
해당 포스팅은 가상 면접 사례로 배우는 대규모 시스템 설계 기초 3장 - 시스템 설계 면접 공략법에 대한 내용을 토대로 구성했습니다.
요구 사항
뉴스 피드(news feed) 시스템 설계 요구 사항
- 모바일 앱과 웹을 둘 다 지원해야한다.
- 가장 중요한 기능은 새로운 포스트(post)를 올리고, 다른 친구의 뉴스 피드를 볼 수 있도록 하는 기능이다.
- 문제를 단순히 하기 위해 시간 역순으로 정렬한다.
- 한 사용자는 최대 500명의 사용자와 친구를 맺을 수 있다.
- 일간 능동 사용자(daily active user, DAU)는 천만 명이다.
- 피드에 이미지나 비디오 같은 미디어 파일도 포스트할 수 있어야 한다.
flow
피드 발행
사용자가 포스트를 올리면 관련된 데이터가 캐시/데이터베이스에 기록되고, 해당 사용자의 친구(friend) 뉴스 피드에 뜨게 된다.
피드 생성
어떤 사용자의 뉴스 피드는 해당 사용자 친구들의 포스트를 시간 역순으로(최신 포스트부터 오래된 포스트 순으로) 정렬하여 만든다.
flow 개략적 설계
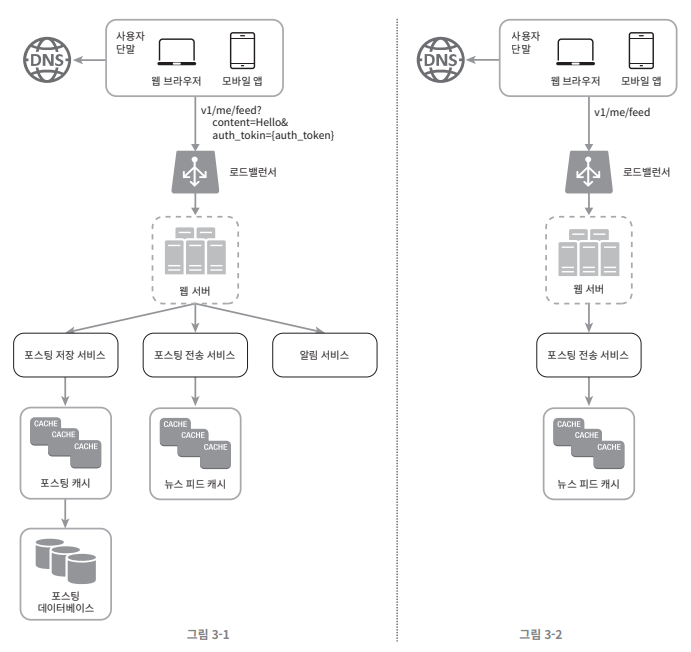
그림 3-1은 피드 발행, 그림 3-2는 피드 생성
상세 설계
피드 발행
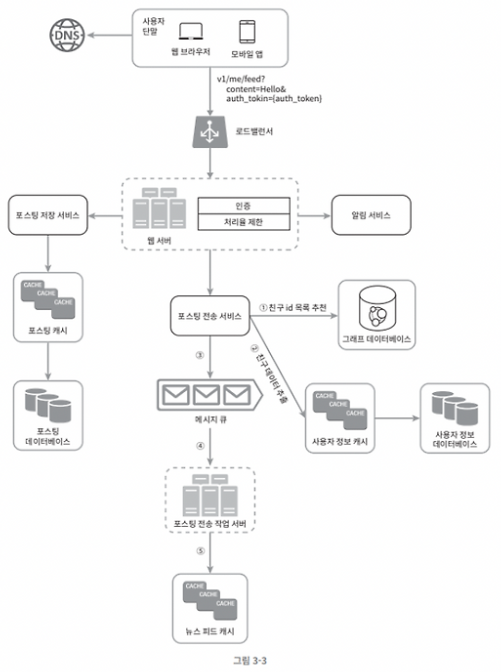
전략
피드 발행의 상세 설계는 어떤 전략인가?
1. 사용자가 글을 작성하면 팔로워들의 뉴스 피드 캐시에 바로 반영
2. 메시지 큐를 통해 병렬적을 처리하고, 각 유저의 뉴스 피드 캐시를 미리 업데이트
3. 쓰기 시점에 fan-out 작업이 발생
즉, 피드 발행은 Fan-out on Write 전략이라고 볼 수 있다.
전체 동작 과정
사용자가 브라우저/앱을 통해 포스트 생성 요청 -> POST /v1/me/feed 전송
로드벨런서 경유 및 인증 처리
- 로드 밸런서가 요청을 웹 서버에 요청 전달
- 웹 서버는 인증 토큰을 검증하고 처리율 제한 수행
포스팅 저장 서비스 처리
- 웹 서버는 요청을 포스팅 저장 서비스에 전달
- 해당 서비스는 작성된 포스트를
포스팅 캐시에 저장하고,포스팅 DB에도 저장
포스팅 전송 서비스 호출
1. 그래프 DB를 통해 친구/팔로워 ID 목록을 추출 (Fan-out 대상)
2. 추출된 팔로워 목록을 기반으로 fan-out 작업 준비
3. 메시지 큐에 Fan-out 작업 요청
- 각 팔로워에 대해 뉴스 피드에 포스트를 추가하는 작업을 메시지 큐에 등록
- 이 큐는 비동기 fan-out 분산 처리를 위해 활용
4. 포스팅 전송 작업 서버가 Fan-out 수행
- 포스팅 전송 작업 서버가 메시지 큐를 구독하여, 각 작업을 병렬로 수행
5. 뉴스 피드 캐시 업데이트
- 각 팔로워의 뉴스 피드 캐시에 새로운 포스트 ID를 추가
- 이후 해당 팔로워가 뉴스 피드를 조회하면 병합 과정 없이 캐시에서 즉시 응답 가능
피드 조회
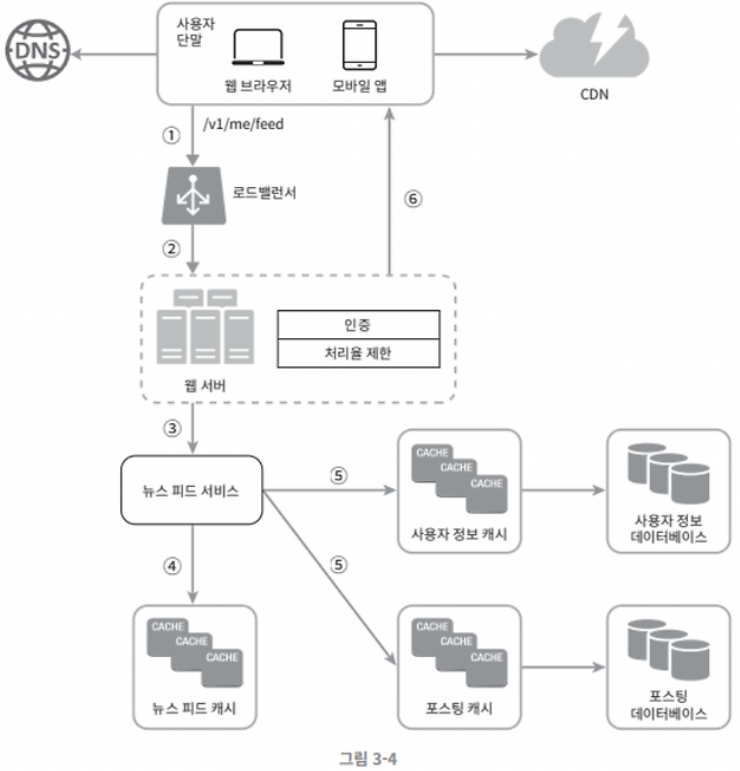
전체 동작 과정
1. 사용자 요청
- 사용자가
/v1/me/feed엔드포인트로 뉴스 피드 요청을 보냄. (요청에는 인증 토큰 포함)
2. 로드밸런서 -> 웹 서버
- 로드 밸런서가 요청을 웹 서버에 분산 처리
- 인증 및 처리율 제한 등의 처리 후 뉴스 피드 서비스로 전달
3. 뉴스 피드 서비스 호출
- 웹 서버는 요청을 뉴스 피드 서비스에 넘김
- 뉴스 피드 서비스는 유저의 뉴스 피드를 조회
4. 뉴스 피드 캐시 확인
- 뉴스 피드 캐시에서 해당 사용자의 피드가 존재하는지 확인
- 캐시 히트 : 바로 응답
- 캐시 미스 : 다음 단계로 이동
5. 캐시/DB에서 정보 병합
사용자 정보 캐시-> 팔로우 목록 등 조회포스팅 캐시-> 해당 팔로우 유저들의 최근 포스트 조회- 필요한 경우 각각의 DB 접근
- 각 캐시 데이터를 병합 후 타임라인 형식으로 정렬 및 구성
6. CDN 전달 및 사용자 응답
- 응답 데이터를 CDN에 캐시하고, 사용자에게 전달
3장 스터디 질문 중..
해당 사진에서 4번, 5번, 6번의 동작 과정에 대해 팀원들이 많이 궁금해 했고 머리를 모아 봤다.
처음에는 뉴스 피드의 데이터가 없다면 유저 디비, 포스트 디비에서 데이터를 갖고 온다고 결론을 짓던 찰나에 답이 나왔다.
피드를 조회하기 위해, 뉴스 피드 서비스가 호출된다고 가정하자.
뉴스 피드 캐시는
user_id를 키로 하여, 해당 사용자가 볼 수 있는post_id리스트를 저장하는 구조이다.user_id -> [post_id1, post_id2, ...]형태의 키-값 구조만약 캐시 미스가 발생하면, 뉴스 피드 서비스는 사용자 정보 캐시 및 포스팅 캐시를 조회하고, 필요한 경우 사용자 정보 DB와 포스팅 DB를 순차적으로 조회한다.
이렇게 가져온 포스트 ID와 메타 정보는 다시 캐시에 저장되어 이후 요청의 응답 속도를 높인다.
전략의 fan-out on Write 방식에서는 포스트 생성 시 각 팔로워의 뉴스 피드 캐시에 해당 포스트를 삽입해야 하므로, 팔로워 수가 많을 수록 쓰기 시점에 latency가 증가할 수 있다. (읽기 성능은 우수)
이후 11장 뉴스 피드 시스템 설계에서 더 자세히 다룰 예정이다.
