Today I Learned ...
오늘은 '엑셀보다 쉽고 빠른 SQL' 강의의 4, 5강을 들었다.
드디어 강의 끝!
📚 4강 _ 데이터 연결하기
4강에서는 크게 두 가지의 내용을 다루는데, 그 중 첫 번째는 여러번의 연산을 한 번에 수행하게 해주는 Subquery이다.
데이터를 다루다보면, 여러번의 연산을 수행해야 할 때도, 조건문에 연산의 결과를 사용해야 할 때도, 혹은 쿼리의 결과를 조건문에 사용하고 싶을 때도 있을 것이다.
원래대로라면 몇 단계를 거쳐서 작업을 진행해야 하지만, subquery를 사용하면 한 번에 모든 내용을 수행하게 할 수 있다.
select column1, special_column
from
(
/* subquery */
select column1, column2 special_column
from table1
) aSubquery의 기본 구조는 위와 같다.
() 안에 있는 내용, 즉 서브 쿼리를 먼저 수행하고, 그 뒤에 () 바깥에 있는 메인 쿼리를 수행한다.
위와 같은 경우에는 서브 쿼리에서 special_column을 지정해두었기 때문에, 메인 쿼리에서 special_column을 그대로 사용할 수 있는 것이다.
4강에서 다루는 두 번째 내용은 필요한 데이터가 서로 다른 테이블에 있을 때 사용하는 Join이다.
엑셀에서 Vlookup을 사용하는 것과 비슷한 역할을 한다.
이번 강의에서 다루는 Join에는 2가지 종류가 있다.
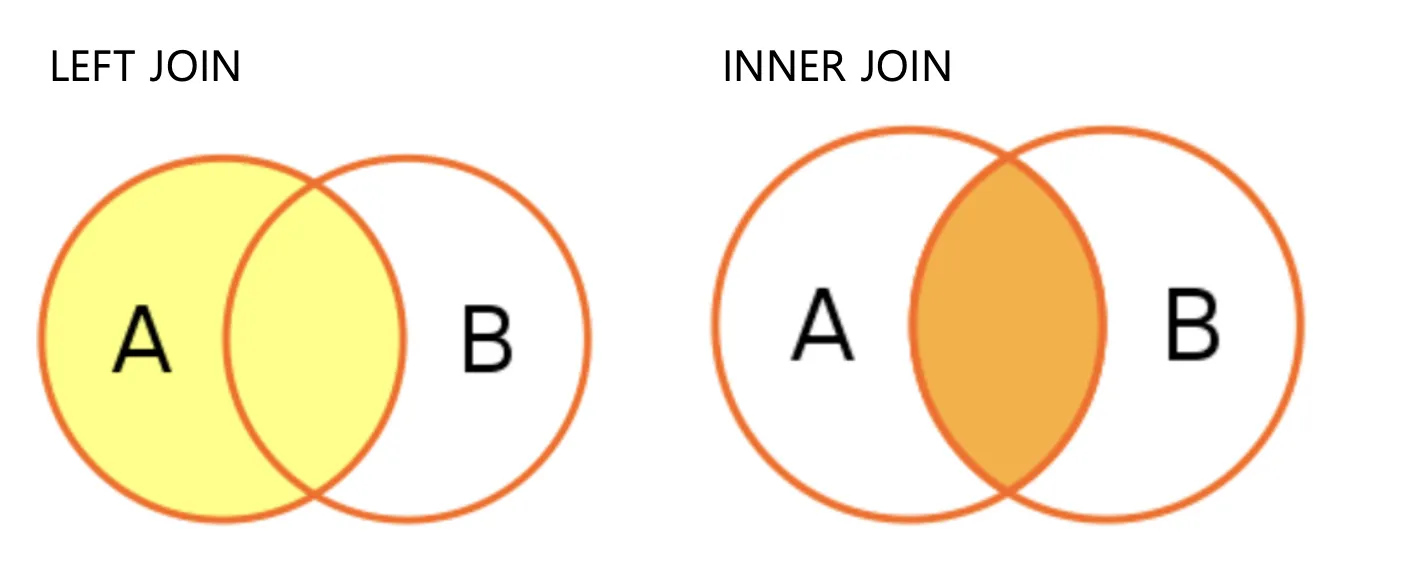
① Left Join
Left Join은 공통 컬럼을 기준으로 하나의 테이블에 값이 없더라도 모두 조회하는 것이다.
즉, 위 사진에서처럼 B에는 내용이 없더라도 A에 있는 내용을 모두 보여준다.
select [조회 할 컬럼]
from [테이블1] a left join [테이블2] b on a.공통컬럼명=b.공통컬럼명기본 골격은 이와 같다.
테이블1의 값이 기준이 되고, 만약 테이블2에 해당 내용이 없다면 Null로 채워진다.
이번 강의에서 다루지는 않았지만, 똑같은 개념으로 Right Join도 사용이 가능하다.
그리고, 좌측, 우측 상관없이 데이터가 있다면 모두 가져오고, 없는 것은 모두 Null로 채우는 Full Join도 있다.
이 3가지를 합쳐서 Outer Join이라고 부른다.
② Inner Join
Inner Join은 공통 컬럼을 기준으로 두 테이블 모두에 있는 값만 조회하는 것이다.
select 조회 할 컬럼
from [테이블1] a inner join [테이블2] b on a.공통컬럼명=b.공통컬럼명기본 골격은 이와 같다.
이때, 공통 컬럼은 단지 두 테이블을 묶어주기 위한 것이기 때문에, 두 테이블의 컬럼명이 달라도 상관없다.
on a.공통컬럼명 = b.공통컬럼명에서 제대로 입력해주기만 하면 된다.
자세한 실습 내용은 노션을 통해 정리해두었다.
Notion 확인하기
📚 5강 _ SQL로 업무시간 단축하기
마지막으로, 5강에서는 SQL을 활용해 더 편리하게 사용할 수 있는 몇몇 함수들을 알려준다.
첫 번째는 데이터 연산을 할 때, 일부 데이터를 변환해서 연산하는 방법이다.
테이블에 값이 없거나 잘못된 경우에는 그 값을 제외해서 연산에 사용해야 한다.
SQL에서는 'Not Given'을 0으로 취급해 계산하기 때문에, 일부 연산을 수행할 때 이로 인한 오류가 생길 수 있다.
이때는 if([컬럼명]<>'Not given', [컬럼명], null)과 같이 사용하여 해당 값을 Null로 취급하도록 지정해야 한다.
또, Outer Join을 사용할 때, 한쪽 테이블에 값이 없다면 Null을 사용한다.
이런 경우에는 다른 값을 대신해서 사용해야 하는데, 데이터 분석 시에는 평균값 또는 중앙값 등 대표값으로 대체하는 경우가 많다고 한다.
이때는 coalesce([컬럼명], 대체값)과 같이 사용하여 Null에 대체값을 적용하여 사용할 수 있다.
그리고, 조회한 데이터가 상식적이지 않을 수도 있다.
이런 경우에는 최솟값과 최댓값을 지정해서 상식적이지 않은 값들이 범위 내로 들어오도록 지정할 수 있다.
case when [컬럼명]<[최솟값] then [최솟값]
when [컬럼명]>[최댓값] then [최댓값]
else [컬럼명]
end이렇게 지정할 경우, 최솟값보다 작다면 최솟값으로, 최댓값보다 크다면 최댓값으로 대체해서 계산할 수 있다.
두 번째는 SQL을 활용해 Pivot Table을 만드는 것이다.
Pivot Table이란 2개 이상의 기준으로 데이터를 집계할 때 보기 쉽게 배열하여 보여주는 것이다.
Pivot Table을 사용할 때는 max(if([기준 컬럼]=[특정 값], [원하는 결과], 0)) 형식을 사용한다.
select [기준 컬럼1],
max(if([기준 컬럼2]=[특정 값], [원하는 결과], 0)) "[특정 값]",위와 같이 사용한다면, 기준 컬럼1로 먼저 분류가 되고, 그 안에서 기준 컬럼2가 특정 값을 만족할 때 나오는 결과를 볼 수 있게 된다.
select [기준 컬럼1], [기준 컬럼2], 원하는 값
from [테이블 이름]
group by 1, 2위와 같이 사용한다면, 각각의 경우마다 하나의 행이 생성되기 때문에 가독성이 좋지 않아진다.
먼저 위 내용처럼 코드를 만들어본 후에, 기준의 우선순위에 따라서 피벗 테이블로 변경해주면 된다.
세 번째로는 Window Function을 다룬다.
Window Function은 각 행의 관계를 정의하기 위한 함수로, 그룹 내의 연산을 쉽게 만들어준다.
window_function(argument) over (partition by 그룹 기준 컬럼 order by 정렬 기준)Window Function의 기본 골격은 위와 같다.
window_function에는 기능명을 작성하면 되는데, 순위를 나타내거나, 그룹 내의 합계 혹은 통계를 계산하는 등 다양한 기능을 사용할 수 있다.
partition by에는 그룹을 나누기 위한 기준이 되는 컬럼을, order by에는 window function을 적용할 때 정렬할 컬럼의 기준을 기입해주면 된다.
이번 강의에서 다룬 내용 중 Window Function이 가장 복잡했는데, 자세한 기능과 기능별 실습 내용들은 노션을 통해 정리해두었다.
마지막은 텍스트 형식으로 기록되었있던 날짜를 날짜 형식으로 변경하는 것이다.
date([대상 컬럼])과 같은 형식으로 작성하면 된다.
날짜가 텍스트 형식으로 되어있었을 때는 substr을 통해 년도, 월, 일을 구분해야 했다.
하지만, 날짜 형식을 사용한다면 date_format(date(date), '%Y(m/d/w)')을 통해 간단하게 년도, 월, 일, 요일 정보를 받을 수 있다.
각 내용별 자세한 실습 내용은 노션을 통해 정리해두었다.
Notion 확인하기
🙃 오늘의 느낀점
이번 강의의 제목이 '엑셀보다 쉽고 빠른 SQL'이었다.
하지만, 엑셀 경험은 많고, SQL 경험은 전혀 없던 나에게는 엑셀보다 훨씬 어려운 SQL 강의였다...
그래도 왜 SQL이 엑셀보다 빠르다고 하는지는 알 것 같다.
엑셀을 사용할 때에는 노가다를 하는 듯한 느낌이 많이 들었고, 데이터가 많아질수록 함수를 실행하는 데에 많은 시간이 소요되었었다.
그런데, SQL을 사용하니 한번의 명령으로 수많은 데이터들이 한번에 처리가 되니 편했다.
언젠가 엑셀보다 SQL이 쉬워질 그날을 기대하며,, SQL을 더 연습해야겠다.
