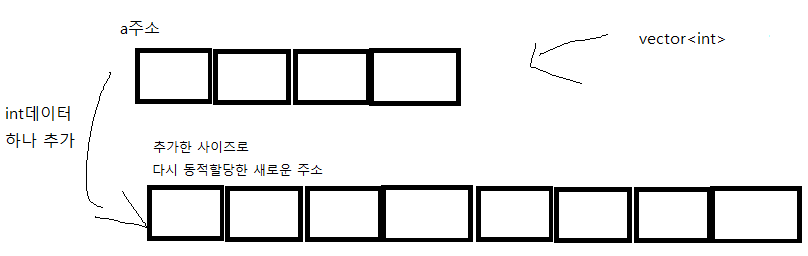
vector
1.가변배열 구조
2.데이터 하나를 넣을 때 마다 자료형 크기로 사이즈 크게 동적할당 하여 새 배열을 가진다
3.배열의 이름은 배열의 첫 주소와 같다. 포인터와 같은 역할을 할수 있다
4.순서에 상관없이 랜덤하게 vector 인덱스에 접근 가능하다 (윗 내용을 근거로)
5.A_iterator를 매개변수로 하여 요소 추가나 제거 한다면 A_iterator는 유효하지 않은 iterator가 되고 B_iterator가 반환된다
장점
1.데이터를 넣을 때 자동으로 배열 크기가 늘어난다
2.배열 사이즈를 직접 조절 가능하다
3.각 인덱스에 접근하는데 처리비용이 적다
4.인덱스 랜덤 접근(random access iterator)
단점
1.마지막 인덱스가 아닌 인덱스에서 데이터 추가,삭제시 처리 비용이 많이 든다
(추가시 뒤에 데이터들이 밀려나야 하는 프로세스들이 필요,제거시 뒤에 데이터들을 앞당기는 프로세스 필요)
2. 동적할당으로 배열이 만들어짐. 생성,제거를 다 신경 써야 함
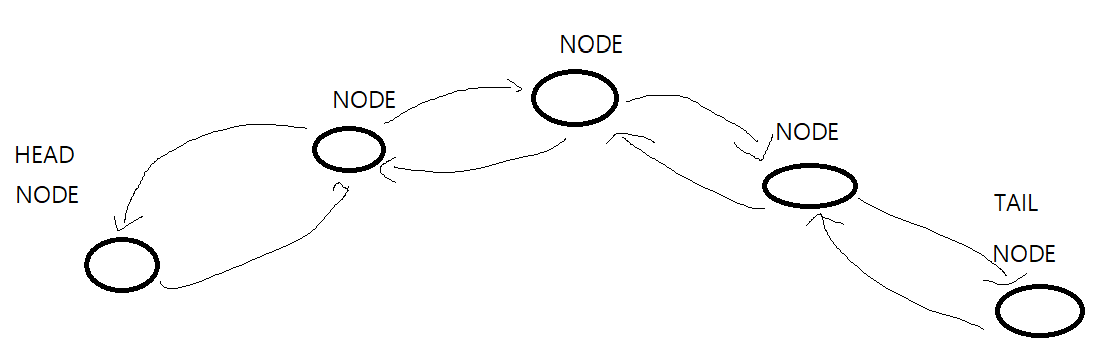
list
1.헤드노드를 시작으로 데이터가 들어오면 연결 됨
2.각 노드로 연결되있음(double linked list 쌍방향 연결)
3.어느 위치든 인덱스 중간 삭제와 삽입의 처리비용이 적다.(각 노드가 포인터로 연결되기 때문)
4.데이터 특정 인덱스에 접근을 위해 무조건 헤드나 테일을 통해 순서대로 이동해야지 접근 가능
5. 특정 인덱스 접근 처리 비용이 많이 든다.(4번을 근거로)
장점
1.어느 인덱스든 데이터 삽입,제거의 처리 비용이 적다
단점
1.특정 인덱스에 접근의 처리 비용이 많이 듬
2.forward/reverse iterator -특정 인덱스 접근 할려면 헤드 or 테일을 거치고 순서대로 거 쳐야 하기 때문
3. double linked를 하기 위해 추가적 메모리 비용 발생
4. 동적할당으로 노드가 만들어짐. 생성,제거를 다 신경 써야 함
