<Synchronization 동기화>
⋅ 두 프로세서가 메모리 영역을 공유할 때
P1이 쓰기 전에 P2가 읽어버릴 수도 있으므로 순서 정하기. lock/unlock (1이면 사용불가, 0이면 사용가능)
⋅ 하드웨어 지원 필요
-원자적 read/write 메모리 연산 / 다른 접근X
-lw와 sw를 사용하는 경우는 원자적이지 않은 swap
⋅ 단일 명령 (완벽히 교환. 둘 사이에 다른 주소X)
swap $s0, 0($s1)
<MIPS에서의 동기화>
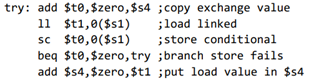
⋅ Load linked: rt, offset(rs)
-값만 가져오는 게 아니라 연결까지(ll은 항상 성공)
⋅ Store conditional: sc rt, offset(rs) #sw+상태저장
-store 성공 시 rt에 1을 반환, 실패 시 rt에 0 반환
-ll의 결과값이 바뀐 경우 store 실패
<Translation번역 및 Startup>
⋅ 비휘발성 저장장치의 프로그램을 실행할 수 있는 프로그램으로 변환하기 위한 4단계
1. C프로그램을 컴파일러가 어셈블리언어 프로그램으로
2. 어셈블러가 기계어 모듈(목적 파일)로
3. 링커가 그 모듈과 기계어로 된 라이브러리 링크
4. 로더가 기계어로 된 프로그램 실행
5. 메모리로 들어감
<어셈블러 의사명령어 Pseudo-instructions>
⋅ 어셈블러 명령어는 기계 명령어를 일대일로 나타냄.
⋅ 의사 명령어: 어셈블러 레벨에서만 사용됨. at이라는 임시 레지스터가 추가로 필요하므로 비용 발생,
$at는 레지스터 1번이 할당되어 있음
<어셈블러의 object 모듈 생성>
symbol table: 전역 정의 및 외부 참조 레이블 저장
relocation(재배치) 정보: 프로그램이 메모리에 적재될 때 절대 주소를 사용해야 하는 명령어, 데이터 word 표시
<Linking object 모듈> - 실행 파일 생성
- 영역별로 세그먼트 병합
- 데이터와 명령어 레이블의 주소 결정
- 외부 및 내부 참조 해결(정보 바꿔줌)
<프로그램 로드>
디스크의 이미지 파일에서 메모리로 로드
1. 세그먼트 크기 결정을 위해 헤더 읽기 / 영역 판단
2. 가상 주소 공간 생성 / 메모리 공간 확보
3. 텍스트 및 초기화된 데이터를 메모리에 복사
4. 스택에 인수 셋팅 (스택 통해서 인수 전달하므로)
5. 레지스터 초기화 ($sp, $fp, $gp, $sp 등)
6. Jump to 시작 루틴 / 메인함수 첫 줄 실행
-인수를 레지스터에 복사하고 main 호출, return시 exit 시스템 호출을 사용해 프로그램 종료
<동적 Linking>
호출 시에만 링크/로드 라이브러리 프로시저
- 프로시저 코드가 재배치 가능 형태
- 실행 파일 크기 줄일 수 있음
- 함수 코드가 실행할 때 삽입되므로 업데이트 되었을 때 새 라이브러리 버전 자동 선택
- 메모리에는 각각 갖고 있어서 메모리 효율은 낮음
<Lazy Linkage>
- 호출된 후 링크
- 간접 접근 기법 사용
<C Sort 예시> - C 버블 정렬
swap 프로시저:

<배열 vs 포인터>
⋅ 배열:
- 인덱스에 원소 사이즈 곱하기
- 배열 base 주소에 추가
⋅ 포인터: 배열로 짠 코드보다 빠름
- 메모리 주소 바로 지정
- 인덱싱 복합성을 피할 수 있다.
⋅ 배열 버전은 shift가 루프 내부에 있어야 함.
- i 증가에 대한 인덱스 계산의 일부
- 컴파일러는 배열을 사용해도 포인터를 수동으로 사용하는 것과 동일한 효과를 얻을 수 있도록 하므로 배열을 사용해서 프로그램을 명확하고 안전하게 만드는 것이 더 좋다.
<ARM와 MIPS의 유사점>
- 둘 다 32bits 사용 (인스트럭션 크기, 주소 공간)
- 데이터 정렬됨
- 데이터 주소지정 방식이 ARM은 9, MIPS는 3
- 레지스터가 ARM은 15개, MIPS는 31개
- 둘 다 입출력이 memory-mapped 형식
<ARM에서 비교 & 브랜치> - Branch 방식이 다름
⋅ 산술/논리 명령 결과에 대한 조건 코드 사용
- Negative, zero, carry, overflow
- 결과를 유지하지 않고 조건 코드를 설정하는 명령이 비교
⋅ 각 명령어는 조건부일 수 있다.
- 명령어 상위 4비트: 컨디션 value
- MIPS는 종속적이면 jump를 넣어야 함. 이 경우 실행할지 말지 선택할 수가 없다.
- ARM은 실행 안 하도록 할 수 있는 컨디션 코드를 쓴다. branch를 굳이 안 써도 된다.
<ARM v8 명령어>
⋅ 64-bit로 전환하면서, ARM은 전면적 점검을 수행함.
⋅ ARM v8은 MIPS와 유사하다. (v7->v8 변경 사항)
- 컨디션 확인 실행 필드 없음
- Immediate field는 12비트
- PC는 더 이상 GPR이 아님
- 32개의 범용 레지스터(GPR)
- 주소 지정 방식이 모든 데이터 크기에 적용
- 분할 명령
- equal/not equal 분기Branch 명령어
- MIPS: RISC의 전형
⋅ 이전 버전과의 호환성을 통한 진화
- 8080: 8비트 마이크로프로세서
- 8086: 16비트로 확장8080, 복합 명령어 세트(CISC)
- 8087: 부동 소수점 코프로세서
- Pentium: MMX 지침 추가 / MMX 명령어는 여러 개의 작은 데이터를 동시에 처리하는 SIMD 방식
- AMD64(2003): 64비트로 확장된 아키텍처
- AMD64(2007): SSE5 명령어 / 인텔은 거부
⋅ 가변 길이 인코딩
- Postfix 바이트는 주소 지정 모드 지칭
- 경우에 따라 Postfix 바이트 수정 작업
<흔히 할 수 있는 오해>
⋅ 강력한 인스트럭션 사용-> 고성능 이라는 오해
- 복잡한 명령어는 구현하기 어렵고, 간단한 명령을 포함하여 모든 명령이 느려질 수 있다.
⋅ 고성능을 위해 어셈블리 언어로 코드 작성하는 것이 좋을 것이라는 오해
- 최신 컴파일러는 최신 프로세서를 더 잘 처리함.
- 더 많은 코드 라인으로 오류 증가 및 생산성 저하됨
⋅ 이전 버전과 호환성이 좋다는 게 명령어 세트가 변하지 않았을 것이라는 오류
- 성장하면서 명령어가 계속 추가됨
<함정>
⋅ 바이트 주소를 사용할 때, 인접 워드 간 주소 차이가 1이 아니라 4라는 것을 잊지 않기.
⋅ 프로시저 반환 후 프로시저 외부에서 자동 변수에 대한 포인터를 사용하지 말 것. (이미 없어진 자동 변수에 대한 포인터 사용하면 예기치 못한 일 발생 가능성)
