.reshape(3, 2)
>>> b = [[0 1], [2 3], [4 5]]np.reshape(a, newshape=(1, 6), order='C')
>>> ([[0, 1, 2, 3, 4, 5]])
* a = 재구성 할 배열
* newshape = 원하는 새로운 모양, 정수 또는 정수 튜플을 지정할 수 있으며 정수를 지정하면 결과는 해당 길이의 배열이다.
* order : c C와 같은 인덱스 순서를 사용하여 요소를 읽고 쓴다는 의미
'C'는 C 스타일의 로우 마지막 저장 순서를 의미하며, 'F'는 포트란 스타일의 컬럼 마지막 저장 순서를 의미한다.배열에 새 축을 추가하는 방법
np.newaxis
a = np.array([1, 2, 3, 4, 5, 6])
a.shape >>> (6,)
a2 = a[np.newaxis, :]
a2 = [[1,2,3,4,5,6]]
a2.shape >>> (1, 6)np.expand_dims
a = np.array([1, 2, 3, 4, 5, 6])
a.shape >>> (6,)
b = np.expand_dims(a, axis=1)
b.shape >>> (6, 1)
c = np.expand_dims(a, axis=0)
c.shape >>> (1, 6)인덱싱 및 슬라이싱
Python과 동일한 방식으로 인덱싱 ,슬라이싱 할 수 있다.

배열에서 특정 조건을 충족하는 값 선택하기
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
print(a[a>5])
>>> [6, 7, 8, 9, 10, 11, 12]
five_down = (a <= 5)
print(a[five_down])
>>> [1, 2, 3, 4, 5]
divisible_by_2 = a[a%2==0]
print(divisible_by_2)
>>> [ 2 4 6 8 10 12]
c = a[(a > 2) & (a < 11)] * & 또는 | 연산자를 이용하여 조건을 줄 수 있음.
print(c)
[ 3 4 5 6 7 8 9 10]
five_up = (a > 5) | (a == 5) *논리 연산자를 이용해서, 특정 조건이 충족되는지 부울 값으로 반환된다.
print(five_up)
[[False False False False]
[ True True True True]
[ True True True True]]기존 데이터에서 배열 만들기
np.vstac, nphstac
수직(vertical) 및 수평(horizontal)으로 두 개의 기존 어레이 쌓기
a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
arr1 = a[3:8]
>>> arr1 = [4, 5, 6, 7, 8]
a1 = np.array([[1, 1],
[2, 2]])
a2 = np.array([[3, 3],
[4, 4]])
np.vstack((a1, a2))
>>> [[1, 1],
[2, 2],
[3, 3],
[4, 4]]
np.hstack((a1, a2))
>>> [[1, 1, 3, 3], [2, 2, 4, 4]]np.hsplit(arr, indices or sections)
배열을 여러개로 분할하기
- arr : 나눌 배열을 의미함.
- indices or sections : 나눌 위치를 나타내는 정수 및 1차원 배열
정수 : 배열이 정수 만큼 나눠진다
1차원 배열: 배열이 지정된 위치에서 나눠진다
x = np.arange(1, 25).reshape(2, 12)
* [1, 2, 3, ... ,23, 24]의 array를 2행 12열로 만들어야 하므로
>>>
[[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]]
np.hsplit(x, 3) *3개의 동일한 모양의 배열로 분할하기.
[array([[ 1, 2, 3, 4],
[13, 14, 15, 16]]), array([[ 5, 6, 7, 8],
[17, 18, 19, 20]]), array([[ 9, 10, 11, 12],
[21, 22, 23, 24]])]출처 : https://numpy.org/doc/stable/user/absolute_beginners.html
