인덱스 기본
- 인덱스 특징과 종류
인덱스는 원하는 데이터를 쉽게 찾을 수 있도록 돕는 책의 색인과 유사한 개념이다.
인덱스의 기본적인 목적은 검색 성능의 최적화이다. Insert, Update, Delete 등과 같은 DML 작업은 테이블과 인덱스를 함께 변경해야 하기 때문에 오히려 느려질 수 있는 단점이 존재한다.
트리 기반 인덱스
DBMS에서 가장 일반적인 인덱스는 B-트리 인덱스이다.
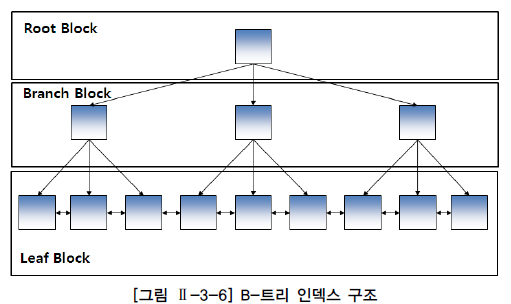
B-트리 인덱스는 브랜치 블록(Branch Block)과 리프 블록(Laef Block)으로 구성
브랜치 블록 중에서 가장 상위에서 있는 블록을 루트 블록(Root Block)이라 한다.
브랜치 블록은 분기를 목적으로 하는 블록이다. 다음 단계의 블록을 가리키는 포인터를 가지고 있다.리프 블록은 트리의 가장 아래 단계에 존재한다.
리프 블록은 인덱스를 구성하는 컬럼의 데이터와 해당 데이터를 가지고 있는 행의 위치를 가리키는 레코드 식별자(RID, Record Identifier/Rowid)로 구성되어 있다.인덱스 데이터는 인덱스를 구성하는 칼럼의 값으로 정렬된다.리프 블록은 양방향 링크(Double Link)를 가지고 있다.
이것을 통해서 오름 차순(Ascending Order)과 내림 차순(Descending Order) 검색을 쉽게 할 수 있다.
B-트리 인덱스는 "="로 검색하는 일치(Exact Match) 검색과 "BETWEEN", ">" 등과 같은 연산자로 검색하는 범위(Range)검색 모두에 적합한 구조이다.
인덱스에서 원하는 값을 찾는 과정
-
브랜치 블록의 가장 왼쪽 값이 찾고자 하는 값보다 작거나 같으면 왼쪽 포인터로 이동
-
찾고자 하는 값이 브랜치 블록의 값 사이에 존재하면 가운데 포인터로 이동
-
오른쪽에 있는 값보다 크면 오른쪽 포인터로 이동
이 과정을 리프 블록을 찾을 때까지 반복
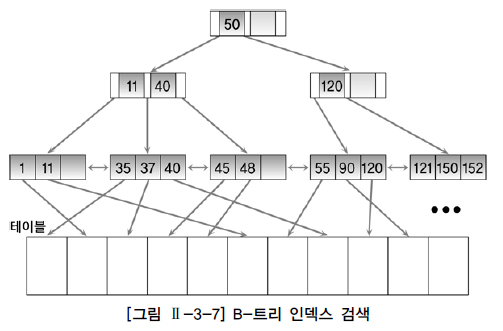
Range 탐색의 경우 (BETWEEN 37 AND 50)
37리프 블록을 찾고 오른쪽으로 이동하면서 인덱스를 읽는다. 이것은 인덱스 데이터가 정렬되어 있고 리프 블록이 양방향 링크로 연결되어 있기 때문에 가능하다.
=> 인덱스를 경유해서 반환된 결과 데이터는 인덱스 데이터와 동일한 순서로 갖게 되는 특징을 갖는다.
인덱스를 생성할 때 동일 컬럼으로 구성된 인덱스를 중복해서 생성할 수 없다. 그렇지만 인덱스 구성칼럼은 동일하지만 컬럼의 순서가 다르면 서로 다른 인덱스를 생성할 수 있다.
ex) JOB + SAL 컬럼 순서의 인덱스와 SAL + JOB 컬럼 순서의 인덱스를 별도의 인덱스를 생성할 수 있다.
- 전체 테이블 스캔과 인덱스 스캔
가. 전체테이블 스캔
테이블에 존재하는 모든 데이터를 읽어 가면서 조건에 맞으면 결과를 추출하고 조건에 맞지 않으면 버리는 방식으로 검색
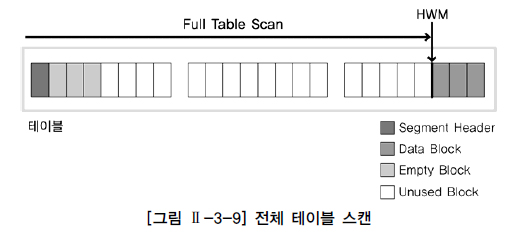
오라클의 경우 검색 조건에 맞는 데이터를 찾기 위해서 테이블의 고수위 마크(HMW, High Water Mark) 아래의 모든 블록을 읽는다.
고수위 마크는 테이블에 데이터가 쓰여졌던 블록 상의 최상위 위치를 의미한다.
전체 테이블 스캔 방식으로 데이터를 검색할 때 고수기 때문에 모든 결과를 찾을 때까지 시간이 오래 걸릴 수 있다.
옵티마이저가 풀 스캔방식을 선택하는 이유(일반적)
-
SQL 문에 조건이 존재하지 않는 경우
-
SQL문의 주어진 조건에 사용 가능한 인덱스가 존재하지 않는 경우(주어진 조건에 사용 가능한 인덱스는 존재하나 함수를 사용하여 인덱스 컬럼을 변형한 경우에도 인덱스 사용 불가)
-
옵티마이저의 취사 선택 (조건을 만족하는 데이터가 많은 경우, 조건에 사용 가능한 인덱스가 존재해도 전체 테이블 스캔 방식으로 읽는다.)
나. 인덱스 스캔
인덱스 스캔은 인덱스를 구성하는 컬럼의 값을 기반으로 데이터를 추출하는 액세스 기법이다.인덱스의 리프 블록은 인덱스 구성하는 칼럼과 레코드 식별자로 구성되어 있다. 따라서 인덱스의 리프 블록을 읽으면 두 값을 알 수 있다. 인덱스에 존재하지 않는 컬럼의 값이 필요한 경우에는 현재 읽은 레코드 식별자를 이용하여 테이블을 액세스해야 한다. SQL 문에서 필요로 하는 모든 컬럼이 인덱스 구성 컬럼에 포함된 경우 테이블에 대한 엑세스는 발생하지 않는다.
인덱스는 인덱스 구성 컬럼의 순서로 정렬되어 있다.
인덱스의 구성 컬럼이 A + B라면 먼저 칼럼 A로 정렬되고 컬럼 A의 값이 동일한 경우 칼럼 B로 정렬된다. 그리고 컬럼 B까지 모두 동일하면 레코드 식별자로 정렬된다. (인덱스가 구성 컬럼으로 정렬되어 있기 때문에 인덱스를 경유하여 데이터를 읽으면 그 결과 또한 정렬되어 반환된다.)
=> 인덱스의 순서와 동일한 정렬 순서를 사용자가 원하는 경우에는 정렬 작업을 하지 않을 수 있다.
인덱스 스캔 종류
-
인덱스 유일 스캔
-
유일 인덱스(Unique Index)를 사용하여 단 하나의 데이터를 추출하는 방식 (중복을 허락하지 않는 인덱스)
-
유일 인덱스 구성 컬럼에 "="로 값이 주어지면 결과는 최대 1건이 된다. "="로 값이 주어진 경우에만 가능한 인덱스 스캔 방식이다.
-
인덱스 범위 스캔
-
인덱스를 이용하여 한 건 이상의 데이터를 추출하는 방식
-
유일 인덱스 구성 컬럼 모두에 대해 "="로 값이 주어지지 않은 경우, 비유일 인덱스(Non-Unique Index)를 이용하는 모든 액세스 방식은 인덱스 범위 스캔 방식으로 데이터를 액세스 한다.
전체 테이블 스캔과 인덱스 스캔 비교
전체 테이블 스캔
-
테이블의 전체 데이터를 모두 읽으면서 데이터 추출
-
인덱스의 존재 유무와 상관없이 항상 이용 가능
인덱스 스캔
-
인덱스를 경유해서 읽는 방식
-사용 가능한 적절한 인덱스가 존재할때만 이용가능SQL 처리 흐름도
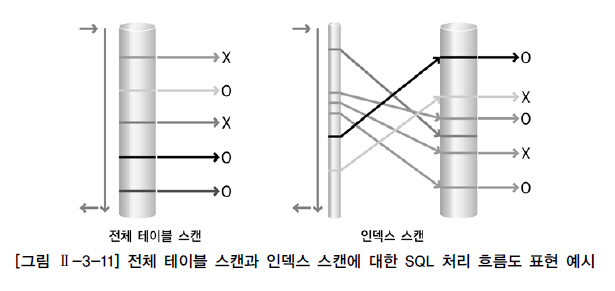
인덱스 스캔은 데이터의 정확한 위치를 알고서(레코드 식별자) 데이터를 읽기 때문에 불필요하게 다른 블록을 더 읽을 필요가 없다. 따라서 한번의 I/O 요청에 한 블록씩 데이터를 읽는다.
그러나 전체 테이블 스캔은 데이터를 읽을 때 한 번의 I/O 요청으로 여러 블록을 한꺼번에 일는다. 어차피 테이블의 모든 데이터를 읽을 것이라면 한번 읽기 작업을 할 때 여러 블록을 함께 읽는 것이 효율적이다.
=> 극히 일부의 데이터를 찾을 때는 인덱스 스캔이 유리
=> 대부분의 데이터를 읽을 거라면 전체 테이블 스캔이 유리
출처: https://cornswrold.tistory.com/83?category=777471 [평범한개발자노트:티스토리]
