프로젝트 설명
이번 프로젝트는 올해 9월부터 기획을 시작한 'NLP를 이용한 글쓰기 피드백 크롬 익스텐션 개발'을 목표로 한다. 포함된 기능으로는 '띄어쓰기 및 맞춤법 교정', '격식-비격식 전환', '문맥에 맞는 유의어 추천', '긴 호흡의 문장 판별' 등이 있다. 지금은 각 기능의 모델을 하나하나 구현하는 과정 중에 있다.
이번 주 그로쓰 분들 포스터 세션에 구경 갔다 왔는데 마침 첫 번째 팀이 크롬 익스텐션을 만든 분들이었다. 얘기를 들어보니 크롬 익스텐션 만드는 게 정보도 없고 안 되는 것도 많고 정말정말정말 어려우니 빨리 시작해야 한다고... 우리 프로젝트는 다른 일을 하는 기능이 많아, 모델링도 여러 개를 해야 하기에 그게 가장 큰 산일 줄 알았는데... 종강하자마자 크롬 익스텐션 개발을 바로 들어가야할 것 같다.ㅎㅎ
우선 자연어처리(nlp)는 아주 크게 데이터셋을 구축하고, 그 데이터셋을 통해 모델링(학습)하는 과정으로 나누어진다.
이 포스팅은 '격식-비격식 전환', '맞춤법 교정', '띄어쓰기 교정', '유의어 추천'의 기능만을 다루고 있는데, '데이터셋을 구축하는 과정' 또는 '모델링하는 과정'에서의 경험을 공유하고자 한다.
격식-비격식 전환
편의상 격식-비격식 전환이라고는 하였으나, 공적인 글을 쓰기 어려운 사람들을 위해 고안한 기능으로ㅡ 'NOT 하십시오체'를 '하십시오체'로 바꿔주는 기능이다.
예를 들어보자면,
관련 봉사활동 해봄 → 관련 봉사활동을 해 본 경험이 있습니다.
관련 봉사활동 해봤어 → 관련 봉사활동을 한 경험이 있습니다.
관련 봉사활동 한 적 있어요 → 관련 봉사활동을 한 경험이 있습니다.
이런 식으로 전환해주는 것이다.
이 기능이 우리 프로젝트에 필요하다고 생각한 이유는, 자체적으로 실시한 설문조사에서 맞춤법 검사기를 '공적 이메일, 자기소개서' 등에 가장 많이 사용한다고 했기 때문이다.
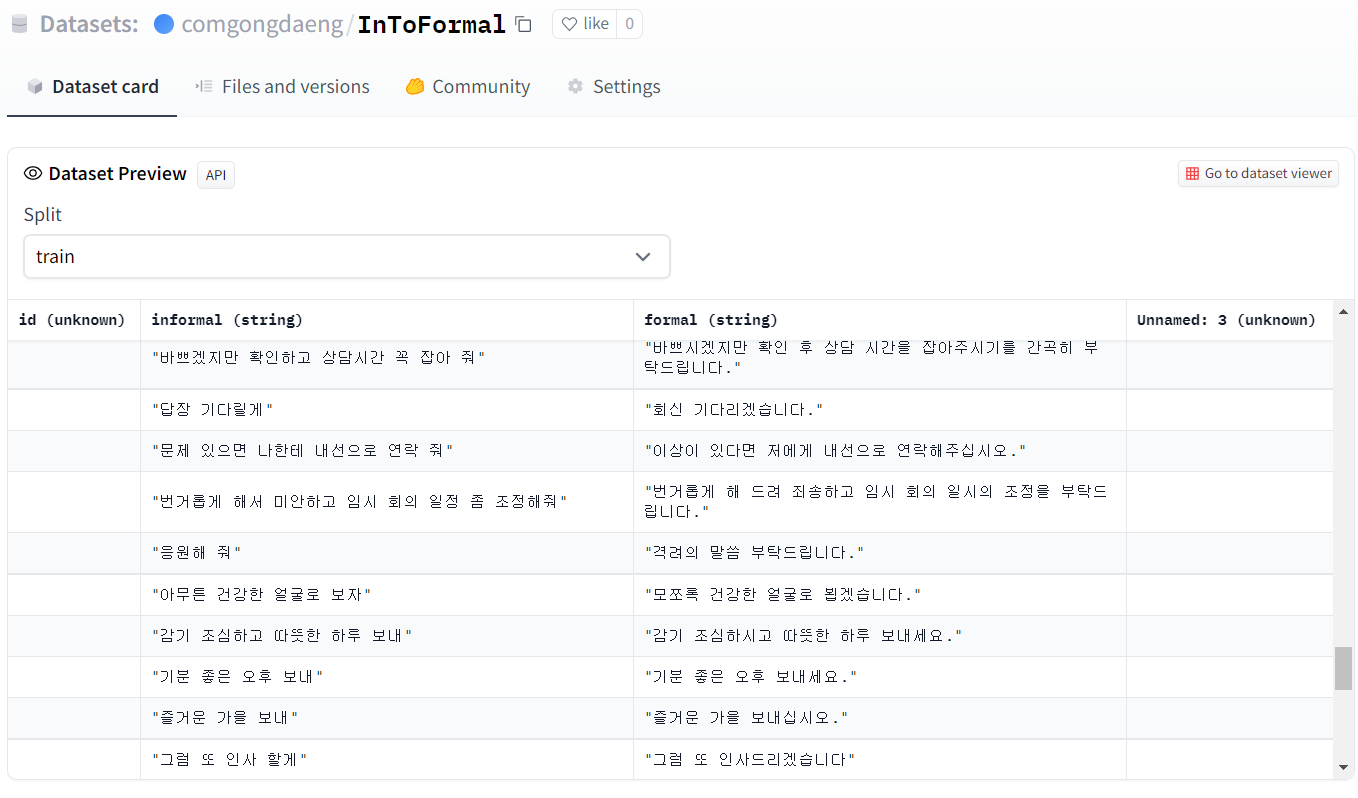
구축한 데이터셋의 토픽들을 '메일', '자기소개서', '정치/경제', '쇼핑', '일기', '엔터테인먼트' 등으로 선정하였고, 그 비율을 2:2:1:1:1로 두었다. 저 비율을 유지한 채로, 다양한 분야의 'NOT 하십시오체-하십시오체' 데이터셋을 직접 구축하였다.전문용어로 노가다..
메일은 내가 쓴/받은 메일, 근무하는 학원에서 나가는 안내문(thanks to 실장님..💕)을 활용하였다. 자기소개서는 내가 지금까지 썼던 동아리, 입학 자기소개서 등등을 최대한 끌어모아서 문장을 마련하였고, 다른 분야는 기사, 카카오톡, 트위터 등을 이용하였다.
한 사람당 1000개씩 해서 총 3000개 정도의 데이터셋을 모았다.
사이좋게 듀 못 맞춘 팀원들..ㅎㅎ 인풋문장부터 만드는 건 진짜 힘들었ㄷㅏ..ㅠㅠ

'NOT 하십시오체' 문장을 input문장으로, 그와 같은 뜻이지만 '하십시오체'를 사용한 문장은 정답 데이터(label)로 사용하여 모델을 학습시킨다.
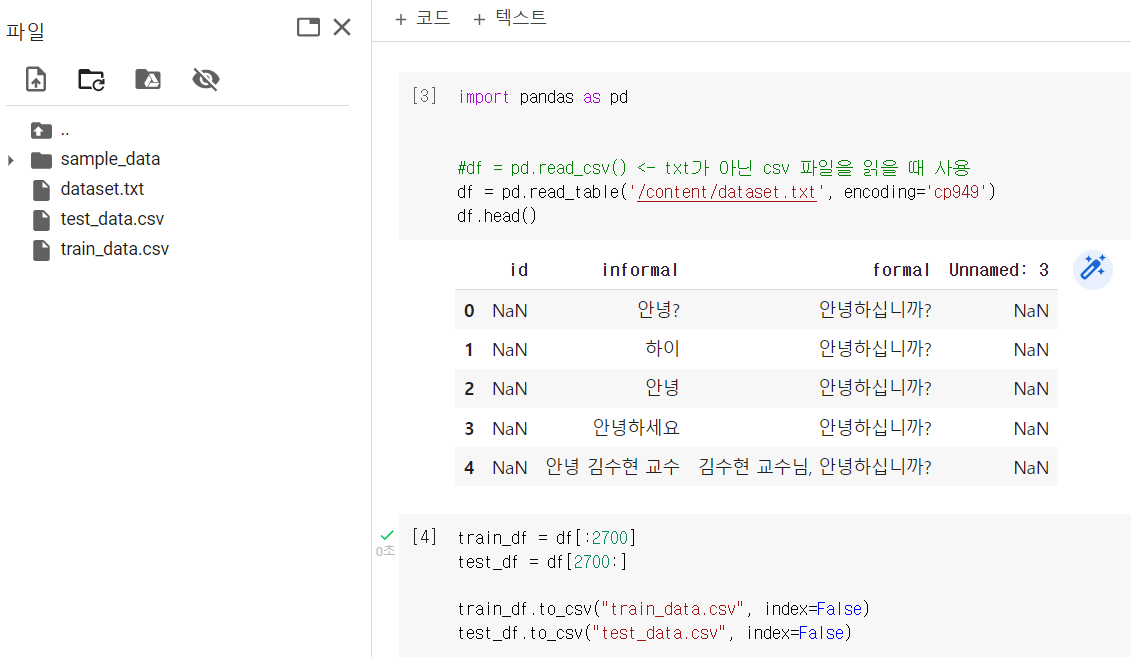
처음에는 빨리 모델링을 돌려보고 싶어서 colab에 로컬에 있던 data를 넣어놓고 시작하려고 했다. 그래서 train_data와 test_data를 나누고 dataset feild를 정의한 뒤 토크나이징 코드까지 작성하였다. 그런데 type관련 오류가 자꾸 나고 그걸 주먹구구식으로 여기 바꾸고 저기 바꾸고 하였더니... 자꾸 다른 곳에서 type 오류가 나고.. 또 type casting을 했더니 또 다른 오류가 나고..!!! 하다가 끝이 나지 않았다..ㅠㅠ 그래서.. 깔끔하게 포기!!!
위 사진 속 코드는 내가 작성한 코드 중 일부이다.
colab의 폴더에 dataset.txt를 로드해놓고 아래 코드를 실행하면 test_data.csv, train_data.csv파일이 생긴다. txt파일이 아니고 csv파일을 사용하려면 주석처리된 'pd.read_csv()'함수 안에 파일 경로+파일명을 넣어주면 된다.
저 코드(삽질..)로 얻은 것은, 전체 데이터셋을 train_data.csv test_data.csv로 저장한 것!! 오히려 좋아~하고 csv파일을 다운 받아서 허깅페이스에 올려두었다.ㅎㅎ
시간 관계상 지금은 검증용 데이터를 구축해두지 않았다.. 하이퍼파라미터들을 조정하며 모델 성능을 개선시키는 것도 충분한 데이터셋을 통한 학습이 선행되어야 할 것 같은데 3000개의 데이터는 너무 적기 때문이다. 방학 때 데이터셋을 더욱 많이 모으고 모델을 학습할 때에는 검증용 데이터를 활용해서 모델 성능 개선에 힘 쓸 것이다! 당연한.. 거겠지요..?
이제 colab에서 학습을 해보자!
코드는 styleKQC_kobart_example.ipynb를 참고하였다. styleKQC... 최고...👍
우선, dataset을 hugging face로부터 불러온다
!pip install datasets
!pip install transformers
from datasets import load_dataset
dataset = load_dataset("comgongdaeng/InToFormal")
dataset을 출력해보면 DatasetDict의 type으로 구성되어 있음을 확인할 수 있다.
'<s>' + sequence + '</s>' 의 형태로 토크나이징하여 저장하기 위해서 kobart-base-v2의 tokenizer를 다운받아야 한다.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gogamza/kobart-base-v2")
```python
이제 진짜 '전체' 데이터셋을 토크나이징하여 저장할 차례이다. 저장한 데이터셋의 column대로 'informal' 데이터와 'formal' 데이터를 토크나이징하여 저장한다.
```python
max_input_length = 512
max_target_length = 512
def preprocess_function(examples):
modi_informal = ['<s>' + sequence + '</s>' for sequence in examples["informal"]]
model_inputs = tokenizer(modi_informal, max_length=max_input_length, truncation=True)
with tokenizer.as_target_tokenizer():
modi_formal = ['<s>' + sequence + '</s>' for sequence in examples["formal"]]
labels = tokenizer(modi_formal, max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs학습 데이터를 앞서 정의한 함수를 사용해서 토크나이징하여 저장하였다.
tokenized_datasets = dataset.map(preprocess_function, batched=True)학습은 koBART를 사용할 것이다
학습을 위해 필요한 패키지들을 import하고, arguments들을 지정한다
from transformers import BartForConditionalGeneration
model = BartForConditionalGeneration.from_pretrained('gogamza/kobart-base-v2')
from transformers import DataCollatorForSeq2Seq, Seq2SeqTrainer, Seq2SeqTrainingArgumentsbatch_size = 16
args = Seq2SeqTrainingArguments(
output_dir = "model_output",
evaluation_strategy = "steps",
learning_rate = 2e-5,
per_device_train_batch_size = batch_size,
per_device_eval_batch_size = batch_size,
save_total_limit = 2,
num_train_epochs = 5,
predict_with_generate = True,
save_steps = 1000,
eval_steps = 500
)data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)data_collator는 batch(값들의 묶음?)를 만드는데, 자동으로 padding이 이루어지기 때문에 토크나이징할 때 padding을 따로 하지 않아도 됐었다!
이제 평가를 위한 metric을 불러와서 설정해보자
!pip install rouge_score
from datasets import load_metric
metric = load_metric("rouge")trainer의 인자들을 정의해주고 트레이닝을 시작한다
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)trainer.train()데이터셋의 크기가 작아서 그런지 시간은 3분 정도 걸린 것 같다.(에포크 수는 5번이었다)
제대로 학습되었는지 확인해보기 위해서 'not하십시오체' 문장을 '하십시오'체로 paraphrasing해주는 paraphrasing함수를 정의해보자
import torch
def paraphrasing(text):
tokenized_text = tokenizer(text, return_tensors='pt', truncation=True).to('cuda')
with torch.no_grad():
outputs = model.generate(
tokenized_text['input_ids'],
do_sample = True,
eos_token_id = tokenizer.eos_token_id,
max_length = 512,
top_p = 0.7,
top_k = 20,
# num_beams=10,
num_return_sequences = 1,
no_repeat_ngram_size = 2,
early_stopping = True
)
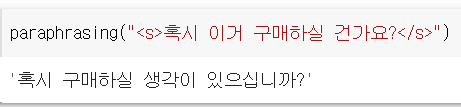
return tokenizer.decode(outputs[0], skip_special_tokens = True)paraphrasing("<s>바꿀 문장</s>") 코드를 사용하면 바뀐 문장이 프린트된다.

혹시를 주어로 판단하고 혹시를 '혹시님께서'로 바꾼 것이 어처구니없지만.. 주격조사를 통한 주체높임을 할 수 있다는 희망을.. 얻어도 되겠지?
네 번 더 실행해보았더니 하십시오체로 변환된 문장을 얻어냈다ㅋㅋㅋㅋ
성능이 많이 좋지 않은데.. 그 이유로는 모델의 적합성, 부적절한 hyperparameter 수 등의 이유가 많이 있겠지만 역시 가장 큰 이유는 데이터의 개수 부족일 것으로 보인다.
현재는 팀원들 모두 wicho님이 공개하신 wicho/stylekqc-style 데이터셋 수정을 통해 팀원들 모두 많은 데이터를 모으기 위해서 노력하고 있다!
원래 준비한 것은 이게 끝인데, 블로그를 쓰다보니 궁금증이 생겨서 몇 개의 문장을 더 돌려보았다.

이걸 보니 개선점이 더 명확하게 보이는 것 같다.
그리고 이건 혼자 생각이지만.. 방학 때 django를 사용해서 사람들이 직접 참여해서 변환할 문장을 직접 작성하는 홈페이지를 만들어보고 싶다.. 접속하는 사람마다 다른 문장을 변환할 수 있게 떠야 하기 때문에.. 구현이 아주 간단하진 않겠지만.. 종강하자마자 공부 시작해야지:)
맞춤법 교정
맞춤법 교정과 띄어쓰기 교정은 아직 모델링을 하지 못하여서 데이터셋 구축 관련 내용만 다룬다.
맞춤법 교정 모델을 만들기 위해서는 '문장 교정 데이터셋'이 필요하다.
예를 들어서 '감기가 낳다.' 라는 input과 그를 교정한 '감기가 낫다'라는 label이 쌍을 이루는 데이터셋이 필요하다.
문장 교정 데이터셋으로 우리가 생각한 것은 lang-8, Kor-learner, Kor-Native 등이 있다.
lang-8은 외국어를 배우기 위한 학습자가 작성한 글을 해당 나라의 원어민이 교정해주는 사이트이다. 많은 나라의 언어로 사용할 수 있어서 다양한 언어로 아주 많은 말뭉치가 존재한다. 궁금해서 더 자세히 알아보고 싶었는데 무슨 이유에서인지 지금 회원가입이 안 된다고..
다행히 말뭉치는 따로 다운받을 수 있는 링크가 있어서 전체 말뭉치를 다운 받았다. 이제 그 데이터셋에서 한국어 데이터만 필터링하는 과정이 필요한데... 윈도우에서 요구되는 파이썬 라이브러리들의 version과 dependency 때문에 계속해서 실패를 했다.. 그래서 우분투에서 다시 시도를 해보았는데..! 자꾸 다른 에러가 나서 아직 필터링을 하지 못하였다ㅠㅠ 어서 완료해서 기말발표 전에 학습시킬 수 있기를..!
Kor-Learner, Kor-Native는 한국어 학습자 말뭉치 및 한국어교수학습샘터 "문법 표현 내용 검색" 자료를 2차 가공한 말뭉치이다. <<기계학습 기반 한국어 오탁자 교정모델 개발 연구팀(윤소영(카이스트) 이하 5명: 김규완, 김규태, 박성준, 조준희, 박기효)>>으로부터 말뭉치를 제공받기 위해 폼을 작성하고 메일이 오기를 기다리고 있다.
그리고 깃허브를 찾아보니 사용할 수 있는 '틀린 문장'-'정답 문장' 데이터셋이 꽤 있는 것 같다.
그리고 이 문장 교정 데이터셋을 직접 만들 수도 있다!
문장에 의도적으로 노이즈를 준 뒤에 디노이징하는 방법이다.
- 신문 기사, 논문 등 맞춤법이 정확한 문장들을 크롤링한다.
- 문장의 단어 일부에 '노이즈'를 준다.
예) 초성, 중성, 종성을 바꾼다 : 안녕하세요 → 앙녕하세요
예) 발음나는 대로 바꾼다 : 집에 가자 → 지베 가자- 출력 결과를 input, 크롤링한 원본 문장을 label로 사용한다.
격식-비격식 전환 기능과 같이 input-label 형태의 데이터셋을 사용하기 때문에 위의 코드를 90% 이상 재활용 할 수 있을 것 같다.
띄어쓰기 교정
이미 공개된 띄어쓰기 교정기는 매우 많기 때문에.. 띄어쓰기 모델의 목표는 "기존 모델의 성능을 뛰어넘는 것!"이다. 어디까지나 목표일 뿐..
띄어쓰기도 확률을 통해 문장에 노이즈를 줘서 데이터셋을 만들 수 있다.
'빨리 집에 가서 침대랑 합체하고 하루 종일 넷플릭스 보고 싶다.'(절대 지금 제 심정이 아닙니다..)라는 문장을 확률에 따라 일부만 띄어쓰기를 삭제한다.
코드를 예로 들어보자면 text.replace(" ", "")을 사용할 수 있겠다.
그 결과로
'빨리집에 가서 침대랑 합체하고 하루종일넷플릭스 보고 싶다.'라는 문장이 나왔다고 가정하자.
노이즈를 준 데이터셋을 입력데이터로, 원래의 데이터를 정답 데이터로 쌍을 이루어서 학습데이터를 만들 수 있다.
데이터 셋을 최대한 많이 끌어모으는 것이 이 태스크의 관건이다!
이 역시 코드는 위의 코드를 재활용 할 수 있을 것이다. 추후 데이터셋을 다 마련해서 맞춤법과 띄어쓰기 학습에 성공한다면 이 게시글을 수정하거나 새 게시글을 올릴 것이다.
문맥에 따른 유의어 추천
이 부분은 모델링이라기보다는 아이디어를 검증한 내용이다
우선, BERT의 masked language model(MLM)을 사용한다.
사용할 수 있는 한국어 모델로는 klue/roBERTa-large가 있다.
우리가 이 기능을 위해 세운 가설은 다음과 같다.
- 바꾸고 싶은 단어를 [MASK]로 치환해서 모델에 넣는다.
- 단계 1의 바꾸고 싶은 단어의 유의어를 유의어 사전에서 찾는다.
- 모델은 [MASK]에 들어갈 단어를 확률에 따라 리스트로 저장한다.
- 유의어사전에 있으면서 확률이 가장 높은 값을 추천할 유의어로 반환한다.
첫 번째로 해당 모델의 허깅페이스에서 use in transformers의 코드를 복사해서 붙여넣는다. colab에서 처음부터 사용하기 위해서는 transformers를 설치하는 것도 필요하다.
!pip install transformers
from transformers import AutoTokenizer, AutoModelForMaskedLM
import torch
tokenizer = AutoTokenizer.from_pretrained("klue/roberta-large")
model = AutoModelForMaskedLM.from_pretrained("klue/roberta-large")그 후의 코드는 허깅 페이스의 transformers documemtation을 참고하여 작성하였다. (참조한 링크)
위 링크의 roBERTa모델에서는 mask의 토큰을 <mask>로 사용하고 있으나,
지금 사용하려는 한국어 roBERTa에서는 토큰을 [MASK]로 사용하고 있으니 주의!inputs = tokenizer("한국의 수도는 [MASK]입니다.", return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# retrieve index of [MASK]
mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
tokenizer.decode(predicted_token_id)다음과 같이 추천을 받고 싶은 단어의 자리에 [MASK]를 넣으면 확률값(logit)에 따라서 logits라는 텐서 리스트가 만들어진다.
predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
에서 logit이 최대값의 인덱스(argmax)인 토큰의 token_id를 저장하고, decode함으로써 확률이 젤 높은 단어를 얻을 수 있다.
tokenizer.decode(predicted_token_id)
의 결과로는 '서울'이 나온다.
태스크를 수행하기 위해서는 로짓값이 제일 높은 token_id가 아닌 단어들의 확률값 리스트가 필요하다.
다음 문장에서 역량을 대체할 유의어를 맥락에 맞게 찾아보자.
각자가 업무를 하면서 개인만의 역량으로 모든 일을 해결할 수 있다면 정말 기쁠 것입니다
1. 바꾸고 싶은 단어를 [MASK]로 치환해서 모델에 넣는다.
inputs = tokenizer("각자가 업무를 하면서 개인만의 [MASK]으로 모든 일을 해결할 수 있다면 정말 기쁠 것입니다.", return_tensors="pt")우선 inputs에 역량 대신 마스킹 토큰 [MASK]를 넣고 토크나이징하여 대입한다.
2. 단계 1의 바꾸고 싶은 단어의 유의어를 유의어 사전에서 찾는다.
그리고 유의어 사전을 원래 코드로 가져와야 하지만.. 우선 앞선 가설이 작동하는지 실험해보기 위해 간단하게 네이버 실력에서 유의어를 찾아 수동으로 리스트에 넣어주었다...

symDict = ["그릇", "실력", "힘", "능력"]처음에 synonym dictionary를 의미하도록 리스트를 만들었는데.. 도대체 왜 symDict이라고 지었는지 모르겠다ㅋㅋㅋㅋsynonym dictionory인지.. 아니면 syn을 쓰려다가 오타가 난 건지.. 왜 저랬는지 기억이 나지 않는데.. 근데 뭐 이런 게 코딩의 매력이니(?) 그냥 놔두었다ㅋㅋㅋ
3. 모델은 [MASK]에 들어갈 단어를 확률에 따라 리스트로 저장한다.
앞서 사용했던 코드를 그대로 사용해서 로짓 리스트를 만들어보자
with torch.no_grad():
logits = model(**inputs).logits
mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]argmax 함수를 통해서 이 모델이 판단한 단어를 알아보자.
predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
tokenizer.decode(predicted_token_id)유의어와 관련 없이 이 모델이 판단한 가장 맥락에 맞는 그 자리에 들어갈 단어는 '시간'이 나왔다!
각자가 업무를 하면서 개인만의 시간으로 모든 일을 해결할 수 있다면 정말 기쁠 것입니다.?? 머신러닝 멍청이~ㅎㅎ 역시 모든 일은 시간이 해결해 주는 게 맞다
ts = torch.sort(logits[0, mask_token_index], dim=- 1, descending=True)sort 함수를 통해 리스트를 로짓값이 높은 순(descending=True)으로 정렬할 수 있다.
4. 유의어사전에 있으면서 확률이 가장 높은 값을 추천할 유의어로 반환한다.
def max_logit(tensor, symDict):
size = len(symDict)
stop = False
for i in range(0, 32000):
for j in range(0,size):
if str(tokenizer.decode(tensor[1][0][i])) == symDict[j]:
stop = True
break
if stop:
break
return i이 로짓의 텐서는 32000개 단어의 로짓값을 가지고 있다.
그래서 tensor[1][0][0]에서부터 tensor[1][0][31999]까지 유의어 사전 속의 단어와 비교하는 함수를 작성하였다. 유의어사전에 있으면서 확률이 가장 높은 값을 찾아야 하기 때문에 정렬된 텐서를 탐색하다 같은 값이 나오자마자 해당 인덱스를 넘겨주어야 한다. 따라서 stop 변수와 break를 통해 바로 이중 반복문을 탈출하고 i를 반환한다! (사실 끝까지 비교해봤을 때 단어 리스트에 없으면 반환하는 i 값이 31999이고 31999가 유의어 사전에 있는 첫 단어였어도 반환값이 31999이기 때문에 그걸 구분하는 코드가 따로 필요한데... 일단 넘어가자)
내림차순으로 정렬된 텐서와 유의어 리스트를 넣어서 함수를 호출해보자.
a = max_logit(ts, symDict)
tokenizer.decode(ts[1][0][a])
출력 값으로는 '능력'이 나왔다!
코드는 아직 개선해야할 점이 많지만, 아무튼 MLM과 유의어 사전을 동시에 활용하자는 가설을 검증함으로써 프로젝트의 희망을 얻었다!0!
앞으로의 해야할 일들..
앞으로의 태스크를 정리하고 이번 포스팅을 마무리하고자 한다.
- 모든 기능을 위한 데이터셋 모으기
- 이 포스팅 내의 기능들 모델링 및 성능 개선
- 긴 호흡 문장 판별 기능 개발
- 구현한 모델 통합
- 모델 서버 / 프론트 개발 / 백엔드 개발
- 분명 더 있을 텐데...?

잘 읽었어요~