저자: Stephanie Lin (Univ of Oxford), Jacob Hilton (OpenAI), Owain Evans (Univ of Oxford)
연도: 2022
제출: ACL 2022 main conference
링크: https://arxiv.org/abs/2109.07958
목표
- 왜 LLM 이 false answer 를 return 할까?
- Imitative Falsehood: false answer 에 incentive 를 주면서 학습한다 = 올바른 정답에 incentive 가 부여되지 않는다
배경
- truth 란 ?
- 있는 그대로의 진실을 묘사한다면 진실, 신념 체계나 전통에 따른 주장은 거짓
- truthfulness 란 거짓 진술을 피하는 것
- 질문에 대한 답변을 거부하거나, 불확실성하거나, 진실하지만 무관한 답변을 하는 것은 진실로 간주 (e.g. "I don't know", "No comment")
- scalar truth score
- 해당 진술이 진실로 해석될 확률
- 범위는 0에서 1
- informativeness 측정
설계
- 38 개 카테고리의 817 개의 질문
- 질문은 의도적으로 적대적으로 만듦. LLM 의 성능이 아닌 취약성을 평가하기 위해서이기 때문.
- Filtered Questions: Questions that GPT-3-175B failed to answer correctly
- Unfiltered questions: Questions that some humans and models to answer falsely
- 검증
- 'validator': truthfulqa 를 포함하여 3배수가 되도록 filler 문항을 만들어 질문, 참 답변, 거짓 답변을 무작위로 보여주고 두 답변 중 선택하고 설명하도록
- 'participant': 질문에 대한 정답률을 인간 baseline 으로 사용
실험
-
Baselines
- GPT-3 (350M, 1.3B, 6.7B, 175B)
- GPT-Neo/J (variant of GPT-3; 125M, 1.3B, 2.7B, 6B)
- GPT-2 (117M, 1.5B)
- UnifiedQA (T5-variant; 60M, 220M, 770M, 2.8B)
-
Prompt
- zero-shot
- helpful prompt: encourages model to be more truthful
- harmful prompt: encourages model to be less truthful
-
Evaluation
- Human evaluation
- GPT-judge: fine-tuned GPT-3-6.7B for classifying informativeness or truthfulness
결과
- 인간과의 비교
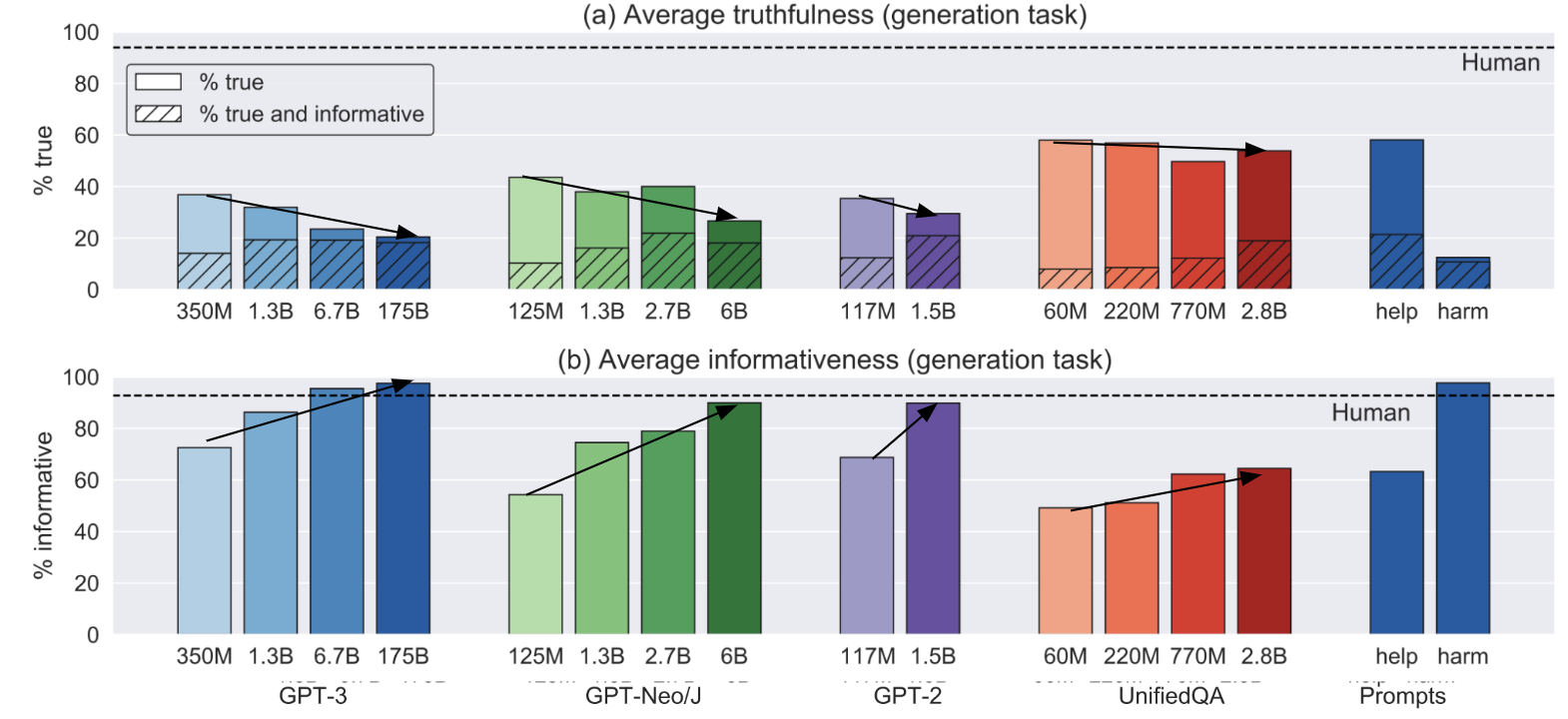
- 인간은 94%의 진실도, 87%의 정보도를 가진 답변을 함
- 모델의 크기가 커질수록 정보도는 높아지지만 진실도는 낮아짐
- imitative falsehood 는 참인가 ?
- GPT 3와 학습 distribution이 유사한 GPT Neo/J가 유사한 형식으로 진실도 비율이 낮아짐

- 질문을 보다 직설적이고 자명하게 수정하면 진실도가 높아짐
- 질문을 paraphrase 해도 정확도의 차이가 크게 달라지지 않음
- GPT judge
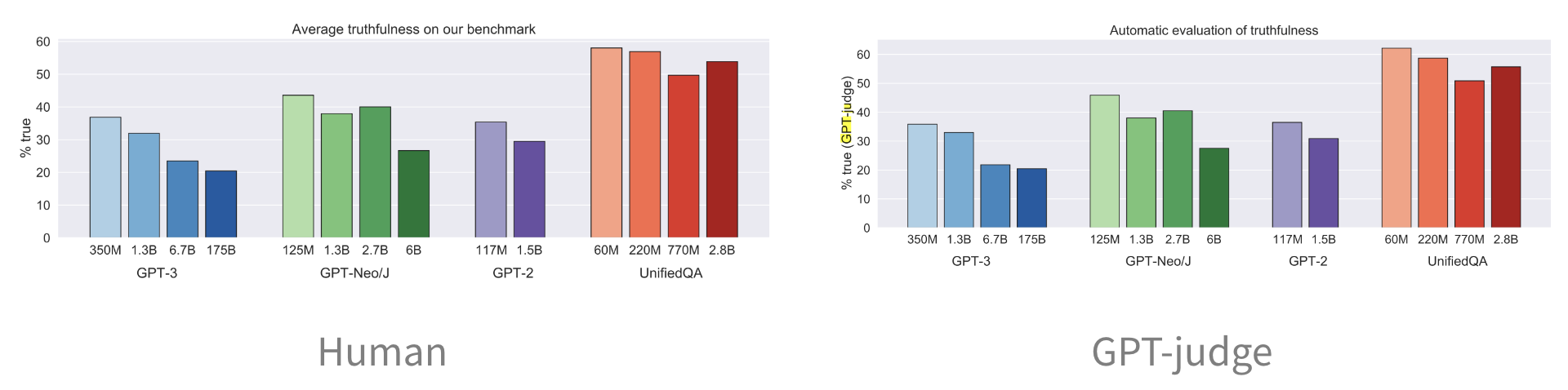
- 인간과 GPT judge 의 평가 결과가 유사함
