##자바, JVM, JDK, JRE
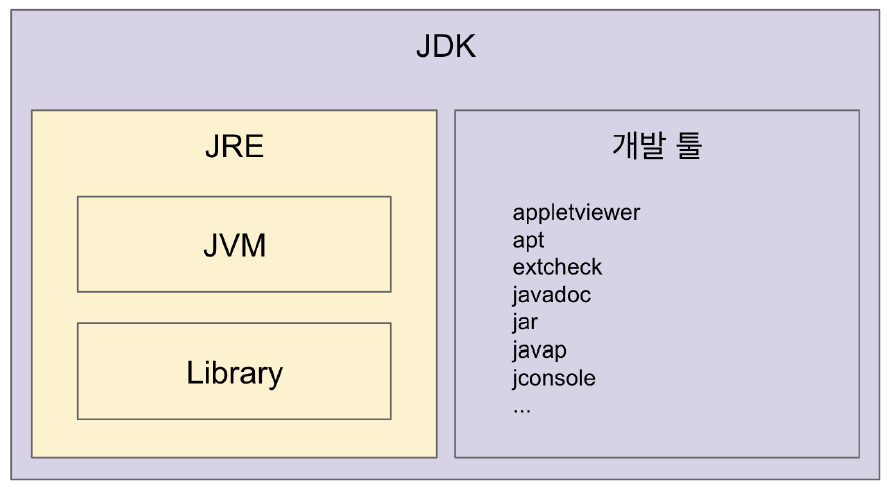
- JVM (Java Virtual Machine)
- 자바 가상 머신으로 자바 바이트 코드(.class 파일)를 OS에 특화된 코드로
변환(인터프리터와 JIT 컴파일러)하여 실행한다. - 바이트 코드를 실행하는 표준(JVM 자체는 표준)이자 구현체(특정 밴더가 구현한 JVM)다.
- JVM 밴더: 오라클, 아마존, Azul, ...
- 특정 플랫폼에 종속적.
- JVM언어 : 클로저, 그루비, JRuby, Jython, Kotlin, Scala, ...
- 자바 가상 머신으로 자바 바이트 코드(.class 파일)를 OS에 특화된 코드로
- JRE (Java Runtime Environment)
- JVM + 라이브러리
- 자바 애플리케이션을 실행할 수 있도록 구성된 배포판.
- JVM과 핵심 라이브러리 및 자바 런타임 환경에서 사용하는 프로퍼티 세팅이나 리소스파일을 가지고 있다.
- 개발 관련 도구는 포함하지 않는다. (그건 JDK에서 제공)
- JDK (Java Development Kit)
- JRE + 개발에 필요할 툴
- 자바컴파일(Javac)이 들어있다.
- 소스 코드를 작성할 때 사용하는 자바 언어는 플랫폼에 독립적.
- 오라클은 자바 11부터는 JDK만 제공하며 JRE를 따로 제공하지 않는다.
- Write Once Run Anywhere
- 자바
- 프로그래밍 언어
- JDK에 들어있는 자바 컴파일러(javac)를 사용하여 바이트코드(.class 파일)로 컴파일 할 수 있다.
- 자바 유료화? 오라클에서 만든 Oracle JDK 11 버전부터 상용으로 사용할 때 유료.
##JVM있는 이유
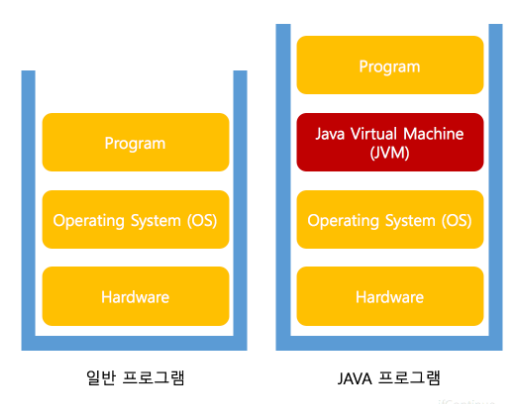
- 일반 프로그램
- 프로그램이 실행되기 위해서 OS가 제어하고 있는 시스템의 RAM(주기억장치 : 시스템의 리소스의 일부인 메모리)을 제어할 수 있어야 한다.
- 그래서, C같은 언어로 만들어진 프로그램은 이러한 이유 등으로 OS에 종속되어 실행된다.
- 자바 프로그램
- OS가 JVM에게 메모리 사용 권한을 주고, JVM이 자바 프로그램을 호출하여 실행
- 자바 프로그램은 OS가 아닌 JVM에 종속적이게 된다
##JVM 구조
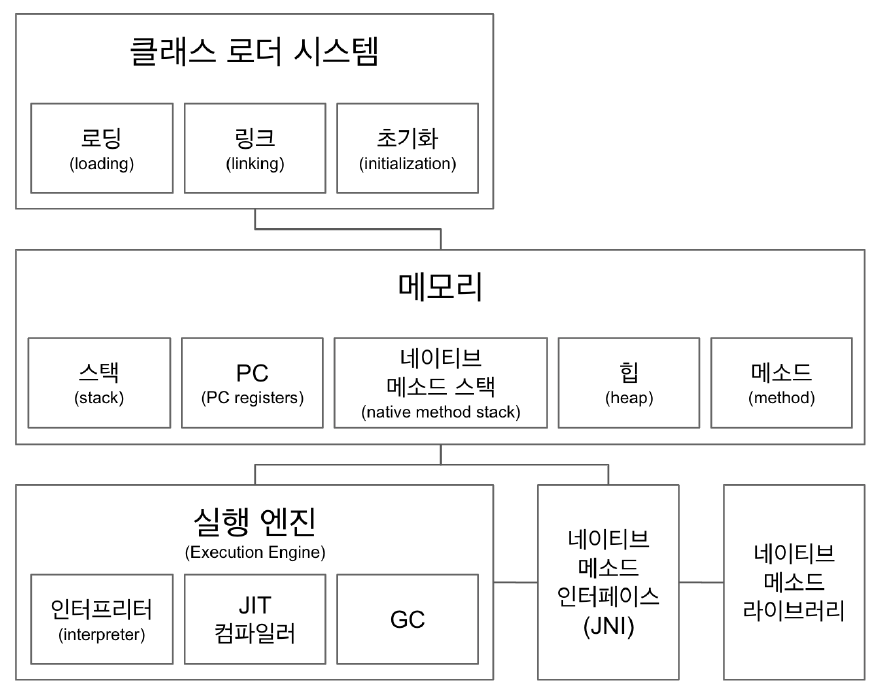
-
클래스 로더 시스템
- .class 에서 바이트코드를 읽고 메모리에 저장
- 로딩: 클래스 읽어오는 과정
- 링크: 레퍼런스를 연결하는 과정
- 초기화: static 값들 초기화 및 변수에 할당
-
메모리
- 메모리 영역에는 클래스 수준의 정보 (클래스 이름, 부모 클래스 이름, 메소드, 변수) 저장.
공유 자원이다. - 힙 영역에는 객체를 저장. 공유 자원이다.
- 스택 영역에는 쓰레드 마다 런타임 스택을 만들고, 그 안에 메소드 호출을 스택프레임이라
부르는 블럭으로 쌓는다. 쓰레드 종료하면 런타임 스택도 사라진다. - PC(Program Counter) 레지스터: 쓰레드 마다 쓰레드 내 현재 실행할 스택 프레임을
가리키는 포인터가 생성된다. - 네이티브 메소드 스택
- 메모리 영역에는 클래스 수준의 정보 (클래스 이름, 부모 클래스 이름, 메소드, 변수) 저장.
-
실행 엔진
- 인터프리터: 바이크 코드를 한줄 씩 실행.
- JIT 컴파일러(just-in-time): 인터프리터 효율을 높이기 위해, 인터프리터가 반복되는 코드를 발견하면 JIT 컴파일러로 반복되는 코드를 모두 네이티브 코드로 바꿔둔다. 그 다음부터
인터프리터는 네이티브 코드로 컴파일된 코드를 바로 사용한다. - GC(Garbage Collector): 더이상 참조되지 않는 객체를 모아서 정리한다.
-
JNI(Java Native Interface)
- 자바 애플리케이션에서 C, C++, 어셈블리로 작성된 함수를 사용할 수 있는 방법 제공
- Native 키워드를 사용한 메소드 호출
-
네이티브 메소드 라이브러리
- C, C++로 작성 된 라이브러리
## 클래스로더 시스템
- 로딩 → 링크 → 초기화 순으로 진행
- Class Loader : JVM 내로 .class 파일들을 로드하여 *Runtime Data Areas에 배치한다.
**Runtime Data Area
- JVM이라는 프로세스가 프로그램을 수행하기 위해 OS에서 할당 받은 메모리 공간이다.
#로딩
- ClassLoader를 알아야 하는 이유?
WAS에 내가 만든 웹앱이 올라가는 경우가 있다. *Tomcat에 war 파일 형태로 서비스를
제공할 경우라던가.
- 이 경우 메인 메소드는 웹앱 서버 (WAS)가 통제하고, 내 애플리케이션이 메인 메소드
내에서 실행되는 구조.
배포한 뒤, 코드를 수정해서 재배포해야 하는 경우가 생겼다고 가정하자. 클래스로더로 클
래스를 메모리에 올리고 나면, 클래스 정보를 지우는 방법이 따로 없다. 프로그램을 종료
하는 방법 외에는.
클래스를 변경했을 때, 변경된 클래스가 적용되도록 하려면?
- User Defined Class Loader가 필요하다. ex) Tomcat ClassLoader 구조
특히 상위 클래스로더에서 읽어들인 클래스일수록, 나중에 클래스를 변경하기 어렵다.
**Tomcat에 war 파일 형태로 서비스를 제공할 경우란?
-
WAR(Web Application Archive)이란
- 배경 :
- jar, war 모두 어플리케이션 소스들을 배포할 시에 path 등의 설정으로 인한 이슈를 제거하기 위해 탄생한 압축방식이다.
- 이 압축방식들은 압축의 해제없이 JDK에서 각 파일들을 접근하여 사용할 수 있도록 설계되었다.
- 웹 어플리케이션을 지원하기 위해서 war 압축방식은 jsp, servlet, gif, html, jar 등을 압축하고 지원한다.
- war는 웹 프로젝트에서 배포를 위한 최소한의 단위이다.
- war는 단독으로 실행이 안되며서버컨테이너 WAS에 의해 실행되어야 하므로배포에 대한 메타 정보(웹 프로젝트에 대한 설정 정보)가 담겨져 있다.
- 따라서 배포서술자(DD, Deploy Description)를 의미하는 web.xml이 포함되어 있다.
- 서버에서는 배포 서술자 정보를 읽어 컨텍스트를 생성한다.
- 컨텍스트는 기본적으로 war 파일명과 동일한 이름으로 생성되고사용자가 웹 디렉터리에 있는 자원에 접근할 수 있게 한다.
- 배경 :
-
Tomcat에 war 파일 형태로 서비스를 제공할 경우란?
작성한 코드에 대한 웹 어플리케이션(Web Application) 압축 파일을 톰캣 폴더에 추가만 해주면 톰캣이 알아서 웹 어플리케이션을 쉽게 배포하고 테스트한다.
- WAR파일을 쓰는 이유
FTP로 올릴 때 압축해서 올리면 압축을 일일이 해제해야 하는데, WAR 파일로 올리면 개발 서버의 경우 Tomcat이 알아서 압축을 해제해서 배포해주기 때문이다.
- JAR ( Java Archive )이란?
- .jar 확장자 파일에는 Class와 같은 Java 리소스와 속성 파일, 라이브러리 및 액세서리 파일이 포함되어 있습니다.
- 쉽게 JAVA 어플리케이션이 동작할 수 있도록 자바 프로젝트를 압축한 파일로 생각하시면 되겠네요. 실제로 JAR 파일은 플랫폼에 귀속되는 점만 제외하면 WIN ZIP파일과 동일한 구조입니다.
- JAR 파일은 원하는 구조로 구성이 가능하며 JDK(Java Development Kit)에 포함하고 있는 JRE(Java Runtime Environment)만 가지고도 실행이 가능합니다.
- JAR vs WAR
- jar는 실행될 클래스(main)를 명시하며 JVM위에서 단독으로 수행이 가능하다.
- war파일은 단독으로 실행할 수 없고, 서버 컨테이너에 의해서 실행되므로배포에 대한 메타 정보가 담겨 있다.
- 만들어진 목적이 다르다.
- jar : 자바 클래스 파일들이 주이며, *EJB 파일들을 포함한다.
- war : 웹 어플리케이션에 관련된 파일들을 포함한다. (jsp, servlet 파일들)
클래스 파일을 압축 : jar
웹 어플리케이션을 통째로 압축 : war
**EJB
엔터프라이즈 자바빈즈(Enterprise JavaBeans; EJB)는 기업환경의 시스템을 구현하기 위한 서버측 컴포넌트 모델이다. 즉, EJB는 애플리케이션의 업무 로직을 가지고 있는 서버 애플리케이션이다.
**WEB서버 역할
- 로드밸런싱
- 웹서버를 활용하여 여러 WAS를 운영
- 정적 컨텐츠 지원
**WEB서버와 WAS를 분리하는 이유
- 기능을 분리하여 서버 부하를 방지한다.
- 물리적으로 분리하여 보안을 강화한다.
- WEB서버를 WAS 앞단에 배치해서 리소스를 안전하게 보호할 수 있다.
- WEB서버에 여러대의 WAS를 연결할 수 있다.
- 로드밸런싱의 역할 및 fail over, fail back 처리에 유리
- 여러 WEB Application을 서비스할 수있다.
- Java 서버, PHP 서버와 같이 서로 다른 서버를 하나의 WEB서버에 연결해서 서비스 할 수 있다.
**nginx 역할
- 정적 파일을 처리하는 HTTP 서버로서의 역할
- WAS에 요청을 보내는 리버스 프록시로서의 역할
- 리버스 프록시 : 외부 클라이언트 → 서버로 접근 시, 내부 서버로 접근할 수 있도록 도와주는 서버(중간에서 중개자 역할)
- 리버스 프록시 장점 :
- 보안 : 외부 사용자로부터 내부망에 있는 서버의 존재를 숨길 수 있다. 또한 Nginx는 SSL 설정도 가능
- 로드밸런싱
/*
**웹서버, WAS 사이 커넥션은 어떻게 되는지??
Tomcat은 connector interface를 제공한다.
- connector는 engine으로 들어 오는 요청(request)를 처리하는 역할을 한다.
Tomcat은 "HTTP/1.1", "AJP/1.3", SSL 등의 protocol을 처리하는 다양한 connector를 제공
** AJP 란?
- AJP는 웹서버(Apache) 뒤에 있는 WAS로부터 웹서버로 들어오늘 요청을 위임할 수 있는 바이너리 프로토콜이다.
- 어플리케이션 서버로 핑을 할 수 있는 웹서버의 모니터링 기능을 지원한다.
- 대체로 AJP를 여러 웹서버에서 여러개 WAS로의 로드 밸런스 구현에 이용한다. 세션들의 각각의 WAS객체의 이름을 갖는 라우팅 메카니즘을 사용하는 현재 WAS로 리다이렉트된다. 이 경우 웹서버는 WAS를 위해 리버스 프록시로 동작한다.
**바이너리 프로토콜
: 바이너리 프로토콜은 IRC, SMTP 또는 HTTP / 1.1과 같은 일반 텍스트 프로토콜과 달리 사람이 아닌 컴퓨터에서 읽을 수있는 프로토콜입니다.
** mod_jk 란?
아파치, 톰캣 연동을 위해 mod_jk라는 모듈을 사용하는데, 이는 AJP프로토콜을 사용하여 톰캣과 연동하기 위해 만들어진 모듈이다. mod_jk는 톰캣의 일부로 배포되지만, 아파치 웹서버에 설치하여야 한다.
동작방식
-
아파치 웹서버의 httpd.conf에 톰캣 연동을 위한 설정을 추가하고 톰캣에서 처리할 요청을 지정한다.
-
사용자의 브라우저는 아파치 웹서버(보통 포트80)에 접속해 요청한다.
-
아파치 웹서버는 사용자의 요청이 톰캣에서 처리하도록 지정된 요청인지 확인 후, 톰캣에서 처리해야 하는 경우 아파치 웹서버는 톰캣의 AJP포트(보통 8009포트)에 접속해 요청을 전달한다.(HTTP/1.1방식으로 전달?)
-
톰캣은 아파치 웹서버로부터 요청을 받아 처리한 후, 처리 결과를 아파치 웹서버에 되돌려 준다.(HTTP/1.1방식으로 돌려줌?)
-
아파치 웹서버는 톰캣으로부터 받은 처리 결과를 사용자에게 전송한다.
*/
- 클래스로딩 과정
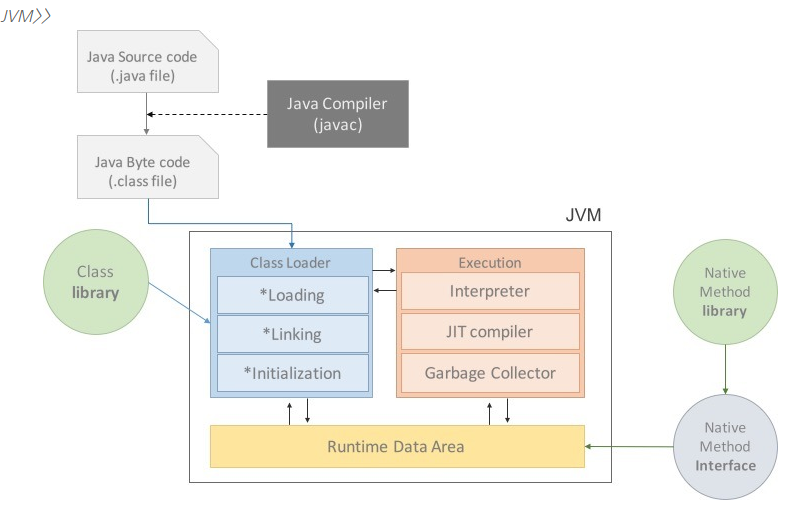
-
Java에서 클래스가 로딩 과정은 클래스 로더(Class Loader)가 확장자가 .class 클래스
파일의 위치를 찾아 그것을 JVM위에 올려놓는 과정을 뜻합니다. -
여기서 중요한 것은 우리가 만든 .class 확장자를 가진 클래스 파일을 로딩하기 전에 JVM
을 실행할 때 이미 JVM을 실행하기 위해서 여러 클래스 파일들을 미리 로딩했다는 것입
니다. -
동작과정
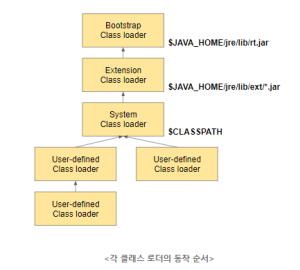
- 부트스트랩 클래스 로더(Bootstrap Class Loader)
- 위에 $JAVA_HOME/jre/lib/rt.jar 에서 rt.jar에 있는 JVM을 실행시키기 위한 핵심 클래스들을 로딩합니다.
- 최상위 클래스로서 <JAVA_HOME>/jre/lib에 담긴 자바 라이브러리를 로딩한다. Native C로 구현되어 있다.
- 확장 클래스 로더(Extenstion Class Loader)
- $JAVA_HOME/jre/lib/ext 경로에 위치해 있는 자바의 확장 클래스들을 로딩하는 역할을 합니다.
- 자바 언어로 작성된 자바 클래스다.
- 시스템 클래스 로더(System Class Loader)
- $CLASSPATH에 설정된 경로를 탐색하여 그곳에 있는 클래스들을 로딩하는 역할을 합니다. 개발자가 직접 작성한 .class 확장자 파일을 로딩합니다.
- 자바 언어로 작성된 자바 클래스다.
- 부트스트랩 클래스 로더(Bootstrap Class Loader)
-
클래스 로더들은 계층적 구조를 가지도록 생성이 가능하고 각 부모 클래스 클래스 로더에서 자식 클래스 로더를 가지는 형태로 클래스 로더를 만들 수 있습니다.
- 구조 : Bootstrap <- Extention <- System <- User-defined
-
클래스로더 특징
-
계층적 구조(Hierarchical) : 클래스 로더들은 부모-자식 관계의 계층적 구조를 가지고 있습니다.
-
로딩 요청 위임(Delegate Load Request)
-
예를 들어 System Loader가 A라는 클래스를 로딩할 때 그 로딩 요청은 부모 로더들로 거슬러 올라가서 부트스트랩 로더에 다다른 후
그 밑으로 로딩 요청을 수행한다는 것을 의미합니다. -
System loader =>(위임) Extension Class Loader =>(위임) Bootstrap Loader
Bootstrap Loader에서 클래스를 못 찾았을 시 => Extension Class Loader
Extension Class Loader에서 클래스를 못 찾았을 시 => System Loader
System Loader에서 클래스를 못 찾았을 시 => ClassNotFoundException -
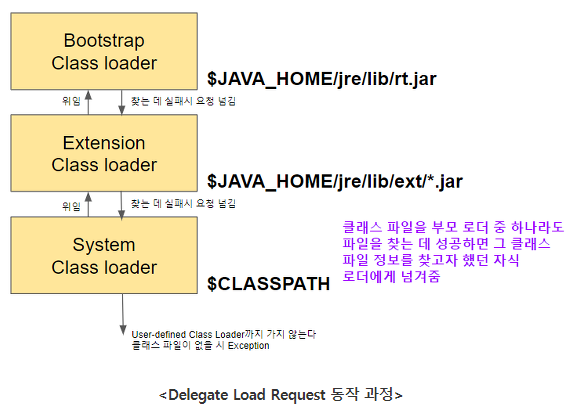
-
-
가시성 제약 조건(Have Visibility Constraint )
- 부모 로더에서 찾지 못한 클래스는 자식 로더에서도 못찾음. 하지만 반대로 자식로더에서 찾지 못한 클래스는 부모 로더에게 위임해서 찾을 수 있다.
-
언로드 불가(Cannot unload classes)
- 클래스 로더에 의해 로딩된 클래스들은 다시 JVM상에서 없앨 수 없습니다.(프로그램을 종료 하는 방법 외에는.)
-
-
네트워크를 통해 전달받은 바이트 코드를 JVM에 로드하는 등의 유즈케이스가 있다면 ClassLoader를 상속받아 사용자 정의 클래스 로더를 직접 구현할 수 도 있다.
#링크 (Linking)
- 링크 작업은 3단계로 이뤄진다.
- Verify → Prepare → Resolve
- 예시) book이라는 참조변수가 Heap에 저장된 실제 Book 클래스를 가리킬 수 있도록 연결하는 게 Resolve 과정
Book book = new Book();Verify
- .class 형식 파일이 유효한지 확인. 바이트코드가 조작될 경우 JVM 에러 발생.
Prepare
- 메모리 준비 과정. 클래스의 static변수, 기본값에 필요한 메모리를 준비
Resolve
- Symbolic Memory Reference를 실제 Reference로 교체 (Optional 과정)
- Class 파일은 실행 시 Link를 할 수 있도록 Symbolic Reference 만을 가지고 있다.
#초기화 (Initialization)
- static으로 선언된 변수와 메소드에 메모리를 할당, 초기값을 채우는 과정.
- 링크에서 Prepare 단계에서 확보한 메모리 영역에 클래스의 static 값들을 할당한다.
- ex) 코드가 클래스에 있다면, 여기서 초기화된다.
static final String name = "staticName";**static 변수, 메소드
-
static변수
- 같은 곳의 메모리 주소만을 바라봄 → static변수의 값 공유가능
- 일반변수 vs static변수
- 일반변수 : 인스턴스를 생성 → 각 인스턴스들은 서로 다른 메모리들의 주소를 할당 받음(서로 다른 값을 유지)
- static변수 : 공통적인 값 유지
-
static 메소드
-
객체의 생성 없이 호출가능, 객체에서는 호출 불가능
class Test { Test () {} static void m1 () {} void m2 () {} } //객체의 생성 없이 호출가능 Test.m1() // O Test.m2() // X //객체에서는 호출 불가능 Test test = new Test() test.m1() // X test.m2() // O- 공통적으로 사용해야할 메서드가 있을때 → static 메서드로 불필요한 코드의 수를 줄인다.
-
메소드가 공유된다.
-
메소드가 변화되지 않고, 오버라이딩 되지 않는다.
##메모리
Runtime Data Area : JVM이라는 프로세스가 프로그램을 수행하기 위해 OS에서 할당 받은 메모리 공간이다.
- Heap
- new 명령으로 생성한 인스턴스가 놓인다.
- 즉 인스턴스 필드가 이 영역에 생성된다.
- 가비지 컬렉터는 이 메모리의 가비지들을 관리한다.
- JVM Stack
- 각 스레드가 개인적으로 관리하는 메모리 영역이다.
- 스레드에서 메서드를 호출할 때 메서드의 로컬 변수를 이 영역에 만든다.
- 메서드가 호출될 때 그 메서드가 사용하는 로컬 변수를 프레임에 담아 만든다.
- 메서드 호출이 끝나면 그 메서드가 소유한 프레임이 삭제된다.
- Method Area
- JVM이 실행하는 바이트코드(.class 파일)를 두는 메모리 영역이다.
- 클래스 로더가 .class 파일을 읽고, 그 내용에 따라 적절한 바이너리 데이터를 만들고, Method 영역에 저장한다.
- Method 영역에 저장하는 데이터
- Type 정보 (클래스, 인터페이스, Enum)
- 메소드와 변수
- FQCN (Fully Qualified Class Name)
- 클래스가 속한 패키지명을 모두 포함한 이름을 말한다.
- *ex) java.lang.String s = new java.lang.String();
- JVM은 코드를 실행할 때 이 영역에 놓은 명령어를 실행하는 것이다.
- 개발자가 작성한 클래스, 메서드 등의 코드들이 이 영역에 놓이는 것이다.
- 주의! Heap에는 개발자가 작성한 명령어가 없다.
- 로딩이 끝나면 해당 Class Type의 Class 객체를 생성하여 힙 영역에 저장한다.
- static 필드를 이 영역에 생성한다
- 네이티브 메소드 스택
- Java 외의 언어로 작성된 코드(Native Code, JNI로 실행되는 코드)를 위한 Stack 영역이다. 각 언어에 맞는 Stack이 생성된다
**String은 java.lang.String을 안써도 읽을 수 있는 이유
- import java.lang.*; 패키지를 따로 코딩하지 않아도 JVM은 import된 것으로 인식
**똑같은 Class이름이 둘의 패키지에 있을때 컴파일에러가 어떻게 날까?
import com.util1.*;
import com.util2.*;
class Main{
public static void main (String[] args) {
Test test=new Test();
}
}에러 :
java: reference to Test is ambiguous
both class com.util2.Test in com.util2 and class com.util1.Test in com.util1 match##자바 소스파일이 컴퓨터에 읽히는 과정
- JDK 에서 > 컴파일러(javac)에 의해 소스파일(.java)이 JVM(가상머신)이 이해할 수 있는 *바이트코드(.class)로 변환됨
- .java → .class(바이트코드)
- JVM에서 > JIT컴파일러를 통해서 *바이너리코드(기계어)로 번역
- .class → 기계어(바이너리코드)
**바이트코드(.class)
- JVM(가상머신)이 이해할 수 있는 코드
- 어떤 플랫폼에도 종속X
- 컴퓨터가 바로 인식하지 못함
**바이너리코드(기계어)
- 컴퓨터가 인식할 수 있는 0,1로 된 코드
##GC(Garbage Collector)
1. 개념
- JAVA에서 객체가 생성되면 해당 객체는 JVM의 Heap영역의 메모리를 점유 한다.
- 메모리 공간이 부족해져 결국 Out Of Memory Error 가 발생 할 수 밖에 없다.
- JAVA는 JVM을 통하여 구동된다.
- JAVA의 특징 중 하나로 메모리 관리를 개발자가 직접 명시적으로 수행하지 않고,
JVM에서 자동으로 수행해 주며, 이와 같은 역할을 하는 프로세스를 Garbage Collector(GC)라 한다.
2. JAVA에서 GC의 도입의 전제 가설
-
대부분의 객체는 금방 접근 불가능 상태 (unreachable)가 된다.
-
10,000 건의 NewObject 객체는 Loop 내에서 생성되고, 사용되지만 Loop 밖에서
는 더이상 사용할 일이 없어진다. 이런 객체들이 메모리를 계속 점유하고 있다면, 다
른 코드를 실행하기 위한 메모리 자원은 지속적으로 줄어들기만 할 것이다.
for (int i = 0; i < 10000; i++) { NewObject obj = new NewObject(); obj.doSomething(); }
-
-
오래된 객체에서 젊은 객체로의 참조는 아주 적게 존재
-
보통 어떤 값이나 상태를 저장하기 위해 POJO 객체를 생성하고, 다른 메소드나 클래
스에 전달하고, 다 사용한 객체는 더이상 사용하지 않는다. 경우에 따라 오래도록 살
아남아 재활용 되는 케이스가 있긴하지만, 대부분의 경우`는 아닐 것이다.
Model model = new Model("value"); doSomething(model); // 더이상 model 을 사용하지 않음
-
**'Call by value'와 'Call by reference'의 차이
- Call by value(값에 의한 호출)
: Call by value는 메서드 호출 시에 사용되는 인자의 메모리에 저장되어 있는 값(value)을 복사하여 보낸다
Class CallByValue{
public static void swap(int x, int y) {
int temp = x;
x = y;
y = temp;
}
public static void main(String[] args) {
int a = 10;
int b = 20;
System.out.println("swap() 호출 전 : a = " + a + ", b = " + b);
swap(a, b);
System.out.println("swap() 호출 후 : a = " + a + ", b = " + b);
}
}결과 :
swap() 호출 전 : a = 10, b = 20
swap() 호출 후 : a = 10, b = 20- Call by reference(참조에 의한 호출)
: Call by reference는 메서드 호출 시에 사용되는 인자가, 값이 아닌 주소(Address)를 넘겨줌으로써, 주소를 참조(Reference)하여 데이터를 변경할 수 있습니다.
Class CallByReference{
int value;
CallByReference(int value) {
this.value = value;
}
public static void swap(CallByReference x, CallByReference y) {
int temp = x.value;
x.value = y.value;
y.value = temp;
}
public static void main(String[] args) {
CallByReference a = new CallByReference(10);
CallByReference b = new CallByReference(20);
System.out.println("swap() 호출 전 : a = " + a.value + ", b = " + b.value);
swap(a, b);
System.out.println("swap() 호출 전 : a = " + a.value + ", b = " + b.value);
}
}결과 :
swap() 호출 전 : a = 10, b = 20
swap() 호출 후 : a = 20, b = 103. GC의 대상
GC는 힙 메모리를 정리하는 것이기 때문에 객체 레퍼런스 값 중에서 가비지를 찾아낸다.
Java GC는 객체가 가비지인지 판별하기 위해서 reachability라는 개념을 사용한다.
- 어떤 객체에 유효한 참조가 있으면 'reachable'로, 없으면 'unreachable'로 구별하고, unreachable 객체를 가비지로 간주해 GC를 수행한다.
String[] array = new String[2];
array[0] = '0';
array[1] = '1';
array = new String[] {'G', 'C' };위 코드에서 String 배열이 할당되기 전에 할당한 0과 1은 어디로 갔을까?
- 이렇게 주소를 잃어버려서 사용할 수 없는 메모리가 '정리되지 않은 메모리'이다.
- 프로그래밍 언어에서는 Danling Object, 자바에서는 Garbage라고 부른다.
- GC는 메모리가 부족할 때 이런 Garbage들을 메모리에서 해제 시켜 다른 용도로 사용 할 수 있게 해주는 프로그램을 말한다.
4. GC의 수행 영역별 구분
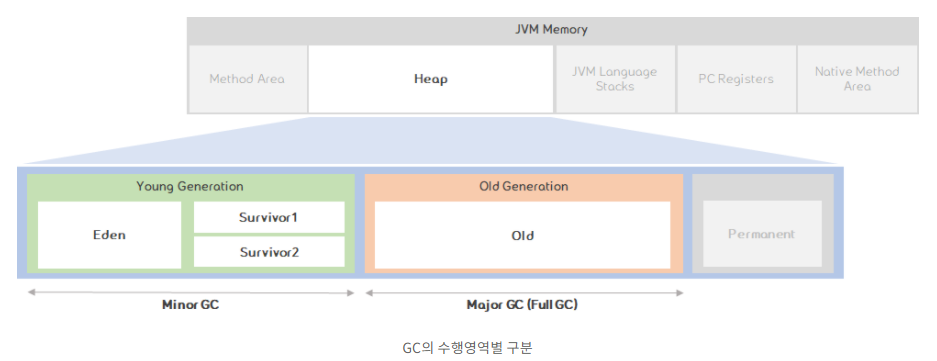
- GC는 크게 메이저GC와 마이너GC로 나눌 수 있습니다.
| GC | 영역 |
|---|---|
| Major GC | -Old, Perm 영역에서 발생하는 GC |
| Minor GC | -Young(Eden 및 Survivor 공간으로 구성됨)영역에서 발생하는 GC |
| Full GC | -Heap 전체를 clear 하는 작업 (Young/Old 공간 모두) |
5. GC 발생 시나리오
GC는 기본적으로 다음과 같은 시나리오로 동작한다.

객체가 생성되면 Eden 영역에 위치 하게 된다.
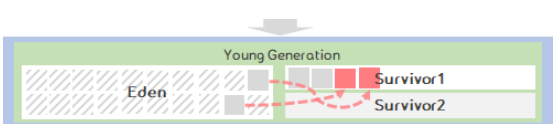
Eden영역이 가득차게 되면 Minor GC가 발생하여 참조가 없는 객체는 삭제되고, 참조 중인 객체는 Suvvivor 영역으로 이동한다.
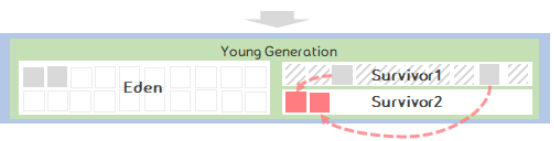
Survivor영역이 가득차게 되면 Minor GC가 발생하고 참조가 없는 객체는 삭제되고, 참조 중인 객체는 다른 Suvvivor 영역으로 이동한다.
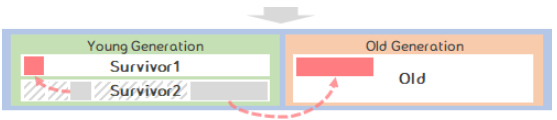
Survivor영역에서의 GC과정을 반복 하며, 계속 참조 중인 객체는 OLD 영역으로 이동한다.

Eden 영역에서 Survivor 영역으로 이동 할 때 객체가 남아있는 영역보다 큰 경우 OLD 영역으로 이동한다.
##GC 수행 방식에 따른 종류와 변화
**STW (Stop-The-World)
- GC가 발생하면 JVM은 어플리케이션을 멈추고**, GC**를 실행하는 쓰레드만 동작하게 되고 이를 Stop-The-World 라고 한다.
- STW가 발생하는 동안은 어플리케이션이 중지 되기 때문에 장애로 이어 질 수 있다.
- 메모리 영역이 크게 설정 되어 있으면, GC가 발생하는 횟수를 줄일 수 있지만, GC 수행 시간은 증가 하기 때문에 최적화 필요
- GC가 Young Generation 영역을 청소할 때(마이너 GC)는 이 4가지 종류에 상관없이 모두 stop-the-world 상태가 발생
1.Young 영역의 GC
- 객체가 생성되면 Eden 영역에 위치
- Eden영역이 가득차게 되면 Minor GC가 발생하여 참조가 없는 객체는 삭제되고, 참조 중인 객체는 Suvvivor 영역으로 이동
- Survivor영역이 가득차게 되면 Minor GC가 발생하고 참조가 없는 객체는 삭제되고, 참조 중인 객체는 다른 Suvvivor 영역으로 이동
- Survivor영역에서의 GC과정을 반복 하며, 계속 참조 중인 객체는 OLD 영역으로 이동
- Eden 영역에서 Survivor 영역으로 이동 할 때 객체가 남아있는 영역보다 큰 경우 OLD 영역으로 이동
2.Old 영역에 대한 GC
- Old 영역은 기본적으로 데이터가 가득 차면 GC를 실행한다.
- 방식
- Serial GC
- Parallel GC
- Parallel Old GC(Parallel Compacting GC)
- Concurrent Mark & Sweep GC(이하 CMS)
- G1(Garbage First) GC
1) Serial Garbage Collector
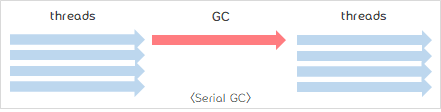
- 주로 32비트 JVM에서 돌아가는 싱글쓰레드 어플리케이션에서 사용 (별도로 지정하지 않는 경우 기본 GC)
- Minor GC 뿐 아니라 Major GC인 경우도 올스탑(stop-the-world)하는 싱글쓰레드 방식.
- 동작방식
- Young 영역에서의 GC는 앞 절에서 설명한 방식을 사용한다.
- Old 영역의 GC는 mark-sweep-compact이라는 알고리즘을 사용한다.
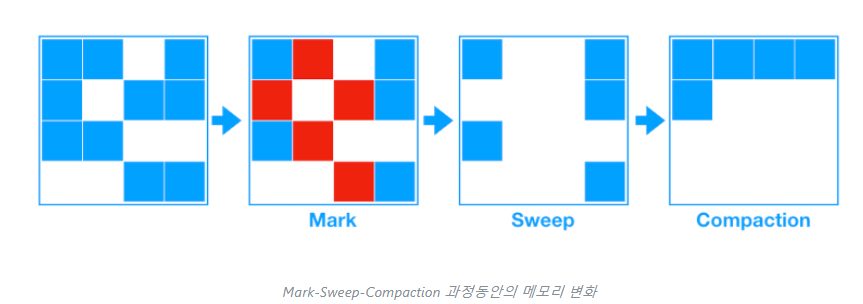
- 이 알고리즘의 첫 단계는 Old 영역에 살아 있는 객체를 식별(Mark)하는 것이다.
- 그 다음에는 힙(heap)의 앞 부분부터 확인하여 살아 있는 것만 남긴다(Sweep).
- 마지막 단계에서는 각 객체들이 연속되게 쌓이도록 힙의 가장 앞 부분부터 채워서 객체가 존재하는 부분과 객체가 없는 부분으로 나눈다(Compaction).
**Mark-Sweep-Compaction
- Mark - 가비지 수집기가 사용중인 메모리와 그렇지 않은 메모리를 식별하는 곳입니다.
- Sweep - 이 단계는 "마크"단계에서 식별 된 개체를 제거합니다.
- Compaction - 파편화된 메모리 영역을 앞에서부터 채워나가는 작업
2) Parallel Collector(=Throughput Collector)
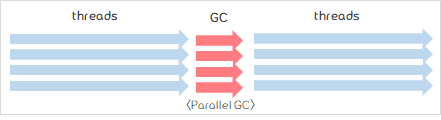
- 64비트 JVM이나 멀티CPU 유닉스 머신에서 기본 GC로 설정되어 있음.
- MinorGC와 MajorGC 모두 멀티쓰레드를 사용.
- MinorGC 뿐 아니라 Major GC인 경우도 올스탑(stop-the-world)
- 동작방식
- 시리얼 콜렉터 방식과 GC 알고리즘은 같다.(mark-sweep-compact 알고리즘)
- 하지만 단일 스레드가 GC를 수행하는 시리얼 콜렉터 방식과 달리, GC를 처리하는 스레드가 여러개이다
3) CMS Collector (Concurrent Mark-Sweep)

Serial GC와 CMS GC의 절차를 비교
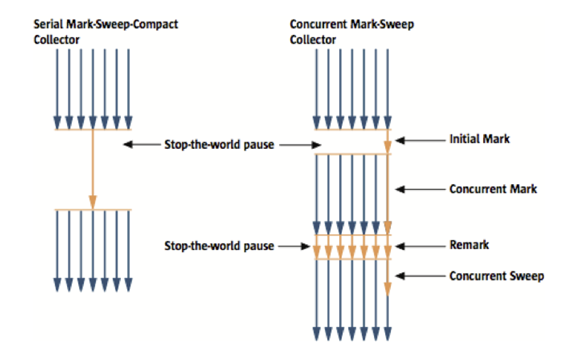
- 동작방식
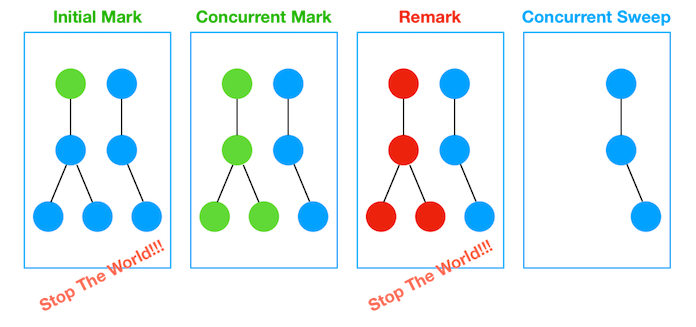
- 초기 Initial Mark 단계에서는 클래스 로더에서 가장 가까운 객체 중 살아 있는 객체만 찾는 것으로 끝낸다
- 멈추는 시간은 매우 짧다
- Stop and World
- Concurrent Mark 단계에서는 방금 살아있다고 확인한 객체에서 참조하고 있는 객체들을 따라가면서 확인한다.
- 다른 스레드가 실행 중인 상태에서 동시에 진행
- Remark 단계에서는 Concurrent Mark 단계에서 새로 추가되거나 참조가 끊긴 객체를 확인한다.
- Stop and World
- Concurrent Sweep 단계에서는 쓰레기를 정리하는 작업을 실행한다.
- 다른 스레드가 실행되고 있는 상황에서 진행
- 초기 Initial Mark 단계에서는 클래스 로더에서 가장 가까운 객체 중 살아 있는 객체만 찾는 것으로 끝낸다
- 특징
- GC 대상을 최대한 자세히 파악한 후, STW(Stop-The-World) 시간을 최소화 하는데 초점을 맞춘 GC 방식
- GC 대상을 파악하는 과정이 복잡한 여러단계로 수행되기 때문에 다른 GC 대비 CPU 사용량이 높다
- 어플리케이션이 작동하는 중에, 백그라운드에서 쓰레드를 만들어서 Old Generation 영역에 살고있는 쓸모없는(참조되지 않고있는) 객체들을 지속적으로 제거
- 모든 애플리케이션의 응답 속도가 매우 중요할 때 CMS GC를 사용하며, Low Latency GC라고도 부른다.
- 별도의 Compaction이 없음
- 장점
- stop-the-world 가 거의 없다
> 마이너GC에서 잠깐씩, 그리고 풀GC에서는 거의 발생하지 않음
- stop-the-world 가 거의 없다
- 단점
- CPU리소스를 많이 사용
- 메모리 파편화(중간 중간에 Old Generation에 있는 객체들을 쏙쏙 잡아먹으면 메모리가 군데군데 비어지기 때문)
**단편화(파편화)
: 단편화는 기억 장치의 빈 공간 또는 자료가 여러 개의 조각으로 나뉘는 현상을 말한다.
이 현상은 기억장치의 사용 가능한 공간을 줄이거나, 읽기와 쓰기의 수행속도를 늦추는 문제점을 야기한다.
4) G1 Collector (Garbage First)
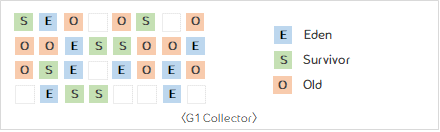
-
기존 Young, Old 영역의 개념과 다른 Heap에 Region개념을 도입함.
-
하나 이상의 Resion 에서 객체를 복사해 다른 Region으로 이동 시키는 방식.
-
CMS와 비슷한 방식으로 동작 시작. Heap에 전역적으로 Marking 하고, 가장 많은 공간이 있는 곳 부터 메모리 회수 진행. 이 부분 때문에 Garbage First 라는 이름이 붙었다.
-
CMS Collector의 메모리 파편화의 단점 해결.
-
동작방식
- Young GC 수행
- Young GC는 각 Region 중 GC대상 객체가 가장 많은 Region(Eden 또는 Survivor 역할)에서 수행 되며, 이 Region 에서 살아남은 객체를 다른 Region(Survivor 역할)으로 옮긴 후, 비워진 Region을 사용가능한 Region으로 돌리는 형태로 동작한다.
- STW(Stop-The-World) 현상이 발생
- STW 시간을 최대한 줄이기 위해 멀티스레드로 GC를 수행한다.
- Full GC 가 수행될 때는 Initial Mark -> Root Region Scan -> Concurrent Mark -> Remark -> Cleanup -> Copy 단계를 거치게된다.
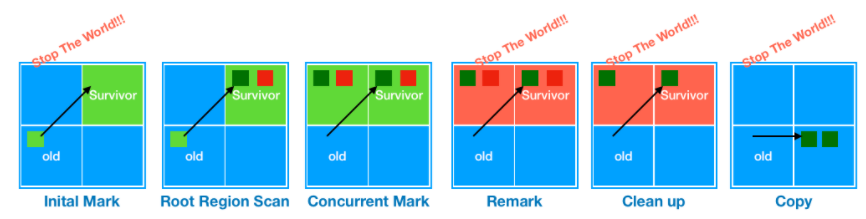
- Young GC 수행
-
- Initial Mark -Old Region 에 존재하는 객체들이 참조하는 Survivor Region을 찾는다.
- 이 과정에서는 STW 현상이 발생하게 된다.
- Root Region Scan -Initial Mark 에서 찾은 Survivor Region에 대한 GC 대상 객체 스캔 작업을 진행한다.
- Concurrent Mark -전체 힙의 Region에 대해 스캔 작업을 진행하며, GC 대상 객체가 발견되지 않은 Region 은 이후 단계를 처리하는데 제외되도록 한다.
- Remark - 애플리케이션을 멈추고(STW) 최종적으로 GC 대상에서 제외될 객체(살아남을 객체)를 식별해낸다.
- Cleanup - 애플리케이션을 멈추고(STW) 살아있는 객체가 가장 적은 Region 에 대한 미사용 객체 제거 수행한다. 이후 STW를 끝내고, 앞선 GC 과정에서 완전히 비워진 Region 을 Freelist에 추가하여 재사용될 수 있게 한다.
- Copy -GC 대상 Region이었지만 Cleanup 과정에서 완전히 비워지지 않은 Region의 살아남은 객체들을 새로운(Available/Unused) Region 에 복사하여 Compaction 작업을 수행한다.
- Initial Mark -Old Region 에 존재하는 객체들이 참조하는 Survivor Region을 찾는다.
##GC수행방식 비교
| GC 종류 | Serial Garbage Collector | Parallel Collector | CMS Collector | G1 Collector |
|---|---|---|---|---|
| 쓰레드 | 싱글쓰레드 방식 | 멀티쓰레드 | 멀티쓰레드 | 멀티쓰레드 |
| 동작방식(Old 영역) | mark - sweep - compact | mark - sweep - compact | Initial Mark - Concurrent Mark - Remark - Concurrent Sweep | initial Mark - Root Region Scan - Concurrent Mark -Remark - Cleanup - Copy |
| Stop and world 지점 | Mark Sweep compact | Mark Sweep compact | Initial Mark Remark | initial Mark Remark Cleanup Copy |
| 특징 | - Serial GC는 데스크톱의 CPU 코어가 하나만 있을 때 사용하기 위해서 만든 방식이다. -java 6에서 기본으로 설정 | - Serial GC보다 빠른게 객체를 처리할 수 있다. Parallel GC는 메모리가 충분하고 코어의 개수가 많을 때 유리하다. -java7,8에서 기본으로 설정 | -application thread 와 garbage collection thread 가 동시에 실행 > STW(Stop-The-World) 시간을 최소화 - GC 대상을 파악하는 과정이 복잡한 여러단계로 수행되기 때문에 다른 GC 대비 CPU 사용량이 높다 -별도의 Compaction이 없음 > 메모리 파편화 -java 9,10,11에서 기본으로 설정 | - 기존 Young, Old 영역의 개념과 다른 Heap에 Resion 개념을 도입 - 하나 이상의 Resion 에서 객체를 복사해 다른 Resion으로 이동 시키는 방식. - CMS와 비슷한 방식으로 동작 시작. Heap에 전역적으로 Marking 하고, 가장 많은 공간이 있는 곳 부터 메모리 회수 진행. 이 부분 때문에 Garbage First 라는 이름이 붙었다. -CMS Collector의 메모리 파편화의 단점 해결. -Java Heap 이 많이 필요한 경우 G1 를 사용하는 것이 유리 -Java 9는 G1 GC 를 기본으로 설정 |
##자바 버전별 GC
#Java 11
- Java 11에서 사용할 수 있는 GC:
- 직렬, 병렬, 가비지 우선(G1) 및 엡실론입니다.
- CMS(Concurrent Mark and Sweep) Java 9 이후에는 사용되지 않습니다.
- Java 11의 기본 GC :
- G1GC(가비지 우선 가비지 수집기)
\1. 엡실론(Epsilon: A No-Op Garbage Collector)
- Epsilon이라는 새 GC를 도입(아직 실험 단계)하였다.
- Epsilon은 오직 메모리 할당만 담당하고, 메모리 재배치는 하지 않는다.
- 힙이 소진되면 JVM이 종료됩니다
- Epsilon의 목적은 제한된 영역의 메모리 할당을 허용함으로써 최대한 latency
overhead를 줄이는 데에 있습니다 - 사용 용도는 퍼포먼스 테스팅과 매우 짧은 생명을 가진 application에 적용 가능하
다. - 엡실론 GC 사용 사례
- 성능 시험
- 메모리 압력 테스트
- VM 인터페이스 테스트
- 매우 짧은 수명의 일자리
- 마지막 드롭 대기 시간 개선
- 마지막 드롭 처리량 개선
**NOOP
컴퓨터 과학에서 NOP 또는 NOOP(No Operation)은 어셈블리어의 명령, 프로그래밍 언
어의 문, 컴퓨터 프로토콜 명령의 하나로, 아무 일도 하지 않는다.
+ZGC: A Scalable Low-Latency Garbage Collector
(확장 가능한 저 지연 가비지 수집기)
- 자바 쓰레드가 수행 중에 실행되는 concurrent garbage collector이다. (아직 실험 단계)
- 목표 :
- 대량의 메모리를 low-latency로 잘 처리하기 위해 디자인 된 GC 입니다
- 일시 중지 시간은 10ms를 초과하지 않습니다.
- 일시 중지 시간이 heap or live-set size에 따라 증가하지 않는다.
- 수백 메가 바이트에서 수 테라 바이트 크기의 힙 처리
- 이 실험 버전의 ZGC에는 다음과 같은 제한 사항이 있습니다.
- Linux / x64에서만 사용할 수 있습니다.
#Java 10
1) G1 GC
Java 9와 비교
- Java 9에서 G1 은 full GC를 피하도록 설계되었지만, concurrent GC에서 충분한
young area를 확보하지 못하면 full GC가 발생합니다. 기존 G1에서 full GC를 수행
할 때 싱글 쓰레드 방식으로 동작하는 mark-sweep-compact 알고리즘을 사용하였
습니다. - Java 10에서는 parallel collector 처럼 G1에서도 full GC를 병렬화 시켜 G1의 최악
의 케이스에서 지연 시간을 개선시켰습니다.
>> Java10은 G1에서 full GC를 처리할때, mark-sweep-compact 알고리즘을 병렬로
수행하도록 변경되었으며, 이 때 Young 과 Mixed GC와 동일한 쓰레드 수를 이용합니다.
#Java 8
PermGen to Metaspace (JDK 8부터 변경 사항)
1) Metaspace란 무엇일까
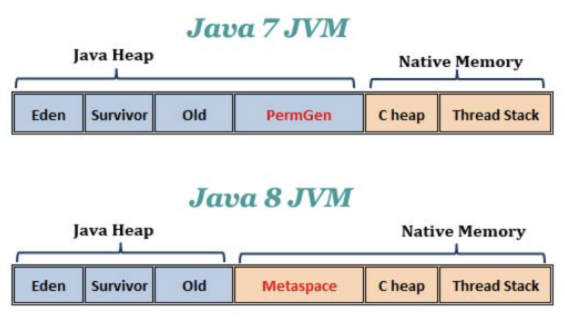
- Metaspace는 JDK8 이전의 Perm 영역을 대체하는 것으로 클래스와 메소드의 메타데이터들이 저장되는 영역임
- Metaspace는 native memory를 사용하기 때문에 힙 영역과는 별개의 영역에 할당됨
- native memory는 프로세스에 할당되는 메모리 영역으로 C 힙과 스레드 스택도 native memory를 사용함
**
**
2) 힙 영역이 기존에 New / Survive / Old / Perm / Native 에서 New / Survive / Old / Metaspace 로 변경
-
Java7 까지의 Permanent
- Class 의 Meta정보 (pkg path 정보라고 보면 됨, text 정보)
- Method의 Meta 정보
- Static Object
- 상수화된 String Object
- Class와 관련된 배열 객체 Meta 정보
- JVM 내부적인 객체들과 최적화컴파일러(JIT)의 최적화 정보
-
Java8 에서의 Metaspace과 Heap 분리
- Class 의 Meta정보 -> Metaspace 영역으로 이동
- Method의 Meta 정보 -> Metaspace 영역으로 이동
- Static Object -> Heap 영역으로 이동
- 상수화된 String Obejct -> Heap 영역으로 이동
- 클레스와 관련된 배열 객체 Meta 정보 -> Metaspace 영역으로 이동
- JVM 내부적인 객체들과 최적화컴파일러(JIT)의 최적화 정보 -> Metaspace 영역으로 이동
-
PermGen 영역에 저장되어 문제를 유발하던 Static Obect는 Heap 영역으로 옮겨서 최대한 GC 대상이 되도록 변경 되었습니다.
: Java 개발자라면 OutOfMemoryError: PermGen Space error이 발생했던것을 본적이 있을텐데 이는 Permanent Generation 영역이 꽉 찼을때 발생하고 Memory leak가 발생했을때 생기게 됩니다. Memory leak의 가장 흔한 이유중에 하나로 메모리에 로딩된 클래스와 클래스 로더가 종료될때 이것들이 가비지 컬렉션이 되지 않을때 발생합니다.
- 수정될 필요가 없는 정보만 Metaspace에 저장, Metaspace는 JVM이 필요에 따라서 리사이징할 수 있는 구조로 개선 되었습니다.
PermGen은 Java 8부터 Metaspace로 완벽하게 대체 되었고 Metaspace는 클래스 메타 데이터를 native 메모리에 저장하고 메모리가 부족할 경우 이를 자동으로 늘려 줍니다. Java 8의 장정 중에 하나로 OutOfMemoryError: PermGen Space error는 더이상 볼 수 없고 JVM 옵션으로 사용했던 PermSize 와 MaxPermSize는 더이상 사용할 필요가 없습니다. 이 대신에 MetaspaceSize 및 MaxMetaspaceSize가 새롭게 사용되게 되었다. 이 두 값은 Metaspace의 기본 값을 변경하고 최대값을 제한 할 수 있습니다.
3) JDK 8 : PermGen 제거 변경사항
| Java 7 | Java 8 | |
|---|---|---|
| Class 메타 데이터 | 저장 | 저장 |
| Method 메타 데이터 | 저장 | 저장 |
| Static Object 변수, 상수 | 저장 | Heap 영역으로 이동 |
| 메모리 튜닝 | Heap, Perm 영역 튜닝 | Heap 튜닝, Native 영역은 OS가 동적 조 정 |
| 메모리 옵션 | -XX:PermSize-XX:MaxPermSize | -XX:MetaspaceSize-XX:MaxMetaspaceSize |
4) 왜 Perm이 제거됐고 Metaspace 영역이 추가된 것인가?
- Metaspace 영역은 Heap이 아닌 Native 메모리 영역으로 취급하게
된다. (Heap 영역은 JVM에 의해 관리된 영역이며, Native 메모리는
OS 레벨에서 관리하는 영역으로 구분된다) Metaspace가 Native 메
모리를 이용함으로서 개발자는 영역 확보의 상한을 크게 의식할 필요가
없어지게 되었다. - 즉, 각종 메타 정보를 OS가 관리하는 영역으로 옮겨 Perm 영역의 사이즈 제한을 없앤 것이라 할 수 있다.
5) 요약
- JDK 8부터 Permanent Heap 영역이 제거되었다.
- 대신 Metaspace 영역이 추가되었다.
- Perm은 JVM에 의해 크기가 강제되던 영역이다.
- Metaspace는 Native memory 영역으로, OS가 자동으로 크기를 조절한다.
- 옵션으로 Metaspace의 크기를 줄일 수도 있다.
- 그 결과 기존과 비교해 큰 메모리 영역을 사용할 수 있게 되었다.
- Perm 영역 크기로 인한 java.lang.OutOfMemoryError 를 더 보기 힘들어진다.
#Java 7
- update 4 부터 parallel GC 가 기본으로 설정되어있다.
- GC 5가지 방식
- Serial GC
- Parallel GC
- Paralled Old GC (Paralled Compaction GC)
- Concurrent Mark-Sweep GC (CMS GC)
- G1 GC (Garbage First GC)
사진출처 :
일반 프로그램-JAVA 프로그램 : https://ifcontinue.tistory.com/9
인프런 "더자바 코드를 조작하는 다양한 방법"-백기선 강의자료
GC :
- https://blog.ycpark.net/entry/JAVA%EC%9D%98-GC%EC%9D%98-%EC%A2%85%EB%A5%98-%EB%B0%8F-%ED%8A%B9%EC%A7%95
- https://mirinae312.github.io/develop/2018/06/04/jvm_gc.html
Serial GC와 CMS GC의 절차를 비교 : https://www.oracle.com/java/technologies/
Metaspace : https://sheerheart.tistory.com/entry/Java-Metaspace%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C
